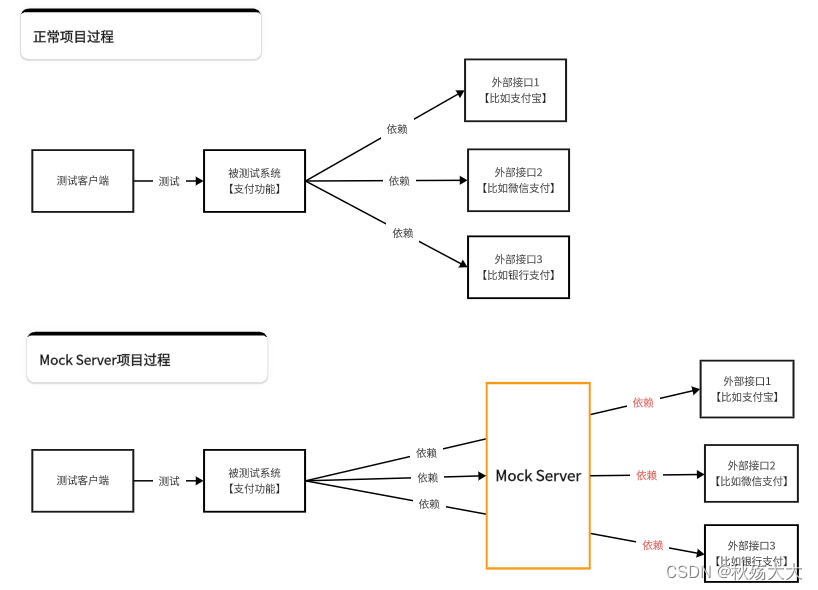
YOLO (You Only Look Once) 是一种高效的目标检测算法,它以速度和精度著称。YOLO 的工作原理是将目标检测视为一个回归问题,直接从图像的像素空间预测目标的类别和位置。YOLO 目标检测头包括以下几个关键部分:
-
输入图像处理:
- YOLO 接受大小固定的输入图像(如 416x416 或 608x608)。
- 输入图像会被分成一个 SxS 的网格(如 13x13, 19x19)。
-
特征提取器:
- 通常使用一个卷积神经网络(如 Darknet)来提取图像的特征。
- 特征提取器的输出是一个特征图,该特征图的尺寸比输入图像小得多,但保留了图像中的关键信息。
-
检测头:
- 检测头的输入是特征提取器的输出特征图。
- 每个网格单元预测 B 个边界框,每个边界框由 5 个参数(x, y, w, h, confidence)和 C 个类别概率组成。
- x 和 y 是边界框中心相对于网格单元的位置。
- w 和 h 是边界框的宽度和高度,相对于整个图像。
- confidence 是边界框中包含目标的置信度。
- C 个类别概率用于表示该边界框属于每个类别的概率。
- 因此,检测头的输出尺寸为 SxSx(B*(5+C))。
-
损失函数:
- YOLO 的损失函数包括三个部分:
- 位置损失(Localization Loss):预测的边界框与真实边界框之间的差异。
- 置信度损失(Confidence Loss):预测的置信度与实际是否包含目标的差异。
- 分类损失(Classification Loss):预测的类别概率与实际类别的差异。
- YOLO 的损失函数包括三个部分:
-
非极大值抑制(NMS):
- YOLO 可能会产生多个重叠的边界框,为了去除冗余,使用非极大值抑制(NMS)来过滤掉置信度较低的框,保留置信度最高的框。
具体细节如下:
-
输入图像处理:
- 图像被调整到一个固定的大小,并标准化处理。
- 图像被划分为 SxS 的网格,每个网格单元负责检测一个特定区域内的目标。
-
特征提取器(例如 Darknet-53):
- 由一系列的卷积层、池化层和激活函数(如 ReLU 或 Leaky ReLU)组成。
- 输出一个特征图,这个特征图包含了图像的空间特征。
-
检测头:
- 在 YOLOv3 中,使用了多尺度检测,分别在三个不同的尺度上进行预测。
- 每个尺度的检测头会输出不同大小的特征图(例如 13x13、26x26、52x52),每个特征图的每个单元预测多个边界框。
-
边界框预测:
- 每个网格单元预测 B 个边界框,每个边界框包含 4 个位置参数(tx, ty, tw, th)、1 个置信度、以及 C 个类别概率。
- 使用以下公式将网络的输出转换为实际边界框坐标:
- bx = σ(tx) + cx
- by = σ(ty) + cy
- bw = pw * e^tw
- bh = ph * e^th
- 其中 (cx, cy) 是网格单元的左上角坐标,pw 和 ph 是预测框的预设宽度和高度。
-
损失函数:
- YOLO 的损失函数由位置误差、置信度误差和分类误差组成。
- 使用均方误差(MSE)计算位置误差。
- 使用交叉熵损失(Cross-Entropy Loss)计算分类误差。
-
后处理(如非极大值抑制):
- 通过非极大值抑制(NMS)去除冗余的边界框,只保留最可信的检测结果。
以上是 YOLO 目标检测头的详细解析,如果你有更具体的问题或需要进一步的细节,可以继续提问。
YOLO检测头的输出尺寸为SxSx(B(5+C))。这是通过分析YOLO的设计和预测目标检测框的方式得出的。下面是详细的解释:*
-
网格划分(Grid Division):
- 输入图像被划分为一个SxS的网格。例如,假设输入图像大小为 416x416,YOLO可能会将其划分为一个 13x13 或 19x19 的网格。
- 每个网格单元负责预测该单元内是否有目标,以及目标的具体信息。
-
每个网格单元的预测:
- 每个网格单元预测 ( B ) 个边界框。典型的值为 ( B = 2 ) 或 ( B = 3 )。
- 每个边界框包含5个预测参数和C个类别概率。
-
边界框参数:
- 5个预测参数分别为:
- ( x ) 和 ( y ):边界框中心相对于网格单元的位置偏移。
- ( w ) 和 ( h ):边界框的宽度和高度,相对于整个图像的比例。
- ( confidence ):该边界框包含目标的置信度。
- 5个预测参数分别为:
-
类别概率:
- 每个边界框预测C个类别概率,即该框属于每个类别的概率分布。
- 因此,对于每个边界框,我们需要预测 ( 5 + C ) 个值。
-
总输出:
- 对于每个网格单元,预测 ( B ) 个边界框,每个边界框包含 ( 5 + C ) 个值。
- 因此,每个网格单元的输出尺寸为 ( B x (5 + C) )。
将这些结合起来,整个输出特征图的尺寸为 SxSx(B*(5+C))。
具体例子
假设我们使用YOLOv3,输入图像被划分为 13x13 的网格,B=3,C=80(例如在COCO数据集上):
-
网格划分:
- ( S = 13 ),输入图像被划分为 13x13 的网格。
-
每个网格单元的预测:
- 每个网格单元预测3个边界框。
- 每个边界框包含 ( 5 + 80 ) 个值(x, y, w, h, confidence + 80个类别概率)。
-
总输出:
- 每个网格单元的输出尺寸为 ( 3 x (5 + 80) = 3 x 85 = 255 )。
- 因此,整个输出特征图的尺寸为 ( 13 x 13 x 255 )。
YOLO检测头的输出尺寸为 ( S x Sx (B x (5 + C)) ) 是通过考虑每个网格单元的预测边界框数量、每个边界框的参数数量以及类别数量计算得出的。这种设计使得YOLO能够在单次前向传递中完成目标检测。
在YOLO中,边界框预测是通过将网络的输出转换为实际的边界框坐标来实现的。以下是详细的解释和一个例子:
详细解释
-
输出预测:
- 每个网格单元预测B个边界框,每个边界框包含4个位置参数(( t_x, t_y, t_w, t_h ))、1个置信度、以及C个类别概率。
- ( t_x ) 和 ( t_y ) 是相对于网格单元左上角的偏移,范围在0到1之间。
- ( t_w ) 和 ( t_h ) 是边界框宽度和高度的对数尺度。
-
转换公式:
- 将网络输出的4个位置参数转换为实际的边界框坐标。
- ( b_x = S(t_x) + c_x ):边界框中心的x坐标。( S) 是sigmoid函数,将输出限制在0到1之间。( c_x ) 是网格单元左上角的x坐标。
- ( b_y = S(t_y) + c_y ):边界框中心的y坐标。( c_y ) 是网格单元左上角的y坐标。
- ( b_w = p_w x e^{t_w} ):边界框的宽度。( p_w ) 是预设的宽度锚点。
- ( b_h = p_h x e^{t_h} ):边界框的高度。( p_h ) 是预设的高度锚点。
举例
假设我们有一个13x13的网格,输入图像大小为416x416,使用了3个边界框预测(B=3),每个边界框的锚点宽度和高度分别为(pw, ph)。
-
假设网格单元 (i, j):
- 该网格单元的左上角坐标为 (i, j)。
- 假设 i=5, j=7,那么 ( c_x = 5 ), ( c_y = 7 )。
-
预测参数:
- 网络输出的预测参数 ( t_x = 0.5 ), ( t_y = 0.6 ), ( t_w = -0.2 ), ( t_h = 0.3 )。
- 锚点宽度和高度分别为 ( p_w = 1.2 ), ( p_h = 1.8 )。
-
转换实际边界框坐标:

-
实际边界框坐标:
- 边界框中心坐标: ( (5.622, 7.645) )
- 边界框宽度和高度: ( (0.982, 2.428) )
解释关键点
- Sigmoid函数:用来将 ( t_x ) 和 ( t_y ) 的输出值限制在0到1之间,这样它们可以表示相对于网格单元的偏移量。
- 指数函数:用来将 ( t_w ) 和 ( t_h ) 的对数尺度转换为实际的边界框宽度和高度,锚点宽度和高度是预设的,表示预测框的基本尺度。
完整公式

通过这些公式,YOLO可以将网络输出的预测参数转换为实际的边界框坐标,用于目标检测。
YOLO 的损失函数由三个主要部分组成:位置损失(Localization Loss)、置信度损失(Confidence Loss)和分类损失(Classification Loss)。以下是每个部分的详细解释及举例:
1. 位置损失(Localization Loss)

2. 置信度损失(Confidence Loss)

3. 分类损失(Classification Loss)

损失函数的总和
总损失函数是位置损失、置信度损失和分类损失的总和。
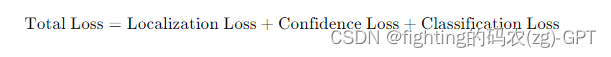
举例
假设一个13x13的网格,B=2,C=3(例如3个类别:猫、狗、鸟)。输入图像大小为416x416,锚点宽度和高度分别为(pw, ph)。
假设:
- 真值(ground truth)边界框中心点 (bx_gt, by_gt) = (5.5, 7.2),宽度和高度 (bw_gt, bh_gt) = (2.0, 3.0),类别为猫(类别索引0)。
- 预测边界框中心点 (bx, by) = (5.6, 7.1),宽度和高度 (bw, bh) = (2.1, 2.9),置信度 = 0.8,类别概率 [0.7, 0.2, 0.1](分别对应猫、狗、鸟)。
位置损失:
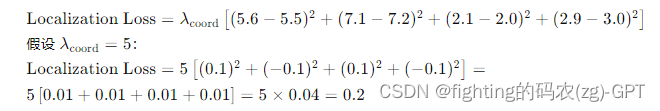
置信度损失:
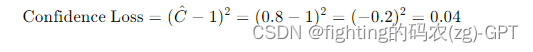
分类损失:

总损失:
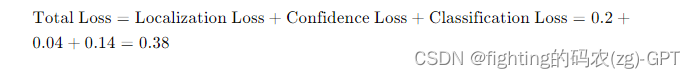
通过这些计算,可以看到如何从YOLO的预测结果和真值计算出总损失。这些损失会用于反向传播,以优化YOLO网络的参数,使得模型预测的边界框和类别越来越准确。
非极大值抑制(NMS)是一种在目标检测中常用的后处理技术,用于去除多余的检测框。YOLO 在预测过程中,可能会生成多个重叠的边界框,这些边界框可能会对同一个目标进行多次检测。NMS 的目标是通过保留置信度最高的边界框,去除那些冗余的、置信度较低的边界框,从而精简检测结果。
NMS 的工作原理
-
输入:
- 一组边界框,每个边界框包括坐标(x, y, w, h)和一个置信度分数。
-
步骤:
- 按置信度排序:将所有边界框按照置信度分数从高到低排序。
- 选取最高置信度框:选取置信度最高的边界框,称之为
A,并将其加入最终的检测结果中。 - 计算重叠区域:计算
A与剩余边界框之间的重叠区域(IoU,Intersection over Union)。 - 移除重叠框:移除与
A的重叠程度超过某一阈值的边界框(例如 IoU > 0.5)。 - 重复步骤:从剩余的边界框中再次选取置信度最高的框,并重复上述过程,直到所有的框都处理完毕。
-
输出:
- 经过筛选后的边界框集合,每个边界框代表一个独立的目标检测。
举例
假设我们有5个边界框,它们的置信度和坐标如下:
| 框ID | 置信度 | x | y | w | h |
|---|---|---|---|---|---|
| A | 0.9 | 30 | 40 | 50 | 60 |
| B | 0.8 | 32 | 42 | 48 | 58 |
| C | 0.75 | 28 | 38 | 52 | 62 |
| D | 0.6 | 100 | 200 | 30 | 40 |
| E | 0.4 | 29 | 39 | 51 | 61 |
步骤1:按置信度排序
排序后的边界框为:A, B, C, D, E
步骤2:选取置信度最高的框A
将边界框A加入最终检测结果中。
步骤3:计算重叠区域(IoU)
计算A与剩余边界框(B, C, D, E)之间的IoU:
- IoU(A, B)
- IoU(A, C)
- IoU(A, D)
- IoU(A, E)
假设计算的IoU如下:
- IoU(A, B) = 0.85
- IoU(A, C) = 0.8
- IoU(A, D) = 0.0
- IoU(A, E) = 0.82
步骤4:移除重叠框
设定阈值为0.5,移除IoU超过0.5的框(B, C, E),仅保留框D。
步骤5:重复步骤
- 从剩余的框中选取置信度最高的框,即D。
- 将D加入最终检测结果中。
- D没有与其他框重叠的情况,结束过程。
最终结果
经过NMS后的最终检测结果为:
- 框A(置信度0.9,坐标[30, 40, 50, 60])
- 框D(置信度0.6,坐标[100, 200, 30, 40])
代码示例(Python)
下面是一个使用Python实现NMS的简单代码示例:
import numpy as np
def iou(box1, box2):
x1, y1, w1, h1 = box1
x2, y2, w2, h2 = box2
xi1 = max(x1, x2)
yi1 = max(y1, y2)
xi2 = min(x1 + w1, x2 + w2)
yi2 = min(y1 + h1, y2 + h2)
inter_area = max(0, xi2 - xi1) * max(0, yi2 - yi1)
box1_area = w1 * h1
box2_area = w2 * h2
union_area = box1_area + box2_area - inter_area
return inter_area / union_area
def non_max_suppression(boxes, scores, iou_threshold):
idxs = np.argsort(scores)[::-1]
selected_idxs = []
while len(idxs) > 0:
current = idxs[0]
selected_idxs.append(current)
idxs = idxs[1:]
idxs = [i for i in idxs if iou(boxes[current], boxes[i]) < iou_threshold]
return selected_idxs
# Example usage:
boxes = [[30, 40, 50, 60], [32, 42, 48, 58], [28, 38, 52, 62], [100, 200, 30, 40], [29, 39, 51, 61]]
scores = [0.9, 0.8, 0.75, 0.6, 0.4]
iou_threshold = 0.5
selected_idxs = non_max_suppression(boxes, scores, iou_threshold)
print("Selected boxes after NMS:", [boxes[i] for i in selected_idxs])
总结
非极大值抑制(NMS)通过保留置信度最高的边界框并移除重叠的置信度较低的边界框,有效地去除了冗余检测框,使得目标检测结果更加精简和准确。
下面是iou函数的详细理论计算过程:
Intersection over Union (IoU) 的计算
IoU 是衡量两个边界框重叠区域与它们的联合区域之间比值的一种指标。计算过程分为以下几步:


代码详细注释
def iou(box1, box2):
# 获取第一个边界框的坐标和尺寸
x1, y1, w1, h1 = box1
# 获取第二个边界框的坐标和尺寸
x2, y2, w2, h2 = box2
# 计算交集区域的左上角坐标
xi1 = max(x1, x2)
yi1 = max(y1, y2)
# 计算交集区域的右下角坐标
xi2 = min(x1 + w1, x2 + w2)
yi2 = min(y1 + h1, y2 + h2)
# 计算交集区域的宽度和高度(确保交集宽高不为负)
inter_width = max(0, xi2 - xi1)
inter_height = max(0, yi2 - yi1)
# 计算交集区域的面积
inter_area = inter_width * inter_height
# 计算两个边界框的面积
box1_area = w1 * h1
box2_area = w2 * h2
# 计算联合区域的面积
union_area = box1_area + box2_area - inter_area
# 计算 IoU(交集面积 / 联合面积)
return inter_area / union_area
举例
假设有两个边界框:
- 边界框1:左上角坐标为(2, 3),宽度和高度分别为4和5。
- 边界框2:左上角坐标为(3, 4),宽度和高度分别为5和6。
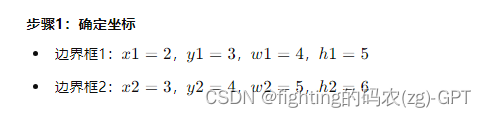


通过这些步骤,我们计算出了两个边界框之间的 IoU 值为约 0.316。这表示两个边界框的重叠区域占它们联合区域的 31.6%。

![【2024最新华为OD-C/D卷试题汇总】[支持在线评测] LYA的登山之旅01(100分)- 三语言AC题解(Python/Java/Cpp)](https://img-blog.csdnimg.cn/direct/a0cba96c424c44a5b0b9d39dfc13abb4.png)