从数据库领域的发展历程来看,分析型数据库已有 40 多年的发展历史,与数据库基本同时代。从OLTP 和 OLAP 的分支来看,分析型数据库支持了海量数据规模下的聚合性分析。尤其是随着移动互联网甚至 AI 等领域的发展,用户画像行为分析的重要性日益凸显,而这些都离不开分析型数据库的支撑。
数据量的增加对分析性能和数据规模增长提出了更高的要求,分布式计算技术应运而生。其最大特点是具备横向 scale out 能力、并行计算 MPP 能力以及 Shared-Nothing 能力。近十年,随着云计算的发展,大家对分布式系统中存算一体、存算绑定、存算耦合的痛点也越来越关注。云原生技术很好地推动分布式系统的迭代,甚至是局部地区或局部领域的重构。

数据库发展历程
ByteHouse则是火山引擎数智平台VeDI旗下的一款云原生数仓产品,以 ClickHouse 技术路线为基础,从2017年内部立项开始,截止到2022年3月,ByteHouse 节点总数已经达到了18,000,最大的行为分析集群超过了2,400个节点,数据量超过700PB。
云数仓/分析平台发展趋势与挑战
高吞吐写入
随着 5G 技术的发展和大模型的应用,数据量呈现爆炸式增长,特别是埋点日志类数据,每天达到百亿甚至千亿级别,一些大规模杀手级应用每天更是产生数千亿的事件量。
这对数据平台的写入能力提出了极高的要求,不仅要支持高吞吐的写入,而且写入过程中还需要实时去重。为了保证数据的高效写入,叠加去重、upsert等能力就成为了关键。以游戏领域为例,如何保证游戏日志数据以每秒几百万的性能进行去重写入,这对数据平台的能力是一个巨大的考验。
高性能、高并发
虽然数据量在不断增长,但业务对性能的要求也越来越高。所有分析查询都需要在毫秒级时间内响应。无论是用户、业务还是广告投放,都需要实时反馈。因此,性能分析必须达到毫秒级响应,秒级响应已经无法满足需求。
此外,高并发也是一个挑战,因为很多系统直接面向 C 端用户,如何确保在几十万甚至上百万级并发情况下仍能保持良好的时延响应,这是一个巨大的挑战。
架构复杂、七国八制
许多规模较大的企业的分析型架构极其复杂,用"七国八制”来形容毫不为过。为了实现一个数据分析功能,可能需要使用三、四个甚至更多的组件来分别构建,这就导致整体架构非常复杂。这不仅带来了数据冗余的弊端,质量难以持久,也给运维带来了很大压力。
不够灵活
不够灵活这一痛点也与前面的架构有关,主要是指过去的存算中,计算和存储的耦合现象严重,无法按需进行弹性伸缩,因此很多用户在扩容时非常担心
此外,存算一体的架构会在扩容过程中对业务产生较大的中断影响,耗时较长。对于规模稍大的企业,例如 TB 级别的系统,在原有架构下进行一次扩容或缩容至少需要半天时间。但现在,业务越来越在线化、实时化,与客户的互动也越来越接近实时化。所以,许多业务无法接受任何中断时间稍长的情况。
成本不可控
成本不可控的痛点主要有三点:
第一,规划系统时,无法按需规划,必须按照峰值系统资源需求进行预购,从而导致资源闲置现象严重。
第二,架构复杂且不够灵活,导致维护人力成本很高。“七国八制”的数据组件支撑不同属性或要求的业务,导致业务开发成本增加。
第三,被厂商锁定导致成本不可控。
云数仓必不可少的五大核心能力
上述五个方面一直是云数仓领域的难题,但同时也为从业者指明了发展方向。从ByteHouse的应用实践中,我们也总结出了云数仓必不可少的五大核心能力。
核心能力一:卓越性能
最为首要且关键的核心能力是性能。在 OLAP 领域,性能是一个永恒的追求。在下图的六个场景中,都存在着各种性能问题。

场景一:实时吞吐慢(IoT)
首先,ByteHouse支持 Upsert的部分列更新能力,这一能力确保在海量数据每秒数百万入库的前提下,数据依然能保持高性能,落盘即更新。其次,ByteHouse自研uniqueMergeTree引擎,为写入即去重提供性能保障,满足了 IoT 场景下的高性能数据写入诉求。此外,ByteHouse自研的 Flink Connector 能够更好地对接 Flink,更有效地满足海量数据的写入需求。
以某畅销游戏公司的实践举例,该公司每秒需要写入 220 万条游戏平台日志数据。换算成数据规模的话,相当于每秒写入约 4GB 的数据。这种写入诉求在实时领域的实时吞吐能力是一个很大的考验。ByteHouse 通过上面介绍的几款自研能力,很好地支撑并满足了这一需求,而且性能还能实现线性增长。
场景二:BI报表慢
大家经常会遇到这些问题,如BI运行慢、报表生成慢、指标平台响应慢以及驾驶舱显示速度慢等。针对这些问题,我们采取了以下措施:
-
在ByteHouse的预聚合功能中,通过增强的MV物化视图和Projection功能,帮助用户对复杂查询和计算逻辑进行预聚合,从而提升应用层的性能表现;
-
增强多层级的Query Cache功能,不仅可以缓存数据,还可以缓存复杂查询中间的结果集;
-
在对接 Kafka层面,我们内置了增强型 Kafka engine,确保 Kafka 以更高效率进行消费。
在某娱乐型公司的案例中,CDC 技术能够支持每天 15 亿记录,其中峰值 TPS 每秒达到 6 万。ByteHouse通过 CDC 技术能够很好地支撑这些数据,并将其快速投放到下游的 BI 系统进行展示,从而使客户的准实时报表的时效性从过去的 t+1 方式直接压缩到分钟级、秒级。
场景三:离/在线复杂分析慢
对于分析领域经常遇到的离线分析/在线复杂分析性能慢的问题,ByteHouse 做了一系列自研优化器增强,包括 CBO、RBO 等,以及在 RBO 中对非等值优化和关联的增强。ByteHouse还做了一些对性能较大的关键算子级优化,如聚合、 Agg/join 算子等。
此外,Runtime Filter 对大关联场景的性能提升非常关键,它能实现动态 Filter,极大地提高大表关联场景的性能。而ByteHouse自研分布式缓存能够进一步解决在分离架构下所带来的性能损失问题。
ByteHouse持续追求的目标是在排除本地缓存的前提下,使存算分离的架构尽可能地接近存算一体的性能。因此,分布式缓存技术显得尤为必要,我们计划在 2025 年上半年将其产品化。
在使用 OLAP 等产品时,用户会遇到一个痛点,即计算速度快,但不能进行批量处理,离/在线无法一体化。在 ETL 方面支撑能力略显不足。而 ByteHouse 很好弥补了这一短板。通过 BSP 这种能力,ByteHouse 实现算子落盘,确保在复杂 ETL 任务中、高并发的情况下依然能够稳定运行。
-
场景四:湖仓联邦分析慢
总所周知,湖仓联邦分析的性能提升一直是业界关注的重点和难点。
ByteHouse 在这方面做了很多提升,比如对于 ORC 和 Parquet 格式,ByteHouse能够通过 Native Reader 技术压缩 IO 访问路径,提升外表访问性能。同时,我们正在研发 DataFebric 能力,通过多表物化能力来加速湖仓访问的性能表现,预计在今年下半年进行产品化。 在外表部分,大家比较关注的是,能否实时地识别大数据外表的模式(schema)变动和数据变动。ByteHouse 则通过一些自研能力,支持识别外表模式,并自动同步。 另外,ByteHouse外表也能与优化器进行融合、适配。优化器会根据代价和统计数据生成最佳执行计划,并进行算子级下推,从而进一步提高湖仓的性能分析速度。 实际上,从性能表现来看,无论是在抖音集团内部还是外部客户场景,ByteHouse外表读性能都比过去十几年常用的 Presto 加对象存储的性能表现提升至少2- 5倍。
-
场景五:人群圈选与行为分析慢
ByteHouse 针对人群分析、人群圈选和行为分析速度较慢所采取的措施,也正是它的优势所在。
抖音集团内部很多圈选和行为分析都是基于 ByteHouse 运行,因此在该方面具备更多经验和优势。在技术层面,ByteHouse 拥有 BitEngine/BitMap64/BitMap indexDe 等自研和增强功能,这些功能的推出时间早于 ClickHouse社区。
其次,ByteHouse与 增长分析DataFinder、行为分析应用和 CDP 客户管理平台等应用的结合很紧密,能提供强大的底层支撑。基于对上层业务的熟悉,ByteHouse针对业务场景开发了许多内置的分析函数,比如常用的留存分析、路径分析等。这些分析函数都内置在 ByteHouse 中,以实现最佳性能表现。目前,分析函数的整体规模已达20-30个。
由于以上增强功能,ByteHouse在人群圈选应用中的性能表现非常出色。即使是 10 亿级的用户圈选, P99 响应时间也能做到秒级或毫秒级。以抖音集团内部的行为分析平台为例,该平台每日处理的数据规模达到万亿级。
-
场景六:以图搜图慢
大模型最近非常火爆,其中舆情分析场景等对性能诉求也越来越高,无论是微博等文字媒体,还是音视频媒体,都给舆情分析带来很大挑战。平台和相关账号运营者,需要更快、更多地发现问题,在问题还没恶化之前对其进行解决。
这里涉及一个关键技术——向量化引擎,ByteHouse也自研向量检索高级特性。向量检索高级引擎内置在 ByteHouse 中,我们主要做了两点:一是,与主流算法库对接;二是,我们的算法要比开源的milvus更丰富。 在性能层面,ByteHouse也做了一系列优化,包括 IO 优化、计算前置、冗余计算消除以及 Vector Index Cache 向量索引缓存等,这些优化措施能够显著提升搜图场景和知识库场景的检索性能表现。
核心能力二:秒级无损弹性

第二个关键的核心能力是弹性。提到云原生,那必讲的就是弹性,这也是用户、行业过去十几年对存算一体、存算耦合架构“诟病”的一点。云原生理念,能够帮助用户解决扩展层问题,使成本更加可控,更具性价比。
云原生技术有几个关键概念,比如serverless、容器化、存算分离等。ByteHouse 是如何综合运用这些技术,实现更出色的性能和弹性呢?
在存储层面, ByteHouse采用 Serverless 架构,具有低成本、无限扩展的能力。
在计算层面,目前有两种不同的实现方式:一种是纯 Serverless 架构,一般存在的问题是,如果在系统中存在一个性能表现不佳的 SQL 语句,那么它一定会拖累整个集群的性能表现,甚至可能导致整个集群崩溃。
虽然我们能在资源隔离、干预甚至主动干预层面做一些努力,但基于一套系统里实现,尤其是在叠加多租户、高并发场景下,这样的干预往往效果不佳。 ByteHouse 则选择了另一条技术路线,即在计算方面基于容器化实现无状态或弱状态化,保证计算资源在秒级内实现弹性拉起和弹性扩缩容。 ByteHouse 将整个计算组包装成租户和应用呈现给用户,这部分计算资源实是专属的,即 PaaS 化,充分保证租户之间不会发生资源征用冲突或性能劣化的情况。 在弹性层面,ByteHouse 当前支持计划内的弹性,正在开发基于 workload 的智能动态弹性。用户可以根据自身负载特征定制弹性计划,触发后,整个弹性过程只需 20 多秒,即可将计算资源弹上去或缩下来。
那么,通过这一系列存算分离容器化和云原生架构的重构,ByteHouse能给用户带来哪些收益呢?
第一个收益是弹性灵活。计算资源基于容器化的 stateless 能实现秒级的弹性。存储方面,ByteHouse则可以做到按需无限容量的弹性。 第二,在性价比方面,通过计算弹性,ByteHouse可以实现随开随用,不使用时自动暂停,暂停期间不收取任何计算层费用。计算资源的 PaaS 化隔离方式,能有效避免因为不规范的 SQL 而消耗过多资源,导致账单失控的情况。
在 ByteHouse 中,计算资源采用 PaaS 方式,计价模式是基于客户的资源用量(即 CPU ),而非扫描数据量,从而确保账单可预期。正是前文提到的租户级隔离、应用级隔离,甚至是 SQL 级隔离,ByteHouse能保证整体系统运行稳定性, 让SLA 持续有保障,且性能输出稳定。
核心能力三:融合/一体化
第三个核心能力是融合/一体化。用人体来比喻,OLAP 相当于腰部的产品。腰部产品虽然是力量汇聚地,但如果缺少胳膊和腿,很难独立支撑。因此,它需要四肢,比如从腿部获取、汇聚数据;然后在内部进行加工,汇聚力量;最后通过胳膊或者躯干投放出去。 因此, 上下游系统的融合和一体化对于云数仓来说格外重要。在此,我们提出了“四个一体化”的概念。
1.TP、AP一体化
通过 TP、AP 一体化技术,可以实时地捕获上游数据。其中TP是数据的生产和供给侧,AP是数据的分析和消费侧。
CDC 方式能将上游数据库的变更数据以秒级速度捕获并拉取到数据仓库中进行分析,给报表或仪表盘提供数据支持。除了内置的物化 MySQL 表引擎,ByteHouse 还提供了可插拔的 DES(数据快车)插件。另外,ByteHouse还能和主流的 CDC 产品实现无缝对接,包括火山引擎VeDI旗下的 DataSail、开源的 DataX、Flink 以及 CDC 等。
第二个技术场景是IoT,主要应对上游埋点类数据。无论是游戏平台的日志数据,还是车联网、物联网的传感器数据等,都可以通过 streaming 技术进行支撑。ByteHouse采用内置的 Kafka 表引擎,并针对 Kafka 做了优化,确保高性能。
此外, ByteHouse Connector for Flink 能够支持更好地对接 Flink,并充分发挥 Flink 的吞吐能力。同时,ByteHouse也正在研发 Connector for Spark。总之,在流处理领域,ByteHouse能够与主流的引擎和组件进行很好的对接。
2.湖、仓一体化
ByteHouse 支持对Lake 中的数据以外表的方式进行“读”和“写”,比如ORC、Parquet、Hive、Iceberg、Paimon和Hudi等。目前业界构建数据湖的技术路线主要有两种:
-
一种是以对象存储为载体,将所有文件以开放格式存储在对象存储上,并在其上架构 Presto等查询分析引擎;
-
另一种是将数据湖架构在 Hadoop 上,通过 Hive、HUDI、 Paimon 等类数据库(DB-Like)的方式进行构建。
无论采用哪种方式,ByteHouse 在湖仓一体方面都能提供良好的支持。
在技术亮点方面,ByteHouse 为了加速性能,在优化器和 Schema 动态感知的层面做了增强。同时,ByteHouse还为 ORC、Parquet 等开放格式提供了原生读取器(Native Reader),确保在湖仓之间实现高性能,并减少数据的来回流动。
3.AP、AI一体化
在AP、AI一体化层面,ByteHouse开发了 Vector search 高级引擎,其可插拔的特点,让用户可以根据不同的应用需求,开启不同的计算组。当其他应用不需要高级特性时,可以选择不开启。
我们也在不断探索运用AI能力让ByteHouse变得更加智能。例如,在查询优化、索引物化视图、cache 等方面会根据用户查询 pattern 进行自动构建。在 schema 层面,ByteHouse也会进行智能优化,如排序键、分布键、压缩低基数以及一些高阶的统计信息等。这些能力预计在明年上半年进行产品化。
4.仓、市一体化
最后一点是“仓”和“市”的一体化,对于上规模的公司而言,数据分析中台往往部件会比较多,它不是一套简单的物理集群,而是可能由多个集群构成。多个集群之间的数据流动,以往通过传统方案会存在很多问题。在这个领域,ByteHouse 在持续地进行迭代和增强,例如通过 Remote 方式,数据可以实现两套不同的ByteHouse,甚至与 ClickHouse之间实现数据联邦,从而帮助用户免除数据搬迁这种复杂繁琐的操作。
5.Zero ETL
通过这四个一体化,我们就可以实现 Zero ETL 理念。 Zero ETL 不是一个工具的代名词,而是一个理念的代名词。在该理念的指引下面,我们可以重新审视整个数据架构中的全链路优化,甚至局部的重构。
“四个一体化”可以帮助我们逐步实现 ZeroETL 轻量化的数据架构。TP 和 AP 的一体化可以实现数据免搬迁,从而使开发更加敏捷,数仓也更加轻快。湖仓一体化,可以大量减少湖和仓之间的传统数据迁移操作。除了数据迁移,由于数据在不同组件、不同平台之间来回迁移,也给数据质量带来了很大的挑战。随着轻量化一体化不断深入,可以使整个数据架构更加轻量化,数据质量会更有保障。此外,通过智能化和 AI in DB 的不断迭代,可以实现运维的智能化,减少运维压力。
核心能力四:全场景分析引擎
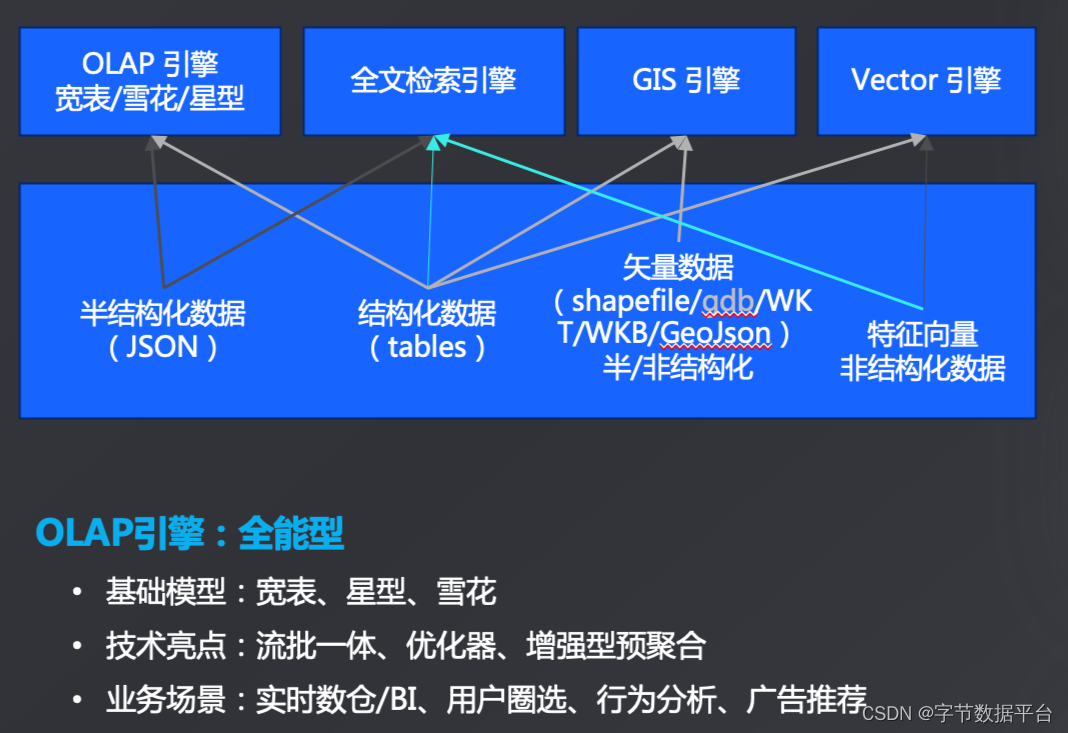
第四个核心能力是全场景分析,它可以规避“七国八制”现象,实现数据效能的最大化。ByteHouse则提出了“一元化数据、多元化引擎”的理念,确保整体数据效能的最大化产出。
ByteHouse 在 OLAP 引擎上实现了一系列增强,从而能支撑更复杂的分析模型,如宽表、星型模型、雪花模型等,甚至在基础模型上也能支持范式化建模。ByteHouse流批一体、优化器和增强型易聚合等都是其技术亮点。在实时数仓、用户圈选、行为分析、广告推荐等传统 OLAP 场景中,ByteHouse 都有出色的表现。
下面着重介绍GIS引擎、Vector引擎和全文检索引擎三个高级分析引擎。
-
GIS引擎
其中,GIS 时空分析对齐了开源的 PostGIS功能,但性能会比后者高 10 倍以上。这是基于 OLAP 引擎和 ByteHouse 强大的计算分析功能实现。
-
技术增强
具体包括二维空间索引、数据分布的优化增强,支持空间分析函数等功能。从目前来看,ByteHouse能支持PostGIS中常用的主流空间分析函。
-
性能测试
在内部电商罗盘业务中,ByteHouse在 ST_DistanceSphere 和 ST_within两个关键函数的性能上都显著超越了其他产品。
-
业务场景
在店铺选址、位置圈选、基于位置的营销作战计划、营销作战地图等方面,ByteHouse也有出色的性能表现。
-
Vector引擎
第二个方面向量检索,ByteHouse已支持多种向量检索算法以及高效的执行链路,可以支撑大规模向量检索场景,并达到毫秒级的查询延迟。通过开源软件VectorDBBench测试工具,在 cohere 1M 标准测试数据集上,recall 98 的情况下,ByteHouse QPS性能已可以超过专用向量数据库。
-
全文检索引擎
在全文检索方面, ByteHouse可以做到比 ES 占用更少的空间,但实现更佳的性能表现,其显著优势在于在技术上实现了高压缩比。由于 ByteHouse 的所有高级引擎都是 SQL base,因此用户使用成本非常低:只要会 SQL,就能实现需要复杂专业技术的业务分析。
核心能力五:生态多元化
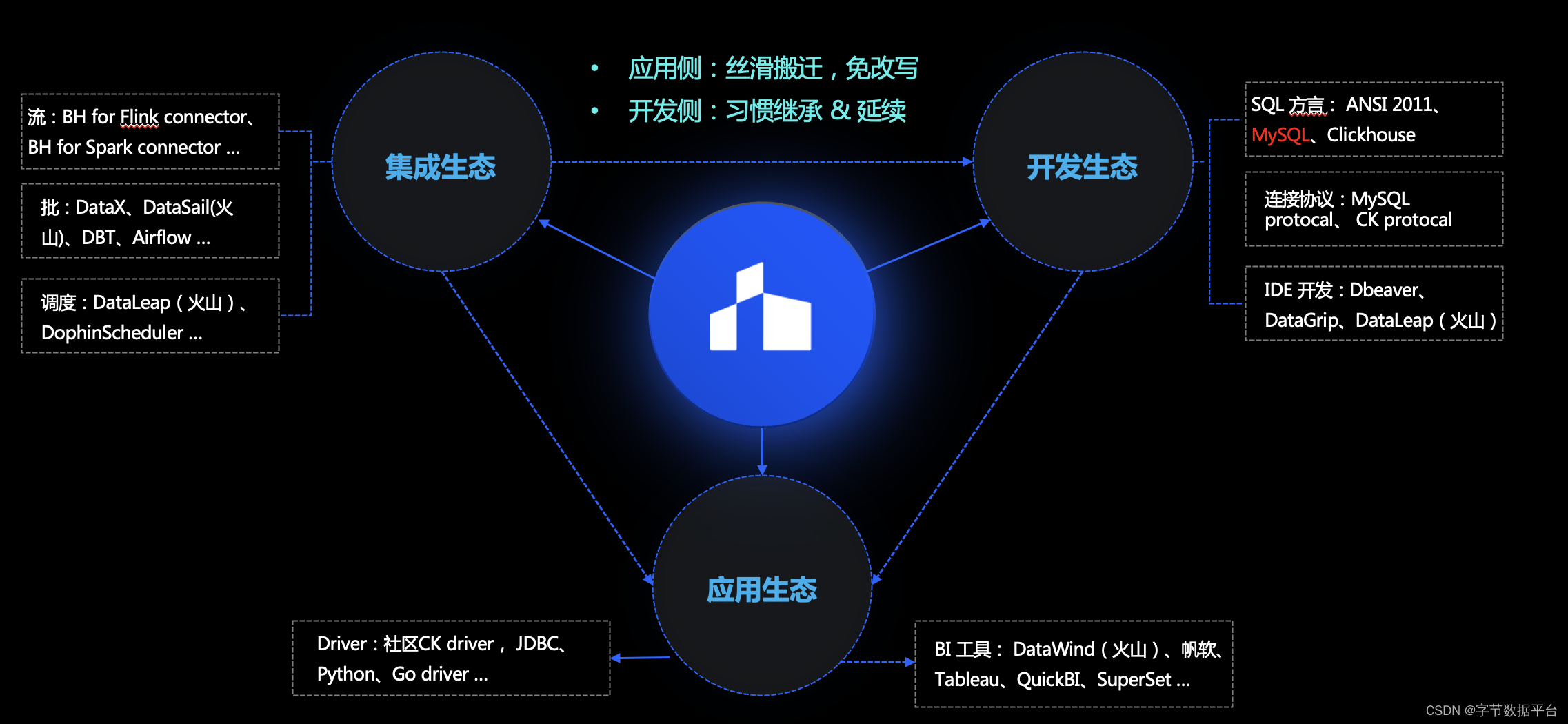
第五个核心能力是生态多元化。OLAP 领域虽然呈现出百花齐放的局面,但主流还是存量场景。为了让更多用户开发者和应用用户从其他平台顺滑迁移到 ByteHouse ,ByteHouse期望能尽量缩减改写和搬迁代价。
因此,ByteHouse主要是围绕集成生态、开发生态和应用生态来迭代和提升。
-
数据集成生态
ByteHouse与主流开源组件进行了良好对接,无论是流处理、批处理还是调度,都能做到较好融合。
-
数据开发生态
ByteHouse SQL 方言的兼容上,投入了大量研发人力进行 MySQL 生态兼容性的开发。无论是 MySQL 方言、函数,还是协议,ByteHouse均能支持,确保开发者和应用侧无需进行代码改写,延续原有的使用习惯。
-
数据应用生态
ByteHouse 提供了丰富的驱动Driver ,包括 社区CK driver、JDBC 、Python 和 Go Driver等。
在BI 工具方面,ByteHouse对接了火山引擎VeDI旗下智能数据洞察产品 DataWind,以及开源的帆软、QuickBI、SuperSet 等。
作为第五个核心能力,生态多元化能够让用户在不同的组件和平台之间的上手成本降到最低,甚至接近零成本。
总结来看,卓越性能能够快速处理海量数据,在各个场景中实现高效运算;秒级无损弹性弹性,使成本更加可控,更具性价比;一体化架构,将数据处理的各个环节紧密融合,从智能化、轻量化角度增强产品能力,减少用户操作成本;全场景覆盖,能规避“七国八制”现象,最大化数据效能;生态多元化,则能与众多不同类型的技术和产品良好兼容,形成强大的生态体系,共同为用户提供更优质的数据服务。
以上五大核心能力已经在ByteHouse实现,这意味着 ByteHouse 能够为用户提供更为高效、灵活、全面且具有良好兼容性的解决方案,帮助各行业客户提升数据分析能力,在数字化转型中抢占先机。欢迎对这方面有需求、感兴趣的用户体验。
点击跳转火山引擎ByteHouse了解更多