文章目录
- 0. 前言
- 1. 安装ElasticSearch
- 1.1 下载安装包
- 1.2 新增用户
- 1.3 解压安装包
- 1.4 更改文件夹用户
- 1.5 修改配置文件
- 1.6 修改系统配置
- 1.7 启动集群
- 2. 安装FSCrawler
- 2.1 下载安装包
- 2.2 创建配置文件
- 2.3 修改配置文件
- 2.4 启动
- 2.5 验证是否被索引
0. 前言
Elasticsearch 是一个开源的分布式搜索和分析引擎,基于 Apache Lucene 构建。它被广泛用于各种数据搜索、日志和数据分析的场景。Elasticsearch 以其强大的实时搜索能力、可伸缩性和易用性而著称。
典型使用场景
(1)日志分析:Elasticsearch 常与 Logstash 和 Kibana 一起使用,构成 ELK/Elastic Stack,用于收集、处理和可视化日志数据。
(2)全文搜索:适用于网站、应用程序和其他系统的搜索功能,提供快速、精准的搜索结果。
(3)数据分析:可以用于分析各种数据,如用户行为数据、财务数据、物联网数据等,支持实时和离线分析。
(4)监控和报警:用于监控系统的性能和健康状态,基于设定的规则触发报警。
1. 安装ElasticSearch
1.1 下载安装包
建议7.x版本的ElasticSearch
二选一:
(1)手动下载安装包
-
官方链接。如果下载太慢,这个不推荐。
-
华为镜像包。推荐。
(2)linux 命令安装
wget https://mirrors.huaweicloud.com/elasticsearch/7.9.3/elasticsearch-7.9.3-linux-x86_64.tar.gz
1.2 新增用户
所有节点都需要操作
ElasticSearch 不允许 root 用户操作,需要新建用户(在所有节点上都需要新增用户):
useradd es # 新增 es 用户
passwd es # 为 es 用户设置密码
此时 /home 应该会创建一个新的目录 es
1.3 解压安装包
所有节点都需要操作
将压缩包拷贝到 /home/es 下,然后解压:
tar -zxf elasticsearch-7.9.3-linux-x86_64.tar.gz
1.4 更改文件夹用户
所有节点都需要操作
chown -R es:es elasticsearch-7.9.3
1.5 修改配置文件
所有节点都需要操作
elasticsearch.yml 配置字段说明:
cluster.name # 配置es的集群名称,默认是elasticsearch,es会自动发现在同一网段下的es,如果在同一网段下有多个集群,就可以用这个属性来区分不同的集群。
node.name # 节点名,默认随机指定一个name列表中名字,该列表在es的jar包中config文件夹里name.txt文件中
node.master # 指定该节点是否有资格被选举成为master,默认是true,es是默认集群中的第一台机器为master,如果这台机挂了就会重新选举master。
node.data # 指定该节点是否存储索引数据,默认为true。
index.number_of_shards # 设置默认索引分片个数,默认为5片。分片的数量:
# 1, 单个分片的大小不要超过32g —— 控制每个分片占用的硬盘容量不超过ES的最大JVM的堆空间设置(一般设置不超过32G,参加上文的JVM设置原则),因此,如果索引的总容量在500G左右,那分片大小在16个左右即可;当然,最好同时考虑原则2。
# 2. shard总数量不超过节点数的3倍 —— 考虑一下node数量,一般一个节点有时候就是一台物理机,如果分片数过多,大大超过了节点数,很可能会导致一个节点上存在多个分片,一旦该节点故障,即使保持了1个以上的副本,同样有可能会导致数据丢失,集群无法恢复。所以, 一般都设置分片数不超过节点数的3倍。
index.number_of_replicas # 设置默认索引副本个数,默认为1个副本。
path.conf # 设置配置文件的存储路径,默认是es根目录下的config文件夹。
path.data # 设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开,例:path.data: /path/to/data1,/path/to/data2
path.work # 设置临时文件的存储路径,默认是es根目录下的work文件夹。
path.log # 设置日志文件的存储路径,默认是es根目录下的logs文件夹
path.plugins # 设置插件的存放路径,默认是es根目录下的plugins文件夹
bootstrap.mlockall # 设置为true来锁住内存。因为当jvm开始swapping时es的效率 会降低,所以要保证它不swap,可以把ES_MIN_MEM和ES_MAX_MEM两个环境变量设置成同一个值,并且保证机器有足够的内存分配给es。 同时也要允许elasticsearch的进程可以锁住内存,linux下可以通过`ulimit -l unlimited`命令。
network.bind_host # 设置绑定的ip地址,可以是ipv4或ipv6的,默认为0.0.0.0。
network.publish_host # 设置其它节点和该节点交互的ip地址,如果不设置它会自动判断,值必须是个真实的ip地址。
network.host # 这个参数是用来同时设置bind_host和publish_host上面两个参数。
transport.tcp.port # 设置节点间交互的tcp端口,默认是9300。
transport.tcp.compress # 设置是否压缩tcp传输时的数据,默认为false,不压缩。
http.port # 设置对外服务的http端口,默认为9200。
http.max_content_length # 设置内容的最大容量,默认100mb
http.enabled # 是否使用http协议对外提供服务,默认为true,开启。
gateway.type # gateway的类型,默认为local即为本地文件系统,可以设置为本地文件系统,分布式文件系统,hadoop的HDFS,和amazon的s3服务器。
gateway.recover_after_nodes # 设置集群中N个节点启动时进行数据恢复,默认为1。
gateway.recover_after_time # 设置初始化数据恢复进程的超时时间,默认是5分钟。
gateway.expected_nodes # 设置这个集群中节点的数量,默认为2,一旦这N个节点启动,就会立即进行数据恢复。
cluster.routing.allocation.node_initial_primaries_recoveries # 初始化数据恢复时,并发恢复线程的个数,默认为4。
cluster.routing.allocation.node_concurrent_recoveries # 添加删除节点或负载均衡时并发恢复线程的个数,默认为4。
indices.recovery.max_size_per_sec # 设置数据恢复时限制的带宽,如入100mb,默认为0,即无限制。
indices.recovery.concurrent_streams # 设置这个参数来限制从其它分片恢复数据时最大同时打开并发流的个数,默认为5。
discovery.zen.minimum_master_nodes # 设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4)
discovery.zen.ping.timeout # 设置集群中自动发现其它节点时ping连接超时时间,默认为3秒,对于比较差的网络环境可以高点的值来防止自动发现时出错。
discovery.zen.ping.multicast.enabled # 设置是否打开多播发现节点,默认是true。
discovery.zen.ping.unicast.hosts: ["host1", "host2:port", "host3[portX-portY]"] # 设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点。
例如,修改一个 elasticsearch-7.9.3/config/elasticsearch.yml 配置文件:
# 集群名称
cluster.name: cluster-es
# 当前节点名称,每个节点名字都需要设置,不能重复
node.name: node-1
# 当前对外的节点ip/域名地址,设置为0.0.0.0,那么就不限制主机的访问和节点的交互
network.host: 0.0.0.0
# 是不是有资格成为主节点
node.master: true
node.data: true
http.port: 9200
# head插件需要配置
http.cors.allow-origin: "*"
http.cors.enabled: true
http.max_content_length: 200mb
# 7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举 master
cluster.initial_master_nodes: ["node-1"]
# 7.x 之后新增的配置,节点发现
discovery.seed_hosts: ["node2:9300","node3:9300","node4:9300"]
gateway.recover_after_nodes: 2
network.tcp.keep_alive: true
network.tcp.no_delay: true
transport.tcp.compress: true
# 集群内同时启动的数据任务个数,默认是 2 个
cluster.routing.allocation.cluster_concurrent_rebalance: 16
# 添加或删除节点及负载均衡时并发恢复的线程个数,默认 4 个
cluster.routing.allocation.node_concurrent_recoveries: 16
# 初始化数据恢复时,并发恢复线程的个数,默认 4 个
cluster.routing.allocation.node_initial_primaries_recoveries: 16
对于集群的其他节点,也需要修改上述文件,例如node2配置文件如下:
# 集群名称
cluster.name: cluster-es
# 当前节点名称,每个节点名字都需要设置,不能重复
node.name: node-2
# 当前对外的节点ip/域名地址,设置为0.0.0.0,那么就不限制主机的访问和节点的交互
network.host: 0.0.0.0
# 是不是有资格成为主节点
node.master: true
node.data: true
http.port: 9200
...
1.6 修改系统配置
所有节点都需要操作
/etc/security/limits.conf 在最后一行添加:
es soft nofile 65536
es hard nofile 65536
/etc/sysctl.conf,添加如下:
vm.max_map_count=655360
配置生效:
sysctl -p
1.7 启动集群
所有节点,用es用户执行
二进制启动:
/home/es/elasticsearch-7.9.3/bin/elasticsearch -d
检查是否当前正常工作:
curl localhost:9200
{
"name" : "node-1",
"cluster_name" : "cluster-es",
"cluster_uuid" : "EFgx4qIcRo-_oAtAzQCabg",
"version" : {
"number" : "7.9.3",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "c4138e51121ef06a6404866cddc601906fe5c868",
"build_date" : "2020-10-16T10:36:16.141335Z",
"build_snapshot" : false,
"lucene_version" : "8.6.2",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
检查集群节点是否正常:
curl localhost:9200/_cat/nodes
192.168.76.116 27 97 9 19.83 20.97 21.14 dilmrt - node-3
192.168.76.114 25 98 4 8.62 8.81 8.82 dilmrt * node-1
192.168.76.115 17 77 11 21.00 21.30 21.36 dilmrt - node-2
2. 安装FSCrawler
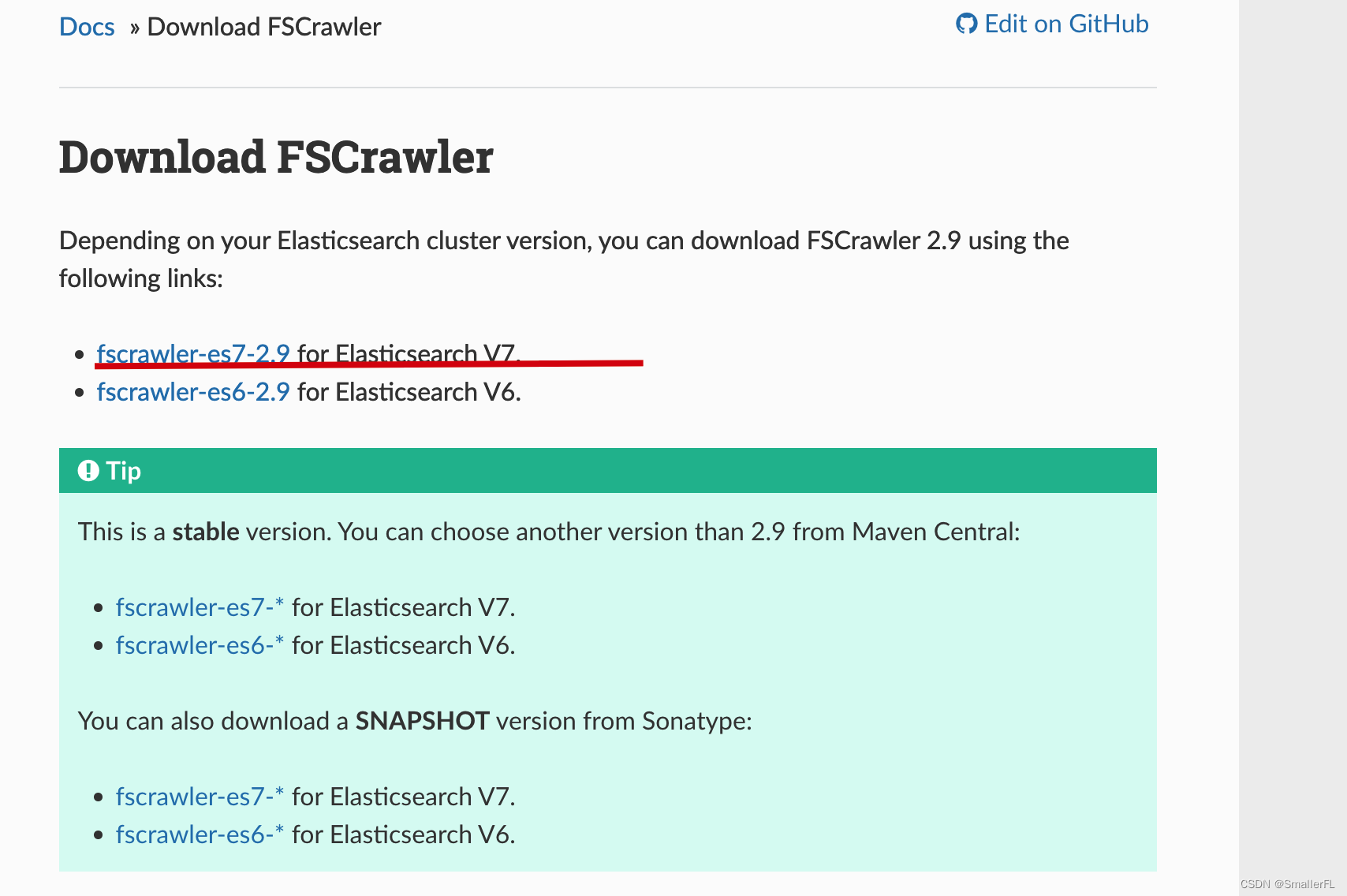
2.1 下载安装包
下载链接看这里
ElasticSearch 7.x 版本对应 fscrawler-es7-2.9;
ElasticSearch 6.x 版本对应 fscrawler-es6-2.9;
2.2 创建配置文件
进入到解压的 fscrawler 文件夹中,执行:
./bin/fscrawler my_file_job --config_dir /xx/xxx
--config_dir 是指定配置文件的路径,选择自己的路径即可;
在你指定的 --config_dir 下会创建一个 _setting.yaml。
2.3 修改配置文件
默认的 _setting.yaml 如下:
---
name: "my_file_job"
fs:
url: "/tmp/es"
update_rate: "15m"
excludes:
- "*/~*"
json_support: false
filename_as_id: false
add_filesize: true
remove_deleted: true
add_as_inner_object: false
store_source: false
index_content: true
attributes_support: false
raw_metadata: false
xml_support: false
index_folders: true
lang_detect: false
continue_on_error: false
ocr:
language: "eng"
enabled: true
pdf_strategy: "ocr_and_text"
follow_symlinks: false
elasticsearch:
nodes:
- url: "http://127.0.0.1:9200"
bulk_size: 100
flush_interval: "5s"
byte_size: "10mb"
ssl_verification: true
其中有关 _setting.yaml 的字段解释:
(1)fs字段配置,官方参考这里
name: "my_file_job"
fs:
url: "/path/to/your/data" # 要索引的文件系统路径
update_rate: "15m" # 多长时间检查一次文件更新
includes: ["*.txt", "*.pdf"] # 包含的文件类型
excludes: ["*.log", "*/temp/*"] # 排除的文件类型
json_support: false # 是否支持 JSON 文件
filename_as_id: true # 是否使用文件名作为文档ID
add_filesize: true # 是否添加文件大小字段
remove_deleted: true # 是否从索引中删除已删除文件
store_source: true # 是否存储文件源
indexed_chars: 10000 # 索引的字符数
attributes_support: true # 是否索引文件属性
raw_metadata: true # 是否索引原始元数据
xml_support: false # 是否支持 XML 文件
index_content: true # 是否索引文件内容
index_folders: true # 是否索引文件夹
follow_symlinks: false # 是否跟随符号链接
lang_detect: true # 是否启用语言检测
continue_on_error: false # 是否在错误时继续
pdf_ocr: true # 是否对 PDF 文件使用 OCR
ocr:
language: "eng" # OCR 的语言
path: "/path/to/tesseract" # Tesseract OCR 的路径
data_path: "/path/to/tessdata" # Tesseract 数据路径
(2)elasticsearch字段配置,官方参考这里
name: "my_file_job"
elasticsearch:
nodes:
- url: "http://localhost:9200" # Elasticsearch 节点的 URL
username: "elastic" # 连接 Elasticsearch 的用户名
password: "changeme" # 连接 Elasticsearch 的密码
bulk_size: 100 # 批量处理的文档数量
flush_interval: "5s" # 刷新间隔时间
byte_size: "10mb" # 批量请求的字节大小限制
index: "fscrawler_index" # 索引名称
index_folder: "fscrawler_folder_index" # 文件夹索引名称
type: "_doc" # 文档类型(Elasticsearch 7.x 之后建议使用 `_doc`)
pipeline: "attachment" # 指定的 Ingest 管道
2.4 启动
修改完配置文件之后,再次执行:
./bin/fscrawler my_file_job --config_dir /xx/xxx
2.5 验证是否被索引
(1)使用 curl 检查索引
curl -X GET "localhost:9200/_cat/indices?v"
能够看到一个名为 my_file_job 的索引。
(2)返回包含搜索词 your_search_term 的文档。
# 使用 cURL 查询索引数据
curl -X GET "localhost:9200/my_file_job/_search?q=content:your_search_term&pretty"
欢迎关注本人,我是喜欢搞事的程序猿; 一起进步,一起学习;
欢迎关注知乎/CSDN:SmallerFL
也欢迎关注我的wx公众号(精选高质量文章):一个比特定乾坤