大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」
抱个拳,送个礼
在当今的人工智能(AI)领域,Embedding 是一个不可或缺的概念。如果你没有深入理解过 Embedding,那么就无法真正掌握 AI 的精髓。接下来,我们将深入探讨 Embedding 的基本概念。

1. Embedding的基本概念
1.1 什么是 Embedding
Embedding 是一种将高维数据映射到低维空间的技术。简单来说,它就是把复杂的、难以处理的数据转换成便于计算的形式。举个例子,假设我们有一个包含上千个词汇的文本数据,每个词汇可以看作是一个维度,这样的数据在计算机处理时会变得非常复杂。而 Embedding 则是通过数学模型将这些高维数据映射到一个低维空间,使得计算更加高效。
1.2 Embedding 在 AI 中的作用
在 AI 中,Embedding 扮演着极其重要的角色。首先,它能大大降低数据的维度,从而提高计算效率。其次,通过 Embedding,AI 模型能够捕捉到数据之间的隐含关系和结构。例如,在自然语言处理(NLP)中,词向量(word embeddings)能够将语义相近的词汇映射到相邻的向量空间中,这样模型就可以更好地理解和处理语言数据。
1.3 常见的 Embedding 类型
根据不同的应用场景,Embedding 的实现方法也有所不同。常见的 Embedding 类型包括:
- 词向量(Word Embedding):这是最常见的一种 Embedding,主要用于 NLP 领域。通过词向量模型,如 Word2Vec 和 GloVe,可以将词汇映射到一个固定维度的向量空间中,从而捕捉到词汇之间的语义关系
- 图像嵌入(Image Embedding):在计算机视觉(CV)领域,图像嵌入技术可以将图像数据转换为向量,从而用于图像分类、对象检测等任务
- 用户嵌入(User Embedding):在推荐系统中,通过对用户行为数据进行嵌入,可以有效地进行个性化推荐

更多内容,见免费知识星球
2. Embedding的数学基础
Embedding 的有效实现离不开坚实的数学基础。为了更好地理解 Embedding 的工作原理,我们需要了解一些关键的数学概念。
2.1 向量空间
向量空间是线性代数中的一个基本概念,也是 Embedding 的核心。向量空间由一组向量组成,这些向量可以进行加法和数乘运算。在 Embedding 中,我们将数据点表示为向量,并将它们映射到一个高维或低维的向量空间中。这样,通过在向量空间中的操作,我们可以捕捉到数据点之间的关系和结构。
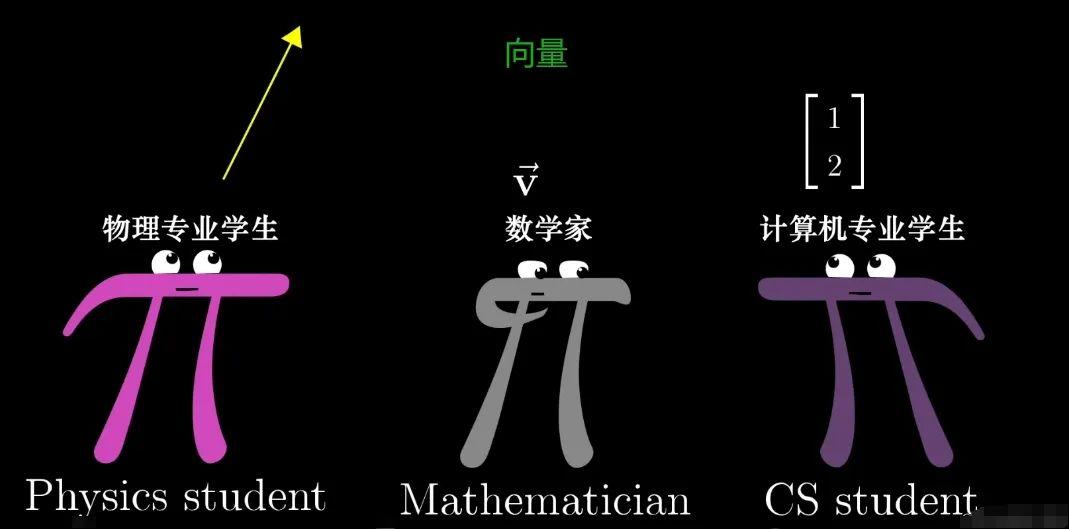
(by 3Blue1Brown)



2.2 线性代数基础
线性代数是 Embedding 技术的基础,以下是一些关键的线性代数概念:
- 矩阵:矩阵是二维数组,常用于表示和操作向量。矩阵乘法是 Embedding 技术中的重要操作,例如在训练词向量模型时,常使用矩阵乘法来计算词汇之间的关系
- 特征值和特征向量:特征值和特征向量是描述矩阵性质的重要工具。在 Embedding 中,特征值分解和奇异值分解(SVD)等技术常用于降维和优化模型
- 内积和外积:内积用于衡量向量之间的相似性,而外积用于构建更高维度的矩阵,这两者在 Embedding 技术中都有广泛应用
2.3 高维数据的处理
处理高维数据是 Embedding 技术的一个重要挑战。高维数据通常包含大量冗余信息,计算复杂度也较高。为了高效地处理高维数据,我们通常采用以下方法:
- 降维技术:降维技术,如主成分分析(PCA)和 t-SNE,可以有效地将高维数据映射到低维空间,保留数据的主要特征
- 正则化:在模型训练过程中,通过添加正则化项,可以防止过拟合,提高模型的泛化能力
- 采样技术:对于大规模数据集,可以采用负采样(Negative Sampling)等技术,以减少计算量,提高训练速度
通过理解向量空间、线性代数基础和高维数据处理方法,我们可以更好地掌握 Embedding 的数学原理
3. Embedding的实现方法
Embedding 的实现方法多种多样,具体选择取决于应用场景和需求。下面,我们将介绍几种常见的 Embedding 实现方法。
3.1 词向量模型(Word2Vec, GloVe)
词向量模型是自然语言处理(NLP)中的重要工具,它们可以将词汇映射到一个固定维度的向量空间中,捕捉到词汇之间的语义关系。
- Word2Vec:这是由 Google 提出的一个词向量模型,主要有两种训练方法:连续词袋模型(CBOW)和跳跃模型(Skip-gram)。CBOW 通过预测上下文词汇来训练词向量,而 Skip-gram 则通过预测给定词汇的上下文来训练。Word2Vec 模型的优点是训练速度快,且能有效捕捉到词汇的语义关系
- GloVe:全局向量(GloVe)是由斯坦福大学提出的另一种词向量模型。它通过构建词汇的共现矩阵,并对矩阵进行优化来生成词向量。与 Word2Vec 不同,GloVe 结合了全局统计信息,使得生成的词向量更加稳定和准确
3.2 神经网络嵌入(Neural Embedding)
神经网络嵌入是利用深度学习模型实现 Embedding 的一种方法,适用于多种数据类型,包括文本、图像和图结构数据。
- 神经网络词嵌入:在 NLP 中,除了 Word2Vec 和 GloVe,基于神经网络的嵌入方法如 BERT 和 GPT 也广泛应用。BERT 通过双向 Transformer 模型进行预训练,可以捕捉到上下文的双向依赖关系。而 GPT 则通过自回归模型进行训练,生成高质量的文本嵌入
- 卷积神经网络(CNN)嵌入:在计算机视觉(CV)中,卷积神经网络(CNN)被广泛用于图像嵌入。通过多层卷积操作,CNN 可以提取图像的特征,并将其映射到一个低维向量空间中
- 图神经网络(GNN)嵌入:对于图结构数据,图神经网络(GNN)通过聚合节点及其邻居的特征,实现图数据的嵌入。GNN 能够捕捉图中节点之间的复杂关系,广泛应用于社交网络分析、推荐系统等领域
3.3 其他 Embedding 技术
除了上述方法,还有一些其他的 Embedding 技术,适用于特定的应用场景:
- 自编码器(Autoencoder):自编码器是一种无监督学习模型,通过构建输入数据的压缩表示,实现在低维空间中的嵌入。自编码器在降维和特征提取方面有良好的表现,适用于多种数据类型
- 潜在语义分析(LSA)和潜在狄利克雷分配(LDA):这两种方法主要用于文本数据的主题建模。LSA 通过奇异值分解(SVD)对词汇-文档矩阵进行降维,而 LDA 通过贝叶斯推断来发现文本中的潜在主题
- 词嵌入的组合方法:在实际应用中,常常结合多种嵌入方法,以提高模型的表现。例如,将 Word2Vec 和 GloVe 生成的词向量进行组合,或将自编码器生成的嵌入与神经网络嵌入结合使用
抱个拳,送个礼
点击 ↑ 领取

4. Embedding的训练与优化
要实现高效的 Embedding,训练与优化过程至关重要。以下是 Embedding 训练与优化的关键步骤。
4.1 数据预处理
数据预处理是 Embedding 训练的第一步,良好的预处理可以显著提高模型的性能。
- 文本数据的预处理:包括分词、去除停用词、词干提取和词形还原等。分词是将文本拆分成独立的词汇,这一步骤在 NLP 中尤为重要。去除停用词是指删除一些频繁出现但没有实际意义的词汇,如“的”、“是”、“在”等。词干提取和词形还原则是将词汇转换为其基础形式,以减少词汇量
- 图像数据的预处理:包括图像归一化、尺寸调整和数据增强。图像归一化是将像素值归一化到一定范围内,提高模型的训练效果。尺寸调整是将图像缩放到统一尺寸,以适应模型输入的要求。数据增强则是通过图像旋转、翻转、裁剪等操作,增加训练数据的多样性
- 图数据的预处理:包括图节点和边的特征提取。对于图结构数据,需要提取节点和边的特征,并将其转换为模型可以处理的格式。例如,在社交网络中,可以提取用户的个人信息和社交关系作为特征
4.2 模型训练
模型训练是 Embedding 实现的核心步骤,选择合适的训练方法和优化算法至关重要。
- 监督学习:在有标签数据的情况下,可以使用监督学习方法进行 Embedding 训练。例如,在文本分类任务中,可以将分类标签作为监督信号,通过神经网络模型进行训练,生成词向量
- 无监督学习:在无标签数据的情况下,可以使用无监督学习方法进行 Embedding 训练。常见的方法包括自编码器和聚类算法。自编码器通过重构输入数据,实现数据的嵌入表示。聚类算法则通过将数据点分组,生成每个数据点的嵌入向量
- 半监督学习:在部分有标签数据的情况下,可以使用半监督学习方法进行 Embedding 训练。通过结合有标签和无标签数据,可以提高模型的泛化能力。例如,在图嵌入中,可以使用 GraphSAGE 等半监督学习方法,通过聚合节点及其邻居的特征,生成节点嵌入
4.3 模型评估与优化
模型评估与优化是确保 Embedding 质量的关键步骤,通过有效的评估和优化,可以提升模型的性能。
- 模型评估:常见的评估指标包括准确率、精确率、召回率和 F1 分数。在 NLP 任务中,可以使用词相似度、词类比和下游任务性能等指标评估词向量的质量。在图嵌入任务中,可以使用节点分类、链接预测等指标评估嵌入的效果
- 超参数优化:超参数对模型的性能有显著影响,常见的优化方法包括网格搜索和随机搜索。通过调整学习率、批次大小、嵌入维度等超参数,可以找到最优的模型配置
- 正则化技术:正则化技术可以防止模型过拟合,提高泛化能力。常见的正则化方法包括 L1 和 L2 正则化、Dropout 和早停(Early Stopping)。在 Embedding 训练中,加入正则化项可以约束模型参数,防止过拟合
通过数据预处理、模型训练和模型评估与优化,我们可以实现高质量的 Embedding

免费知识星球,欢迎加入交流
5. Embedding的应用场景
Embedding 技术在不同领域中有广泛的应用,它们能够帮助我们高效地处理和分析复杂的数据。以下是几种主要的应用场景。
5.1 自然语言处理(NLP)
在自然语言处理(NLP)领域,Embedding 技术是至关重要的,它能够将文本数据转换为计算机可以处理的向量形式,捕捉到词汇和短语之间的语义关系。
- 文本分类:通过词向量(如 Word2Vec 或 GloVe),可以将文本中的每个词映射到一个向量空间中,再通过平均或其他方法生成文本的向量表示,进而用于分类任务。经典的应用包括垃圾邮件过滤、情感分析和主题分类等
- 机器翻译:在机器翻译任务中,Embedding 技术用于将源语言和目标语言的词汇转换为向量表示,从而通过神经网络模型进行翻译。典型的模型包括基于 RNN 的序列到序列模型和基于 Transformer 的注意力机制模型
- 问答系统:问答系统需要理解用户提出的问题并从知识库中找到答案。通过词向量或句子向量,可以将问题和候选答案表示为向量,并通过计算相似度来匹配最合适的答案
5.2 计算机视觉(CV)
在计算机视觉(CV)领域,Embedding 技术主要用于将图像数据转换为低维向量表示,以便进行各种图像分析任务。
- 图像分类:通过卷积神经网络(CNN),可以将图像嵌入到一个低维向量空间中,从而实现图像分类。经典的 CNN 模型包括 AlexNet、VGG 和 ResNet 等,这些模型在图像分类任务中表现出色
- 对象检测:对象检测任务需要在图像中定位并分类多个对象。通过将图像分割成小区域,并对每个区域进行嵌入,可以实现对象检测。典型的模型包括 R-CNN、YOLO 和 SSD 等
- 图像检索:在图像检索任务中,通过将查询图像和数据库中的图像嵌入到相同的向量空间中,可以通过计算向量相似度来找到最相似的图像。这个过程通常涉及图像特征提取和度量学习
5.3 推荐系统
推荐系统通过分析用户行为数据,为用户提供个性化的推荐。Embedding 技术在推荐系统中起着关键作用,能够将用户和物品的特征表示为向量,从而进行高效的推荐。
- 协同过滤:在协同过滤方法中,通过将用户和物品嵌入到一个共同的向量空间中,可以根据用户的历史行为数据,预测用户对未评分物品的喜好。矩阵分解(如 SVD)和神经协同过滤是常见的实现方法
- 内容推荐:在内容推荐方法中,通过将用户特征和内容特征嵌入到向量空间中,可以根据内容的相似性,为用户推荐感兴趣的内容。典型的应用包括新闻推荐、视频推荐和商品推荐
- 混合推荐:混合推荐方法结合了协同过滤和内容推荐的优点,通过多种 Embedding 技术,将用户和物品的特征进行综合分析,以提高推荐的准确性和多样性
通过 Embedding 技术在自然语言处理、计算机视觉和推荐系统中的应用,我们可以大大提升数据分析和处理的效率和效果
6. 经典Embedding案例分析
为了更好地理解 Embedding 的实际应用,我们将通过几个经典案例来详细分析 Embedding 技术的实现和效果。
6.1 Word2Vec案例
Word2Vec 是由 Google 提出的词向量模型,通过将词汇嵌入到一个高维向量空间中,捕捉到词汇之间的语义关系。Word2Vec 有两种主要的训练方法:连续词袋模型(CBOW)和跳跃模型(Skip-gram)。
- 连续词袋模型(CBOW):CBOW 模型通过预测给定上下文中间的词汇来训练词向量。假设我们有一个句子 “The quick brown fox jumps over the lazy dog”,CBOW 模型会用上下文 “The quick brown fox” 和 “over the lazy dog” 来预测中心词 “jumps”
- 跳跃模型(Skip-gram):Skip-gram 模型通过预测给定词汇的上下文来训练词向量。以同一个句子为例,Skip-gram 模型会用中心词 “jumps” 来预测上下文 “The quick brown fox” 和 “over the lazy dog”
效果:通过 Word2Vec 训练的词向量,可以有效地捕捉到词汇之间的语义关系。例如,词向量之间的向量运算可以表示语义关系,如
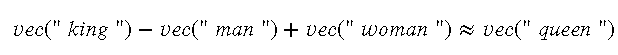
这种语义操作在很多 NLP 任务中都表现出了极大的优势。
6.2 GloVe案例
GloVe(全局向量)是斯坦福大学提出的一种词向量模型,它通过构建词汇的共现矩阵,并对矩阵进行优化来生成词向量。与 Word2Vec 不同,GloVe 结合了全局统计信息,使得生成的词向量更加稳定和准确。
- 共现矩阵:GloVe 首先构建一个词汇的共现矩阵,矩阵中的每个元素表示两个词汇在一个固定窗口大小内共同出现的次数。例如,如果我们有一个句子 “The quick brown fox jumps over the lazy dog”,那么词汇 “quick” 和 “brown” 之间的共现次数就是 1
- 矩阵优化:GloVe 通过对共现矩阵进行优化,使得词向量能够更好地表示词汇之间的语义关系。优化过程通过最小化一个损失函数,使得词向量能够尽可能准确地表示共现矩阵中的统计信息
效果:通过 GloVe 训练的词向量,同样能够有效地捕捉到词汇之间的语义关系,并且在某些任务中表现得比 Word2Vec 更加稳定和准确。例如,在词类比任务中,GloVe 通常能够给出更符合语义的结果。
6.3 BERT案例
BERT(双向编码器表示的 Transformer)是 Google 提出的基于 Transformer 模型的词向量表示方法,它通过双向 Transformer 模型进行预训练,能够捕捉到词汇的上下文语义信息。
- 双向 Transformer:与传统的单向语言模型不同,BERT 通过双向 Transformer 模型进行训练,即同时考虑词汇的前后文信息。这样,BERT 能够更好地捕捉到词汇的上下文语义关系。例如,在句子 “The bank can guarantee deposits will cover future tuition costs because it invests in adjustable-rate mortgage securities” 中,BERT 能够根据上下文信息区分 “bank” 是指金融机构还是河岸
- 预训练和微调:BERT 首先在大规模语料库上进行预训练,学习词汇的通用语义表示。然后,在具体任务上进行微调,使得模型能够适应特定任务的需求
效果:BERT 在多个 NLP 任务中取得了显著的效果提升,包括问答系统、文本分类和命名实体识别等。BERT 的预训练模型能够生成高质量的词向量表示,显著提高了下游任务的性能。
通过 Word2Vec、GloVe 和 BERT 的案例分析,我们可以看到 Embedding 技术在不同 NLP 任务中的实际应用效果。接下来,我们将探讨 Embedding 与其他 AI 技术的关系。
抱个拳,送个礼
点击 ↑ 领取

7. Embedding与其他AI技术的关系
Embedding 技术与其他 AI 技术密切相关,通过结合不同的 AI 技术,能够实现更强大的功能和性能。下面我们将探讨 Embedding 与深度学习、强化学习和迁移学习的关系。
7.1 Embedding与深度学习
深度学习(Deep Learning)是实现 Embedding 技术的重要方法之一,许多现代 Embedding 技术都依赖于深度神经网络模型。
- 卷积神经网络(CNN):在计算机视觉(CV)领域,CNN 被广泛用于图像嵌入。通过多层卷积操作,CNN 可以提取图像的特征,并将其映射到一个低维向量空间中。这些嵌入向量可以用于图像分类、对象检测和图像检索等任务
- 循环神经网络(RNN):在自然语言处理(NLP)领域,RNN 尤其是长短期记忆网络(LSTM)和门控循环单元(GRU),被广泛用于序列数据的嵌入。通过处理序列数据,RNN 可以捕捉到时间序列中的依赖关系,将序列嵌入到低维向量空间中
- Transformer:Transformer 模型在 NLP 中取得了巨大的成功,尤其是 BERT 和 GPT 等预训练模型。Transformer 通过自注意力机制,可以有效地捕捉到序列数据中的长距离依赖关系,实现高质量的词向量嵌入
7.2 Embedding与强化学习
强化学习(Reinforcement Learning,RL)是一种通过与环境交互来学习策略的机器学习方法。Embedding 技术在强化学习中也有广泛应用,尤其是在状态表示和策略学习中。
- 状态表示:在强化学习中,状态表示是一个关键问题。通过 Embedding 技术,可以将复杂的高维状态空间映射到一个低维向量空间中,使得状态表示更加紧凑和有效。例如,在机器人控制任务中,可以通过图像嵌入技术,将视觉输入表示为低维向量,从而提高策略学习的效率
- 策略嵌入:强化学习中的策略可以通过嵌入技术进行表示和优化。通过策略嵌入,可以将策略映射到一个连续的向量空间中,从而进行优化和改进。例如,在推荐系统中,可以通过策略嵌入技术,学习用户的个性化推荐策略,提高推荐的准确性和多样性
7.3 Embedding与迁移学习
迁移学习(Transfer Learning)是一种通过将已学到的知识从一个任务迁移到另一个任务的机器学习方法。Embedding 技术在迁移学习中起着重要作用,尤其是在预训练模型的应用中。
- 预训练模型:预训练模型是迁移学习的核心方法,通过在大规模数据集上进行预训练,学习通用的特征表示。然后,在具体任务上进行微调,使得模型能够适应特定任务的需求。BERT 和 GPT 就是典型的预训练模型,通过预训练生成高质量的词向量嵌入,再在下游任务中进行微调
- 特征迁移:通过 Embedding 技术,可以将预训练模型生成的特征向量迁移到新的任务中。例如,在图像分类任务中,可以将预训练的 CNN 模型生成的图像嵌入,迁移到新的图像分类任务中,提高训练效率和模型性能
通过结合深度学习、强化学习和迁移学习,Embedding 技术能够实现更强大的功能和性能

免费知识星球,欢迎加入,一起交流切磋
8. 如何选择合适的Embedding技术
在实际应用中,选择合适的 Embedding 技术对于模型的性能和效果至关重要。以下是一些选择 Embedding 技术的指南,根据数据类型、应用场景和计算资源进行选择。
8.1 根据数据类型选择
不同的数据类型适合不同的 Embedding 技术,选择合适的技术可以提高模型的性能。
- 文本数据:对于文本数据,常用的词向量模型包括 Word2Vec、GloVe 和基于 Transformer 的预训练模型(如 BERT、GPT)。如果任务是简单的词汇嵌入,Word2Vec 和 GloVe 是不错的选择。如果需要捕捉复杂的上下文关系,基于 Transformer 的模型则更为适用
- 图像数据:对于图像数据,卷积神经网络(CNN)是最常用的嵌入方法。经典的 CNN 模型如 AlexNet、VGG、ResNet 等,都能够有效地将图像嵌入到低维向量空间中。如果需要处理大规模图像数据,可以考虑使用预训练的 CNN 模型,并在具体任务上进行微调
- 图结构数据:对于图结构数据,图神经网络(GNN)是最常用的嵌入方法。GNN 能够捕捉图中节点之间的复杂关系,适用于社交网络分析、推荐系统等任务。常见的 GNN 模型包括 GraphSAGE、GAT 和 GCN
8.2 根据应用场景选择
不同的应用场景对嵌入的要求不同,选择适合应用场景的嵌入技术可以提高任务的完成效果。
- 自然语言处理(NLP):在 NLP 中,如果任务是文本分类、情感分析等,可以使用 Word2Vec 或 GloVe 等简单的词向量模型。如果任务是问答系统、机器翻译等复杂任务,基于 Transformer 的模型(如 BERT、GPT)更为适用
- 计算机视觉(CV):在 CV 中,如果任务是图像分类、对象检测,可以使用经典的 CNN 模型。如果需要处理图像检索任务,可以结合度量学习(如对比损失)来训练图像嵌入
- 推荐系统:在推荐系统中,如果任务是协同过滤,可以使用矩阵分解技术(如 SVD)或神经协同过滤。如果需要结合内容推荐,可以使用基于文本或图像的嵌入技术,并将它们与协同过滤结合
8.3 根据计算资源选择
计算资源的限制也会影响嵌入技术的选择。在资源有限的情况下,选择计算效率高的嵌入技术可以提高模型的实用性。
- 轻量级模型:如果计算资源有限,可以选择计算效率高的轻量级模型。例如,在 NLP 任务中,可以使用较小的词向量模型(如 Word2Vec)而不是复杂的 Transformer 模型。在 CV 任务中,可以选择较小的 CNN 模型(如 MobileNet)而不是大型的 ResNet
- 分布式训练:在大规模数据和高计算资源的情况下,可以采用分布式训练技术,提高模型训练的效率。例如,在训练大型预训练模型(如 BERT、GPT)时,可以使用分布式计算框架(如 TensorFlow、PyTorch)进行分布式训练
- 云计算和硬件加速:如果需要处理超大规模数据,可以借助云计算平台(如 AWS、Google Cloud)和硬件加速技术(如 GPU、TPU)来提高计算效率和模型性能
[ 抱个拳,总个结 ]
Embedding 技术在人工智能领域中起着至关重要的作用,能够将复杂的高维数据映射到低维空间,提高数据处理和分析的效率。本文详细探讨了 Embedding 的基本概念、数学基础、实现方法、训练与优化以及实际应用场景,并分析了经典的 Embedding 案例和与其他 AI 技术的关系。最后,提供了根据数据类型、应用场景和计算资源选择合适的 Embedding 技术的指南。通过全面了解和应用 Embedding 技术,我们可以在各种 AI 任务中实现更高效和准确的数据处理,从而推动人工智能的发展和应用
接下去,看你的了,大侠!
- 科研为国分忧,创新与民造福 -

日更时间紧任务急,难免有疏漏之处,还请大侠海涵 内容仅供学习交流之用,部分素材来自网络,侵联删
[ 算法金,碎碎念 ]
全网同名,日更万日,让更多人享受智能乐趣
如果觉得内容有价值,烦请大侠多多 分享、在看、点赞,助力算法金又猛又持久、很黄很 BL 的日更下去;
同时邀请大侠 关注、星标 算法金,围观日更万日,助你功力大增、笑傲江湖