自学python如何成为大佬(目录):https://blog.csdn.net/weixin_67859959/article/details/139049996?spm=1001.2014.3001.5501
open()函数用于打开文件,返回一个文件读写对象,然后可以对文件进行相应读写操作。
语法参考
open()函数的语法格式如下:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
参数说明:
l file:必需参数,文件路径,表示需要打开文件的相对路径(相对于程序所在路径,例如,要创建或打开程序所在路径下的“mr.txt”文件,则可以直接写成相对路径“mr.txt”,如果是程序所在路径下的“soft”子路径下的“mr.txt”文件,则可写成“soft/mr.txt”)或者绝对路径(需要输入包含盘符的完整文件路径,如'D:/mr.txt')。文件路径注意需要使用单引号或双引号括起来。
多学两招:在指定文件路径时,也可以在表示路径的字符串前面加上字母r(或R),那么该字符串将原样输出,这时路径中的分隔符就不需要再转义了。例如,路径'D:/mr.txt'也可以写作r'D:/mr.txt'。
l mode:可选参数,用于指定文件的打开模式。常见的打开模式有r(以只读模式打开)、w(以只写模式打开)、a(以追加模式打开),默认的打开模式为只读(即r)。实际调用的时候可以根据情况进行组合,mode参数的参数值及说明如表1所示。
表1 mode参数的参数值及说明
| 值 | 说 明 | 注 意 |
| r | 以只读模式打开文件(默认模式)。文件的指针将会放在文件的开头 | 文件必须存在 |
| rb | 以二进制格式打开文件,并且采用只读模式。文件的指针将会放在文件的开头。一般用于非文本文件,如图片、声音等 | |
| r+ | 打开文件后,可以读取文件内容,也可以写入新的内容覆盖原有内容(从文件开头进行覆盖) | |
| rb+ | 以二进制格式打开文件,并且采用读写模式。文件的指针将会放在文件的开头。一般用于非文本文件,如图片、声音等 | |
| w | 以只写模式打开文件。如果文件存在,则将其覆盖;如果文件不存在,则创建新文件 | 必须要保证文件所在目录存在,文件可以不存在 |
| wb | 以二进制格式打开文件,并且采用只写模式。一般用于非文本文件,如图片、声音等 | |
| w+ | 打开文件后,先清空原有内容,使其变为一个空的文件,对这个空文件有读写权限 | |
| wb+ | 以二进制格式打开文件,并且采用读写模式。一般用于非文本文件,如图片、声音等 | |
| a | 以追加模式打开文件。如果文件存在,文件指针将放在文件的末尾(即新内容会被写入到已有内容之后),如果文件不存在,则创建新文件用于写入 | |
| ab | 以二进制格式打开文件,并且采用追加模式。如果该文件已经存在,文件指针将放在文件的末尾(即新内容会被写入到已有内容之后),否则,创建新文件用于写入 | |
| a+ | 以读写模式打开文件。如果该文件已经存在,文件指针将放在文件的末尾(即新内容会被写入到已有内容之后),否则,创建新文件用于读写 | |
| ab+ | 以二进制格式打开文件,并且采用追加模式。如果该文件已经存在,文件指针将放在文件的末尾(即新内容会被写入到已有内容之后),否则,创建新文件用于读写 |
l buffering:可选参数,用于指定读写文件的缓冲模式,值为0表示不缓存;值为1表示缓存(默认为缓存模式);如果大于1,则表示缓冲区的大小。
l encoding:表示读写文件时所使用的文件编码格式,一般使用UTF-8;
l errors:表示读写文件时碰到错误的报错级别。常见的报错级别有:
Ø 'strict':严格级别,字符编码有报错即抛出异常,默认级别,errors参数值传入None即按此级别处理。
Ø 'ignore':忽略级别,字符编码有错,忽略掉。
Ø 'replace':替换级别,字符编码有错的,替换成?。
l newline:表示用于区分换行符(只对文本模式有效,可以取的值有None、'\n'、'\r'、'\r\n')
l closefd:表示传入的file参数类型(缺省为True),传入文件路径时一定为True,传入文件句柄则为False。
文件操作的常用方法
打开文件后对文件读取操作通常有三种方法:read()方法表示读取全部内容;readline()方法表示逐行读取;readlines()方法表示读取所有行内容。下面分别进行介绍。
l read()方法
读取文件的全部或部分内容,对于连续的面向行的读取,则不使用该方法。语法如下:
fp.read([size])
其中,size为可选参数,用于指定要读取文件内容的字符数(所有字符均按一个计算,包括汉字,如“name:无”的字符数为6),如read(8),表示读取前8个字符。如果省略,则返回整个文件的内容。
注意:使用read()方法读取文件内容时,如果文件大于可用内存,则不能实现文件的读取,而是返回空字符串。
l readline()方法
返回文件中一行的内容,具体语法为:
file.readline([size])
其中,size为可选参数,用于指定读取一行内容的范围,如readline(8),表示指读取一行中前8个字符的内容。如果省略,则返回整行的内容。
l readlines()方法
返回一个列表,列表中每个元素为文件中的一行数据,语法如下:
file.readlines()
除了对文件读取操作,还可以对文件进行写入、获取文件指针位置和关闭文件等操作。具体方法如下:
l write()方法
将内容写入文件,语法如下:
f.write(obj)
其中,obj为要写入的内容。
l tell()方法
返回一个整数,表示文件指针的当前位置,即在二进制模式下距离文件头的字节数,语法如下:
f.tell()
说明:使用tell()方法返回的位置与为read()方法指定的size参数不同。tell()方法返回的不是字符的个数,而是字节数,其中汉字所占的字节数根据其采用的编码有所不同,如果采用GBK编码,则一个汉字按两个字符计算;如果采用UTF-8编码,则一个汉字按3个字符计算。
l seek()方法
将文件的指针移动到新的位置,位置通过字节数进行指定。这里的数值与tell()方法返回的数值的计算方法一致。语法如下:
file.seek(offset[,whence])
参数说明:
Ø file:表示已经打开的文件对象;
Ø offset:用于指定移动的字符个数,其具体位置与whence有关;
Ø whence:用于指定从什么位置开始计算。值为0表示从文件头开始计算,1表示从当前位置开始计算,2表示从文件尾开始计算,默认为0。
l close()方法
关闭打开的文件,语法如下:
f. close ()
快用锦囊
锦囊01 常用文件读取操作
打开文件后对文件读取操作通常有三种方法:read()表示读取全部内容;read(8)表示读取前8个字符;readline()表示逐行读取;readline(8)表示读取行的前8个字符;readlines()表示读取所有行内容,可以通过括号内的数字限制读取内容的范围。
l 一次读取文件的全部内容
打开文件后,如果要一次读取文件的全部内容,可以使用read()方法。代码如下:
f = open('D:/lift.txt') # 以只写模式打开文件
f.read()
使用readline()方法也可以实现文件全部内容的读取,但括号中读取的字符数要设置足够大,实现代码如下:
f = open('D:/lift.txt') # 以只写模式打开文件
lines = f.readline(20000) # 设置读取的字符足够大
print(lines) # 输出读取到的文件内容
f.close() # 关闭文件
l 读取文件或者每行的前几个字符
如果要读取文件内容中的前几个字符,可以直接在Read()方法的括号里面输入要读取的字符数。如读取文件的前8个字符,实现代码如下:
f = open('D:/lift.txt') # 以只写模式打开文件
f.read(8)
如果要一次读取每行内容的前几个字符,可以使用readline()方法,设置读取的字符个数即可,实现代码如下:
f = open('D:/lift.txt') # 以只写模式打开文件
while True:
line = f.readline(5) # 一次读取一行中的5个字符
print(line) # 输出读取的内容
if line == '': # 如果读取的内容为空
break # 跳出循环
f.close() # 关闭文件
l 逐行读取文件内容,可以使用while语句和readline()方法,实现代码如下:
f = open('D:/lift.txt') # 以只写模式打开文件
line = f.readline() # 读取一行
while line:
print(line) # 输出读取的一行内容
line = f.readline() # 读取一行
f.close() # 关闭文件
或
f = open('D:/lift.txt') # 以只写模式打开文件
while True:
line = f.readline() # 读取一行
print(line) # 输出读取的一行内容
if line == '': # 如果读取的内容为空
break # 跳出循环
f.close() # 关闭文件
逐行读取文件内容,也可以使用for语句和readline()方法,实现代码如下:
for line in open('D:/lift.txt'):
print(line) # 输出一行内容
锦囊02 使用with open语句打开文件
在Python中,使用with open语句可以用指定的模式打开一个文件对象。使用该方式打开文件,并对文件操作完成后,无需通过close()方法关闭文件,文件会自动关闭。下面是一次读取整个文件内容的代码:
with open('D:/lift.txt', 'r' ) as f: # 以只读方式打开文件
print(f.read()) # 读取全部文件内容并输出
使用with open语句打开文件后,也可以按行读取文件内容,代码如下:
with open('D:/lift.txt', 'r') as f: # 以只写模式打开文件
lines=f.readlines() # 读取全部内容
for line in lines: # 遍历每行内容
print(line.rstrip()) # 输出每行中去掉右侧空白字符的内容
锦囊03 在相对路径下创建或写入文件
编写程序经常要用到绝对路径和相对路径,绝对路径是指从根目录开始直到文件所在位置的路径,通常是从盘符开始的路径,如“C:\mingribook\python”;相对路径是程序或文件所在目录到指定文件位置的路径,如“/test”。使用相对路径会使程序处理文件时非常灵活、方便。建议用户在编写程序时尽量使用相对路径,除非特殊要求。本实例调用open()函数以写方式打开程序所在路径下的lift.txt文件,然后向该文件内写入信息,示例代码如下:
with open('lift.txt', 'w') as f: # 以只写模式打开文件
f.write('生命美妙之处, 就在于你的勇气会成就更美的你。')
执行上面的代码后,将在程序所在路径下生成一个名称为lift.txtt的文件,内容如图1所示。

图1 创建的lift.txt文件
锦囊04 读取操作文件时去除空格,空行等
读取文件后,针对文件内容,有时需要做相应的处理,如去除空格、空行、回车符(\n)、制表符(\t)等。下面是数据去除的典型应用。
with open('lift.txt', 'r') as f: # 以只读模式打开文件
for line in f.readlines():
print( line.strip() ) # 去除空格
print( line.strip('\n') ) # 去除换行符
print( line.strip('\t') ) # 去除制表符
锦囊05 读取非UTF-8编码的文件
要读取非UTF-8编码的文本文件,需要给open()函数传入encoding参数,例如,读取GBK编码的文件:
with open('D:/lift.txt', 'r',encoding='gbk') as f: # 以只读模式打开文件
print( f.readlines() ) # 读取全部内容
说明:在指定encoding参数时,指定的编码一定是文件采用的编码,否则将抛出异常。
读取有些编码不规范的文件,可能会出现UnicodeDecodeError错误,遇到这种情况,通过open()函数接收errors参数,在遇到编码错误时,可以直接忽略错误,如:
with open('D:/lift.txt', 'r',encoding='gbk', errors='ignore') as f: # 以只读模式打开文件
print( f.readlines() ) # 读取全部内容
锦囊06 在指定目录(绝对路径)下生成TXT文件
调用open()函数在D盘根目录下创建一个名为lift.txt的文件,并且向该文件中写入指定内容,示例代码如下:
with open('D:/lift.txt', 'w') as fp: # 以只写模式打开文件
fp.write(' *'*10+'生命之美妙'+' *'*10)
fp.write('\n 生命美妙之处, 就在于你的勇气会成就更美的你。')
执行上面的代码后,将在“D:\”目录下生成一个名称为lift.txtt的文件,内容如图2示。

图2 创建的lift.txt文件
锦囊07 以二进制方式打开图片文件
在D盘目录下放置一个名称为python.jpg的图片文件,如图3示,使用open()函数以二进制方式打开该文件,并输出创建的对象,示例代码如下:
file = open('D:/python.jpg','rb') # 以二进制方式打开图片文件
print(file)
运行上面的代码,结果如下:
<_io.BufferedReader name='D:/python.png'>

图3 目标图片
锦囊08 多个文件的读取操作
有时需要同时读取多个文件的数据,如mr1.txt、mr2.txt、mr3.txt中的文件格式是一样的,现在要分别从三个文件中读取一行数据并输出,实现代码如下:
f1 = open('mr1.txt', 'r') # 打开一个文件,命名为f1
f2 = open('mr2.txt', 'r') # 打开一个文件,命名为f2
f3 = open('mr3.txt', 'r') # 打开一个文件,命名为f3
i = f1.readline() # 读取一行
j = f2.readline() # 读取一行
k = f3.readline() # 读取一行
print(i, j, k) # 输出读取到的数据
其实有更简单的方法,使用zip()函数,代码如下:
f1 = open('mr1.txt', 'r') # 打开一个文件,命名为f1
f2 = open('mr2.txt', 'r') # 打开一个文件,命名为f2
f3 = open('mr3.txt', 'r') # 打开一个文件,命名为f3
for i, j, k in zip(f1, f2, f3): # 读取每个文件的内容
print(i, j, k)
锦囊09 读取一个文件夹下所有文件
如果要读取一个路径下所有文件(不包含子文件夹下的文件),并将读取的内容保存到一个列表进行输出。需要遍历该目录下所有文件,然后循环读取每个文件的内容到列表,最后将每个文件的内容添加到列表,实现代码如下:
import os # 导入文件与系统操作模块
path = 'temp/mr' # 待读取文件的文件夹相对地址
names = os.listdir(path) # 获得目录下所有文件的名称列表
all = [] # 保存文件信息的列表
for item in names: # 读取每一个文件
f = open(path+'/'+item) # 打开文件
new = [] # 保存单个文件内容的列表
for i in f: # 按行读取文件内容
new.append(i)
all.append(new) #将new添加到列表中
for i in all: # 遍历并输出列表
print(i)
运行程序,程序所在目录下包括3个文件,内容如图4示。运行效果如下:
['生命美妙之处, 就在于你的勇气会成就更美的你。\n']
["['明日学院', 'www.mingrisoft.com', '让编程更简单!']\n"]
['愿你的青春不负梦想!\n']
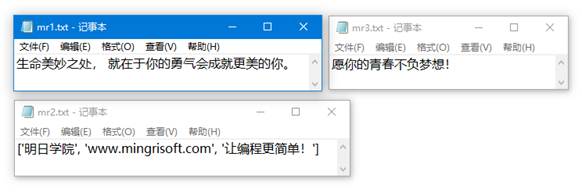
图4 要读取的3个文件的内容
锦囊10 将文件的写入和读取写入类
自定义文件操作类operatxt,实现文件的写入和读取操作。示例代码如下:
class operatxt(): # 定义操作文件类
def __init__(self,encoding):
self.enc = encoding
def WriteTxt(self,s): # 写入文件的方法
with open("test.txt","a+",encoding=self.enc) as fileInfo:
fileInfo.write(s) # 写入内容
def ReadTxt(self): # 读取文件的方法
with open("test.txt","r",encoding=self.enc) as fileInfo:
s= fileInfo.read() # 读取全部文件内容
return s
# 接收用户输入,将输入内容写入到文件,同时询问用户是读取文件还是继续写入文件
# 当用户选择读取文件时,将前面已经写入的内容读取出来并输出给用户,然后结束用户输入
while True:
content=input("请输入要写入到文件的内容:")
ot=operatxt("utf-8") # 创建操作文件类的对象,指定编码为UTF-8
ot.WriteTxt(content) # 写入文件内容
yn = input("内容已写入文件,是否要读取?输入y则读取文件,继续写入请输入n:")
if yn=='y':
s=ot.ReadTxt() # 读取文件
print("文件内容为:",s) # 输出文件内容
break # 退出出循环
输出结果为:
请输入要写入到文件的内容:第一段:跟着你的心走。
内容已写入文件,是否要读取?输入y则读取文件,继续写入请输入n:n
请输入要写入到文件的内容:第二段:You do what's in your heart.
内容已写入文件,是否要读取?输入y则读取文件,继续写入请输入n:y
文件内容为: 第一段:跟着你的心走。第二段:You do what's in your heart.
运行程序,输入需要写入test.txt文件中的内容,然后在当前的Python文件的同级目录下自动创建test.txt文件,内容如图5所示。

图5 test.txt文件的内容
应用场景
场景一:逐行显示蚂蚁庄园的动态
在蚂蚁庄园的动态栏目中记录着庄园里的新鲜事,现在可以通过读取文件的方式显示庄园里的动态信息。首先应用open()函数以只读方式打开一个记录动态信息的文件,然后应用while语句创建一个循环,在该循环中调用readline()方法读取一条动态信息并输出,另外还需要判断内容是否已经读取完毕,如果读取完毕应用break语句跳出循环,示例代码如下:
print("\n","="*35,"蚂蚁庄园动态","="*35,"\n")
with open('message.txt','r') as file: # 打开保存蚂蚁庄园动态信息的文件
number = 0 # 记录行号
while True:
number += 1
line = file.readline()
if line =='':
break # 跳出循环
print(number,line,end= "\n") # 输出一行内容
print("\n","="*39,"over","="*39,"\n")
输出结果为:
=================================== 蚂蚁庄园动态 ===================================
1 你使用了1张加速卡,小鸡撸起袖子开始双手吃饲料,进食速度大大加快。
2 mingri的小鸡在你的庄园待了22分钟,吃了6g饲料之后,被你赶走了。
3 你的小鸡在QQ的庄园待了27分钟,吃了8g饲料被庄园主人赶回来了。
4 你使用了1张加速卡,小鸡撸起袖子开始双手吃饲料,进食速度大大加快。
5 CC来到你的庄园,并提醒你无语的小鸡已经偷吃饲料21分钟,吃掉了6g。你的小鸡拿出了10g饲料奖励给CC。
======================================= over =======================================
场景二:读取两层文件夹的文件内容
如果要读取多层文件夹的所有文件内容,需要循环读取各个文件夹的文件内容。读取时,需要判断读取的是文件还是文件夹,如果是文件,先将文件的路径和文件名称保存到列表,然后读取文件所有内容到列表;如果是文件夹,则循环读取文件夹下的文件和文件夹,然后判断是文件还是文件夹,如果是文件,仍然是先将文件的路径和文件名称保存到列表,然后读取文件所有内容到列表。本实例只实现二级目录的文件内容读取,实现代码如下:
import os
path = "user" # 要读取的文件夹绝对路径
import os
list=[] # 保存文件内容的列表
path = "user" # 读取文件的目录
files = os.listdir(path) # 目录下所有文件和文件夹列表
for file in files: # 遍历目录下所有文件与文件夹
pathfile =path+"/"+file # 带完整路径的文件或文件夹
if not os.path.isdir(pathfile): # 如果是文件(不是文件夹)
with open(pathfile,'r') as fp: # 只读方式打开文件
list.append(pathfile) # 添加文件路径与名称到列表
list.append(fp.readlines()) # 将文件内容添加到列表
else:
newpath = path+"/"+file # 指定下级目录
files1 = os.listdir(newpath) # 下级目录下所有文件和文件夹列表
for file1 in files1: # file1和files1不能写成上层的file和files
pathfile = newpath + "/" + file1 # 带完整路径的下层文件或文件夹
if not os.path.isdir(pathfile): # 如果是文件(不是文件夹)
with open(pathfile, 'r') as fp: # 只读方式打开文件
list.append(pathfile) # 添加文件路径与名称到列表
list.append(fp.readlines()) # 将文件内容添加到列表
for item in list: # 遍历列表
print(item)
运行程序,实现效果如图6所示。
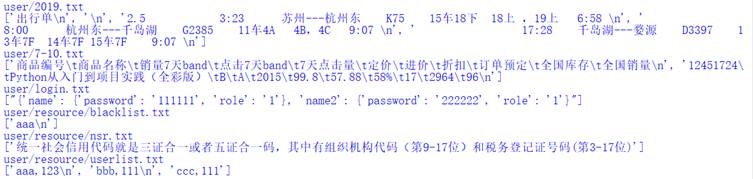
图6 输出列表中保存的文件内容
注意:级联目录读取时,下级级联目录是建立在上级目录基础上的,所以定义的上级目录变量不能和下级目录变量冲突。如代码中的file、files是上级的目录变量,file1、files1是下级目录变量,两者不能混淆。