重点:Qwen2提供了CPU与GPU两种运行方式
运行成功效果图: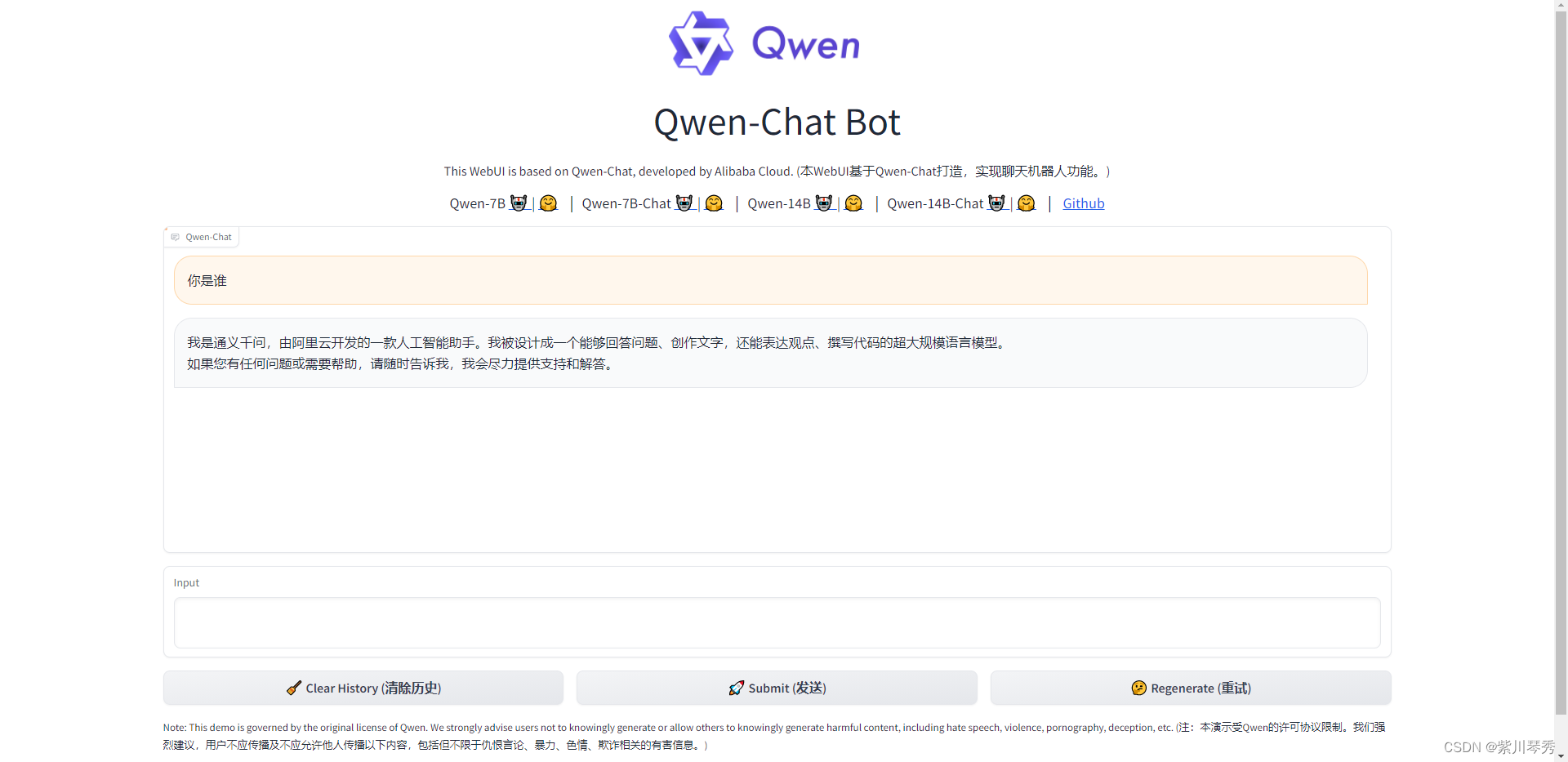
前提说明:如果需要用GPU,那么请在物理机安装ubuntu系统,不然显卡驱动很难安装,不建议新手部署。训练微调模型需要用到GPU。本文仅以ubuntu系统演示说明。
1、首先我们安装一个Ubutun系统,安装系统不展开说明,自行安装,我安装的是117~20.04.1-Ubuntu
2、新建2个文件夹,用于下载模型以及Qwen源码。
mkdir -p /usr/local/project/conda/Qwen #【用来存放Qwen2源码】
mkdir -p /home/zhangwei/llm #【用来存放Qwen2模型】3、利用git clone 下载源码以及模型
root@zhangwei-H610M-K-DDR4:/# cd /usr/local/project/conda/Qwen #【进入文件夹】
root@zhangwei-H610M-K-DDR4:/# git clone https://github.com/QwenLM/Qwen.git#【下载Qwen源码】
root@zhangwei-H610M-K-DDR4:/usr/local/project/conda/Qwen# ls
ascend-support docker FAQ.md LICENSE process_data_law.py README_ES.md recipes tech_memo.md 'Tongyi Qianwen LICENSE AGREEMENT' tran_data_law1.json
assets eval FAQ_zh.md NOTICE qweb_lora_merge.py README_FR.md requirements.txt tokenization_note_ja.md 'Tongyi Qianwen RESEARCH LICENSE AGREEMENT' utils.py
cli_demo.py examples finetune openai_api.py QWEN_TECHNICAL_REPORT.pdf README_JA.md requirements_web_demo.txt tokenization_note.md train_data_law2.json web_demo.py
dcu-support FAQ_ja.md finetune.py output_qwen README_CN.md README.md run_gptq.py tokenization_note_zh.md train_data_law.json
root@zhangwei-H610M-K-DDR4:/usr/local/project/conda/Qwen# cd /home/zhangwei/llm#【进入文件夹】
root@zhangwei-H610M-K-DDR4:/home/zhangwei/llm# git clone https://www.modelscope.cn/qwen/Qwen-1_8B-Chat.git#【下载Qwen_1_8模型】
root@zhangwei-H610M-K-DDR4:/home/zhangwei/llm# ls
Qwen-1_8B-Chat Qwen-1_8B-Chat_law2 Qwen-1_8B-Chat_law3 Qwen-1_8B-Chat_law4 tran_data_law1.json tran_data_law.json
4、安装miniconda以及python3.10【注意:必须安装3.10版本,否则启动不了】
root@zhangwei-H610M-K-DDR4:/# wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda.sh --no-check-certificate
root@zhangwei-H610M-K-DDR4:/# bash ~/miniconda.sh
root@zhangwei-H610M-K-DDR4:/# conda init
root@zhangwei-H610M-K-DDR4:/# source ~/.bashrc
root@zhangwei-H610M-K-DDR4:/# conda --version
conda 24.5.0
root@zhangwei-H610M-K-DDR4:/#conda create -n pytorch2 python=3.10
root@zhangwei-H610M-K-DDR4:/#conda activate pytorch2
root@zhangwei-H610M-K-DDR4:/#conda install pytorch torchvision torchaudio cpuonly -c pytorch
root@zhangwei-H610M-K-DDR4:/#python -c "import torch; print(torch.__version__); print(torch.cuda.is_available())"
root@zhangwei-H610M-K-DDR4:/#python --version
Python 3.10.14
5、安装所需模块
root@zhangwei-H610M-K-DDR4:/# cd /usr/local/project/conda/Qwen
#在源码目录下有2个txt,分别为:requirements.txt,requirements_web_demo.txt安装他们
root@zhangwei-H610M-K-DDR4: /usr/local/project/conda/Qwen/# pip install -r requirements.txt
pip install -r requirements_web_demo.txt
#最后启动web界面
root@zhangwei-H610M-K-DDR4: /usr/local/project/conda/Qwen/# python web_demo.py --server-name 0.0.0.0 -c /home/zhangwei/llm/Qwen-1_8B-Chat --cpu-only
#启动后打印如下信息,可以在浏览器输入http://ip:8000,最终呈现文章开头的页面
/home/zhangwei/conda/envs/pytorch2/lib/python3.10/site-packages/torch/cuda/__init__.py:619: UserWarning: Can't initialize NVML
warnings.warn("Can't initialize NVML")
Warning: import flash_attn rotary fail, please install FlashAttention rotary to get higher efficiency https://github.com/Dao-AILab/flash-attention/tree/main/csrc/rotary
Warning: import flash_attn rms_norm fail, please install FlashAttention layer_norm to get higher efficiency https://github.com/Dao-AILab/flash-attention/tree/main/csrc/layer_norm
Warning: import flash_attn fail, please install FlashAttention to get higher efficiency https://github.com/Dao-AILab/flash-attention
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 15.99it/s]
Running on local URL: http://0.0.0.0:8000
To create a public link, set `share=True` in `launch()`.
IMPORTANT: You are using gradio version 3.41.2, however version 4.29.0 is available, please upgrade.
--------
#--cpu-only这个参数是仅用cpu来跑欢迎大家一起探讨,后续会更新微调Qwen2模型