前言
😺Hello,大家好,我是
GISer Liu,😀😀 一名热爱AI技术的GIS开发者;在上一篇文章中,我们学习了LLM API的申请、应用以及提示词工程;
在本文中,作者将介绍如何从零开始构建个人知识库🎉🤓;主要内容包括:
- 词向量和向量数据库概念
- 申请Embedding Model API
- 使用LangChain工具对文本数据进行处理
- 基于文本数据搭建向量数据库并进行测试
一、词向量和向量数据库
1. 向量
① 概念
向量是一个既有方向又有大小的量,可以在空间中用来表示点或对象之间的关系。在数学和物理学中,向量表示大小和方向的物理量,如速度、加速度等。在自然语言处理中,向量用于表示词语、句子或文档的语义信息,使得机器能够理解和处理自然语言。
数学上,向量可以表示为一组有序数字的列表,通常写成列向量的形式。例如,一个三维空间中的向量可以表示为:
v = [ v 1 , v 2 , v 3 ] T v = [v_1, v_2, v_3]^T v=[v1,v2,v3]T
其中, v 1 v_1 v1、 v 2 v_2 v2和 v 3 v_3 v3是向量的分量,上标 T T T表示向量的转置。
② 特点
-
高维度:向量通常是高维度的,每一维度代表对象的某一特征。在机器学习和深度学习中,常用一组向量来表示训练集的特征;例如,一个词向量可能包含300维或更多,每一维捕捉不同的语义特征。
-
相似性度量:可以通过计算向量之间的距离(如余弦相似度、欧几里得距离)来度量对象之间的相似性。余弦相似度衡量两个向量之间的角度,而欧几里得距离则是两个向量在空间中的直线距离。
③ 向量的度量公式
- 余弦相似度(Cosine Similarity):余弦相似度是通过计算两个向量的内积除以其模的乘积来度量相似度。公式如下:
cosine_similarity ( A , B ) = A ⋅ B ∥ A ∥ ∥ B ∥ \ \text{cosine\_similarity}(A, B) = \frac{A \cdot B}{\|A\| \|B\|} \ cosine_similarity(A,B)=∥A∥∥B∥A⋅B
其中, ( A ⋅ B ) (A \cdot B) (A⋅B) 是向量A和B的内积, ∥ A ∥ \|A\| ∥A∥ 和 ∥ B ∥ \|B\| ∥B∥ 分别是向量A和B的模。余弦相似度的取值范围从-1到1,其中1表示向量完全相同,0表示它们正交(或无关),-1表示它们完全相反。
- 欧几里得距离(Euclidean Distance):欧几里得距离是通过计算两个向量之间的直线距离来度量相似度。公式如下:
euclidean_distance ( A , B ) = ∑ i = 1 n ( A i − B i ) 2 \ \text{euclidean\_distance}(A, B) = \sqrt{\sum_{i=1}^{n} (A_i - B_i)^2} \ euclidean_distance(A,B)=i=1∑n(Ai−Bi)2
其中, A i A_i Ai 和 B i B_i Bi 分别是向量A和B的第i个分量。
- 欧几里得距离(Euclidean Distance):一种衡量两个向量之间距离的方法,通过
计算两个向量在空间中的直线距离来表示相似度,距离越小,向量越相似。
2. 词向量
① 概念
在自然语言处理的背景下,一个词向量通常是使用Word2Vec或GloVe等技术学习得到的。这些方法旨在捕捉词语在高维向量空间中的语义和句法关系。这种方法的思想是:在相似的上下文中使用的词语将具有相似的向量,从而允许我们对词语执行数学运算以理解它们的含义。
v
例如,
“king”这个词的向量可能接近“queen”这个词的向量,而远离“apple”这个词的向量,这反映了“king”和“queen”之间的相关性,而“king”和“apple”之间没有相关性。这使我们能够执行诸如“king” - “man” + “woman”的操作,得到一个接近“queen”的向量,这是一种词类推理的形式。

② 特点
- 语义保持:相似的词在向量空间中的距离较近。例如,“国王”和“王后”的词向量会比“国王”和“苹果”的词向量距离更近。
- 高效计算:词向量便于进行数学运算和相似性计算。例如,可以通过简单的向量加减操作,计算词语之间的关系(如“国王” - “男人” + “女人” ≈ “王后”)。
③ 词向量计算应用
在NLP中,词向量的运算经常用于各种任务,作者总结如下:
-
词性消除(Word Analogy):正如上文提到的案例,通过执行类似于"king" - “man” + "woman"的操作,我们可以找到一个与"queen"相似的词。这种技术被广泛用于语言模型和词嵌入的评估。
-
情感分析(Sentiment Analysis):在情感分析任务中,词向量可以用于表示文档或句子的情感。例如,一个文档的情感可以被表示为其中所有词向量的平均值。然后,可以使用这些情感向量来训练分类器,以预测文档的情感是正面的还是负面的。
-
文本分类(Text Classification):词向量可以用于表示文档或句子的主题。例如,一个文档的主题可以被表示为其中所有词向量的平均值。然后,可以使用这些主题向量来训练分类器,以将文档分配到不同的类别。
-
机器翻译(Machine Translation):在机器翻译任务中,词向量可以用于表示词语在源语言和目标语言之间的语义关系。例如,一个词向量可以被表示为一个矩阵的乘积,其中矩阵捕捉了源语言和目标语言之间的语义转换。然后,可以使用这些转换向量来生成目标语言中的翻译。
-
问答系统(Question Answering Systems):在问答系统中,词向量可以用于表示问题和答案之间的相似性。例如,一个问题可以被表示为其中所有词向量的平均值,一个答案也是如此。然后,可以使用这些问题和答案向量之间的相似性来选择最佳答案。
这也是RAG技术的核心原理;🙂
③ 构建词向量的方法
-
使用大模型厂商提供的Embedding API
- 优势:
便于使用,模型性能优秀,能够处理大量数据。例如,OpenAI的GPT-3和Google的BERT API可以直接使用现有的高质量词向量。 - 劣势:
依赖外部服务,可能存在成本和隐私问题。例如,调用外部API服务可能需要支付高额费用,并且数据需要传输到外部服务器,可能存在数据泄露风险。
- 优势:
-
本地搭建嵌入模型
- 优势:
数据私密性好,无需依赖外部服务,可根据需要自定义模型。例如,公司内部的数据可以通过本地搭建的Word2Vec或BERT模型进行训练,确保数据不外泄。 - 劣势:
需要大量计算资源和时间来训练模型。例如,训练一个高质量的Mistral或Qwen模型需要高性能的GPU集群和大量的训练数据,普通玩家带不动。
- 优势:
④ 词向量生成示例
- Word2Vec:假设有以下简化的句子:
“I like deep learning”。Word2Vec模型通过上下文窗口来训练词向量,例如,窗口大小为2时,“like”的上下文是“I”和“deep”。模型将这些上下文词汇与目标词汇一起训练,生成词向量。
训练文本:
(I, like), (like, I), (like, deep), (deep, like), (deep, learning), (learning, deep)
可能生成的词向量:
I -> [0.2, -0.1, 0.3, ...]
like -> [0.4, 0.2, -0.5, ...]
deep -> [-0.3, 0.8, 0.1, ...]
learning -> [0.5, -0.7, 0.2, ...]
3. 向量数据库
① 什么是向量数据库
向量数据库是专门用于存储、索引和检索高维向量数据的数据库。它广泛应用于推荐系统、图像识别和语义搜索等领域。与传统的关系型数据库不同,向量数据库能够高效处理非结构化数据和高维向量。
② 向量数据库的原理
向量数据库通过将数据对象表示为向量,并使用相似性度量方法(如余弦相似度、欧几里得距离等)来实现高效的相似性搜索。例如,给定一个查询向量,向量数据库可以快速找到与之最相似的向量,并返回对应的对象。
- 具体的数学公式已在上文中给出;
- Embedding的过程:将数据转换为向量的过程通常被称为“嵌入”。嵌入是一种技术,用于
将数据从高维空间映射到低维空间,同时保留数据的结构。在向量数据库的背景下,嵌入用于将数据对象转换为可以高效存储和搜索的向量。
③ 向量数据库的特点及优势
- 速度与性能:使用各种索引技术(如
HNSW、LSH等)来实现快速搜索。例如,HNSW(Hierarchical Navigable Small World)索引能够在大规模数据集上实现毫秒级的相似性搜索。 - 可扩展性:能够存储和管理大量的非结构化数据,并随着数据量的增加保持性能稳定。例如,向量数据库可以轻松扩展到数亿级的向量数据,同时保持高效的查询性能。
- 灵活性:能够处理多种类型的数据,包括文本、图像、音频等(各种类型的数据都可以转化为向量存储)。例如,在图像搜索应用中,可以将图像表示为向量,并通过向量数据库进行相似图像搜索(
这也是百度或谷歌识图的原理)。
- HNSW(Hierarchical Navigable Small World):一种高效的近似最近邻搜索算法,通过构建层次化的小世界图,实现快速的向量相似性搜索。
- LSH(Locality-Sensitive Hashing):一种用于高维数据相似性搜索的哈希算法,通过将相似的数据映射到相同的哈希桶,实现快速的近似相似性搜索。
④ 主流的向量数据库
- 开源
- Faiss:由Meta(原FaceBook) AI Research开发,适用于
高效相似性搜索。Faiss支持多种索引方法,如IVF(Inverted File)、HNSW等,并能够处理大规模数据集。 - Chroma:支持多种向量索引和检索方法,适用于各种应用场景。Chroma通过结合多种索引技术,实现高效的向量搜索和管理。
- Weaviate:支持多种媒体类型的数据嵌入和搜索。Weaviate不仅支持文本向量,还支持图像、视频等多媒体向量的存储和检索。
- Qdrant:高性能、可扩展的向量搜索引擎,适合大规模数据集。Qdrant采用了多种优化技术,实现了高效的向量索引和检索。
- Faiss:由Meta(原FaceBook) AI Research开发,适用于
本文中,作者将以Faiss向量数据库为例:构建向量数据库😂
- 商业
- Pinecone:提供高性能向量搜索和存储解决方案,集成简单,适合企业应用。Pinecone支持多种向量索引方法,并提供API接口,方便企业集成和使用。
- Milvus:支持亿级数据量的向量搜索,具备高扩展性和高可用性。Milvus由Zilliz开发,广泛应用于推荐系统、图像识别等领域,提供了多种索引方法和查询优化技术。
⑤向量数据库应用(可选)
- 推荐系统:在电子商务平台中,通过分析用户的浏览历史和购买行为,将用户和商品表示为向量,并使用向量数据库实现个性化推荐。例如,亚马逊使用商品向量和用户向量计算相似度,为用户推荐可能感兴趣的商品。
- 图像识别:在图像搜索引擎中,将图像表示为向量,并通过向量数据库实现相似图像搜索。例如,Google Photos通过图像嵌入向量,实现了快速的相似图像检索和管理。
- 语义搜索:在搜索引擎中,通过将查询和文档表示为向量,并使用向量数据库实现语义匹配。例如,ElasticSearch结合向量搜索功能,实现了更加智能的语义搜索,提高了搜索结果的相关性。
二、使用Embedding API
1.Embedding API申请
①OpenAI
在上一篇文章中,作者已经给出了申请OpenAI API的过程,因此这里我们只介绍使用的Embedding模型:

上图是官网的截图,作者这里优化了一下:
| 模型名称 | 描述 | 输出维度 | 价格 |
|---|---|---|---|
| text-embedding-3-large | 适用于英语和非英语任务的最强大的嵌入模型 | 3,072 | 9615 token/$ |
| text-embedding-3-small | 比第二代ada嵌入模型性能更好 | 1,536 | 62500 token/$ |
| text-embedding-ada-002 | 最强大的第二代嵌入模型,取代了16个第一代模型 | 1,536 | 12500 token /$ |
显而易见,
text-embedding-3-small最具性价比
②文心千帆
| 模型名称 | 描述 | 更新时间 | 语言 |
|---|---|---|---|
| Embedding-V1 | 基于百度文心大模型技术的文本表示模型,将文本转化为用数值表示的向量形式,用于文本检索、信息推荐、知识挖掘等场景。 | 2024-06-20 | 中文 |
| bge-large-zh | 由智源研究院研发的中文版文本表示模型,可将任意文本映射为低维稠密向量,以用于检索、分类、聚类或语义匹配等任务,并可支持为大模型调用外部知识。 | 2024-06-20 | 中文 |
| bge-large-en | 由智源研究院研发的英文版文本表示模型,可将任意文本映射为低维稠密向量,以用于检索、分类、聚类或语义匹配等任务,并可支持为大模型调用外部知识。 | 2024-06-20 | 英文 |
| tao-8k | 由Huggingface开发者amu研发并开源的长文本向量表示模型,支持8k上下文长度,模型效果在C-MTEB上居前列,是当前最优的中文长文本embeddings模型之一。 | 2024-06-20 | 中文 |
所有模型的功能都是根据输入内容生成对应的向量表示。
③ Mistral
通用,之前的文章中已经给出了详细的API申请方案,这里Mistral当前只有一个Embedding模型:
| 模型名称 | 描述 | 输出维度 | 最大Token | 调用参数 |
|---|---|---|---|---|
| Mistral Embeddings | 一个将文本转换成1024维数值向量的模型。嵌入模型使得检索和检索增强生成应用成为可能。它在MTEB上实现了55.26的检索分数。 | 1024 | 8k | mistral-embed |
相关参数可以看看官方文档:https://docs.mistral.ai/capabilities/embeddings/
③智谱AI

| 模型名称 | 描述 |
|---|---|
| Embedding-2 | 文本向量模型,将输入的文本信息进行向量化表示,以便于结合向量数据库为大模型提供外部知识库,提高大模型推理的准确性。 |
官网文档:https://open.bigmodel.cn/dev/api#emohaa
2. Embedding API代码测试
①OpenAI
- 测试调用代码如下:
import os
from openai import OpenAI
from dotenv import load_dotenv, find_dotenv
# 读取本地/项目的环境变量。
# find_dotenv()寻找并定位.env文件的路径
# load_dotenv()读取该.env文件,并将其中的环境变量加载到当前的运行环境中
# 如果你设置的是全局的环境变量,这行代码则没有任何作用。
_ = load_dotenv(find_dotenv())
# 如果你需要通过代理端口访问,你需要如下配置
os.environ['HTTPS_PROXY'] = 'http://127.0.0.1:7890'
os.environ["HTTP_PROXY"] = 'http://127.0.0.1:7890'
def openai_embedding(text: str, model: str=None):
# 获取环境变量 OPENAI_API_KEY
api_key=os.environ['OPENAI_API_KEY']
client = OpenAI(api_key=api_key)
# embedding model:'text-embedding-3-small', 'text-embedding-3-large', 'text-embedding-ada-002'
if model == None:
model="text-embedding-3-small"
response = client.embeddings.create(
input=text,
model=model
)
return response
response = openai_embedding(text='要生成 embedding 的输入文本,字符串形式。')
- 代码结果
作者没有额度了...,大家可以测试一下
② Mistral
代码如下:
# Mistral测试
import os
from mistralai.client import MistralClient
api_key = api_key = os.getenv('MISTRAL_API_KEY')
client = MistralClient(api_key=api_key)
embeddings_response = client.embeddings(
model="mistral-embed",
input=["什么是GIS?", "如何学习GIS."],
)
print(embeddings_response.data[0].embedding)
运行结果如下:
[-0.025238037109375, -0.0018138885498046875, 0.0482177734375, -0.0030612945556640625, -0.0041656494140625, -0.0060272216796875, 0.037994384765625, 0.0193634033203125, -0.0011968612670898438, -0.0174560546875, -0.05242919921875, 0.05255126953125, 0.0081787109375, -0.003032684326171875, -0.03790283203125, 0.028076171875, -0.0045318603515625, 0.0204925537109375, 0.005374908447265625, -0.007598876953125, -0.020172119140625, 0.0255279541015625, -0.031341552734375, 0.059814453125, -0.0181732177734375, -0.02008056640625, -0.0401611328125, -0.020599365234375, -0.022064208984375, -0.01178741455078125, 0.001678466796875, -0.0137939453125, -0.018524169921875, 0.0186309814453125, -0.0006866455078125, -0.00031375885009765625, -0.003204345703125, -0.035675048828125, 0.0206146240234375, -0.01253509521484375, 0.00957489013671875, -0.0013856887817382812, -0.010833740234375, -0.03802490234375, -0.021759033203125, -0.0135040283203125, 0.020751953125, -0.01392364501953125, 0.0186309814453125, -0.04107666015625, 0.01346588134765625, 0.048126220703125, 0.02197265625, -0.0011663436889648438, -0.0174713134765625, -0.00502777099609375, 0.0231170654296875, -0.06884765625,...]
③智谱AI
调用代码:
from zhipuai import ZhipuAI
client = ZhipuAI(api_key="your api key")
response = client.embeddings.create(
model="embedding-2", #填写需要调用的模型名称
input="你好",
)
本地搭建开源Embedding模型

此模型可以基于Ollama调用,下面是调用代码:
ollama部署nomic-embed-text:
ollama pull nomic-embed-text
python调用:
import ollama
ollama.embeddings(model='nomic-embed-text', prompt='The sky is blue because of rayleigh scattering')
```bash
略
三、文本数据处理
0.环境配置
- 安装第三方库
# 基于Mistral AI 和 Faiss的向量数据库
# %pip install -qU langchain-mistralai
# %pip install -qU nltk
# %pip install -qU langchain_community
# !sudo apt-get install sqlite3 libsqlite3-dev
# %pip install langchain_openai
# %pip install unstructured
# %pip install "unstructured[pdf]"
# %pip install markdown
# %pip install pypdf
# %pip install faiss-cpu
# %pip install -qU langchain-text-splitters
作者使用的是Linux服务器上的Jupyter,windows用户可以使用
!替代%或者直接使用%;
- 导入必要库
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain.text_splitter import CharacterTextSplitter,NLTKTextSplitter
from langchain_community.document_loaders import DirectoryLoader,UnstructuredMarkdownLoader,PyPDFLoader#用于加载各种文件数据
#import magic
import os
import nltk
1.源文档选取
作者是GIS开发者,工作中经常遇到GIS理论和原理性问题,为了保证GIS开发快速理解GIS理论,避免低效检索,作者这里决定构建一个包含GIS、遥感等原理的文章作为知识库,方便工作中快速查阅,能更好的进行优化WorkFlow,作者选择的案例文件如图,数据保存在./folder/文件目录下:

各位读者可以自行选择需要导入到数据库中的文件;🤓
2. 数据读取
由上图可知,我们的数据主要包含以下三种格式:
- TXT
- Markdown
因此我们需要构建三个文件加载器TextLoader,PyPDFLoader,UnstructuredMarkdownLoader;
数据读取代码如下:
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
import getpass
import os
from dotenv import load_dotenv, find_dotenv
# 读取本地/项目的环境变量。
_ = load_dotenv(find_dotenv())
api_key = os.getenv('MISTRAL_API_KEY')
from langchain_mistralai import ChatMistralAI
llm = ChatMistralAI(model="mistral-large-latest") # 创建LLM
# 选择加载的文件,作为GIS开发者,作者选择了Markdown、PDF、TXT三种格式的数据,保存为/folder文件夹下
# 分别构建三个类型的DocumentLoader
txt = TextLoader("./folder/GIS原理与应用名词解释.txt").load()
pdf = PyPDFLoader("./folder/85个你必须知道的常用遥感名词.pdf").load()
md = UnstructuredMarkdownLoader("./folder/遥感物理基础.md").load()
print(txt[0].page_content[:100],len(txt[0].page_content))
print(pdf[0].page_content[:100],len(pdf[0].page_content))
print(md[0].page_content[:100],len(md[0].page_content))
运行查看结果:

这说明我们得到的是多个列表,其中的每个元素都是一个文本对象,可以通过其page_content属性查看对应的文本内容;
我们能看到,其输出的结果中,文本格式和原有文件中一样带有空行;
3. 数据清洗
数据清洗是处理文本数据的关键步骤之一,目的是去除无用信息、噪声和错误,提高数据质量。在本例中,由于文档中存在大量空行和无关字符,如果不进行处理,经过嵌入(Embedding)后会产生大量无用信息,影响数据库存储效率和向量相似度计算精度。
因此,我们需要对文本数据进行清洗,主要包括以下两个方面:
- 删除无用空行:使用正则表达式匹配连续的空行,并将其替换为单个空行。
- 删除无关字符:根据具体应用场景和文档类型,删除文本中无关的字符,如空格、标点符号等。但是需要注意,对于某些特定类型的文档,如代码文档,需要保留缩进和某些符号,以保证语义的完整性和可读性。
以下是数据清洗代码:
# 数据清洗
import re
# 定义清洗模式
pattern = re.compile(r'[^\S\n]|(\n{2,})', re.MULTILINE)
# 遍历所有文档
for doc in txt + pdf + md:
# 对每个文档进行清洗
doc.page_content = re.sub(pattern, lambda match: '\n' if match.group(1) else '', doc.page_content)
# 打印每个文档的前100个字符和长度
for doc in txt + pdf + md:
print(doc.page_content[:100], len(doc.page_content))
在这段代码中,作者使用正则表达式匹配空白字符和连续的空行,并将其替换为单个空行。同时,我们保留了文本中的其他符号,以保证语义的完整性和可读性。通过这样的清洗处理,我们可以提高文本数据的质量,提高存储效率和向量相似度计算精度。
运行查看结果:

可以看到,空行已经被删除完毕;
- 数据清洗的标准取决于我们知识库的应用场景和文档类型;
- 对于代码文档,我们要保持缩进,不能删除符号;
- 对于文本,我们可以删除缩进,但是不能删除太多符号;保证语义完整,易于区分;
4. 文档分割
在构建向量知识库时,由于单个文档的长度通常会超过模型支持的上下文(Token)长度,因此需要对文档进行分割,将其切分成多个较小的块(chunk),然后将每个块转化为词向量,存储到向量数据库中。这样在检索时,可以以块为单位进行检索,每次检索到 k 个块,作为模型可以参考的知识来回答用户问题。
Langchain 提供了多种文档分割方式,每种方式在确定块与块之间的边界、块由哪些字符/token组成、以及如何测量块大小方面都有所不同。以下是一些常用的文本分割方式:
RecursiveCharacterTextSplitter(): 按字符串分割文本,递归地尝试按不同的分隔符进行分割文本。CharacterTextSplitter(): 按字符来分割文本。MarkdownHeaderTextSplitter(): 基于指定的标题来分割 markdown 文件。TokenTextSplitter(): 按 token 来分割文本。SentenceTransformersTokenTextSplitter(): 使用 Sentence-Transformers 库按 token 来分割文本。Language(): 用于 CPP、Python、Ruby、Markdown 等编程语言文件的分割。NLTKTextSplitter(): 使用 NLTK(自然语言工具包)按句子分割文本。SpacyTextSplitter(): 使用 Spacy 按句子的切割文本。
在使用这些分割方法时,需要根据具体的应用场景和文档类型选择适合的分割方式,以及设定合适的分割参数,如块大小( c h u n k _ s i z e chunk\_size chunk_size)和块与块之间的重叠大小( c h u n k _ o v e r l a p chunk\_overlap chunk_overlap)。
作者这里使用了 RecursiveCharacterTextSplitter 进行文本分割:
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 创建一个分割器实例
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=200, chunk_overlap=50,
length_function=len,
is_separator_regex=False,
)
# 遍历所有文档
all_text = ""
for doc in txt + pdf + md:
content = doc.page_content
# 将文档的 page_content 属性连接到 all_text 中
all_text += content
# 对文本进行分割
split_docs = text_splitter.create_documents([all_text])
# 打印分割后的文档块和块的数量
print(split_docs, len(split_docs))
运行代码,查看结果:

可以看到,文档文本数据已经被切分为546块大小;
因为作者的数据资料都是一些名词解释,因此设定了块大小为 200,块与块之间的重叠大小为 50。保证向量检索语义不会丢失太多;😲通过这样的分割处理,我们可以将长文档切分成适合模型处理的块,
提高检索和回答问题的效率和精度。
作者这里整理了一下LangChain支持的文档分割方法,感兴趣的读者可以自行学习:
| 名称 | 类别 | 拆分方式 | 添加元数据 | 描述 |
|---|---|---|---|---|
| 递归式 | RecursiveCharacterTextSplitter, RecursiveJsonSplitter | 用户定义的字符列表 | 否 | 递归地拆分文本。这种拆分尝试保持相关文本片段彼此靠近。这是开始拆分文本的推荐方式。 |
| HTML | HTMLHeaderTextSplitter, HTMLSectionSplitter | HTML特定字符 | 是 | 根据HTML特定字符拆分文本。值得注意的是,这将添加有关该片段来源的相关信息(基于HTML)。 |
| Markdown | MarkdownHeaderTextSplitter | Markdown特定字符 | 是 | 根据Markdown特定字符拆分文本。值得注意的是,这将添加有关该片段来源的相关信息(基于Markdown)。 |
| 代码 | 多种语言 | 代码(Python、JS)特定字符 | 否 | 根据特定于编程语言的字符拆分文本。有15种不同的语言可供选择。 |
| 令牌 | 多个类别 | 令牌 | 否 | 根据令牌拆分文本。存在几种不同的方法来测量令牌。 |
| 字符 | CharacterTextSplitter | 用户定义的字符 | 否 | 根据用户定义的字符拆分文本。这是较简单的方法之一。 |
| [实验性] 语义块 | SemanticChunker | 句子 | 否 | 首先按句子拆分。然后,如果它们在语义上足够相似,就将彼此靠近的句子组合在一起。由Greg Kamradt提供。 |
5.构建向量数据库
我们已经切分好了文本数据,现在我们需要将切分好的文本数据转化为向量格式,并且存储到向量数据库中,这里由于作者的OpenAI 的API key没有余额了 🤐🤐,作者使用Mistral封装了一个LangChain可用的Embedding模型;封装代码如下:
# 封装Mistral Embedding
from __future__ import annotations
import logging
import os
from typing import Dict, List, Any
from langchain.embeddings.base import Embeddings
from langchain.pydantic_v1 import BaseModel, root_validator
logger = logging.getLogger(__name__)
class MistralAIEmbeddings(BaseModel, Embeddings):
"""`MistralAI Embeddings` embedding models."""
client: Any
"""`mistralai.MistralClient`"""
@root_validator()
def validate_environment(cls, values: Dict) -> Dict:
"""
实例化MistralClient为values["client"]
Args:
values (Dict): 包含配置信息的字典,必须包含 client 的字段.
Returns:
values (Dict): 包含配置信息的字典。如果环境中有mistralai库,则将返回实例化的MistralClient类;否则将报错 'ModuleNotFoundError: No module named 'mistralai''.
"""
from mistralai.client import MistralClient
api_key = os.getenv('MISTRAL_API_KEY')
if not api_key:
raise ValueError("MISTRAL_API_KEY is not set in the environment variables.")
values["client"] = MistralClient(api_key=api_key)
return values
def embed_query(self, text: str) -> List[float]:
"""
生成输入文本的 embedding.
Args:
texts (str): 要生成 embedding 的文本.
Return:
embeddings (List[float]): 输入文本的 embedding,一个浮点数值列表.
"""
embeddings = self.client.embeddings(
model="mistral-embed",
input=[text]
)
return embeddings.data[0].embedding
def embed_documents(self, texts: List[str]) -> List[List[float]]:
"""
生成输入文本列表的 embedding.
Args:
texts (List[str]): 要生成 embedding 的文本列表.
Returns:
List[List[float]]: 输入列表中每个文档的 embedding 列表。每个 embedding 都表示为一个浮点值列表。
"""
return [self.embed_query(text) for text in texts]
开始向量化,构建向量数据库,并且保存向量数据库到本地;作者这里使用的Faiss向量数据库,Chroma有Sqlite3的Bug,时间太短,暂时搁置😣
# 对文本数据进行向量化,这里作者使用自己封装的Mistral Embedding
embeddings_model = MistralAIEmbeddings()
# 构建向量数据框
db = FAISS.from_documents(split_docs, embeddings_model)
# # 保存向量数据库到本地
db.save_local("./db/GIS_db")
代码运行后,可以看到,当前文件./db/目录下面已经多出来一个向量数据库GIS_db;

OK,🎉🎉🎉🎉🏆现在我们向量数据库已经构建完毕,下面测试一下!
6.进行向量相似度检索
现在,我们输入“电磁辐射”,然后对其进行向量相似性查询,计算出相似度最高的3个文档切块:
代码如下:
# 使用向量数据库进行检索
# 加载向量数据库
loaded_db = FAISS.load_local("./db/GIS_db", embeddings_model, allow_dangerous_deserialization=True) # 允许来自危险源的数据库
# 计算相似度并检索最相似的文档
query = "电磁辐射"
docs = loaded_db.similarity_search(query, k=3) # 相似度最高的前3个chunk
# 输出检索结果
for doc in docs:
print(doc.page_content+"\n-----------------\n")
输出结果如下:

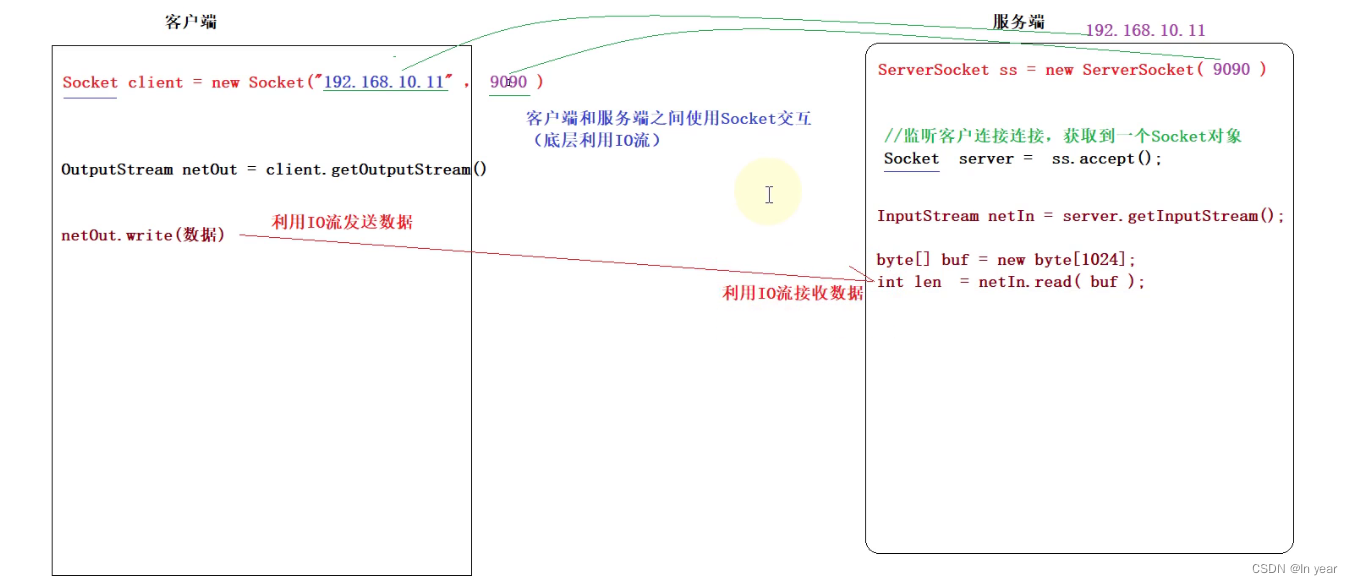
如此一来,我们就得到了与用户prompt最接近的辅助信息,这些辅助信息会经过Prompt Engine提示词工程被打包为一个Prompt发送给LLM,这样得到的回答就有了一定的保证和可信度;这就是RAG的核心思想;总体思路也可以用下面这张图来表示,各位读者可以阅读一下:

OK,今天就到这儿了!🤓🤓🤓🏆🏆🎉
5. 完整代码
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain.text_splitter import CharacterTextSplitter,NLTKTextSplitter
from langchain_community.document_loaders import DirectoryLoader,UnstructuredMarkdownLoader,PyPDFLoader#用于加载各种文件数据
#import magic
import os
import nltk
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
import re
import getpass
from dotenv import load_dotenv, find_dotenv
# 读取本地/项目的环境变量。
_ = load_dotenv(find_dotenv())
api_key = os.getenv('MISTRAL_API_KEY')
from langchain_mistralai import ChatMistralAI
llm = ChatMistralAI(model="mistral-large-latest") # 创建LLM
# 选择加载的文件,作为GIS开发者,作者选择了Markdown、PDF、TXT三种格式的数据,保存为/folder文件夹下
# 分别构建三个类型的DocumentLoader
txt = TextLoader("./folder/GIS原理与应用名词解释.txt").load()
pdf = PyPDFLoader("./folder/85个你必须知道的常用遥感名词.pdf").load()
md = UnstructuredMarkdownLoader("./folder/遥感物理基础.md").load()
print(txt[0].page_content[:100],len(txt[0].page_content))
print(pdf[0].page_content[:100],len(pdf[0].page_content))
print(md[0].page_content[:100],len(md[0].page_content))
# 数据清洗
# 定义清洗模式
pattern = re.compile(r'[^\u4e00-\u9fff](\n)[^\u4e00-\u9fff]', re.DOTALL)
# 遍历所有文档
for doc in txt + pdf + md:
# 对每个文档进行清洗
doc.page_content = re.sub(pattern, lambda match: match.group(0).replace('\n', ''), doc.page_content)
# 打印每个文档的前100个字符和长度
for doc in txt + pdf + md:
print(doc.page_content[:100], len(doc.page_content))
# 封装Mistral Embedding
from __future__ import annotations
import logging
import os
from typing import Dict, List, Any
from langchain.embeddings.base import Embeddings
from langchain.pydantic_v1 import BaseModel, root_validator
logger = logging.getLogger(__name__)
class MistralAIEmbeddings(BaseModel, Embeddings):
"""`MistralAI Embeddings` embedding models."""
client: Any
"""`mistralai.MistralClient`"""
@root_validator()
def validate_environment(cls, values: Dict) -> Dict:
"""
实例化MistralClient为values["client"]
Args:
values (Dict): 包含配置信息的字典,必须包含 client 的字段.
Returns:
values (Dict): 包含配置信息的字典。如果环境中有mistralai库,则将返回实例化的MistralClient类;否则将报错 'ModuleNotFoundError: No module named 'mistralai''.
"""
from mistralai.client import MistralClient
api_key = os.getenv('MISTRAL_API_KEY')
if not api_key:
raise ValueError("MISTRAL_API_KEY is not set in the environment variables.")
values["client"] = MistralClient(api_key=api_key)
return values
def embed_query(self, text: str) -> List[float]:
"""
生成输入文本的 embedding.
Args:
texts (str): 要生成 embedding 的文本.
Return:
embeddings (List[float]): 输入文本的 embedding,一个浮点数值列表.
"""
embeddings = self.client.embeddings(
model="mistral-embed",
input=[text]
)
return embeddings.data[0].embedding
def embed_documents(self, texts: List[str]) -> List[List[float]]:
"""
生成输入文本列表的 embedding.
Args:
texts (List[str]): 要生成 embedding 的文本列表.
Returns:
List[List[float]]: 输入列表中每个文档的 embedding 列表。每个 embedding 都表示为一个浮点值列表。
"""
return [self.embed_query(text) for text in texts]
# 数据切分
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 切分文档
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=200, chunk_overlap=50,
length_function=len,
is_separator_regex=False,
)
# 遍历所有文档
all_text = ""
for doc in txt + pdf + md:
content = doc.page_content
# 将文档的 page_content 属性连接到 all_text 中
all_text += content
split_docs = text_splitter.create_documents([all_text])
print(split_docs,len(split_docs))
# 对文本数据进行向量化,这里作者使用自己封装的Mistral Embedding
embeddings_model = MistralAIEmbeddings()
# 构建向量数据框
db = FAISS.from_documents(split_docs, embeddings_model)
# # 保存向量数据库到本地
db.save_local("./db/GIS_db")
# 使用向量数据库进行检索
# 加载向量数据库
loaded_db = FAISS.load_local("./db/GIS_db", embeddings_model, allow_dangerous_deserialization=True)
# 计算相似度并检索最相似的文档
query = "电磁辐射"
docs = loaded_db.similarity_search(query, k=3) # 相似度最高的前3个chunk
# 输出检索结果
for doc in docs:
print(doc.page_content+"\n-----------------\n")
文章参考
- OpenAI官方文档
- DeepSeek官方文档
- Mistral官方文档
- ChatGLM官方文档
项目地址
- Github地址
- 拓展阅读
- 专栏文章

如果觉得我的文章对您有帮助,三连+关注便是对我创作的最大鼓励!或者一个star🌟也可以😂.