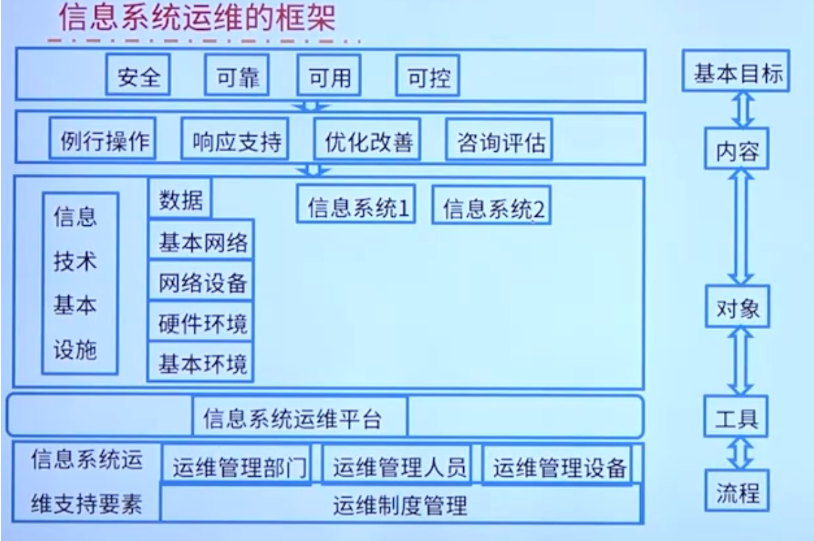
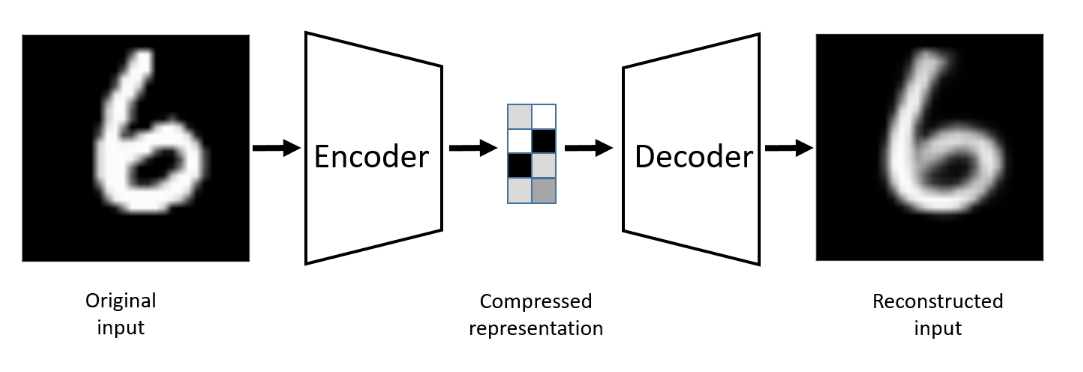
自编码器(Autoencoder)是一种无监督学习算法,主要用于数据的降维、特征提取和数据重建。自编码器由两个主要部分组成:编码器(Encoder)和解码器(Decoder)。其基本思想是将输入数据映射到一个低维的潜在空间,然后再从该潜在空间重建出原始数据。
1. 自编码器的结构
一个典型的自编码器包括以下部分:
- 编码器(Encoder):将输入数据压缩到一个低维的潜在空间表示。通常由若干层神经网络组成。
- 潜在空间(Latent Space):编码器输出的低维表示,也称为编码(Code)或瓶颈(Bottleneck)。
- 解码器(Decoder):将低维的潜在空间表示解码回原始数据的维度。通常也由若干层神经网络组成。
2. 自编码器的工作原理
自编码器通过两个阶段来训练和使用:
-
训练阶段:
- 输入数据 x 通过编码器映射到潜在空间 z,表示为 z=f(x)。
- 潜在空间表示 z 通过解码器重建出原始数据 x^ ,表示为 x^=g(z)=g(f(x))。
- 训练目标是最小化重建误差,即 x 和 x^ 之间的差异,常用的损失函数为均方误差(MSE)。
-
使用阶段:
- 训练完成后,编码器可以用于将新数据映射到低维潜在空间进行特征提取或降维。
- 解码器可以用于从潜在空间表示生成数据,应用于生成模型等任务。
3. 自编码器的类型
根据不同的应用和需求,自编码器有多种变体:
-
稀疏自编码器(Sparse Autoencoder):
- 通过添加稀疏性约束,使得潜在空间表示中只有少数几个单元被激活,常用于特征提取。
-
去噪自编码器(Denoising Autoencoder):
- 输入数据加入噪声,目标是从噪声数据中重建出原始的无噪声数据,常用于去噪和鲁棒性增强。
-
变分自编码器(Variational Autoencoder, VAE):
- 在潜在空间中引入概率分布,学习数据的生成分布,可以用于生成新数据和数据增强。
-
卷积自编码器(Convolutional Autoencoder, CAE):
- 使用卷积层替代全连接层,常用于图像数据的降维和特征提取。
4. 自编码器的实现示例(使用TensorFlow和Keras)
下面是一个使用TensorFlow实现自编码器的简单示例。这个示例展示了如何构建一个基本的自编码器,用于图像数据的压缩和重构。我们将使用经典的MNIST手写数字数据集。
import tensorflow as tf
from tensorflow.keras import layers, models
import numpy as np
import matplotlib.pyplot as plt
# 加载MNIST数据集
(x_train, _), (x_test, _) = tf.keras.datasets.mnist.load_data()
x_train = x_train.astype('float32') / 255.0
x_test = x_test.astype('float32') / 255.0
# 将数据展开为一维向量
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
# 定义编码器
input_dim = x_train.shape[1]
encoding_dim = 32 # 压缩后的维度
input_img = layers.Input(shape=(input_dim,))
encoded = layers.Dense(encoding_dim, activation='relu')(input_img)
# 定义解码器
decoded = layers.Dense(input_dim, activation='sigmoid')(encoded)
# 构建自编码器模型
autoencoder = models.Model(input_img, decoded)
# 构建单独的编码器模型
encoder = models.Model(input_img, encoded)
# 构建单独的解码器模型
encoded_input = layers.Input(shape=(encoding_dim,))
decoder_layer = autoencoder.layers[-1]
decoder = models.Model(encoded_input, decoder_layer(encoded_input))
# 编译自编码器模型
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
# 训练自编码器
autoencoder.fit(x_train, x_train,
epochs=50,
batch_size=256,
shuffle=True,
validation_data=(x_test, x_test))
# 使用编码器和解码器进行编码和解码
encoded_imgs = encoder.predict(x_test)
decoded_imgs = decoder.predict(encoded_imgs)
# 可视化结果
n = 10 # 显示10个数字
plt.figure(figsize=(20, 4))
for i in range(n):
# 原始图像
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# 重构图像
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
说明:
- 数据预处理: 加载MNIST数据集,并将其像素值归一化到[0,1]区间。
- 模型构建:
- 编码器: 输入层连接到一个隐藏层(编码层),将数据压缩到32维。
- 解码器: 将编码后的数据重构回原始维度。
- 自编码器: 编码器和解码器组合在一起形成完整的自编码器模型。
- 训练模型: 使用
binary_crossentropy损失函数和adam优化器进行训练。 - 结果可视化: 显示原始图像和重构图像,以比较它们的相似性。
输出:
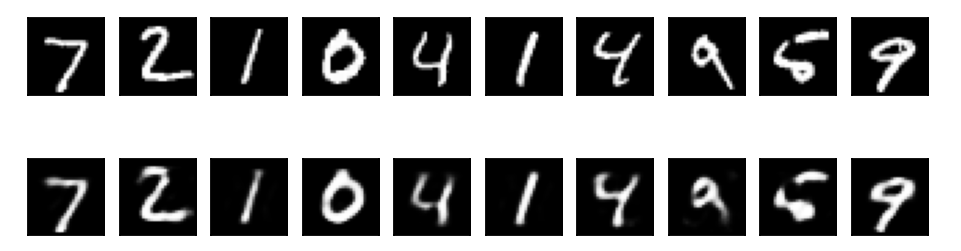
5. 自编码器的应用
自编码器(Autoencoders)具有广泛的应用场景,以下是一些主要的应用领域:
1. 数据降维
自编码器可以用于高维数据的降维,将数据压缩到低维空间,从而减少存储和计算的复杂性。这种方法在很多方面可以替代主成分分析(PCA),特别是在处理非线性数据时(Springer)(MDPI)。
2. 特征提取
在无监督学习中,自编码器能够自动学习数据的潜在特征表示。通过训练自编码器模型,可以提取输入数据的有用特征,这些特征可以用于其他机器学习任务,例如分类和聚类(ar5iv)。
3. 图像去噪
去噪自编码器(Denoising Autoencoders, DAE)被用来去除图像中的噪声。通过向输入图像添加噪声,并训练自编码器去重构原始的无噪声图像,可以有效地消除噪声(Springer)。
4. 数据生成
变分自编码器(Variational Autoencoders, VAE)是一种生成模型,可以用来生成与训练数据分布相似的新数据。VAE在潜在空间中引入了随机性,使得生成的样本具有多样性(ar5iv) (ar5iv)。
5. 异常检测
自编码器可以用来检测数据中的异常点。通过训练自编码器重构正常数据,任何重构误差较大的数据点可能就是异常点。这个方法广泛应用于工业设备故障检测、网络入侵检测等领域(Springer)。
6. 图像和视频压缩
自编码器可以用于图像和视频压缩,通过将图像和视频数据压缩到潜在空间,再从潜在空间重构,从而实现高效压缩(MDPI)。
7. 自监督学习
自编码器作为自监督学习的一个重要工具,可以在没有标签的数据上进行预训练,帮助提升有监督学习任务的效果。它在自然语言处理、图像识别等领域有重要应用(ar5iv)。
8. 数据填补
自编码器可以用于数据缺失值的填补。通过训练自编码器重构完整数据,可以用潜在空间的表示来推断并填补缺失的数据(MDPI)。