一位等于1比特。比特(BIT)和位是同一个概念的不同表述,都是信息量的最小单位。1字节(byte)由8位组成。
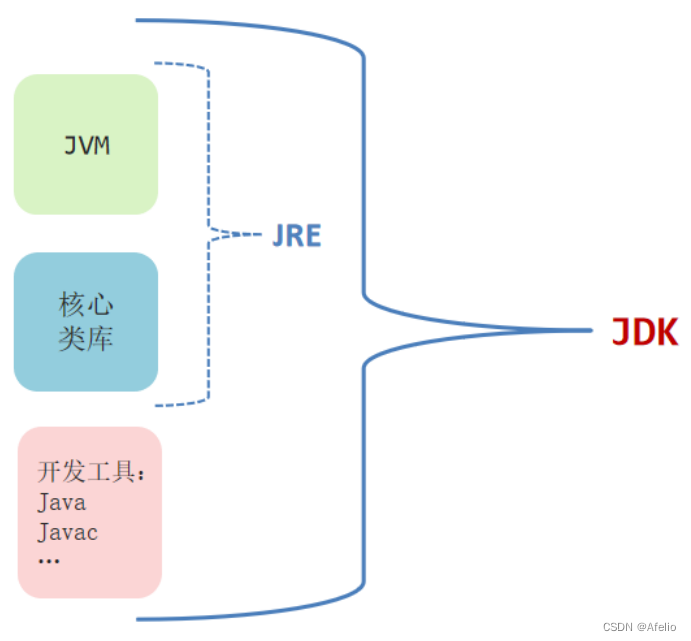
1.介绍
- JVM(Java Virtual Machine):Java虚拟机, 真正运行Java程序的地方
- 核心类库:Java自己写好的程序,给程序员自己的程序调用的
- JRE(Java Runtime Environment): Java的运行环境
- JDK(Java Development Kit): Java开发工具包(包括上面所有)
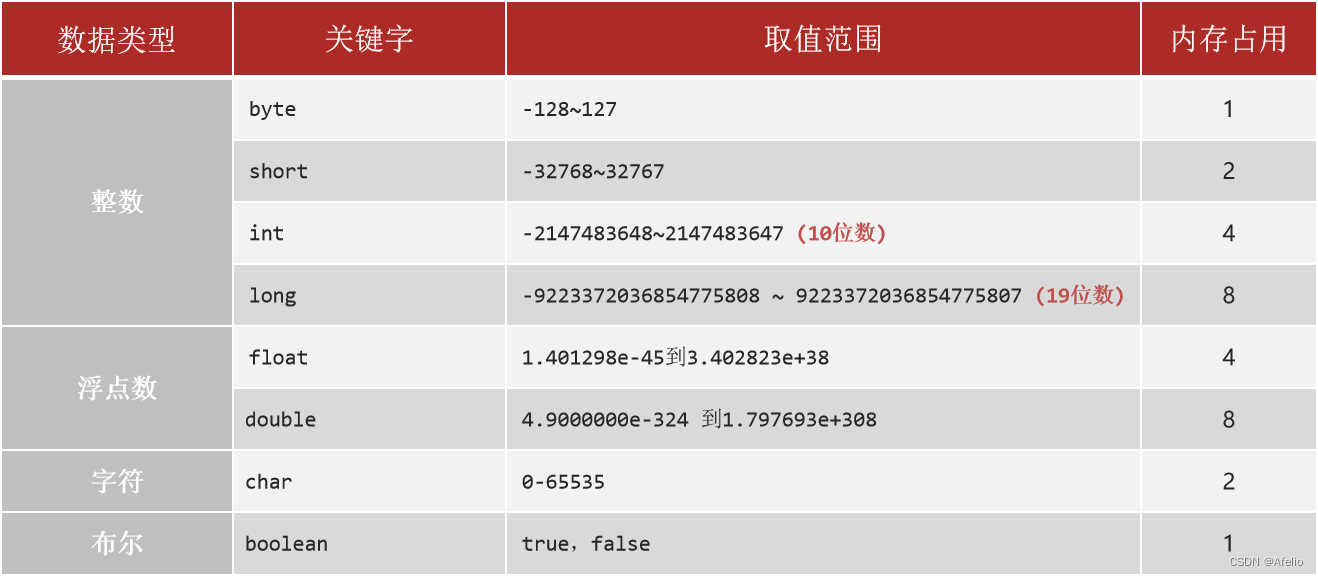
1.1 数据类型
1.1.1 基本数据类型
2 运算符
算数运算符、自增自减运算符、赋值运算符、关系运算符、逻辑运算符、三元运算符
2.1 逻辑运算符
- 逻辑与 &,无论左边 true false,右边都要执行。
短路与 &&,如果左边为 true,右边执行;如果左边为 false,右边不执行。 - 逻辑或 |,无论左边 true false,右边都要执行。
短路或 ||,如果左边为 false,右边执行;如果左边为 true,右边不执行。
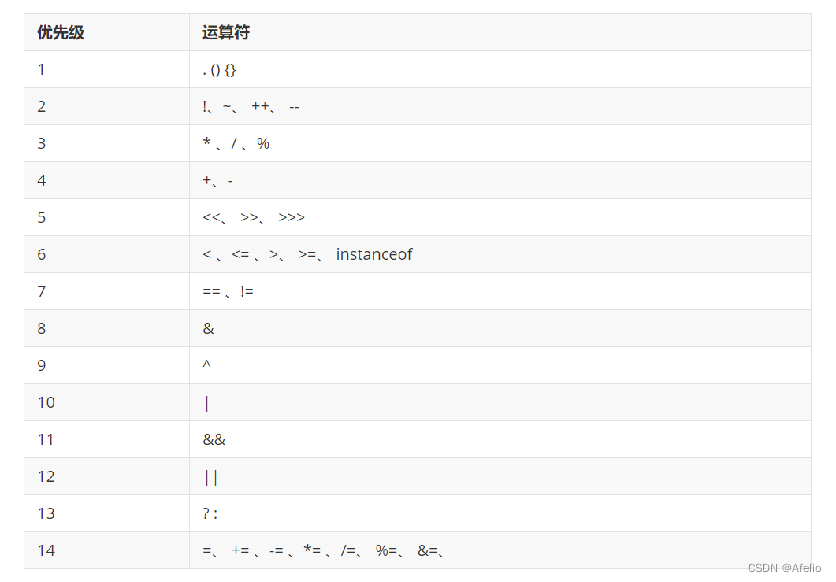
2.2 运算符优先级
3 方法重载
同一个类中,方法名相同,参数不同的方法(个数不同、类型不同、顺序不同)
注意:识别方法之间是否是重载关系,只看方法名和参数,跟返回值无关。
4 流程控制语句
4.1 顺序结构
系统默认
4.2 分支结构
4.2.1 if 语句
if、else if、else
if 语句中只有一条语句时,大括号可省略
1.4.2.2 Switch 语句
switch(表达式){
case 值1:
语句体1;
break;
case 值2:
语句体2;
break;
...
default:
语句体n;
break;
}
表达式:(将要匹配的值) 取值为 byte、short、int、char,JDK5以后可以是 枚举 ,JDK7以后可以是 String。
注:case给出的值不允许重复;case后面的值只能是常量,不能是变量
4.3 循环语句
for、while、do…while
5 面向对象
5.1 面向对象三大特征
封装、继承、多态
5.1.1 继承
子类重写父类方法,需要保证方法声明完全一致(方法名,参数,返回值类型需要保持一致)
标识:@Override注解
注:
- 父类中私有方法不能被重写
- 子类重写父类方法时,访问权限必须大于等于父类
- 接口可以多继承,类只能单继承
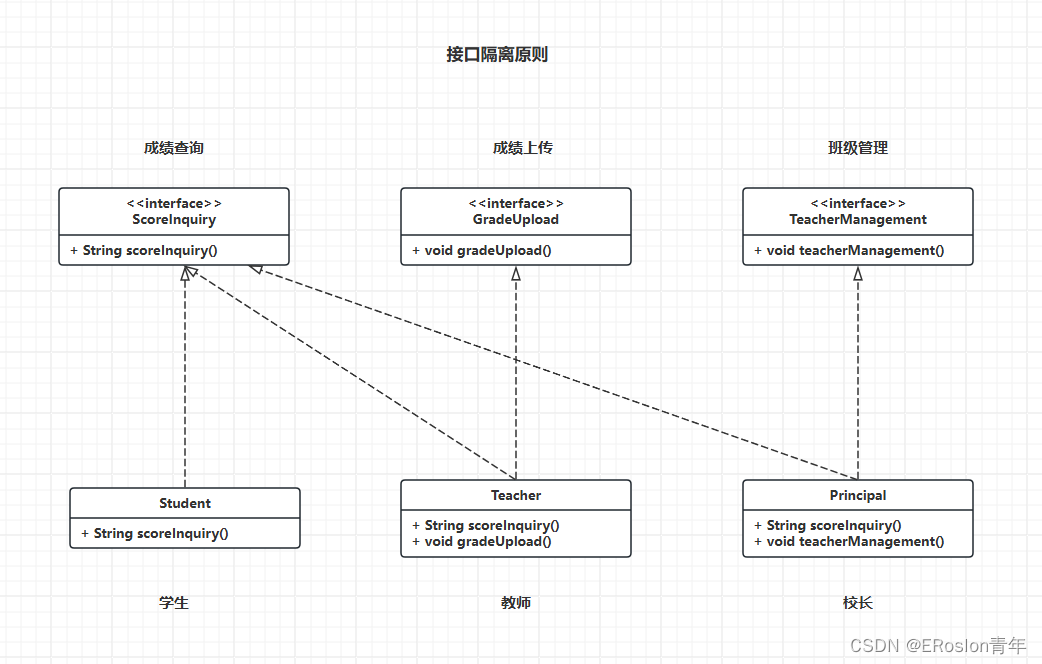
5.2 接口
抽象类和接口的对比:
-
成员变量 :
抽象类 : 可以定义变量, 也可以定义常量
接口 : 只能定义常量 -
成员方法
抽象类 : 可以是定义具体方法, 也可以定义抽象方法
接口 : 只能定义抽象方法 -
构造方法
抽象类 : 有
接口 : 没有
5.2.1 新特性
5.2.1.1 JDK8的新特性
接口中可以定义有方法体的方法。(默认、静态)
5.2.1.1.1 默认方法
允许在接口中定义非抽象方法,但是需要使用关键字 default 修饰,这些方法就是默认方法
作用:解决接口升级的问题
接口中默认方法的定义格式:
格式:public default 返回值类型 方法名(参数列表) {}
范例:public default void show() {}
注:
- 默认方法不是抽象方法,所以不强制被重写 (但是可以被重写,重写的时候去掉default关键字)
- public可以省略,default不能省略
- 如果实现了多个接口,多个接口中存在相同的方法声明,子类就必须对该方法进行重写
5.2.1.1.2 静态方法
接口中允许定义 static 静态方法
接口中静态方法的定义格式:
格式:public static 返回值类型 方法名(参数列表) {}
范例:public static void show() {}
注:
- 静态方法只能通过接口名调用,不能通过实现类名或者对象名调用
- public可以省略,static不能省略
5.2.1.2 JDK9的新特性
接口中可以定义私有方法。
5.3 final关键字
不能被重写、不能被继承、不能再次被赋值
final 修饰的引用类型的地址值不能发生改变,但是地址里面的内容是可以发生改变的
5.4 抽象
抽象方法:将共性的行为(方法)抽取到父类之后,发现该方法的实现逻辑无法在父类中给出具体明确,该方法就可以定义为抽象方法。
抽象类:如果一个类中存在抽象方法,那么该类就必须声明为抽象类
抽象方法的定义格式:
public abstract 返回值类型 方法名(参数列表);
抽象类的定义格式:
public abstract class 类名{}
注:
- 抽象类不能实例化
- 抽象类存在构造方法
- 抽象类中可以存在普通方法
- 抽象类的子类
- 要么重写抽象类中的所有抽象方法
- 要么是抽象类
abstract 关键字的冲突:
- final:被 abstract 修饰的方法,强制要求子类重写,被 final 修饰的方法子类不能重写
- private:被 abstract 修饰的方法,强制要求子类重写,被 private 修饰的方法子类不能重写
- static:被 static 修饰的方法可以类名调用,类名调用抽象方法没有意义
5.5 代码块
在Java类下,使用 { } 括起来的代码被称为代码块
- 局部代码块
位置:方法中定义
作用:限定变量的生命周期,及早释放,提高内存利用率 - 构造代码块
位置:类中方法外定义
特点:每次构造方法执行的时,都会执行该代码块中的代码,并且在构造方法执行前执行
作用:将多个构造方法中相同的代码,抽取到构造代码块中,提高代码的复用性 - 静态代码块
位置:类中方法外定义
特点:需要通过static关键字修饰,随着类的加载而加载,并且只执行一次
作用:在类加载的时候做一些数据初始化的操作 - 同步代码块
6 集合
6.1 单列集合
Collection接口
一次添加一个元素,单列集合.add(“元素”)
ArraysList、LinkedList、TreeSet、HashSet、LinkedHashSet
6.1.1 List接口
有序、有索引、可重复
6.1.1.1 ArrayList
ArrayList 长度可变原理:
- 当创建 ArrayList 集合容器的时候, 底层会存在一个长度为10个大小的空数组
- 扩容原数组 1.5 倍大小的新数组
- 将原数组数据,拷贝到新数组中
- 将新元素添加到新数组
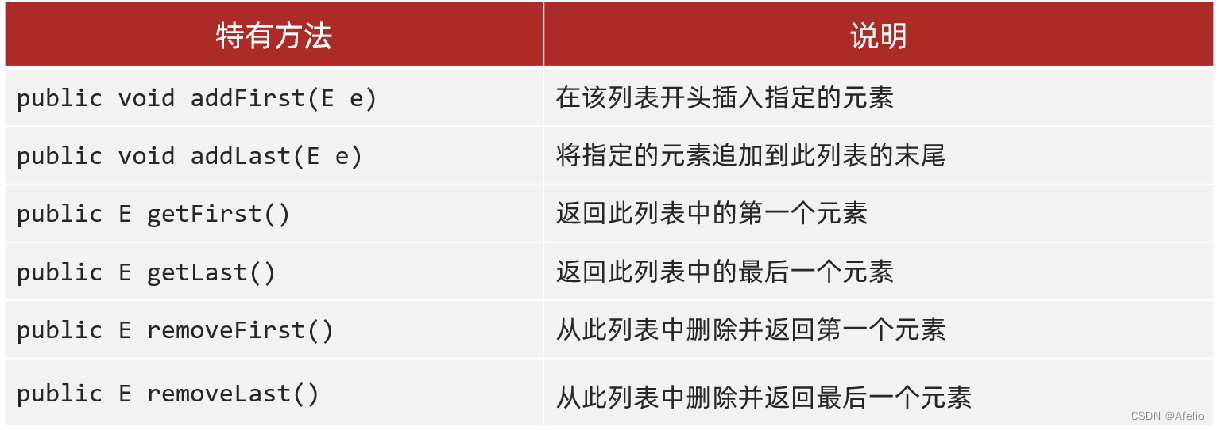
6.1.1.2 LinkedList
LinkedList 底层基于双链表实现的,查询元素慢,增删首尾元素是非常快的
6.1.2 Set接口
无序、无索引、去重
6.1.2.1 TreeSet
作用 : 对集合中的元素进行排序操作 (底层红黑树实现)
6.1.2.1.1 自然排序
1.类实现 Comparable 接口
2.重写 compareTo 方法
3.根据方法的返回值, 来组织排序规则
负数 : 左边走
正数 : 右边走
0 : 不存
public class Student implements Comparable<Student>{
@Override
public int compareTo(Student o) {
return this.age - o.age;
}
}
TreeSet<Student> ts = new TreeSet<>();
ts.add(new Student("王五", 25));
ts.add(new Student("张三", 23));
ts.add(new Student("李四", 24));
6.1.2.1.2 比较器排序
1.在 TreeSet 的构造方法中, 传入 Compartor 接口的实现类对象
2.重写 compare 方法
3.根据方法的返回值, 来组织排序规则
负数 : 左边走
正数 : 右边走
0 : 不存
public class Student implements Comparable<Student>{
@Override
public int compareTo(Student o) {
return this.age - o.age;
}
}
TreeSet<Student> ts = new TreeSet<>();
ts.add(new Student("王五", 25));
ts.add(new Student("张三", 23));
ts.add(new Student("李四", 24));
6.1.2.2 HashSet
HashSet 集合底层采取哈希表存储数据
哈希表是一种对于增删改查数据性能都较好的结构
哈希表 :
JDK8版本之前 : 数组 + 链表
JDK8版本之后 : 数组 + 链表 + 红黑树
6.1.2.2.1 hashCode
哈希值:是JDK根据某种规则算出来的int类型的整数。
public int hashCode():调用底层 C++ 代码计算出的一个随机数 (常被人称作地址值)
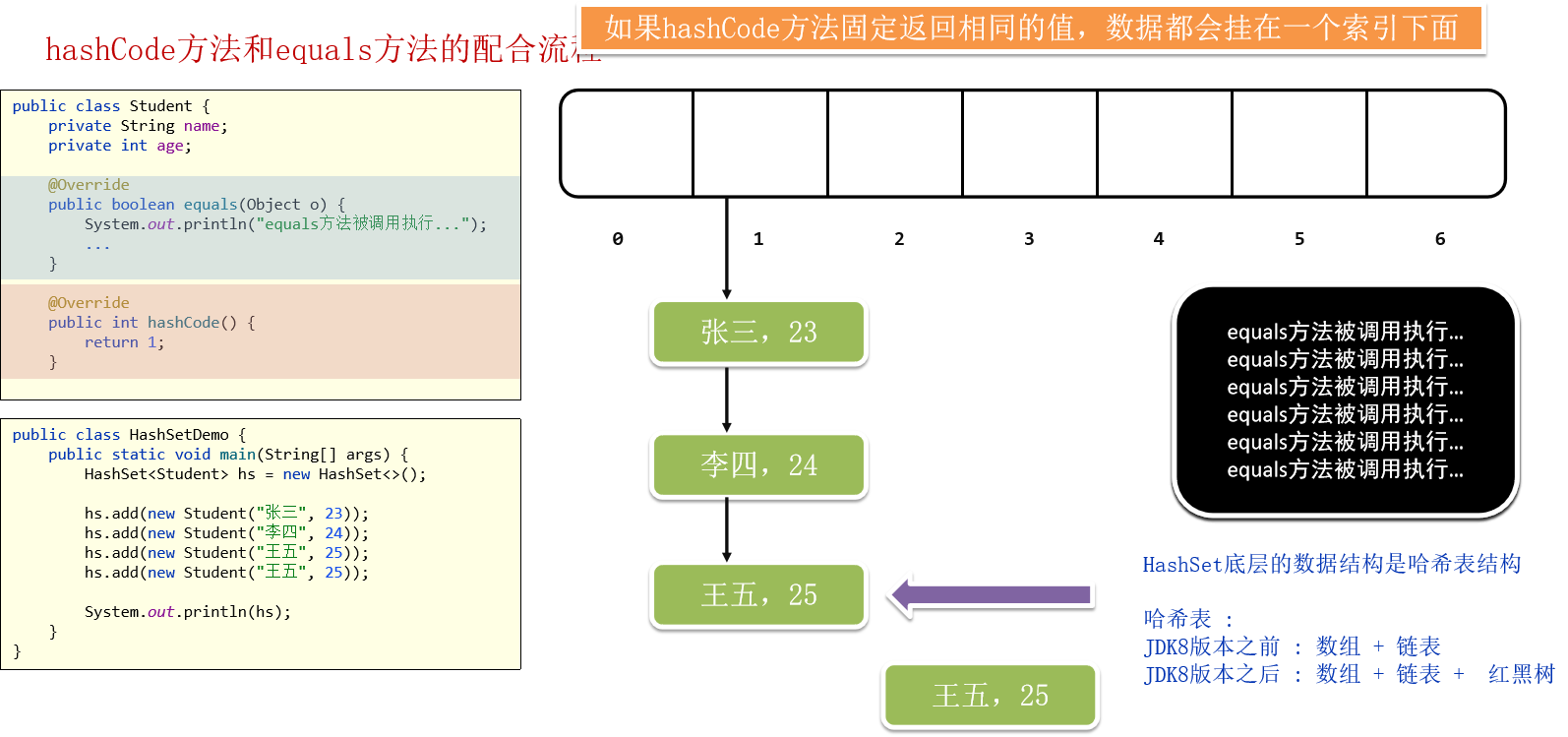
当添加对象的时候, 会先调用对象的hashCode方法计算出一个应该存入的索引位置, 查看该位置上是否存在元素:
不存在:直接存
存在:调用equals方法比较内容,false : 存,true : 不存
如果hashCode方法固定返回相同的值,数据都会挂在一个索引下面(如上图,hashCode方法return 1)

- 创建一个默认长度16的数组,数组名table
- 根据元素的哈希值跟数组的长度求余计算出应存入的位置
- 判断当前位置是否为null,如果是null直接存入
- 如果位置不为null,表示有元素,则调用equals方法比较
- 如果一样,则不存,如果不一样,则存入数组,
- JDK 7新元素占老元素位置,指向老元素 (头插法)
- JDK 8中新元素挂在老元素下面(尾插法)
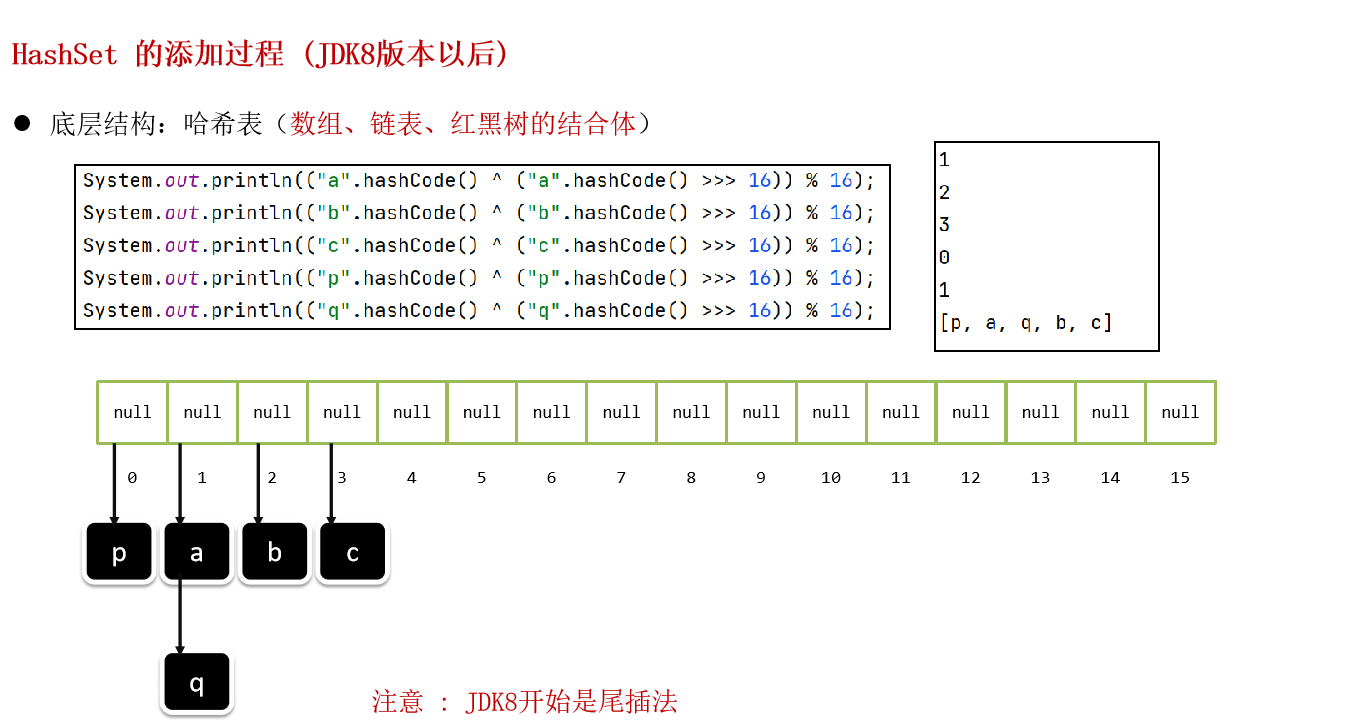
- 创建 HashSet 集合, 内部会存在一个默认长度16,默认加载因为0.75的数组
- 调用集合的添加方法, 会拿着对象的hashCode方法计算出应存入的索引位置 ( 哈希值 % 数组长度)
- 判断索引位置元素是否是null:
是 : 存入
不是: 说明有元素, 调用equals方法比较内容,如果一样,则不存,如果不一样,则存入数组。 - 当数组存满到16*0.75=12时,就自动扩容,每次扩容原先的两倍
- 当链表挂载元素超过了8个 (阈值),检查数组长度:
没有到达64, 扩容数组
到达了64, 会转换为红黑树
6.1.2.3 LinkedHashSet
有序、不重复、无索引。
原理:底层数据结构是依然哈希表,只是每个元素又额外的多了一个双链表的机制记录存储的顺序。
6.1.3 单列集合小结
- 如果想要集合中的元素可重复
用ArrayList集合,基于数组的。(用的最多) - 如果想要集合中的元素可重复,而且当前的增删操作明显多于查询
用LinkedList集合,基于链表的。 - 如果想对集合中的元素去重
用HashSet集合,基于哈希表的。 (用的最多) - 如果想对集合中的元素去重,而且保证存取顺序
用LinkedHashSet集合,基于哈希表和双链表,效率低于HashSet。 - 如果想对集合中的元素进行排序
用TreeSet集合,基于红黑树。后续也可以用List集合实现排序。
6.2 双列集合
Map接口
一次添加两个元素,双列集合.put(“元素key”,“元素value”)
双列集合的数据结构,都只针对于键有效,和值没有关系:
TreeMap : 键(红黑树)
HashMap : 键(哈希表)
LinkedHashMap : 键(哈希表 + 双向链表)

7 正则表达式
String telRegex = "编写规则";
"需要做校验的字符串".matches(telRegex));
字符类(默认匹配一个字符)
[abc] 只能是a, b, 或c
[^abc] 除了a, b, c之外的任何字符
[a-zA-Z] a到z A到Z,包括(范围)
[a-d[m-p]] a到d,或m通过p:([a-dm-p]联合)
[a-z&&[def]] d, e, 或f(交集)
[a-z&&[^bc]] a到z,除了b和c:([ad-z]减法)
[a-z&&[^m-p]] a到z,除了m到p:([a-lq-z]减法)
预定义的字符类(默认匹配一个字符)
. 任何字符
\d 一个数字: [0-9]
\D 非数字: [^0-9]
\s 一个空白字符: [ \t\n\x0B\f\r]
\S 非空白字符: [^\s]
\w [a-zA-Z_0-9] 英文、数字、下划线
\W [^\w] 一个非单词字符
量词(配合匹配多个字符)
X? X , 一次或根本不
X* X,零次或多次 (任意次数)
X+ X , 一次或多次
X {n} X,正好n次
X {n, } X,至少n次
X {n,m} X,至少n但不超过m次
8 时间类(jdk8)
8.1 日历类
LocalDate :代表本地日期(年、月、日、星期)
LocalTime :代表本地时间(时、分、秒、纳秒)
LocalDateTime :代表本地日期、时间(年、月、日、星期、时、分、秒、纳秒)
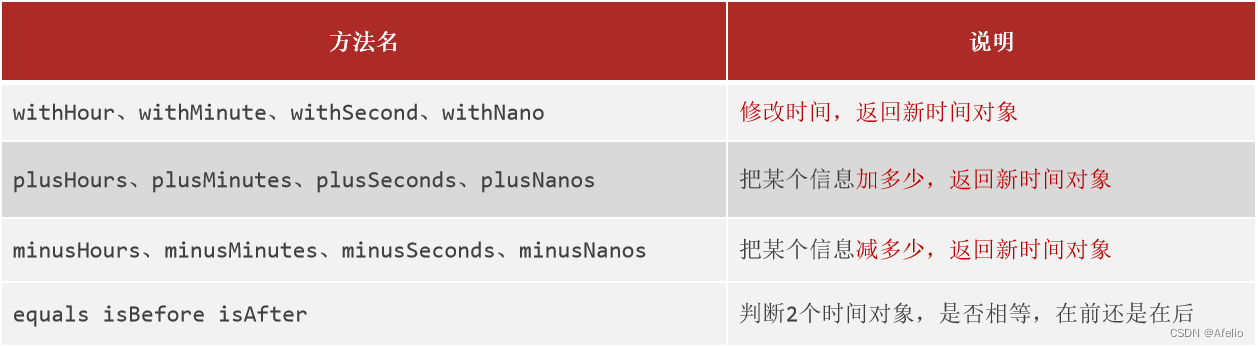
修改年月日时分秒相关的方法
LocalDateTime 、LocalDate 、LocalTime 都是不可变的, 下列方法返回的是一个新的对象
8.2 日期格式化类
DateTimeFormatter :用于时间的格式化和解析

8.3 时间类
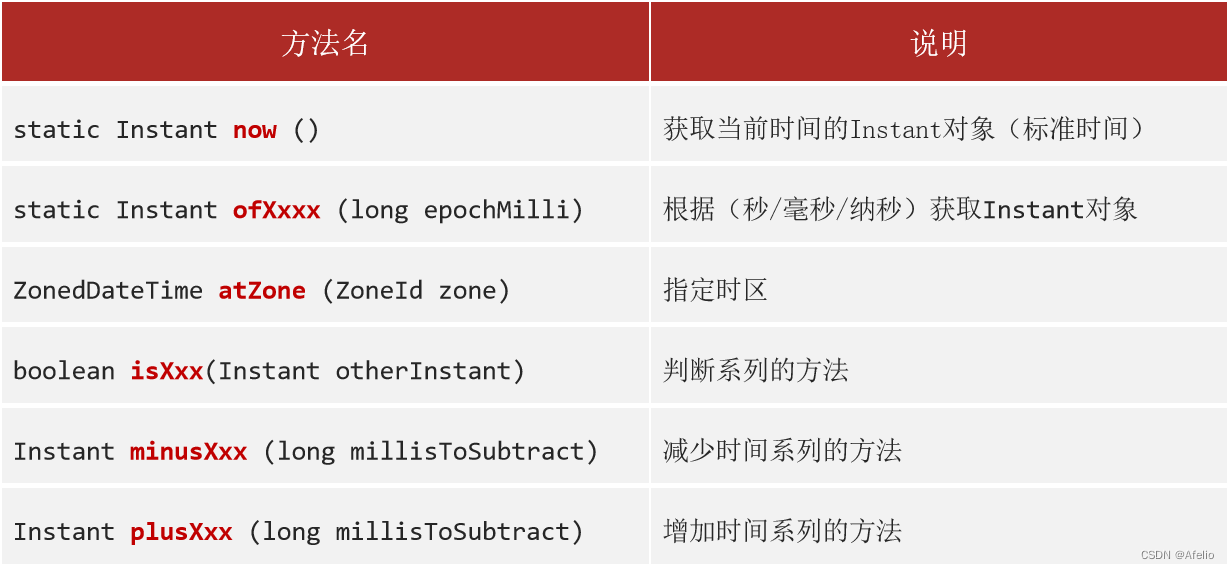
Instant :时间戳/时间线
ZoneId : 时区
ZonedDateTime : 带时区的时间
8.4 工具类
Period : 时间间隔(年,月,日)
Duration : 时间间隔(时、分、秒,纳秒)
ChronoUnit : 时间间隔 (所有单位)
9 异常
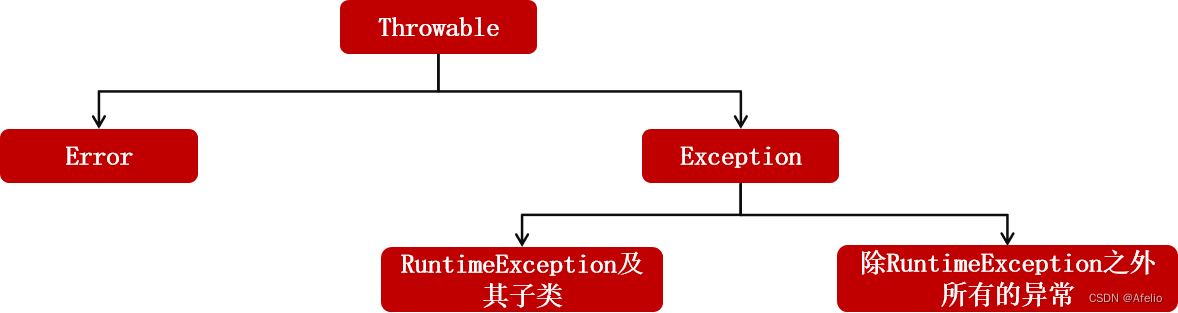
Error 严重级别问题
常见的 : 栈内存溢出 (StackOverflowError) 堆内存溢出 (OutOfMemoryError)
Exception:
RuntimeException 及其子类:运行时异常
除RuntimeException 之外所有的异常:编译时异常
运行时异常:
数组索引越界异常: ArrayIndexOutOfBoundsException
空指针异常 : NullPointerException
数学操作异常:ArithmeticException
类型转换异常:ClassCastException
数字转换异常: NumberFormatException
…
异常的默认处理流程
1.虚拟机会在出现异常的代码那里自动的创建一个异常对象:ArithmeticException
2.异常会从方法中出现的点这里抛出给调用者,调用者最终抛出给JVM虚拟机
3.虚拟机接收到异常对象后,先在控制台直接输出异常信息数据
4.终止 Java 程序的运行
5.后续代码没有机会执行了
10 Stream流
配合Lambda表达式,简化集合和数组操作
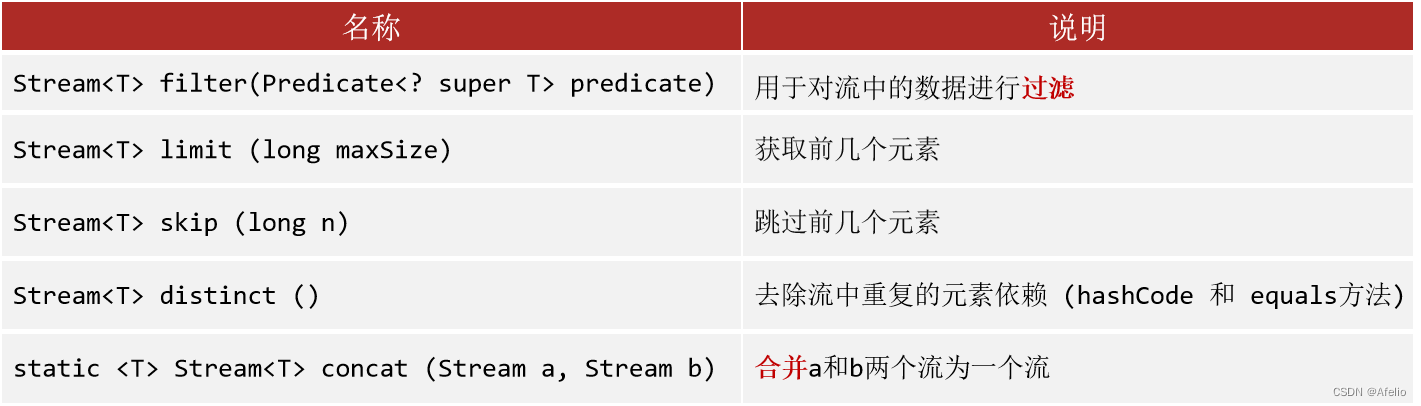
注:如果流对象已经被消费过,就不允许再次使用了
11 File类

File 对象可以定位文件和文件夹
File 封装的对象仅仅是一个路径名,这个路径可以是存在的,也可以是不存在的


注:delete() 方法只能删除空文件夹,且不走回收站

- 当调用者File表示的路径不存在时,返回null
- 当调用者File表示的路径是文件时,返回null
- 当调用者File表示的路径是一个空文件夹时,返回一个长度为0的数组
- 当调用者File表示的路径是需要权限才能访问的文件夹时,返回null
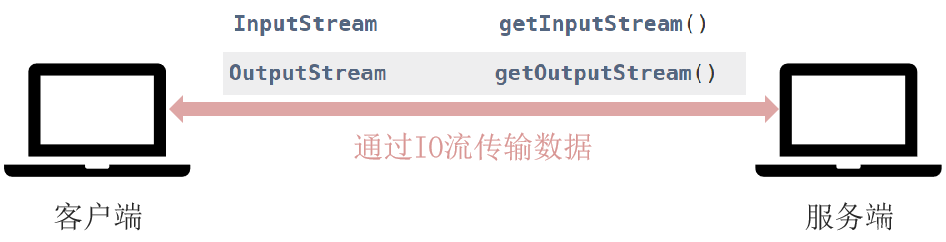
12 IO流
input:输入(读取)
output:输出(写出)
12.1 IO 流体系结构
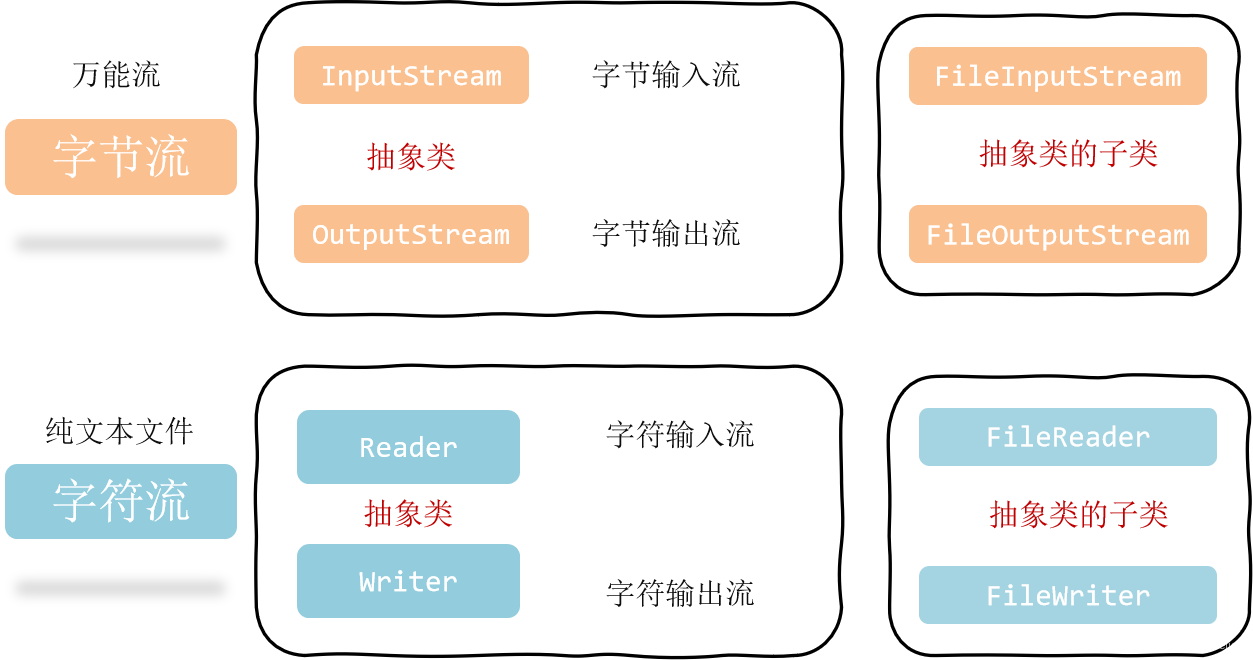
12.2 FileOutputStream 字节输出流
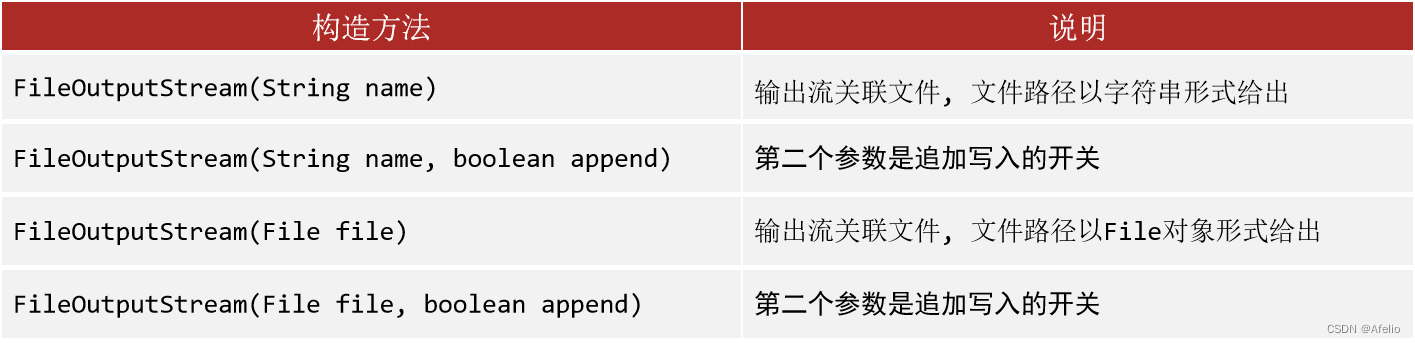

注:最后要关流释放资源
12.3 FileInputStream 字节输入流

注:
1.关联的文件不存在会抛出 FileNotFoundException 异常
2.文件夹的话会拒绝访问

12.4 字节缓冲流
字节缓冲流在源代码中内置了字节数组,可以提高读写效率。
注: 缓冲流不具备读写功能, 它们只是对普通的流对象进行包装,真正和文件建立关联的, 还是普通的流对象

字节缓冲流读写过程:

没使用缓冲流:
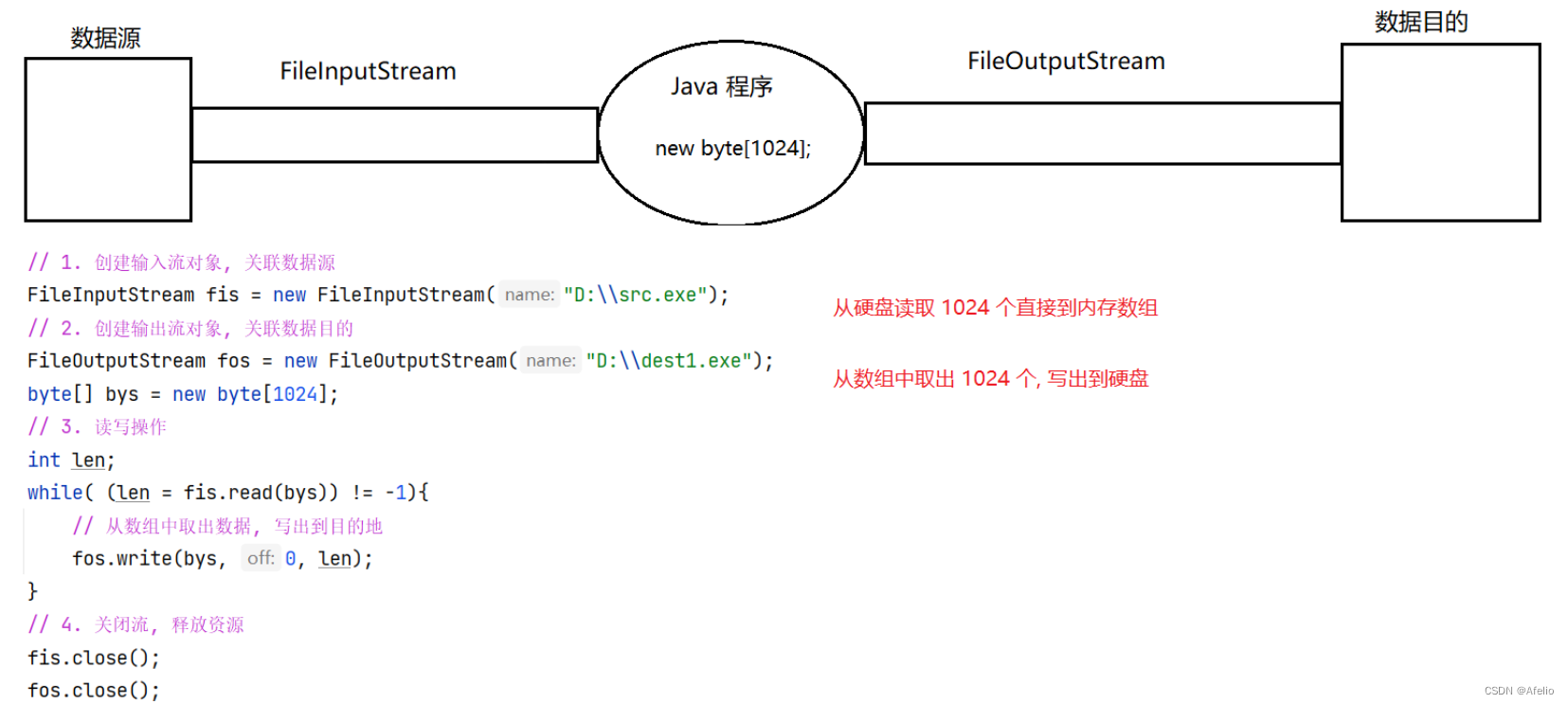
使用缓冲流:

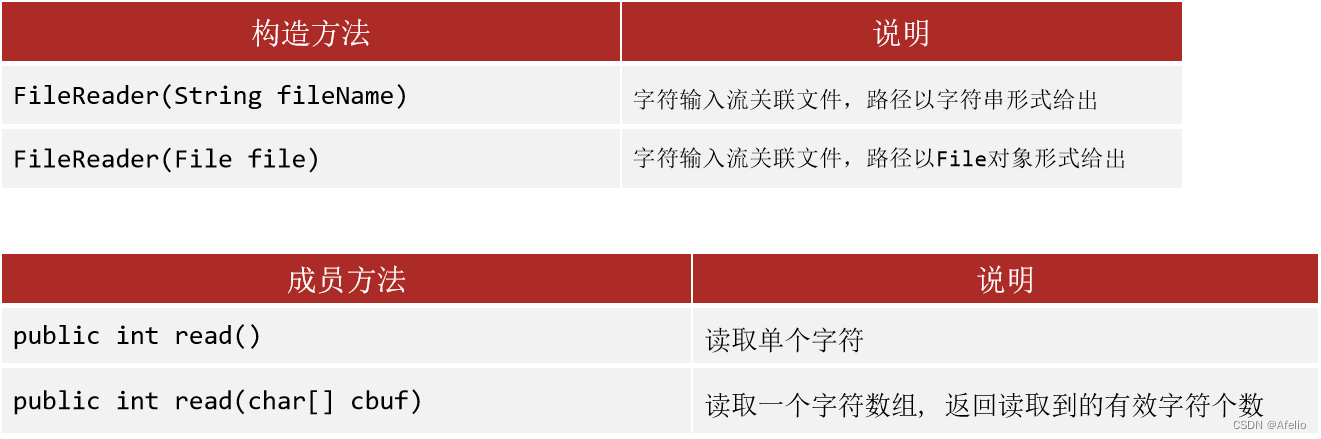
12.5 FileReader 字符输入流
用于读取纯文本文件,解决中文乱码问题
12.6 FileWriter 字符输出流
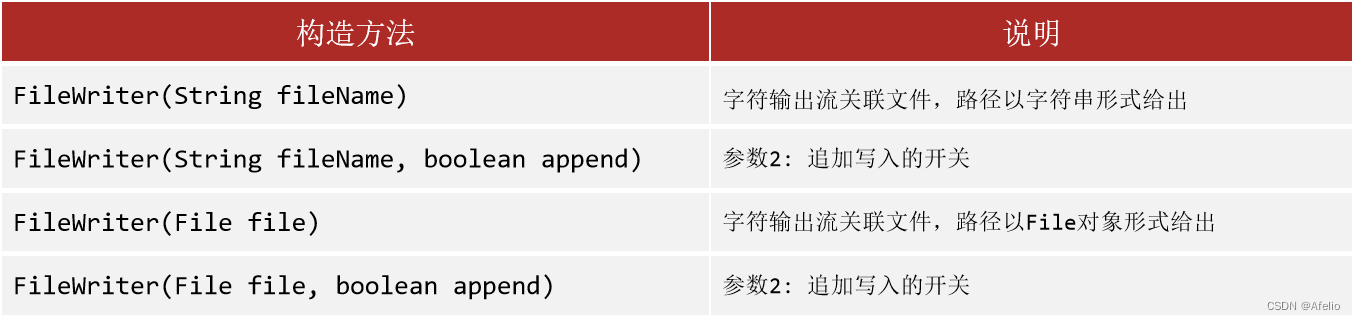
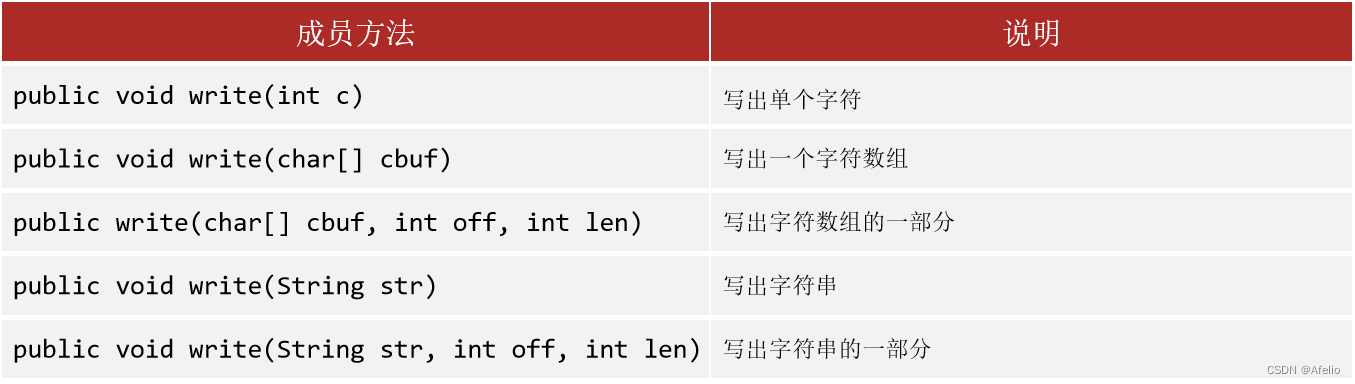
注:
1.字符输出流写出数据,需要调用flush或close方法,数据才会写出
2.Flush后可以继续写出,Close 后不能继续写出
字符流使用场景:读写纯文本文件
字节流使用场景:不是纯文本文件都用字节流
12.7 字符缓冲流
字节缓冲流在源代码中内置了字符数组,可以提高读写效率
BufferedReader、BufferedWriter
注: 缓冲流不具备读写功能, 它们只是对普通的流对象进行包装

12.8 转换流
InputStreamReader、OutputStreamWriter
作用:按照指定的字符编码读写操作、将字节流转换为字符流进行操作
为什么用转换流?直接new 需要的流不行吗?
因为有些流对象不是我们自己创建的,而是通过方法获取到的。
12.9 序列化流

public class Student implements Serializable {
private static final long serialVersionUID = 1L;
...
}
- 序列化流的作用是?
可以在流中,以字节的形式直接读写对象 - 序列化流我们用的是哪个类读取, 又是哪个类在写?
ObjectInputStream、ObjectOutputStream - 调用的方法是?
readObject() writeObject() - 类需要实现什么接口才可以序列化?
Serializable接口 - 实现接口后, 推荐多做一步操作, 这一步是 ?
手动加入 serialVersionUID - transient 关键字的作用是?
被 transient 修饰的成员变量不会被序列化
12.10 打印流
打印流可以实现方便、高效的打印数据到文件中去,并且可以指定字符编码
write(97); 输出a
println(97); 输出97


两个流都具备自动刷出、自动换行的功能
12.11 Properties
其实就是一个Map集合,内部存在着两个方法,可以很方便的将集合中的键值对写入文件,也可以方便的从文件中读取。
常用于加载配置文件
12.11.1 作为集合的使用

12.11.2 和 IO 有关的方法

12.12 字符编码:
- GBK: 英文字符占用1个字节、中文字符占用2个字节
- Unicode:
UTF-16编码规则:用2~4个字节保存
UTF-32编码规则:固定使用四个字节保存
UTF-8编码规则:用1~4个字节保存
12.13 编码和解码:

13 多线程
13.1 进程和线程
13.2 进程
进程 (Process) 是计算机中的程序关于某数据集合上的一次运行活动
是系统进行资源分配的基本单位
简单理解:程序的执行过程
1.独立性:每一个进程都有自己的空间,在没有经过进程本身允许的情况下,一个进程不可以直接访问其它的的进程空间
2.动态性:进程是动态产生,动态消亡的
3.并发性:任何进程都可以同其它进程一起并发执行
并行和并发
并行:在同一时刻,有多个指令在多个CPU上【同时】执行
并发:在同一时刻,有多个指令在单个CPU上【交替】执行

13.3 线程
进程可以同时执行多个任务,每个任务就是线程
多线程的意义:提高效率,可以同时处理多个任务
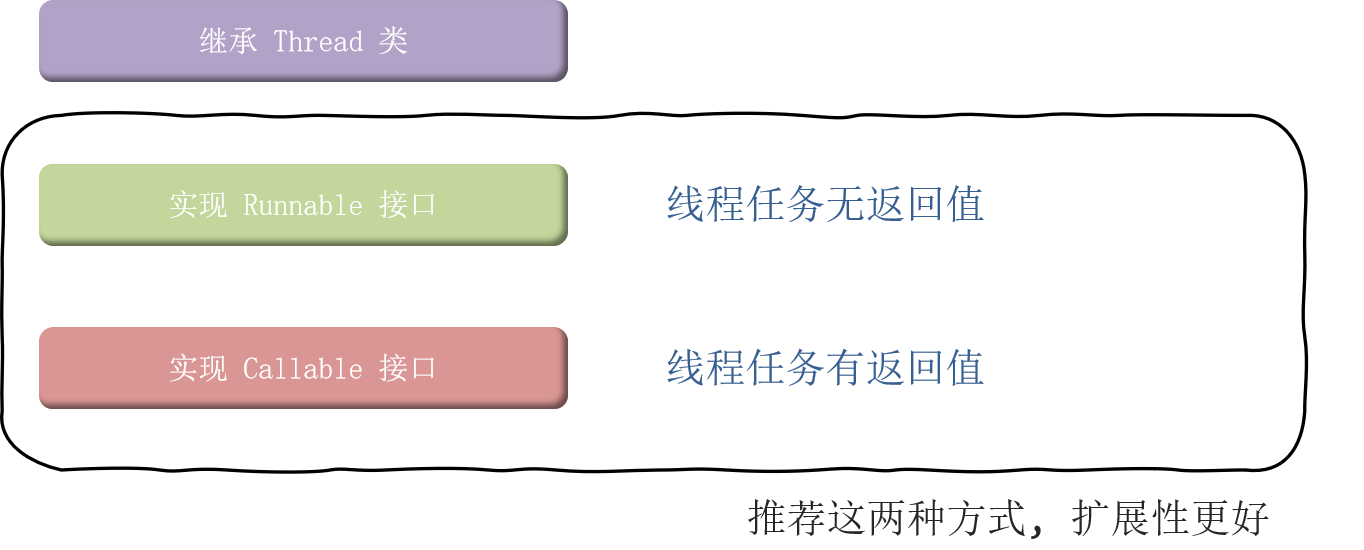
13.4 Java 开启线程的方式
13.5 线程相关方法

优先级: 1 ~ 10 默认为5
线程的调度方式:
抢占式调度(随机)
非抢占式调度(轮流使用)
13.6 线程安全和同步
安全问题出现的条件:多线程环境、有共享数据、有多条语句操作共享数据
同步技术:将多条语句操作共享数据的代码给锁起来,让任意时刻只能有一个线程可以执行
同步代码块、同步方法、Lock锁
13.6.1 同步代码块
synchronized(锁对象) {
多条语句操作共享数据的代码
}
注:
1.锁对象可以是任意对象,但是需要保证多条线程的锁对象,是同一把锁
2.同步可以解决多线程的数据安全问题,但是也会降低程序的运行效率
13.6.2 同步方法
public synchronized void method() {
多条语句操作共享数据的代码
}
方法分为静态和非静态,静态方法的锁对象是字节码对象,非静态方法的锁对象是 this
13.6.2 Lock 锁
lock.lock();
...
lock.unlock();
Lock 是接口,无法直接创建对象

13.6.3 死锁
由于两个或者多个线程互相持有对方所需要的资源,导致这些线程处于等待状态,无法前往执行
13.6.4 等待唤醒机制

注:需要使用锁对象调用,wait() 方法在等待的使用会释放锁对象
使用 ReentrantLock 实现同步,并获取 Condition 对象

13.7 生产者消费者模式
为了解耦生产者和消费者的关系,通常会采用共享的数据区域 (缓冲区),就像是一个仓库
生产者生产数据之后直接放置在共享数据区中,并不需要关心消费者的行为
消费者只需要从共享数据区中去获取数据,并不需要关心生产者的行为
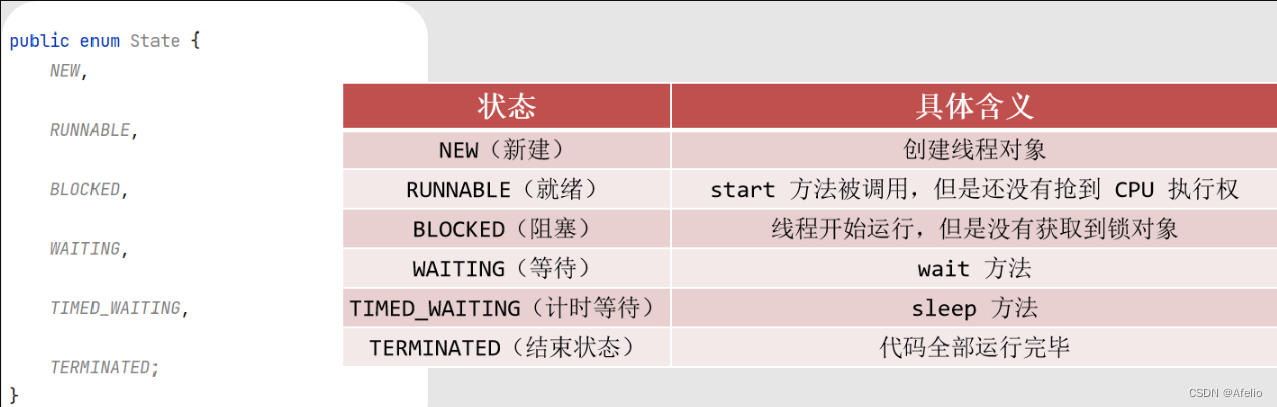
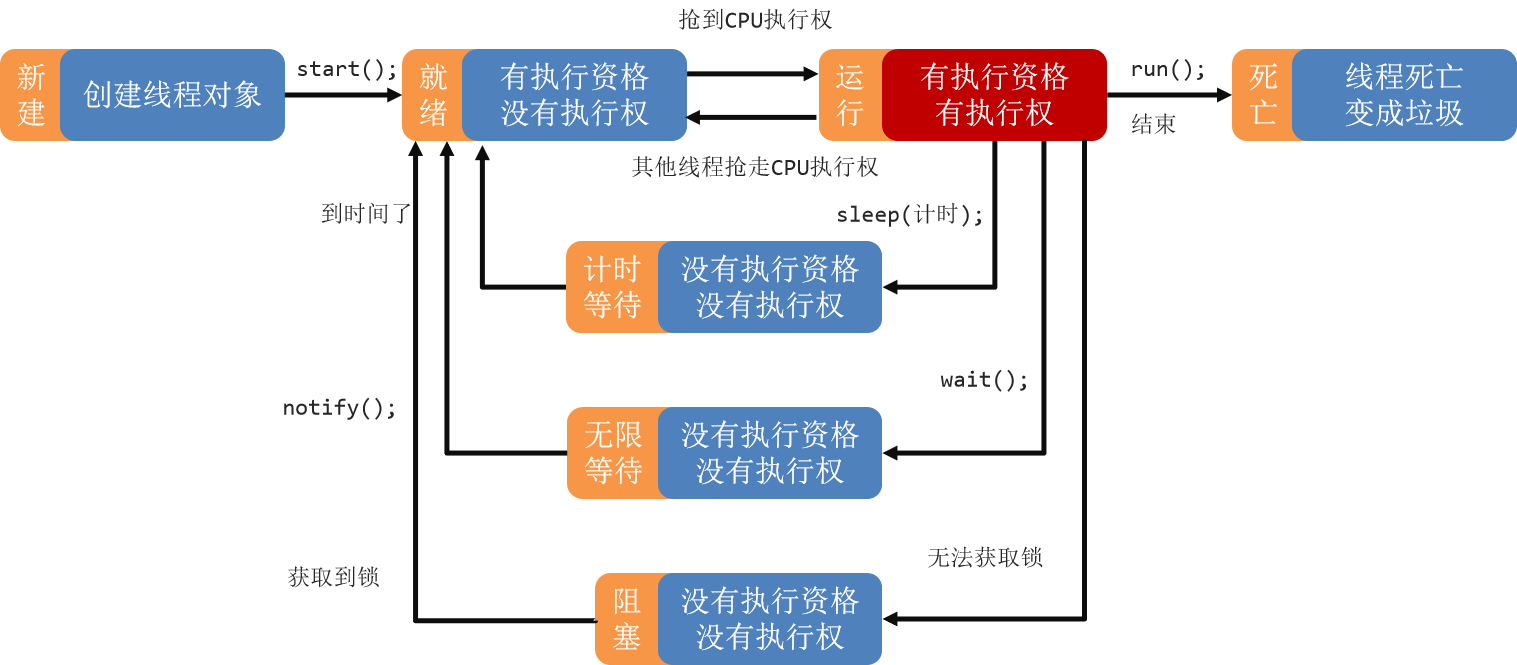
13.8 线程生命周期
线程被创建并启动以后,它并不是一启动就进入了执行状态,也不是一直处于执行状态。
Java 中的线程状态被定义在了 java.lang.Thread.State 枚举类
13.9 线程池
当程序中需要创建大量生存期很短暂的线程时,频繁的创建和销毁线程,就会严重浪费系统资源。
将线程对象交给线程池维护,可以降低系统成本 ,从而提升程序的性能。

线程池不建议使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,规避资源耗尽的风险。
说明:Executors 返回的线程池对象的弊端如下:
- FixedThreadPool和SingleThreadPool
允许的请求队列长度为 Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM。 - CachedThreadPool :
允许的创建线程数量为 Integer.MAX_VALUE,可能会创建大量的线程,从而导致 OOM。
Executors 中提供静态方法来创建线程池

自定义线程池ThreadPoolExecutor 类

参数1:核心线程数量 (正式员工),不能小于0
参数2:最大线程数量 (正式员工 + 临时工),不能小于等于0, 最大数量 >= 核心线程数量
参数3:空闲时间,不能小于0
参数4:时间单位
参数5:任务队列 (指定排队人数),不能为null
参数6:线程对象任务工厂,不能为null
参数7:拒绝策略,不能为null
拒绝策略:
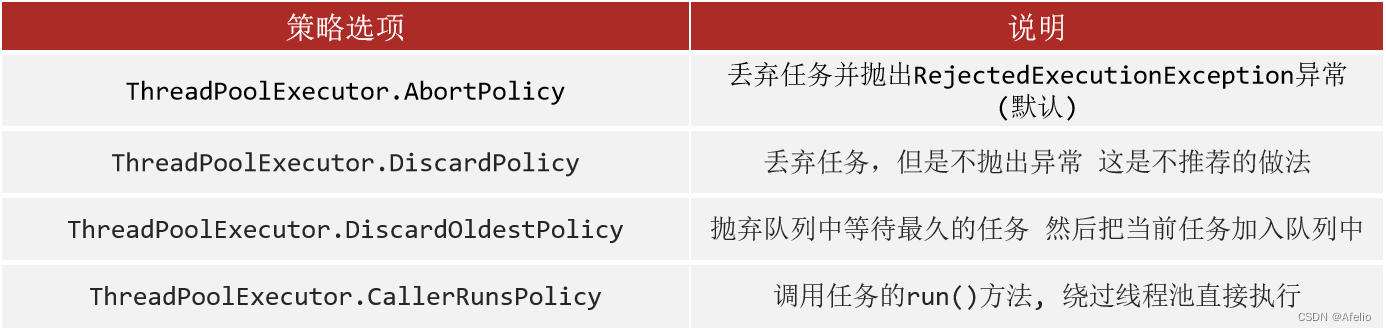
- 临时线程什么时候创建?
线程任务数 > 核心线程数 + 任务队列的数量 - 什么时候会开启拒绝策略
线程任务数 > 最大线程数 + 任务队列的数量
15 数据结构
数据结构是计算机底层存储、组织数据的方式,是指数据相互之间是以什么方式排列在一起的
通常情况下,精心选择的数据结构可以带来更高的运行或者存储效率
常见的数据结构:栈、队列、数组、链表、二叉树、二叉查找树、平衡二叉树、红黑树、哈希表
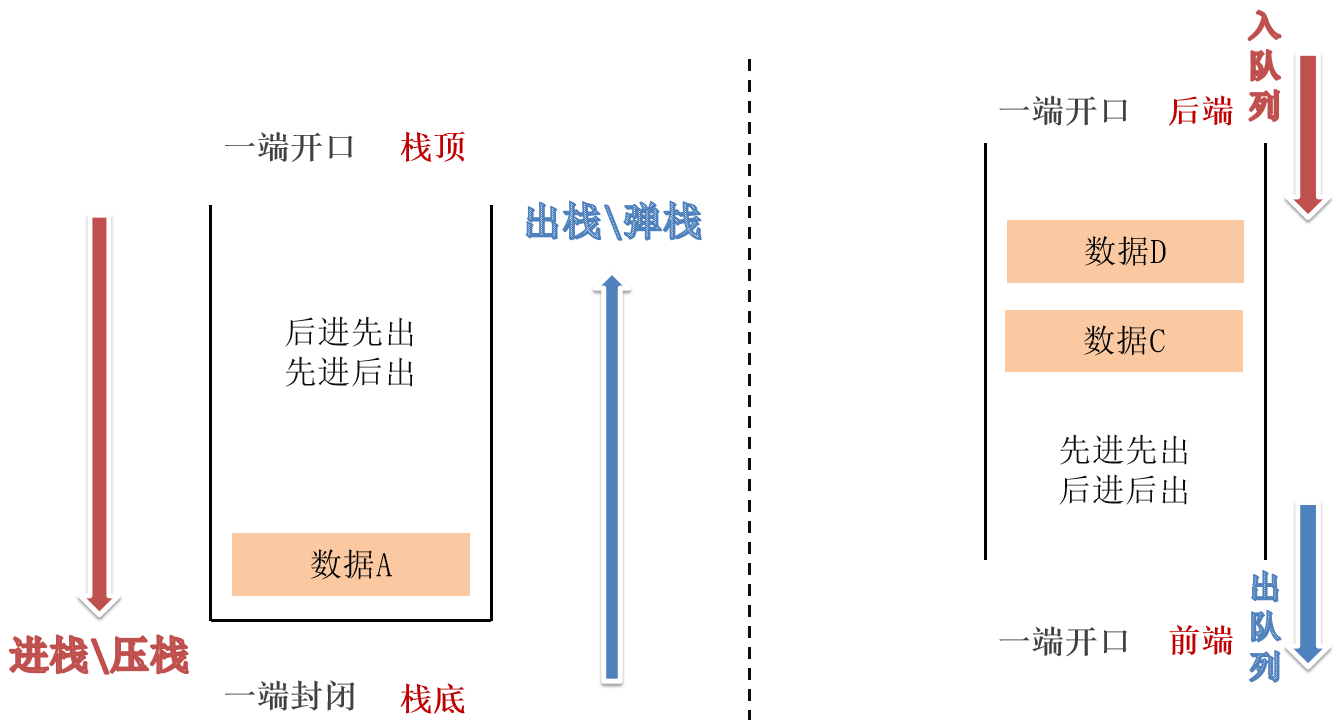
15.1 栈、队列
15.2 数组
查询速度快:查询数据通过地址值和索引定位,查询任意数据耗时相同
增、删效率低:新增或删除数据的时候,都有可能大批量的移动数组中其他的元素
15.3 链表
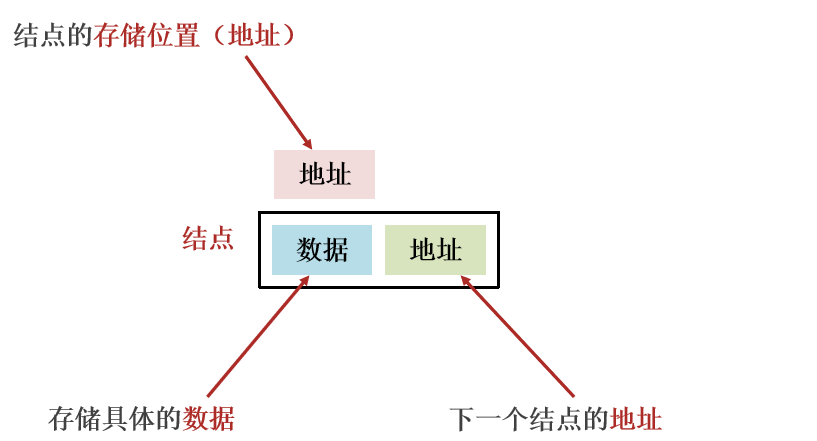
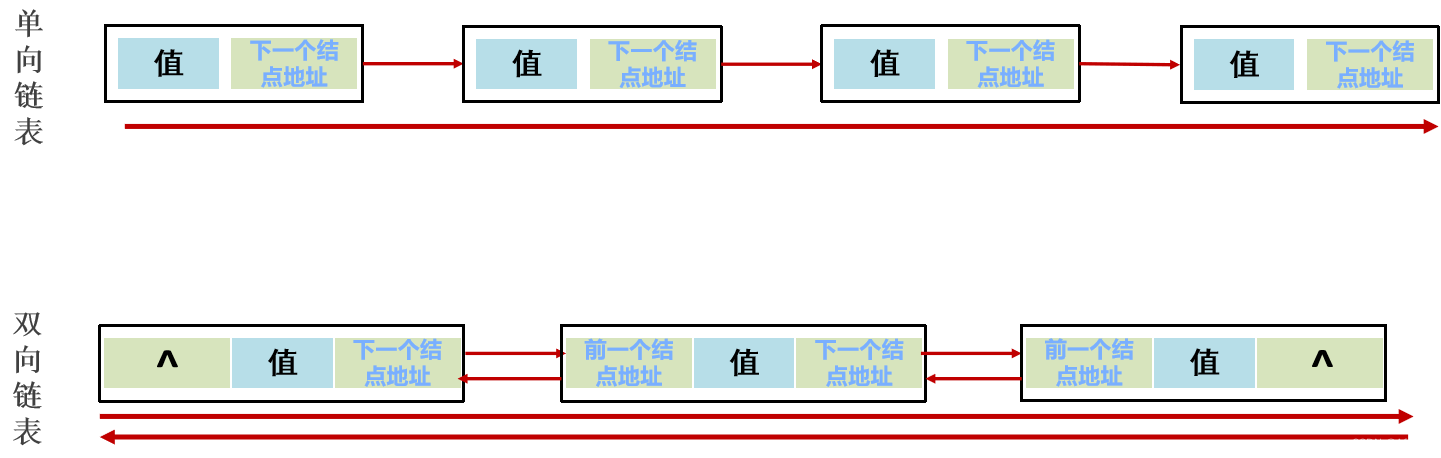
链表中的结点是独立的对象,在内存中是不连续的,每个结点包含数据值和下一个结点的地址。
链表查询慢,无论查询哪个数据都要从头开始找。
链表增删相对快
15.4 小结
栈:后进先出,先进后出。
队列:先进先出,后进后出。
数组:内存连续区域,查询快,增删慢。
链表:元素是游离的,查询慢,首尾操作极快。
15.5 树
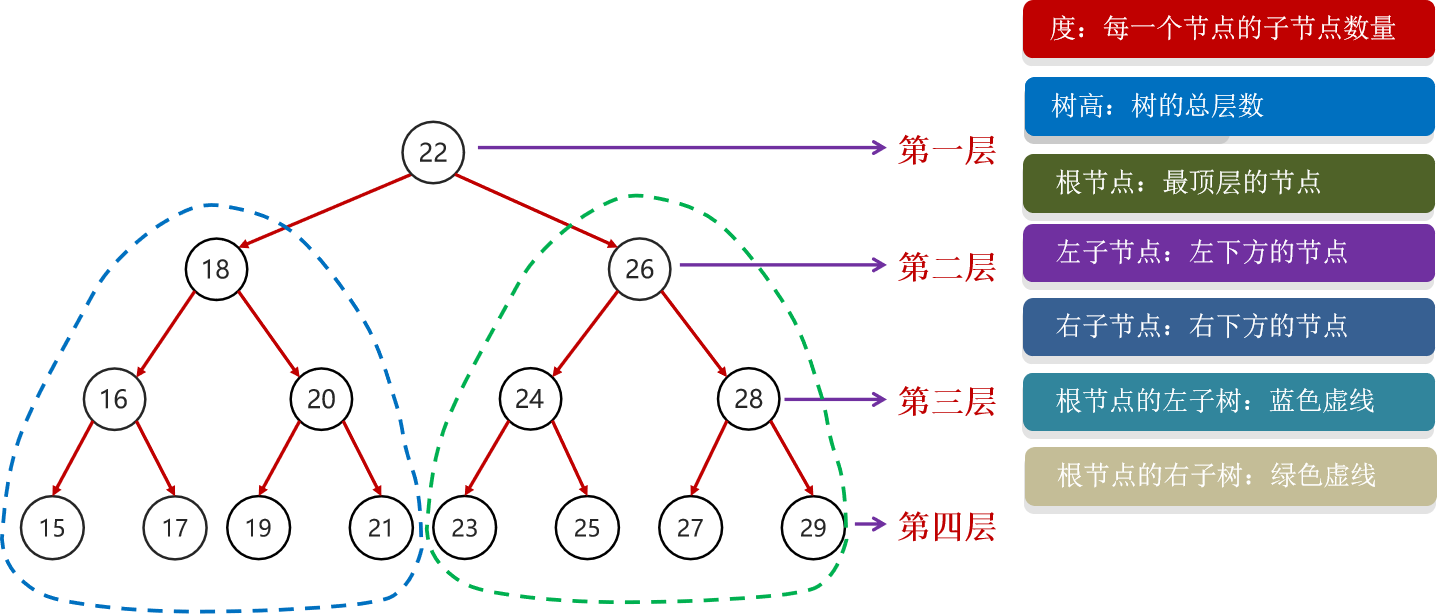
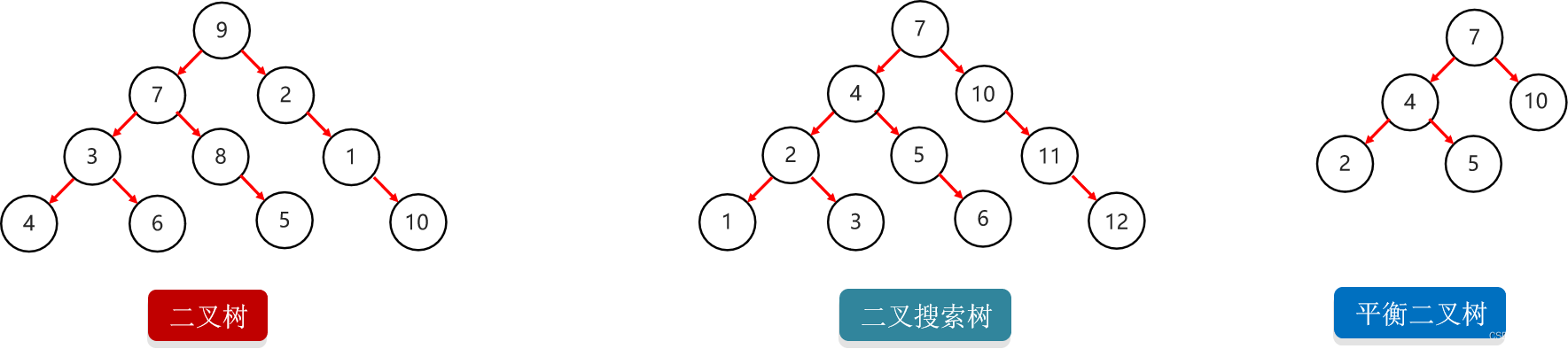
15.5.1 二叉查找树
二叉查找树,又称二叉排序树或者二叉搜索树
每一个节点上最多有两个子节点
任意节点左子树上的值都小于当前节点
任意节点右子树上的值都大于当前节点
15.5.2 红黑树
15.5.2.1 介绍
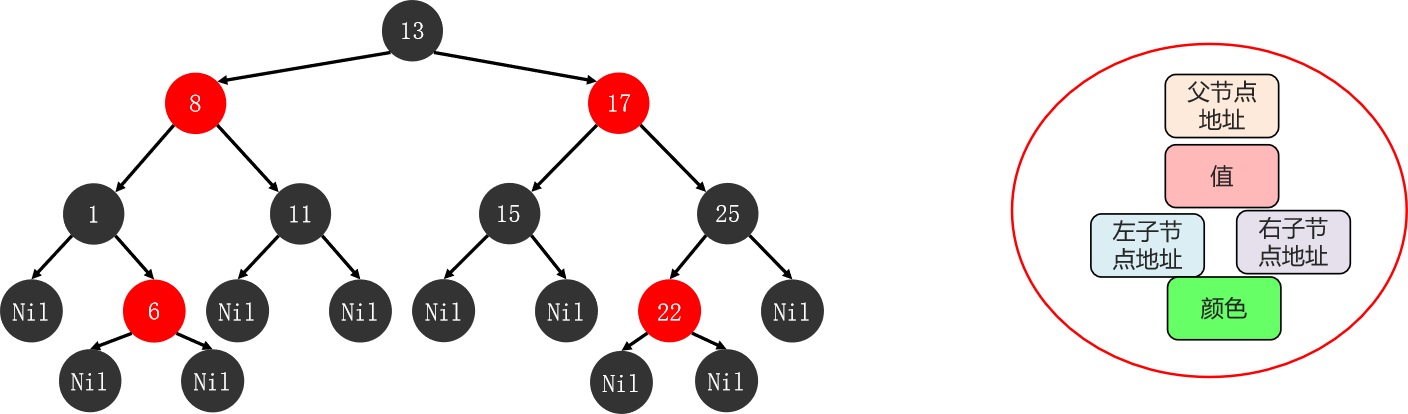
红黑树是一种自平衡的二叉查找树,是计算机科学中用到的一种数据结构。
是一种特殊的二叉查找树,红黑树的每一个节点上都有存储位表示节点的颜色
每一个节点可以是红或者黑;红黑树不是高度平衡的,它的平衡是通过"红黑规则"进行实现的
15.5.2.2 平衡二叉树和红黑树区别
- 平衡二叉树:
高度平衡,当左右子树高度差超过1时,通过旋转保持平衡。 - 红黑树:
是一个二叉查找树,高度不平衡,特有的红黑规则。
15.5.2.3 红黑规则
- 每一个节点是红色的,或者是黑色的
- 根节点必须是黑色
- 如果一个节点没有子节点或者父节点,则该节点相应的指针属性值为Nil,这些Nil视为叶节点,每个叶节点(Nil)是黑色的
- 如果某一个节点是红色,那么它的子节点必须是黑色(不能出现两个红色节点相连的情况)
- 对每一个节点,从该节点到其所有后代叶节点的简单路径上,均包含相同数目的黑色节点
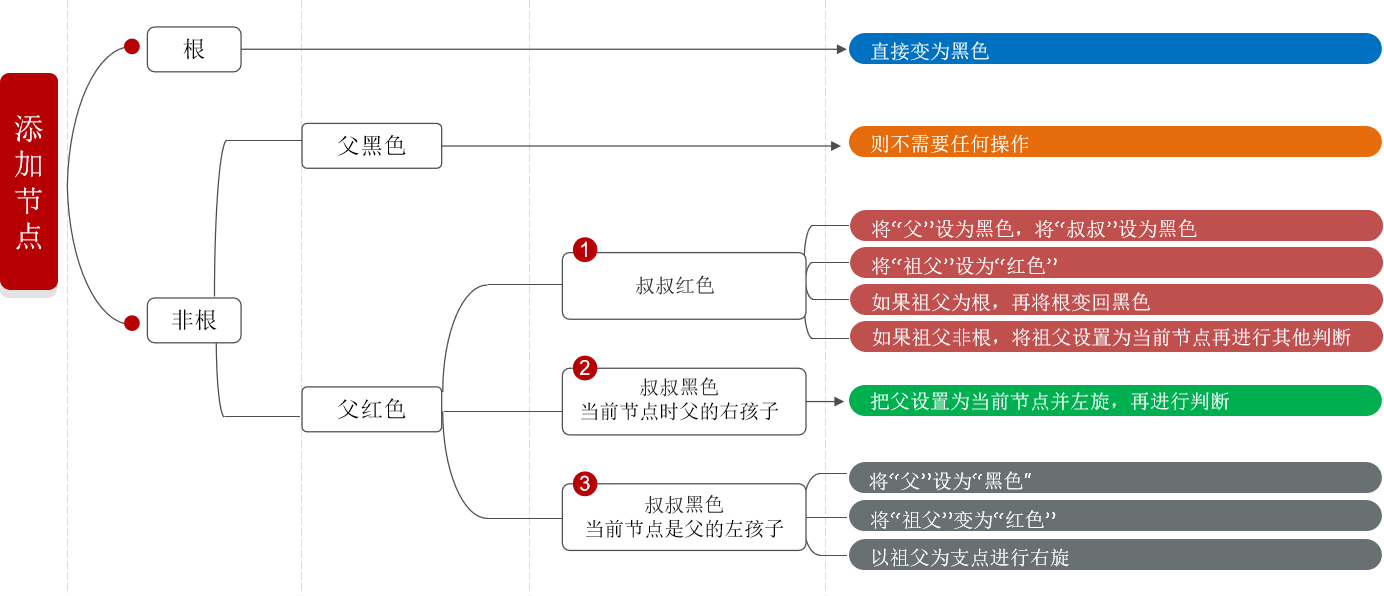
添加节点规则:
红黑树在添加节点的时候,添加的节点默认是红色的
16 泛型
JDK5引入的, 可以在编译阶段约束操作的数据类型, 并进行检查
16.1 泛型类
创建对象的时候确定具体类型
16.2 泛型方法
非静态方法:
public class ArrayList<E> {
public boolean add(E e) {
}
}
静态方法
public static<T> void printArray(T[] array){
}
16.3 泛型接口
类实现接口的时候,直接确定类型
延续接口的泛型,等创建对象的时候再确定
16.4 泛型通配符
? (任意类型)
? extends E (只能接收 E 或者是 E 的子类)
? super E (只能接收 E 或者是 E 的父类)