文章目录
- 一、torch.nn.Conv2d基本介绍
- 1.1构造方法
- 1.2参数、偏置、属性
- 1.2.1参数与偏置
- 1.2.2可查看属性
- 1.3torch.nn.functional.conv2d
- 1.4dilation
- 二、卷积操作
- 2.1in_channels=1, out_channels=1, kernel_size=3, stride=1, padding=0
- 2.2in_channels=1, out_channels=1, kernel_size=3, stride=2, padding=1
- 2.3in_channels=2, out_channels=3, kernel_size=3, stride=1, padding=0
- 2.4设置padding使特征图与原图像大小相等
- 2.5分组卷积
注意以下区别:
torch.nn.Conv2d:构造卷积层的类,用于创建卷积层对象。这是一个模型组件,它具有可学习的参数(如权重和偏置),并且在模型训练过程中会通过反向传播更新这些参数。nn.functional.conv2d():执行卷积操作的函数,它直接进行卷积计算。这个函数没有可学习的参数,因此在模型训练过程中不能通过反向传播来调整它的参数。
在构建深度学习模型时会使用nn.Conv2d而非nn.conv2d,在定义模型结构时,Conv2d 通常作为卷积层的组件使用(它有可学习的参数,且会通过反向传播更新),而在模型的前向传播过程中会使用conv2d函数来执行具体的卷积操作。
一、torch.nn.Conv2d基本介绍
torch.nn.Conv2d类对象常常用于作为卷积层以构造神经网络模型,官方文档地址为:点击跳转。torch.nn.Conv2d类对象以
(
N
,
C
i
n
,
H
,
W
)
(N,C_{in} ,H,W)
(N,Cin,H,W)作为输入数据,以
(
N
,
C
o
u
t
,
H
o
u
t
,
W
o
u
t
)
(N,C_{out} ,H_{out},W_{out})
(N,Cout,Hout,Wout)作为输出数据(仅批量大小
N
N
N保持不变)。含义如下:
- N N N:批量大小。
- C C C:通道数。
- H H H:图像高度。
- W W W:图像宽度。
这一设定使得卷积层支持对数据流进行批量处理,网络间传递的是四维数据,即,将N次的处理汇总成了1次进行:
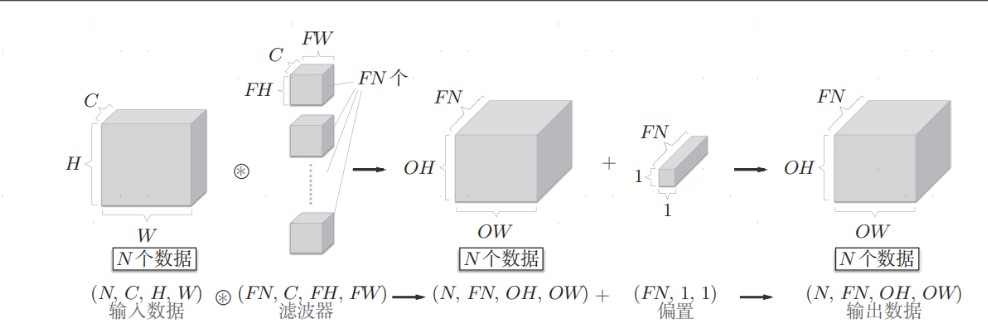
1.1构造方法
对象构造方法:
torch.nn.Conv2d(
in_channels: int,
out_channels: int,
kernel_size: _size_2_t,
stride: _size_2_t = 1,
padding: Union[str, _size_2_t] = 0,
dilation: _size_2_t = 1,
groups: int = 1,
bias: bool = True,
padding_mode: str = 'zeros', # TODO: refine this type
device=None,
dtype=None
)
| 参数名 | 数据类型 | 作用 |
|---|---|---|
| in_channels | int | 输入图像的通道数 |
| out_channels | int | 输出图像通道数,也就是卷积核的数量,每个卷积核会生成一个输出通道。也就是卷积操作后生成的特征图数量。 |
| kernel_size | int或tuple | 卷积核的大小。如果是 int 类型,表示卷积核的高度和宽度相等;如果是 tuple 类型,如 kernel_size=(3, 5),表示卷积核的高度和宽度分别为 3 和 5。 |
| stride | int或tuple | 卷积步长。如果是 int 类型,表示在高度和宽度方向上的步长相等;如果是 tuple 类型,如 stride=(2, 1),表示在高度和宽度方向上的步长分别为 2 和1。默认值为 1。 |
| padding | int或tuple | 填充控制padding_mode的数目。如果是 int 类型,表示在高度和宽度方向上的填充层数相等;如果是 tuple 类型,如 (1, 2),表示在高度和宽度方向上的填充层数分别为 1 和 2。 |
| padding_mode | string | 选择填充方式,可选值为zeros(默认值)或 reflect。前者表示零填充,后者使用输入图像边界值填充。 |
| dilation | int或tuple | 控制卷积核内部元素之间的间距(dilation)。如果是 int 类型,表示在卷积核内部元素之间的间距在高度和宽度方向上相等;如果是 tuple 类型,如 (2, 2),表示在高度和宽度方向上的间距分别为 2。 |
| groups | int或tuple | 控制分组卷积。当 groups>1 时,表示使用分组卷积,将输入通道和输出通道分成 groups 组,并分别进行卷积操作。默认值为 1,即普通卷积。 |
| bias | bool | 是否在输出中添加可学习偏置 |
| device | torch.device | 指定运行在哪个设备上(例如 CPU 或 GPU)。默认值为 None,表示使用默认设备。 |
| dtype | torch.dtype | 指定该层的数据类型。默认值为 None,表示使用默认数据类型。 |
1.2参数、偏置、属性
1.2.1参数与偏置
在模型训练过程中,nn.Conv2d对象会不断通过反向传播更新自己的参数,包括:
- Conv2d.weight(卷积核参数):每个卷积核都是一个可学习的参数矩阵,用于在输入图像上执行特征提取。
nn.Conv2d层会学习这些卷积核的参数,使得它们能够有效地捕捉输入图像中的不同特征。 - Conv2d.bias(偏置项参数):如果在
nn.Conv2d中使用了偏置(bias=True),则在进行卷积操作时,每个输出通道的卷积结果会与相应的偏置项相加,从而得到输出特征图。
其中,偏置项参数用于引入对输入数据的线性偏移,使得模型能够更好地拟合数据。查看参数:
import torch
import torch.nn as nn
# 实例化一个二维卷积
conv_layer = torch.nn.Conv2d(in_channels=1, out_channels=1, kernel_size=(3, 3),
stride=1, padding=0, bias=False)
print(f"conv_layer.bias: {conv_layer.bias}")
print(f"conv_layer.weight: {conv_layer.weight}")

在创建torch.nn.Conv2d时,其权重与偏置都是随机初始化的,也可在对象创建后自行指定使用的参数:
import torch
import torch.nn as nn
# 实例化一个二维卷积
conv_layer = torch.nn.Conv2d(in_channels=1, out_channels=1, kernel_size=(3, 3),
stride=1, padding=0, bias=True)
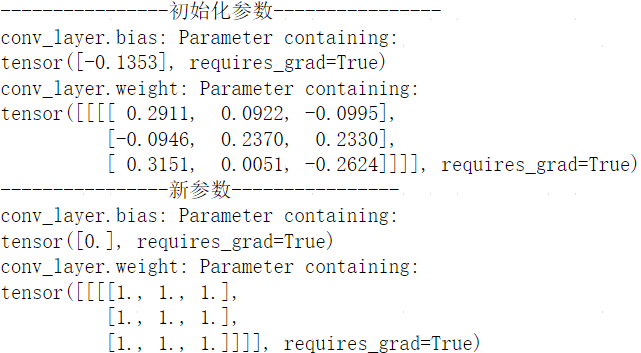
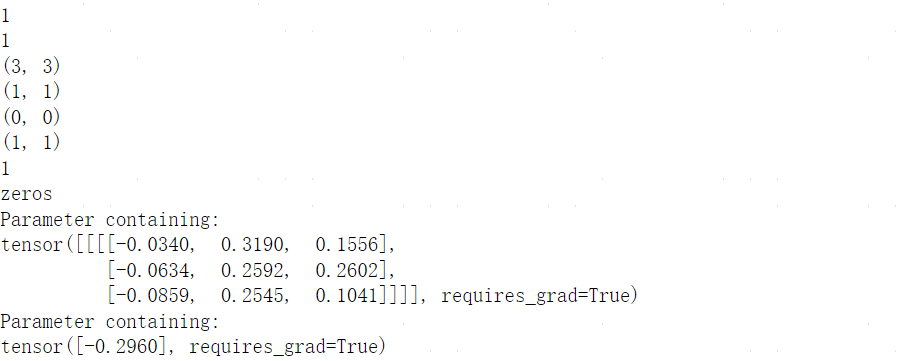
print('----------------初始化参数----------------')
print(f"conv_layer.bias: {conv_layer.bias}")
print(f"conv_layer.weight: {conv_layer.weight}")
conv_layer.bias=nn.Parameter(torch.zeros(conv_layer.bias.size()))
conv_layer.weight=nn.Parameter(torch.ones(conv_layer.weight.size()))
print('----------------新参数----------------')
print(f"conv_layer.bias: {conv_layer.bias}")
print(f"conv_layer.weight: {conv_layer.weight}")
1.2.2可查看属性
对于创建的nn.Conv2d提供了以下可查看属性:
| 属性名 | 功能 |
|---|---|
| in_channels | 输入通道数 |
| out_channels | 输出通道数 |
| kernel_size | 卷积核大小 |
| stride | 卷积操作的步长。 |
| padding | 填充层数 |
| dilation | 卷积核元素之间的间距 |
| groups | 输入和输出通道之间的连接方式 |
| padding_mode | 填充模式 |
| weight | 权重参数 |
| bias | 偏置项参数 |
print(conv_layer.in_channels) # 输出输入通道数
print(conv_layer.out_channels) # 输出输出通道数
print(conv_layer.kernel_size) # 输出卷积核的大小
print(conv_layer.stride) # 输出卷积操作的步长
print(conv_layer.padding) # 输出填充层数
print(conv_layer.dilation) # 输出卷积核元素之间的间距
print(conv_layer.groups) # 输出输入和输出通道之间的连接方式
print(conv_layer.padding_mode) # 输出填充的模式
print(conv_layer.weight) # 输出卷积核的权重参数
print(conv_layer.bias) # 输出偏置项的参数
1.3torch.nn.functional.conv2d
torch.nn.functional.conv2d()官方地址:点击跳转,函数声明:
torch.nn.functional.conv2d(input, weight, bias=None, stride=1,
padding=0, dilation=1, groups=1) -> Tensor
torch.nn.functional.conv2d()是用于执行二维卷积操作的函数,可在函数调用时直接指定卷积核的权重参数,而不需要像类那样在初始化时定义。注意,输入数据类型为TensorFloat32,且同样为
(
N
,
C
,
H
,
W
)
(N,C,H,W)
(N,C,H,W)格式。
import torch
import torch.nn as nn
import torch.nn.functional as F
# 定义一个输入特征图
input_feature_map = torch.randn(size=[1, 1, 4, 4]) # N, C, H, W
# 实例化一个二维卷积
conv_layer = torch.nn.Conv2d(in_channels=1, out_channels=1, kernel_size=(3, 3),
stride=1, padding=0, bias=False)
# 定义卷积核参数
kernel_weight = torch.Tensor([[[[-0.0765, 0.1716, 0.2779],
[-0.1685, -0.1217, 0.0160],
[0.1584, -0.2000, -0.2148]]]])
# 设置卷积层卷积核
conv_layer.weight=nn.Parameter(kernel_weight)
# 将输入特征图送入卷积层对象得到输出特征图1
output_feature_map_1 = conv_layer(input_feature_map)
# 直接使用卷积运算函数得到输出特征图2
output_feature_map_2 = torch.nn.functional.conv2d(
input=input_feature_map, weight=kernel_weight, bias=None, stride=1, padding=0)
print(f"\r\n----------------输出特征图--------------------")
print(f"output feature map 1: {output_feature_map_1}")
print(f"output feature map 2: {output_feature_map_2}")

其中,梯度函数grad_fn=<ConvolutionBackward0>表示output_feature_map_1由卷积操作生成,可在反向传播时根据此信息计算梯度。而torch.nn.functional.conv2d只单纯进行卷积运算,并不涉及与梯度相关的操作,也不会生成梯度函数。
1.4dilation
dilation用于控制卷积核内部元素之间的间距。如果是int类型,表示在卷积核内部元素之间的间距在高度和宽度方向上相等;如果是tuple类型,如 (2, 2),表示在高度和宽度方向上的间距分别为2。
1.dilation=0
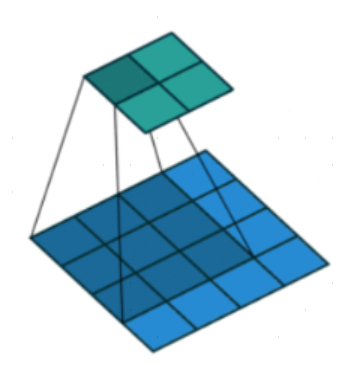
此时是最常见的普通卷积核。
2.dilation=1
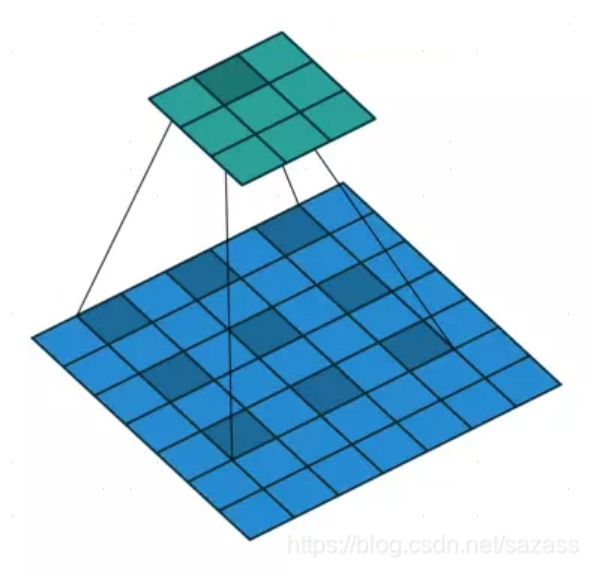
此时卷积核被称为扩张卷积(空洞卷积),单次计算时覆盖的面积(即感受域)由dilation=0时的3*3=9变为了dilation=1时的5*5=25。在增加了感受域的同时却没有增加计算量,保留了更多的细节信息,对图像还原的精度有明显的提升。详情见链接:点击跳转。
二、卷积操作
2.1in_channels=1, out_channels=1, kernel_size=3, stride=1, padding=0

输入图像通道数为1,输出特征图通道数为1,卷积核采用3x3大小,不使用填充,步长为1。使用代码模拟:
import torch
import torch.nn as nn
import torch.nn.functional as F
# 定义输入图像
input_feature_map=torch.FloatTensor([
[3,3,2,1,0],
[0,0,1,3,1],
[3,1,2,2,3],
[2,0,0,2,2],
[2,0,0,0,1]
]).view((1,1,5,5))
# 定义卷积核
kernel_weight = torch.Tensor([[[[0.0, 1.0, 2.0],
[2.0, 2.0, 0.0],
[0.0, 1.0, 2.0]]]])
# 实例化一个二维卷积并设置卷积核
conv_layer = torch.nn.Conv2d(in_channels=1, out_channels=1, kernel_size=(3, 3),
stride=1, padding=0, bias=False)
conv_layer.weight=nn.Parameter(kernel_weight)
# 将输入特征图送入卷积层对象得到输出特征图1
output_feature_map = conv_layer(input_feature_map)
output_feature_map
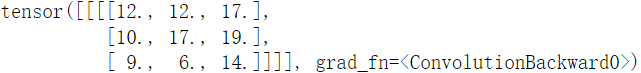
2.2in_channels=1, out_channels=1, kernel_size=3, stride=2, padding=1

输入图像通道数为1,输出特征图通道数为1,卷积核采用3x3大小,使用填充(填充后输入图像大小为7x7),步长为2。使用代码模拟:
import torch
import torch.nn as nn
import torch.nn.functional as F
# 定义输入图像
input_feature_map=torch.FloatTensor([
[3,3,2,1,0],
[0,0,1,3,1],
[3,1,2,2,3],
[2,0,0,2,2],
[2,0,0,0,1]
]).view((1,1,5,5))
# 定义卷积核
kernel_weight = torch.Tensor([[[[0.0, 1.0, 2.0],
[2.0, 2.0, 0.0],
[0.0, 1.0, 2.0]]]])
# 实例化一个二维卷积并设置卷积核
conv_layer = torch.nn.Conv2d(in_channels=1, out_channels=1, kernel_size=(3, 3),
stride=2, padding=1, bias=False)
conv_layer.weight=nn.Parameter(kernel_weight)
# 将输入特征图送入卷积层对象得到输出特征图1
output_feature_map = conv_layer(input_feature_map)
output_feature_map
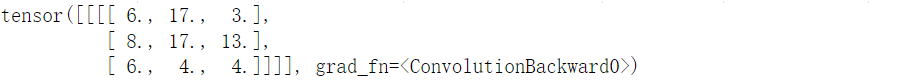
2.3in_channels=2, out_channels=3, kernel_size=3, stride=1, padding=0
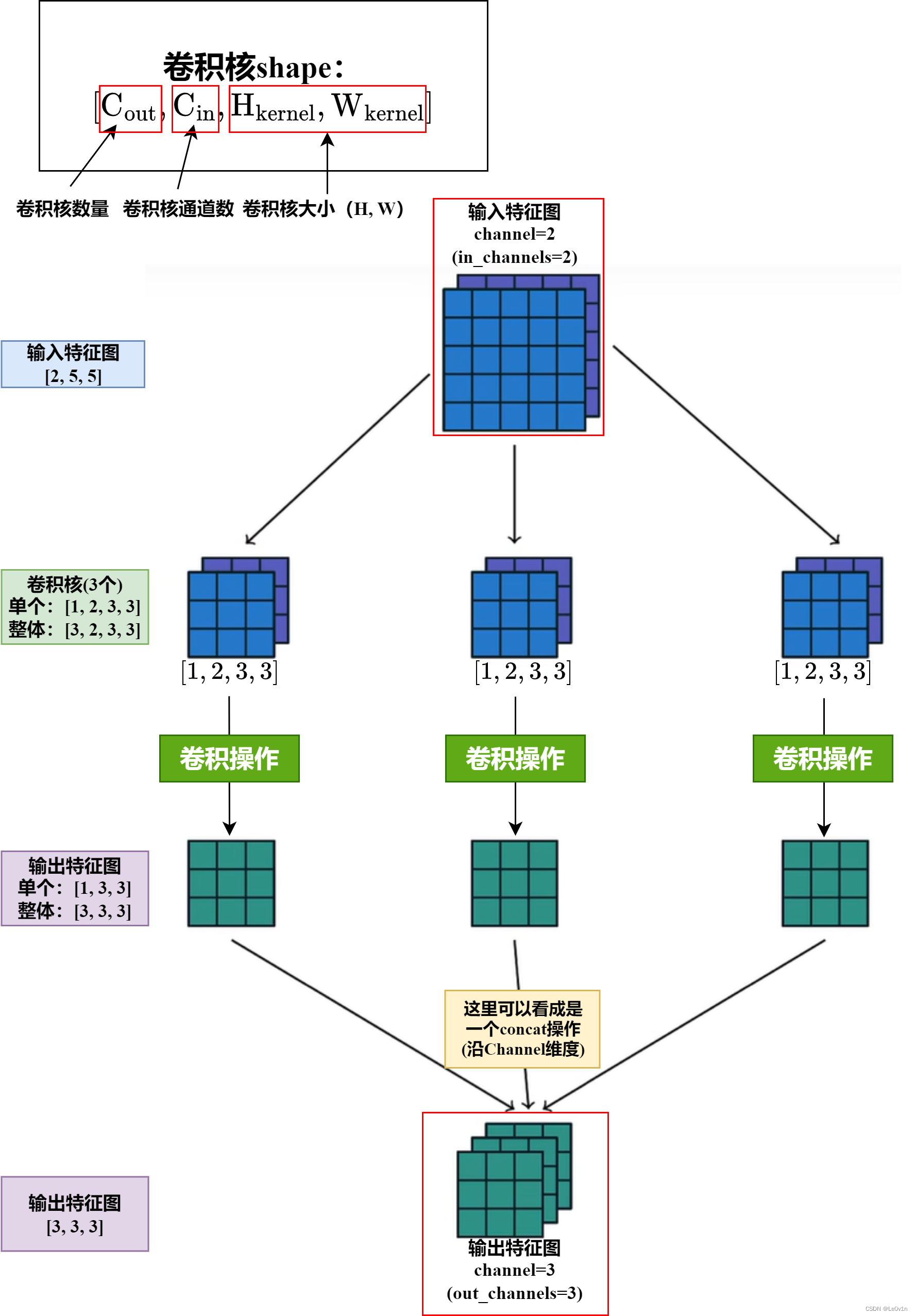
在2.1、2.2中使用的输入图像与卷积核都是单通道的,且输入图像与卷积核批大小均为1,事实上,在实际训练模型过程中二者一般并不相等。卷积核的形状:
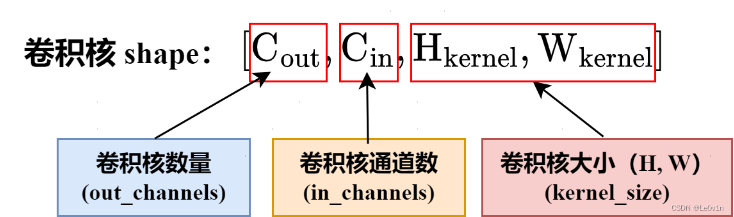
一个卷积核与原图像运算时,无论二者是否是1通道,生成特征图的通道均为1,最后将所有特征图叠加进行输出,故输出图像的通道数(对应
o
u
t
_
c
h
a
n
n
e
l
s
out\_channels
out_channels参数)由卷积核个数(对应卷积核形状的
C
o
u
t
C_{out}
Cout)决定,即,
o
u
t
_
c
h
a
n
n
e
l
s
=
=
C
o
u
t
out\_channels==C_{out}
out_channels==Cout。细化到每一个卷积核,当一个卷积核与输入图像运算时,要求卷积核通道数与输入图像通道数相同(对应通道的矩阵进行运算),即
C
i
n
=
=
i
n
_
c
h
a
n
n
e
l
s
C_{in}==in\_channels
Cin==in_channels。总结:
- 输出图像通道数等于卷积核数,即 o u t _ c h a n n e l s = = C o u t out\_channels==C_{out} out_channels==Cout。
- 卷积核通道数等于输入图像通道数,即 C i n = = i n _ c h a n n e l s C_{in}==in\_channels Cin==in_channels。
2.4设置padding使特征图与原图像大小相等
方法一:
padding = (kernel_size - 1) // 2 # kernel_size 必须为奇数
方法二:
padding = (kernel_size * 2 + 1) // 2 # kernel_size 可以为偶数
2.5分组卷积
group=in_channels,碰到再弄懂吧。