这篇论文的标题是《LongRAG: Enhancing Retrieval-Augmented Generation with Long-context LLMs》,由滑铁卢大学的Ziyan Jiang、Xueguang Ma和Wenhu Chen撰写。论文主要探讨了在传统的检索增强生成(RAG)框架中存在的一些问题,并提出了一种新的框架LongRAG,旨在改进检索和生成的平衡性。
代码:https://tiger-ai-lab.github.io/LongRAG/
论文摘要
在传统的RAG框架中,检索单元通常较短,如100字的维基百科段落。检索器需要在庞大的语料库中搜索,这增加了检索负担。为了减轻这种负担,作者提出了LongRAG框架,包括“长检索器”和“长阅读器”,将整个维基百科处理成4K-token的单位,使检索单元减少至60万,大大减轻了检索器的负担,显著提高了检索性能。在不需要训练的情况下,LongRAG在NQ和HotpotQA(全维基)上达到了62.7%和64.3%的EM(精确匹配)率,与最先进的模型相当。
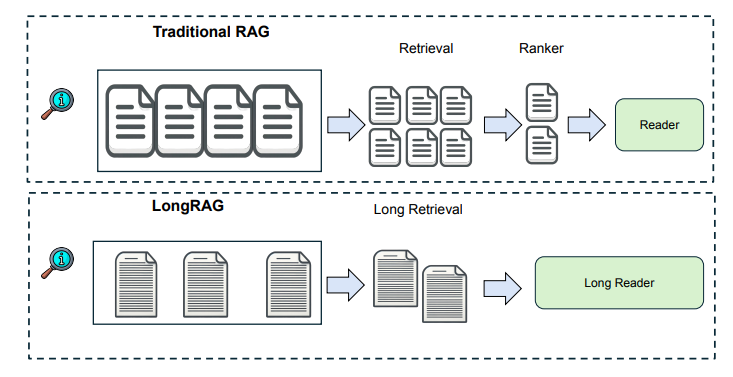
主要方法
LongRAG框架包含三个重要设计:
- 长检索单元:通过使用整个维基百科文档或将多个相关文档分组,构建超过4K token的长检索单元,显著减少语料库的大小。
- 长检索器:长检索器通过搜索长检索单元来识别相关信息,将前4到8个检索单元连接起来作为长上下文。
- 长阅读器:长阅读器从检索的长上下文中提取答案,利用现有的长上下文LLM(如Gemini或GPT-4)进行零样本答案提取。

LongRAG示例。在左侧,展示了通过超链接将维基百科文档分组形成的长检索单元。每个检索单元平均包含4K个token,对应多个相关文档。右侧展示了来自HotpotQA的多跳问答测试案例。最终结果可以通过使用少量检索单元,并将其输入到长阅读器中实现。
文档分组算法

相似性搜索
我们使用一个编码器,记为EQ(·),将输入问题映射到一个d维向量。此外,我们使用一个不同的编码器,记为EC(·),将检索单元映射到一个d维向量。我们使用它们向量的点积来定义问题与检索单元之间的相似性: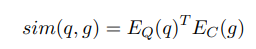
在LongRAG设置中,由于 g 的长度,计算 EC(g) 是有挑战性的,因此我们采用如下近似方法。

我们通过最大化检索单元 g 内所有子单元 g’ 的得分来进行近似。我们考虑了不同层次的粒度,包括段落级别、文档级别和完整的分组文档。在表3中展示了关于这些设置的实证研究。使用这种相似性评分设置,我们将检索与给定查询最接近的前 k 个检索单元。为了提高检索效率,我们预先计算每个检索单元 g’ 的嵌入,并在FAISS中预测精确的内积搜索索引。
汇总检索结果 我们将前 k 个检索单元连接成一个长上下文作为检索结果,记为CF=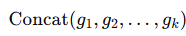 。根据检索单元的选择,较大的检索单元会导致较小的k 值。例如,如果检索单元是段落,k 大约在100以上;如果是文档,k大约为10;而如果是分组文档作为检索单元,我们通常将k设定为4到8。
。根据检索单元的选择,较大的检索单元会导致较小的k 值。例如,如果检索单元是段落,k 大约在100以上;如果是文档,k大约为10;而如果是分组文档作为检索单元,我们通常将k设定为4到8。
创新贡献
- 减少语料库大小:通过长检索单元,语料库大小从2200万减少到60万,减轻了检索器的负担。
- 提高信息完整性:长检索单元避免了语义不完整,减少了信息丢失。
- 无需再排序器:最佳结果可以通过仅考虑前4-8个检索单元实现。
实验结果
实验结果显示,LongRAG在NQ和HotpotQA上的表现显著优于传统方法,达到或接近最先进的RAG模型的性能。具体来说,在NQ数据集上,LongRAG的答案召回率(answer recall)从52%提高到71%,在HotpotQA数据集上,从47%提高到72%。
方法的优缺点
优点:
- 大幅减少了检索单元的数量和大小,减轻了检索器的负担。
- 提高了检索的准确性和信息的完整性。
- 实验结果显示其在零样本情况下性能优异。
缺点:
- 依赖于长上下文嵌入模型的性能,而现有的长上下文嵌入模型还有提升空间。
- 仅使用了黑盒LLM作为阅读器,未来可以探索更优化的阅读器模型。
总结
LongRAG框架通过平衡检索器和阅读器的负担,实现了更高效的检索和生成性能,为未来RAG系统的设计提供了新的思路。
论文下载地址
链接:https://pan.quark.cn/s/0f0b35098dc5