文章目录
- 前言
- 1. 索引是什么
- 2. 索引的优缺点
- 2.1 优点
- 2.2 缺点
- 3. 索引的操作
- 3.1 创建索引
- 3.2 查看索引
- 3.3 删除索引
- 4. 索引的存储原理
- 4.1 B树
- 4.2 B+树
- 结语
前言
在数据库中,我们经常使用到的操作就是查询,当数据量小的时候,查询的速度很快,一下子就找到了;但当数据量特别大时,我们应该要怎么做才能提高查询效率呢?哎,索引刚好就是干这个的
1. 索引是什么
索引(index):在 MySQL 中,索引是一种数据库优化技术,用于提高数据库查询的效率。索引可以类比于书籍的目录,相当于在数据库中构建一个特殊的“目录”,它允许数据库系统快速定位到数据,而不必扫描整个表来查找记录,避免了针对表数据进行遍历操作
类似字典,它的前面会有各种目录。我们在查字的时候就可以根据目录来加快查询速度,比无头苍蝇一样一页一页翻要快的多的多
要注意:索引是以“列”为维度进行创建的,只有当我们针对有索引的列为条件来查询,索引才能生效,才能够真正的提升查询速度
假设我们对表中的
a列创建了一个索引,当我们使用select ... where ...语句时若以 a 列为条件判断,如select * from where a = xxx,此时索引才会生效;但如果是以b、c、d等其他列进行查询,那查询速度也不会变快
2. 索引的优缺点
2.1 优点
- 可以大大提高数据库的查询速度
- 可以提高数据库系统的性能,减少查询所需要的时间,降低服务器的负载
- 可以用来加速数据的查找、排序、分组等操作
2.2 缺点
与其是缺点,倒不如说是代价:
- 需要消耗额外的存储空间(硬盘)
- 有可能会影响到 “增删改” 的效率,因为我们在进行 “增删改” 的时候,需要同步更新维护索引
- 在数据量很大的时候,创建索引可能会触发大量的硬盘IO,直接把机器卡死
索引的使用场景:
- 数据量比较大,而且经常对某些列进行查询操作
- 某些列的插入修改操作频率比较低
总的来说,正确使用索引可以极大地提升数据库的性能,但我们也需要根据实际的查询模式和数据使用情况来设计索引策略
在实际开发中,我还是很建议使用索引的,“性价比”很高。不过在建表的时候,我们就要规划好哪些列需要创建索引,避免后期修改而导致一系列的问题
3. 索引的操作
在我们创建主键约束、唯一约束、外键约束的时候,数据库会自动帮我们创建这些列的索引,因为它们都高频使用到查询操作
3.1 创建索引
create index 索引名 on 表名(字段名);
- 对于非主键约束、非唯一约束、非外键约束的字段,我们可以创建普通索引
- 索引名习惯以 idx 或 ix 做前缀,后面的名字最好有意义
-- 演示
-- 为学生表的成绩列创建索引
-- 先建表
create table student (
id int primary key,
name varchar(20) unique,
grade int
);
-- 创建成绩列的索引
create index grade_index on student(grade);

3.2 查看索引
show index from 表名;
-- 演示
-- 我们直接查看上面刚创建的学生表
show index from student;
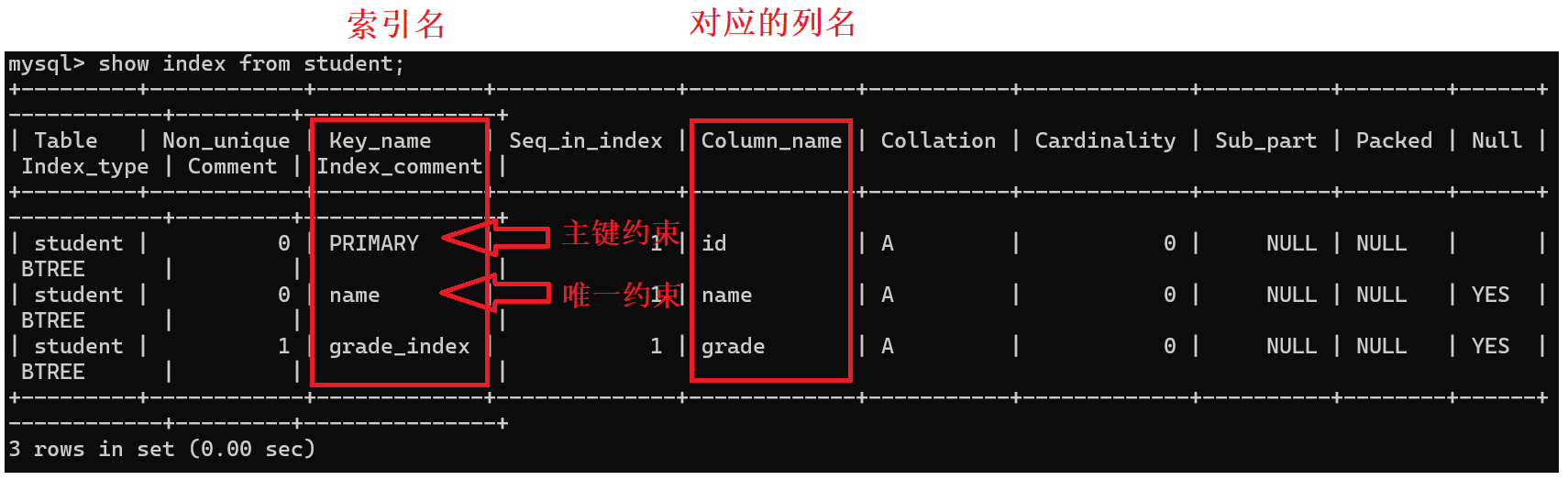
我们可以发现:除了我们自己创建的成绩列索引,还有数据库自动生成的主键索引和唯一索引。还有一点,外键约束也会生成索引,此处就不展示了
3.3 删除索引
drop index 索引名 on 表名;
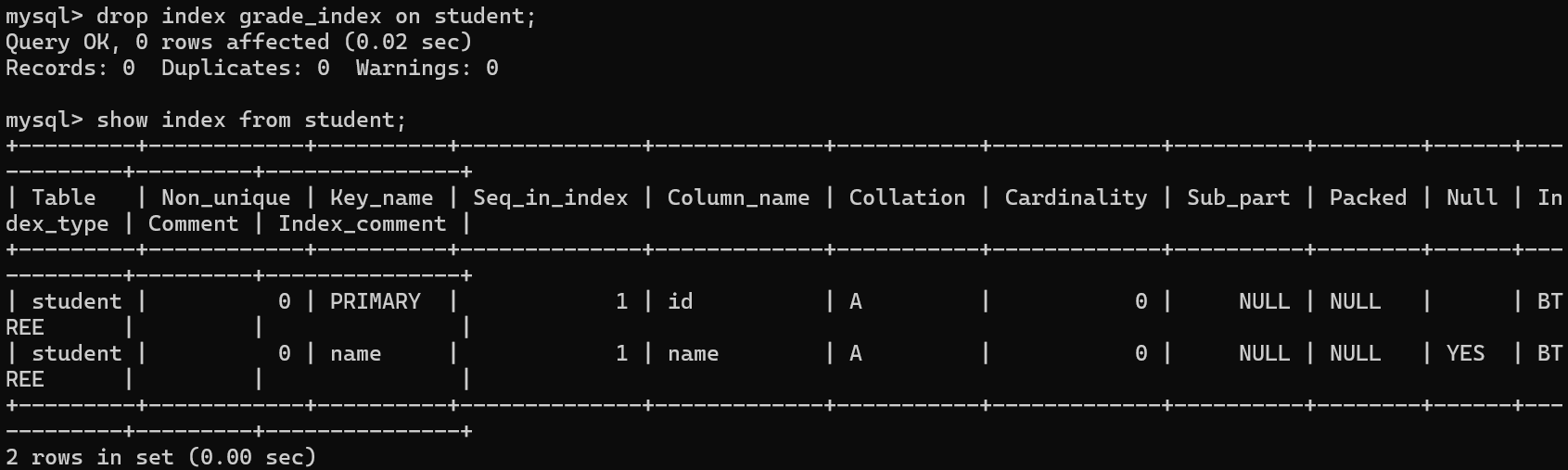
- 删除索引时,我们只能够删除手动创建的普通索引,如果删除数据库自动生成的索引,则会导致约束消失,非常不建议这样的操作(博主的 MySQL 版本为5.7,版本号偏低,具体删除情况请以实际版本号为准)
- 删除索引也是一个十分危险的操作,数据量大的时候直接删除索引可能会触发大量硬盘IO,使数据库宕机
-- 演示
-- 删除手动创建的索引
drop index grade_index on student;
4. 索引的存储原理
MySQL 索引的存储使用的是 B+ 树,而想要搞懂 B+树,我们得先来了解 B 树
4.1 B树
B 树,又叫做 B-tree,通常读作 “Bee-tree” 而非 “B 减树”,它是一种自平衡树形数据结构,同时也是一棵多叉平衡搜索树
B 树的特点有:
- 每个节点可以有多个子节点,可以存储多个元素
- 通过分裂和合并操作保持树的平衡,使得树的高度尽可能低
- 查询效率高,减少了硬盘IO的次数
以下是 B 树的结构:
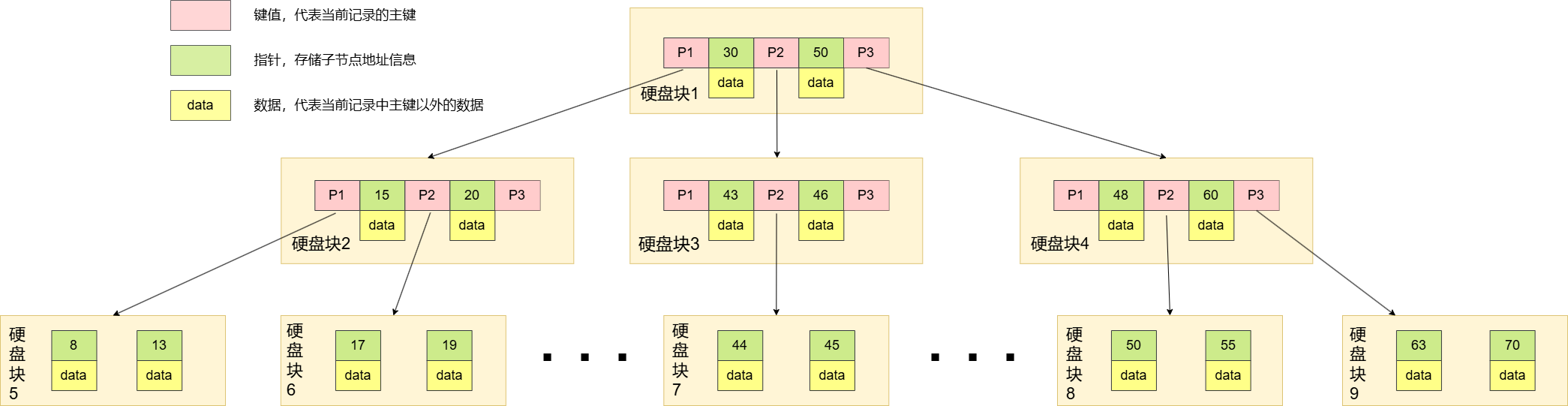
相较于二叉树,我们在查找元素的过程中,数据比较的次数并没有减少,但是对于硬盘IO的次数大大减少。我们在和某个节点比较时,是先一次硬盘IO,把该节点上的所有内容都读取出来,接下来的比较都是在内存中进行的
但是,B 树还是有一些不足之处:不支持快速进行范围查询,当查找到叶子节点时,还需返回到根节点重新遍历查询;时间复杂度不稳定,与目标元素的位置有很大关系
4.2 B+树
B+ 树跟 B 树类似,不同点有:
- 所有数据记录节点都是叶子节点,非叶子节点仅包含键值和指向子节点的指针,不存储数据记录
- 所有叶子节点都是数据记录,并且叶子节点之间通过指针连接,形成一个有序链表
- 可以提供更快的顺序访问性能,特别是对于范围查询
以下是 B+ 树的结构:
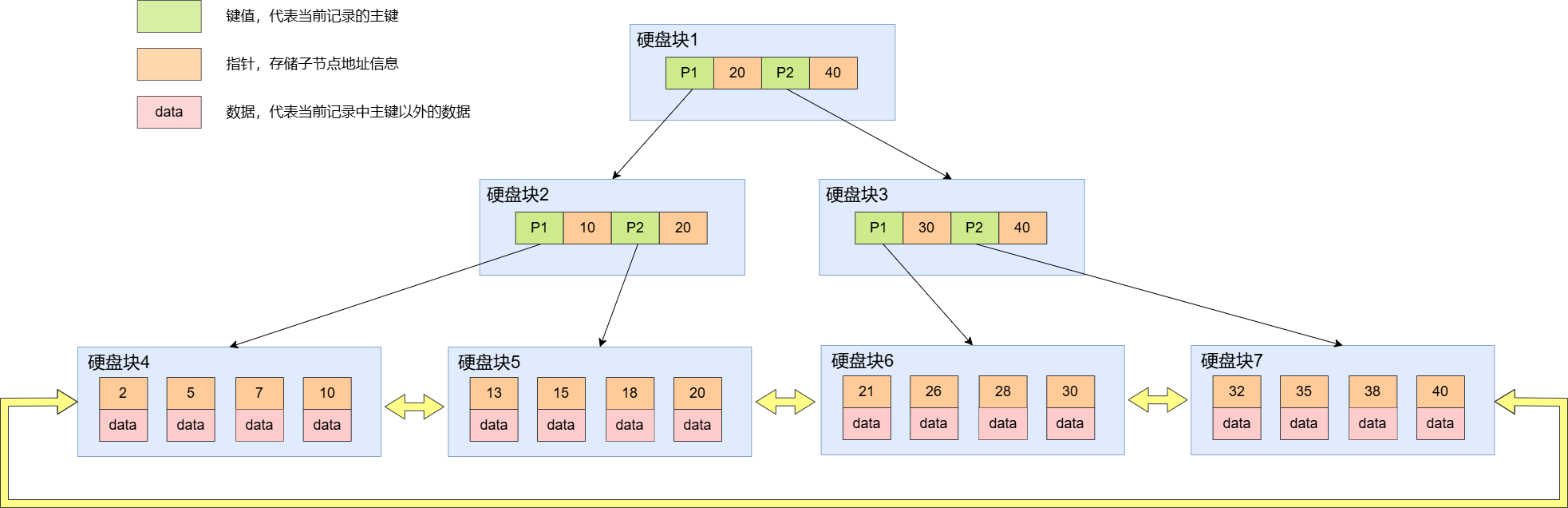
由于 B+ 树将所有的索引项都放在了叶子节点上。所有的查询都需要落到叶子节点上完成的,那么每次检索的时候,经历的硬盘IO次数和比较次数都是差不多的,使得查询的开销变得很稳定,即时间复杂度稳定
而且在 B+ 树里,只有叶子节点上存储数据行,非叶子节点只存储索引列的 key 值,所以非叶子节点占据的空间很小,可以加载到内存中,相对于 B 树来说,B+ 树的树高理论情况下是比 B 树要矮的,进而可以减少相应的硬盘IO操作
综上所述,B+ 树可以确保数据库进行快速、精准的查询
结语
关于本篇博客,我们需要知道索引的定义、索引的操作(增删查)、索引的优缺点、以及索引背后的数据结构(B+ 树的特点和优势),知道并熟练掌握这些知识点对我们来说非常重要
希望大家能够喜欢本篇博客,有总结不到位的地方还请多多谅解。若有纰漏,希望大佬们能够在私信或评论区指正,博主会及时改正,共同进步!









![[深度学习] 自编码器Autoencoder](https://img-blog.csdnimg.cn/direct/0e6a0131894a459dbe1360640d63a9ed.png)