本文探讨了乳腺组织显微图像的分类问题。根据主要的癌症类型,目标是将图像分为四类:正常、良性、原位癌和浸润性癌。给定合适的训练数据集,利用深度学习技术来解决分类问题。由于训练数据集中每个图像的大小很大,提出了一种基于patch的技术,该技术由两个连续的卷积神经网络组成。第一个“patch-wise”网络作为自动编码器,提取图像patch中最显著的特征,而第二个“image-wise”网络对整个图像进行分类。第一种网络经过预训练,旨在提取局部信息,第二种网络获取输入图像的全局信息。使用ICIAR 2018年乳腺癌组织学大挑战(BACH)数据集训练网络。与先前文献中报道的77%的准确率相比,所提出的方法在验证集上产生95%的准确率。
1. 引言
在活组织检查中,通过手术取出组织样本进行分析。这可以表明哪些细胞癌变,如果癌变,这些细胞与哪种类型的癌症有关。活检标本的显微成像数据体积大,性质复杂。因此,病理学家在组织病理学癌症诊断方面面临着大量的工作量增加。
近年来,深度学习技术的出现解决了医学图像处理领域的许多问题。提出了一种基于深度卷积神经网络(CNN)的乳腺癌组织图像分类方案。当输入是高维数据(如图像)时,卷积网络被认为是分类问题的最新技术。这些网络“学习”从图像中提取局部特征,并根据提取的特征对输入进行分类。显微镜图像的尺寸非常大,由于硬件障碍,文献[3,4,5]中提出了几种基于patch的CNN方法,将输入图像处理为一组较小的patch。在这些模型中,每个图像被分成更小的补丁,每个补丁被“补丁智能”分类器网络分类并分配给一个标签。
为了在整个图像级别进行分类,在patch-wise网络之后是另一个分类器,该分类器接收来自第一个网络的输出标签作为输入,并生成标签分数。这些技术在图像斑块上实现了高精度和高置信度,然而,它们无法捕获图像的全局属性:一旦所有图像斑块被标记,空间信息被忽略,并且斑块之间可能共享的任何特征都丢失了。
提出了一种新的两阶段卷积神经网络,以一种补丁式的方式,旨在利用输入的局部和全局信息。该方法不需要大量的端到端训练内存占用。在该方案中,补丁智能网络的唯一目的是从每个补丁中提取空间较小的特征映射。经过训练后,该网络将根据图像的局部信息从所有斑块中提取出最显著的特征图。这些特征图堆叠在一起,形成空间上较小的“图像智能”网络的3D输入。该网络基于从图像中提取的局部特征和不同patch之间共享的全局信息对图像进行分类。
使用ICIAR 2018乳腺癌组织学大挑战(BACH)数据集[6]来训练我们的网络,该数据集包含400张苏木精和伊红(H&E)染色的乳腺组织学显微镜图像。模型在验证集上达到了95%的准确率,在分类准确率方面优于[3]。
2. 相关工作
在过去的几年中,已经发表了一些针对使用cnn进行乳腺癌检测和分类的工作[7,8,9,10,11,5,12]。虽然所有这些作品的目的都非常相似,但每个作品都考虑了特定类型的问题。例如,[7,8,9]提出了两类(恶性和良性)分类器。[10,11]中的其他作品考虑了更复杂的3类分类(正常癌、原位癌和浸润癌)。最后,[5,12]制定了乳腺癌的分割方案。 工作在本质上与Ara´ujo等[3]的工作相似。其是第一个考虑乳房组织图像的四类分类器的团队。开发了CNN,然后是支持向量机(SVM)分类器。在他们的技术中,首先将原始图像分成12个连续的不重叠的小块。使用patch-wise训练的CNN和CNN+SVM分类器计算patch类概率。最后,采用三种不同的斑块概率融合方法进行图像分类。这三种方法分别是“majority voting”、“maximum probability”和“sum of probabilities”[3]。
3. 方法
给定一张高分辨率(2048 × 1536)的组织学图像,目标是将图像分为四类:正常组织、良性组织、原位癌和浸润癌。
3.1 基于patch的CNN方法
数据集中图像的高分辨率特性以及从中提取相关歧视性特征的需要,对实现常规前馈卷积网络施加了额外的限制。在高分辨率图像上训练CNN需要非常大的内存占用,这在大多数情况下是不可用的,或者逐步减少图像的空间大小,以便下采样版本可以存储在内存中。然而,对图像进行降采样会增加失去鉴别特征(如细胞核信息及其密度)的风险,从而无法正确区分癌细胞和非癌细胞。此外,如果在大型显微镜图像上进行训练,神经网络可能会学会只依赖最显著的特征,而完全抛弃其他所有特征。
遵循由[3,4,5]提出的patch-wise CNN方法,然后是一个image-wise CNN,将组织学图像分为四类。给定一个显微镜图像,通过在图像上滑动一个大小为k × k的补丁(窗口),步长为s来提取固定大小的补丁。 总共提取了总数为的补丁,其中
和
分别是图像的宽度和高度。选择k = 512的patch大小。还选择了s = 256的步长,得到了7 × 5 = 35个重叠的图像patch。允许重叠对于补丁智能网络学习补丁之间共享的特征是必不可少的。适当的步幅是通过考虑两个网络在一起“工作”时的接受域来选择的。图1概述了我们的两阶段CNN。注意,训练集中的标签仅为整个图像提供,而单个补丁标签是未知的,然而我们使用基于相应显微镜图像标签的分类交叉熵损失来训练补丁智能网络。
这个网络就像一个自动编码器,学习提取图像补丁中最显著的特征。
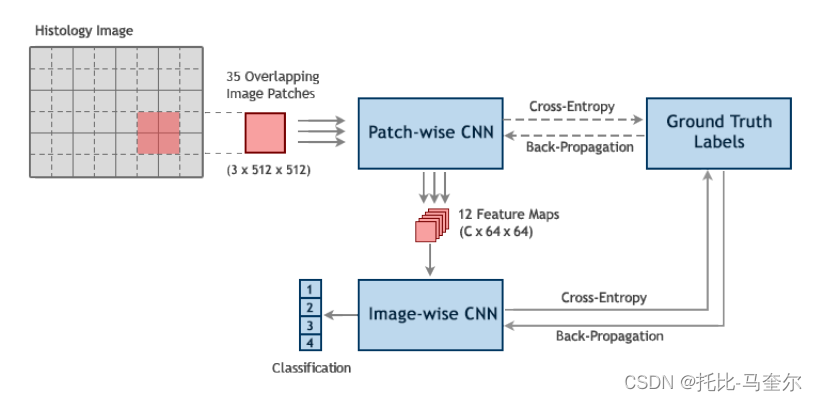
一旦训练完成,丢弃该网络的分类器层,并使用最后一个卷积层从图像中任意数量的补丁中提取大小为(C × 64 × 64)的特征映射,其中C是我们提出的系统中的另一个超参数,它控制输出特征映射的深度。
CNN是在图像块上训练的。从所有图像补丁中提取的特征映射叠加在一起,传递给第二个CNN,后者学习预测图像级标签。
3.2 网络体系架构
使用一系列3 × 3卷积层,然后是池化层,每次下采样后通道数量增加一倍,来设计patch-wise CNN。所有卷积层之后是批处理归一化[14]和ReLU非线性[15]。我们遵循[16]的指导原则,通过使用2的步幅来实现偶尔降维的齐次全卷积网络。在测试中,发现stride为2的2 × 2内核在性能方面优于传统的最大池化层。对于分类任务,不是使用完全连接的层,而是使用1 × 1的卷积层从其下的卷积层获得特征映射的空间平均值,因为置信度类别和结果向量被馈送到softmax层[17]。稍后使用这个特征映射作为图像CNN的输入。为了进一步控制和实验使用空间平均层的效果,引入了另一个控制输出特征图深度的超参数C。批归一化和全局平均池化都是结构性正则器[17,14],它们天生就能防止过拟合。因此,没有在模型中引入任何dropout或权重衰减。总的来说,网络中有16个卷积层,输入在第3层、第6层和第9层被下采样3次。图2展示了所建议的逐补丁网络的总体结构。

对于提出的image-wise网络,遵循类似的模式。一系列3 × 3的卷积层之后是一个2×2卷积,步长为2,用于下采样。每层之后是批归一化和ReLU激活函数。使用与之前相同的1 × 1卷积层来获得分类器之前激活图的空间平均值。卷积层之后是3个完全连接的层,最后是一个softmax分类器。与patch-wise网络不同,过拟合是该网络的主要问题,因此,使用dropout[18]以0.5的比率对该网络进行了大量正则化,并在验证精度没有提高时使用提前停止来限制过拟合。网络架构如图3所示。

最后一个卷积层相对于patch-wise网络的接受野为252[19]。原则上,这个数字必须是在提取patch时可以选择的最大跨距值s,以覆盖输入图像的整个表面。在实验中,s = 256几乎具有相同的精度。大的补丁大小(512 × 512)使网络对s的小变化不变性。注意,s的小值使训练时间变慢,网络容易过度拟合。
4. 实验和结果
数据集由400张高分辨率苏木精和伊红(H&E)染色的乳腺组织学显微镜图像组成,这些图像被标记为正常、良性、原位癌和浸润性癌(每个类别100张图像)。这些图像是从整个幻灯片图像中提取的补丁,并由两位医学专家注释。病理学家之间存在分歧的图像被丢弃。图4突出显示了样本图像中的可变性。
对于卷积网络来说,数据集的大小相对较小。为了防止斑块智能网络过度拟合,对从显微镜图像中提取的斑块进行了一些数据增强。病理图像不具有规范取向,分类问题是旋转不变性的[12,3]。为了扩大数据集,将每个补丁旋转4倍90度,有镜像和没有镜像,这导致每个补丁有8个有效的变化。根据[20]的建议,进一步将随机颜色扰动应用于这些变化,并产生8个以上的斑块。颜色增强过程有助于我们的模型学习颜色不变性特征,使预处理颜色归一化[21]步骤变得不必要。补丁数据集的总大小变成16×35×400。
5. 总结和未来工作
考虑了使用显微组织图像进行乳腺癌分类的问题。利用深度学习技术,提出了一种新的两阶段CNN管道,以克服处理超大图像所带来的硬件限制。第一个所谓的patch-wise网络作用于整个图像的较小的补丁,并输出空间较小的特征图。第二个网络在补丁网络之上运行。它接收来自patch-wise网络的特征映射堆栈作为输入,并生成图像级标签分数。在这个框架中,patch-wise网络负责捕获输入的局部特征,而image-wise网络则学习组合这些特征并找到相邻补丁之间的关系,以全局推断图像的特征并生成类自信分数。