背景
AI模型规模不断剧增已是不争的事实。模型参数增长至百亿、千亿、万亿甚至十万亿,大模型在算力推动下演变为人工智能领域一场新的“军备竞赛”。
这种竞赛很大程度推动了人工智能的发展,但随之而来的能耗和端侧部署问题限制了大模型应用落地。2022达摩院十大科技趋势指出,“大模型参数竞赛正进入冷静期,大小模型将在云边端协同进化”。
大模型向边、端的小模型输出模型能力,小模型负责实际的推理与执行,同时小模型再向大模型反馈算法与执行成效。
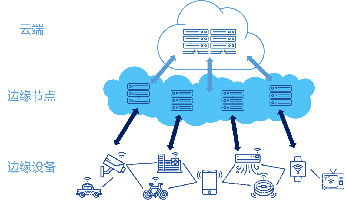
历史上计算形态经历了几次重要变化:
当本地计算成本低于通信成本时,计算模式由分时共享机制迅速转变为本地计算完成方式;当网络技术进步使得通信成本远低于计算成本时,开始出现由本地计算向云计算的过渡。
随着硬件成本降低、计算能力提升、通信带宽飞跃、传感器感知能力进化等技术进步持续发生,传统计算长久以“算力为王”的模式来部署完成,即任务汇聚到大型机上集中处理,而后分散到用户终端设备处理,再然后相当一部分的计算任务重新汇聚到云计算中心处理。尤其是5G/6G通信技术的出现和萌芽,将进一步大幅降低通信成本。
然而,随着物联网技术的爆发,本地计算需求指数级持续涌现,将全部的计算和数据均交由集中式的云计算中心来处理并不现实,更合理的是既充分发挥云计算优势、又调动端计算敏捷性,形成端边云协同的新计算模式。
大模型结合小模型
主要有以下几个思路:
1、 模型压缩
模型压缩技术旨在减小深度学习模型的大小而不显著牺牲其性能。这可以通过剪枝、量化和知识蒸馏等多种方法实现。通过压缩大型模型,可以使它们更适合在资源有限的设备上部署或在小数据集上训练。
参考论文
Model Compression:An Evaluation of Model Compression & Optimization Combinations
「论文简述:」本文旨在探索模型压缩领域的各种可能性,讨论不同级别的剪枝和量化的组合效率,并提出一种质量测量指标,以客观地决定哪种组合在最小化准确性差异和最大化大小减小因子方面最佳。
1.1 知识蒸馏
以大模型为teacher、小模型为student,通过数据蒸馏或者logits蒸馏等蒸馏方法,将大模型某方面的能力转移到小模型上。
用大模型去训练数据,然后用小模型去拟合大模型的输出,小模型可以学习大模型的知识(古已有之的线路是,以大模型为teacher对小模型进行知识蒸馏(KD),以期用更小的模型学会大模型涌现出的能力,提高推理效率)
具体步骤:
首先需要一个性能优秀的大模型作为教师模型,让其学习数据并产生预测结果;
然后将这个大模型的输出概率向量作为软目标,称之为“soft targets”;
接着训练一个小模型,我们称其为学生模型,让学生模型去尽量拟合这些软目标;
最后在一些验证集或者测试集上评估学生模型的性能。
参考论文:
- Distilling the Knowledge in aNeural Network
提取神经网络中的知识
「论文简述:」一种简单的方法是训练多个不同的模型,然后平均它们的预测结果来提高机器学习算法的性能。然而,使用整个模型集合进行预测可能会变得繁琐和计算密集。Caruana和他的合作者提出了将知识压缩到一个单一模型中的方法,这种方法更容易部署。他们通过将模型集合的知识蒸馏到一个单一模型中,显著提高了商用系统的声学模型性能。他们还引入了一种由完整模型和专家模型组成的新型集成方法,这些专家模型可以快速并行地训练,用于区分完整模型混淆的细粒度类别。
- 代码下载
蒸馏的方法可以是数据蒸馏,即用大模型生成的文本数据训练小模型
参考论文:
Alpaca: A Strong, Replicable Instruction-Following Model
- 论文下载
- 代码下载
用GPT3.5生成的数据继续训练Llama-7b
logits蒸馏:即对同一对输入输出,让小模型模仿大模型输出的概率分布
参考论文:
微软的MiniLLM,MiniLLM有意思的地方是,提出把普通KD的KL散度loss°的两个项反过来(MReverseKLD),
- 论文下载:Knowledge Distillation of Large Language Models
- 代码下载
1.2 剪枝大模型
训练一个大模型,然后通过剪枝的方法压缩模型,去掉冗余的结构和参数,得到一个更小但精度依然高的模型
参考论文:
论文下载:Pruning Filters for Efficient ConvNets
剪枝过滤器以获得高效的卷积神经网络
代码下载
「论文简述:」本文介绍了一种加速卷积神经网络(CNN)的方法,即通过剪枝对网络影响较小的过滤器来减少计算成本。与权重剪枝不同,这种方法可以在整个网络中删除整个过滤器及其连接的特征图,从而显著降低计算成本。由于不需要稀疏卷积库的支持,因此该方法可以与现有的高效BLAS库一起使用。实验表明,即使在简单的过滤器剪枝技术下,VGG-16和ResNet-110在CIFAR10上的推理成本也可以分别降低34%和38%,并且通过重新训练网络可以获得接近原始精度的结果。
1.3 模型蒸馏
用大模型蒸馏出小模型实现降本
参考论文:
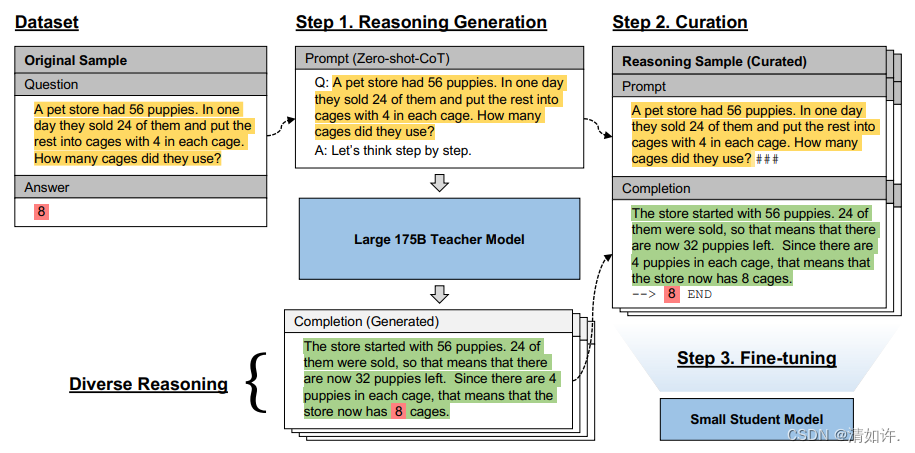
- 论文下载:Large Language Models Are Reasoning Teachers
- 代码下载
这篇论文提供了一个思路借助思维链(CoT)逐步解决复杂推理任务的能力,可以使用大模型作为推理教师,针对一批数据集,让大模型给出详尽的解答思路,然后把问题和解题过程交给学生模型进行 Fine-tuning。这个解决思路也有一个专有名词,叫做“模型蒸馏”,其效果还是非常亮眼的,在保持同样的推理能力,甚至超越大模型的情况下,模型的大小降低到原来的 1/500~1/25。这可以帮助很多特定场景降低成本,例如使用自建的蒸馏小模型替代直接调用 ChatGPT,很多简单场景都适用,如果蒸馏出来的模型足够小,还可以直接在端侧(移动设备或嵌入式系统)部署,在用户本地完成推理,进一步降低服务成本
2、联合推理:小模型杀鸡,大模型宰牛
在一个系统里集成大模型和小模型,用小模型处理简单的输入、大模型处理复杂的输入,提高整个系统的效率
基本思路是,一个系统里既有参数少速度快、性能低的小模型,又有参数多、速度慢、性能高的大模型,用小模型处理简单的任务,它处理不了的任务才交给大模型处理,以此提高整个系统的效率。这个”小刀杀鸡,大刀宰牛“的思路非常直观,其核心就是要怎么定义”简单“和”复杂“的”任务“,让大小模型各得其所、各尽所能。下面是两个有代表性的具体方法:
2.1 模型串联✳
所有样本先过小模型,根据小模型的置信度(如softmax概率或者熵)判断样本的难易程度,对置信度高的”简单样本“直接输出小模型的预测,置信度低的”困难样本“才交给大模型来处理。这个方法可以追溯到BERT时代的CascadeBERT
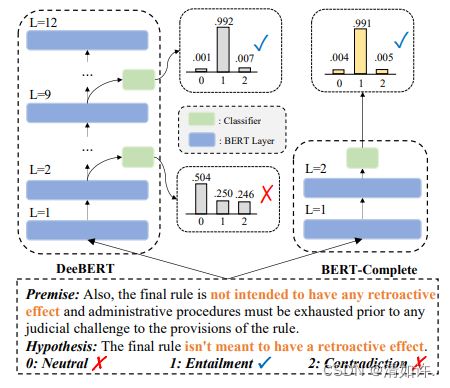
参考论文:
论文下载:CascadeBERT: Acceleratingnference of Pre-trained Language Models viaCalibrated Complete Models Cascade
代码下载
2.2 投机采样:
参考论文:
论文下载:Fast inference from transformers via speculative decoding
代码下载
它的思路是在某个生成的timestep,把自回归生成这个耗时的过程交给小模型(或者大模型的底下几层,我们统称为小模型),小模型采样生成几个候选序列,再把它们拼在一起输给大模型,让大模型选择language modeling概率最高的那个候选序列。
这里要注意的是,这几个候选序列输给大模型的时候要修改相应的attention mask(即Medusa的Tree Mask):
Medusa: Simple framework for accelerating LLM generation with multiple decoding heads
代码下载
3、权值共享
在小模型中共享大模型中部分层的权值,比如可以共享低层的特征提取层,然后在高层重新训练适合小模型的权值。参考论文:
Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks viaAttention Transfer
论文下载
代码下载
4、迁移学习
使用大模型预训练的权值来初始化小模型,然后基于小模型的任务重新进行微调,这种方法可以快速得到一个性能不错的小模型。
它涉及利用预训练的大型模型来构建小数据集上的模型。迁移学习允许从大型数据集转移知识到较小的数据集,从而提高小数据集上的模型性能。这在可用于训练的数据有限时特别有用。通过使用预训练的模型作为起点,小型模型可以从大型模型学到的特征和表征中受益。

参考论文:
A Simple Framework for Contrastive Learning of Visual Representations
论文下载
代码下载
Cross-property deep transfer learning framework for enhanced predictive analytics on small materials data
论文下载
5、将小模型作为插件
参考论文:
Small Models are Valuable Plug-ins for Large Language Models
论文下载
代码下载
背景:大型语言模型(LLMs)如GPT3和GPT-4非常强大,但它们的权重通常不公开,并且它们的巨大大小使得这些模型难以使用常见硬件进行调整。由于上下文长度限制,In-Context Learning(ICL)只能使用少量监督示例。
创新点:本文提出了Super In-Context Learning(SuperICL),它允许黑盒LLMs与本地微调的较小模型一起工作,从而在监督任务上获得更好的性能。超级上下文学习(SuperICL)将LLMs与本地微调的较小模型结合起来,使它们可以共同提高监督任务的性能。较小的模型充当插件,提供任务特定的知识和预测,而大型预训练模型则专注于一般语言理解。
效果:SuperICL可以提高性能,超越最先进的微调模型(比独立的大模型和小模型都要好),同时解决上下文学习的不稳定性问题。此外,SuperICL可以增强较小模型的能力,例如多语言性和可解释性。
步骤:SuperICL分为以下三个步骤:
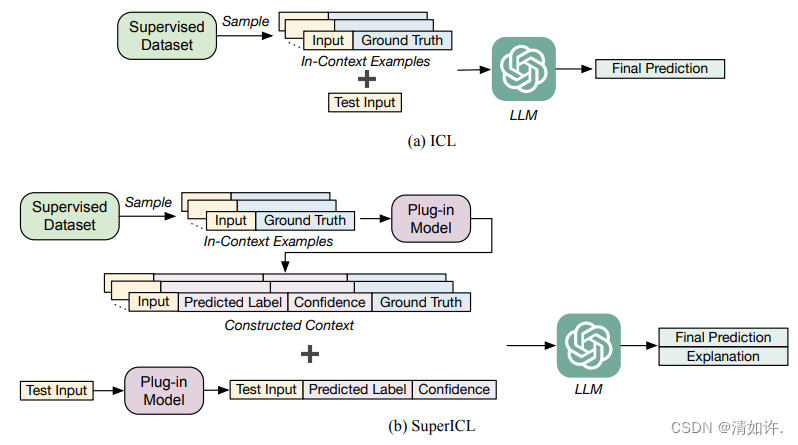
插件模型微调:
首先在具体任务上使用训练数据微调出一个小模型(例如RoBERTa),作为插件模型。
上下文构建:
然后利用小型模型提供的任务特定知识,为大模型构造上下文。该上下文包括从训练数据中随机抽取的一组示例,以及它们对应的小型插件模型的预测结果(包括预测的标签及其置信度分数)。
推理:
构造出上下文后,对于一条实际输入,插件模型的预测结果,包括的标签和置信度分数将与上下文连接起来,形成大型语言模型的完整输入。然后,LLM生成最终预测结果和对预测结果的解释。
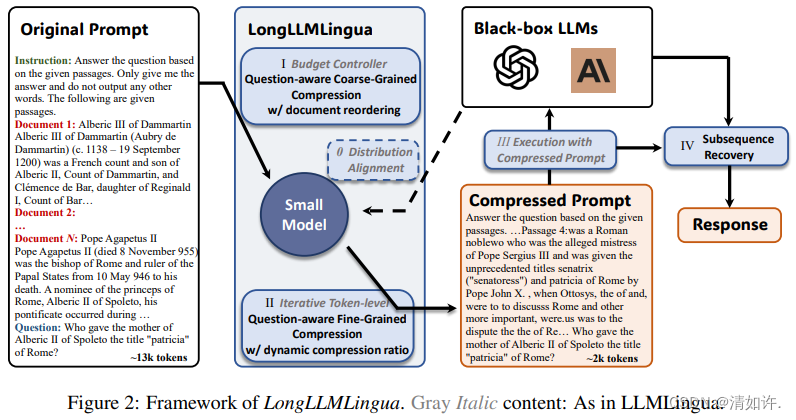
6、提示语压缩
通过一个小模型对提示语进行压缩
参考论文:
LongLLMLingua:ACCELERATING ANDLLMS IN LONG CONTEXT SCENARIOS VIA PROMPTCOMPRESSION
项目下载
论文下载
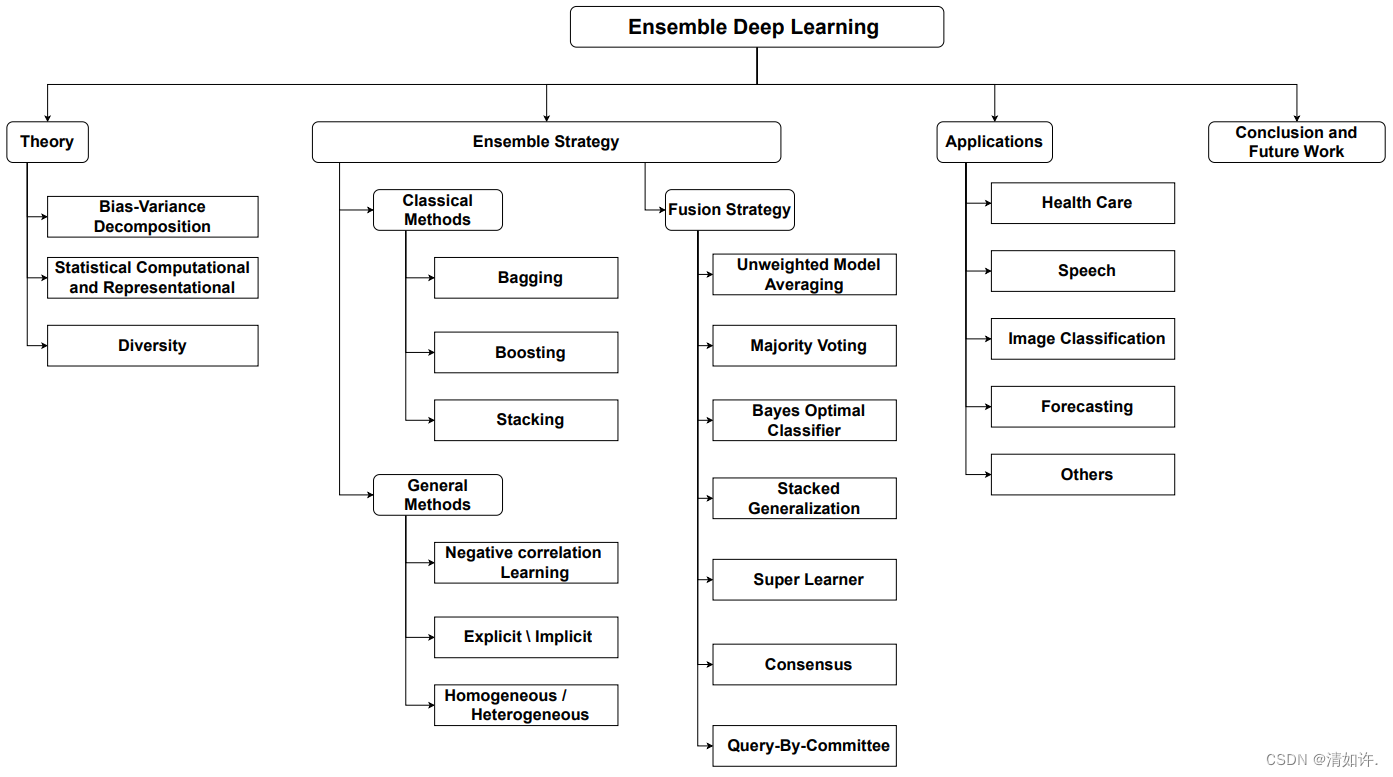
7、集成学习
通过集成学习之类的技术可以实现将大型模型与小型模型结合。集成学习涉及结合多个模型进行预测。通过将大型模型与小型模型结合,可以利用两者的优势来提高整体性能。这可以通过模型平均或堆叠等技术来实现。
参考论文:
Ensemble deep learning: A review
论文下载
8、其他:
参考论文:
8.1 SuperContext: WU等提出大小模型结合新思路
论文下载
论文提出了一个简单而有效的框架SuperContext,通过整合小型、有监督的语言模型(SLMs)的输出,来增强LLMs的可靠性,特别是在处理分布外数据和减少生成任务中的幻觉方面。这一方法为开发更可靠、泛化能力更强的LLMs提供了新的思路。
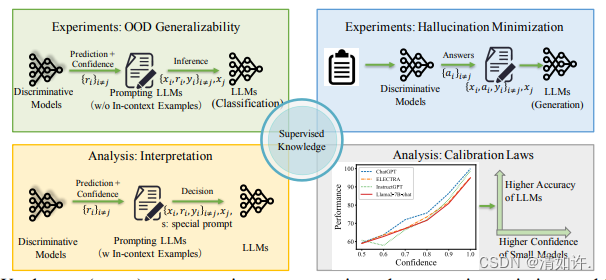
方法
传统ICL:基于假设,即LLMs在给定的上下文示例和任务特定数据的条件下,生成响应的概率是近似不变的。
SuperContext:在传统ICL的基础上,在推理阶段将SLMs的预测和置信度作为额外的提示信息插入到问题-答案对之间。
步骤
微调SLMs:在领域内数据集上微调SLMs。
测试SLMs:在测试集上使用微调后的SLMs进行预测。
整合输出:将SLMs的预测、置信度和特殊提示插入到LLMs的提示中。
推理:使用LLMs进行推理,输出预测结果。
8.2 投机式推理:「投机式推理」引擎SpecInfer
可以借助于轻量化的小模型帮助大模型,在完全不影响生成内容准确度的情况下,实现两到三倍的推理加速。
论文下载
项目主页
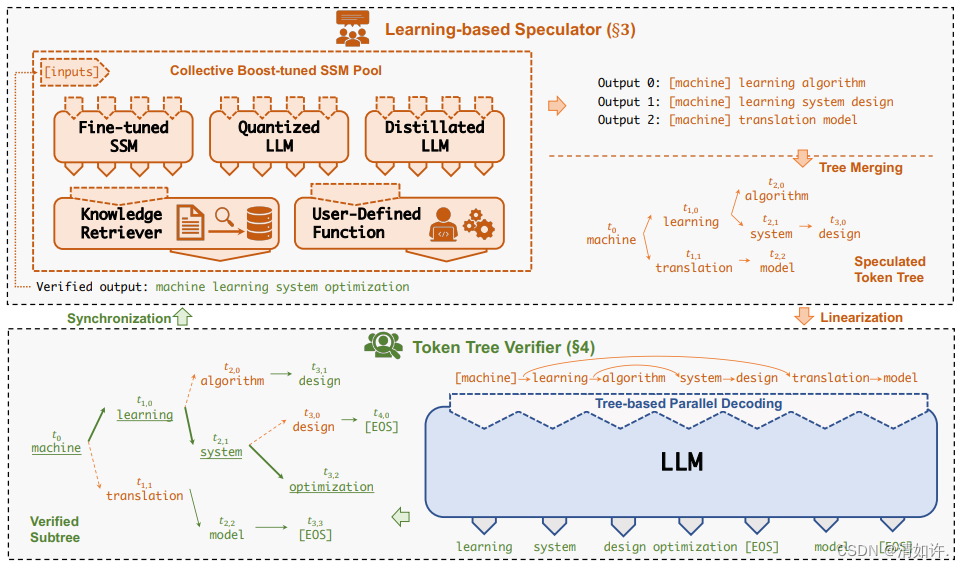
研究者提出了一种「投机式」推理引擎SpecInfer,其核心思想是通过计算代价远低于LLM的“小模型”SSM(Small Speculative Model)替代LLM进行投机式地推理(Speculative Inference),每次会试探性地推理多步,将多个SSM的推理结果汇聚成一个Speculated Token Tree,交由LLM进行验证,通过高效的树形解码算子实现并行化推理,验证通过的路径将会作为模型的推理结果序列,进行输出。
总体上来说,SpecInfer利用了SSM的内在知识帮助LLM以更低廉的计算成本完成了主要的推理过程,而LLM则在一定程度上破除了逐token解码的计算依赖,通过并行计算确保最终输出的结果完全符合原始的推理语义。
8.3 大模型辅助小模型
大模型在各方面的表现都还可以,但是在很多垂直领域反而是一种浪费,因为很多时候我们并不需要它是个通才,只需要专注于特定任务。今天分享一篇文章,主要思想就是借助LLM来辅助训练一个特定任务的小模型。
论文标题:《PROMPT2MODEL: Generating Deployable Models from Natural Language Instructions》
论文下载
代码下载
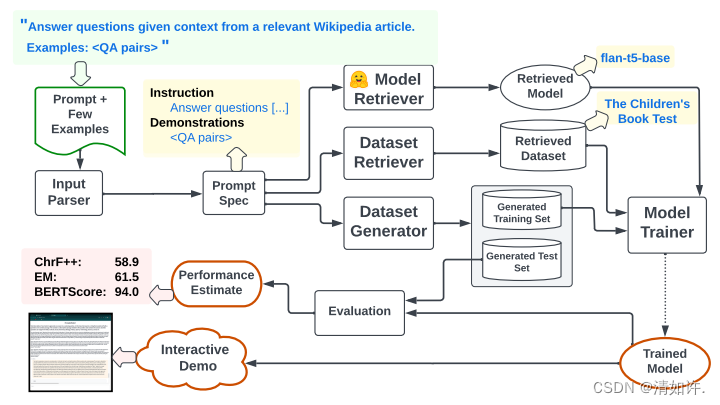
本文提出了一种名为Prompt2Model的框架,它可以接受自然语言任务描述,然后训练一个特定目的且便于部署的模型。该方法结合了检索现有数据集、预训练模型、使用LLM生成数据集,并在这些数据上进行微调。实验结果显示,与gpt-3.5-turbo相比,Prompt2Model训练的模型性能提高了20%,但模型大小减少了700倍。
9 应用场景
把大模型和小模型相结合,常见应用场景:
1.自然语言处理
通过使用预训练的大模型 (如BERT、GPT-3等) 作为特征提取器或生成器,然后在下游任务 (如文本分类、问答、文本生成等)上进行微调或融合,可以提高小模型的效果和效率
2.计算机视觉
通过使用预训练的大模型 (如ResNet、VGG等) 作为特征提取器或分类器,然后在下游任务 (如目标检测、人脸识别、图像分割等) 上进行微调或融合,可以提高小模型的效果和效率
3.多模态学习
通过使用预训练的大模型 (如CLIP、DALL-E等)作为多媒体信息的编码器或生成器,然后在下游任务 (如图像检索、图像描述、图像生成等) 上进行微调或融合,可以提高小模型的效果和效率。