Redis 的有序集合(Sorted Set,简称 Zset)是一个非常强大的数据结构,它结合了集合(Set)的唯一性和列表(List)的有序性。每个元素都关联一个评分(score),并且元素按照评分值从小到大排序。这种数据结构在许多场景中都非常有用。本文将深入探讨 Redis 的 Zset 数据结构及其常用命令和应用场景。
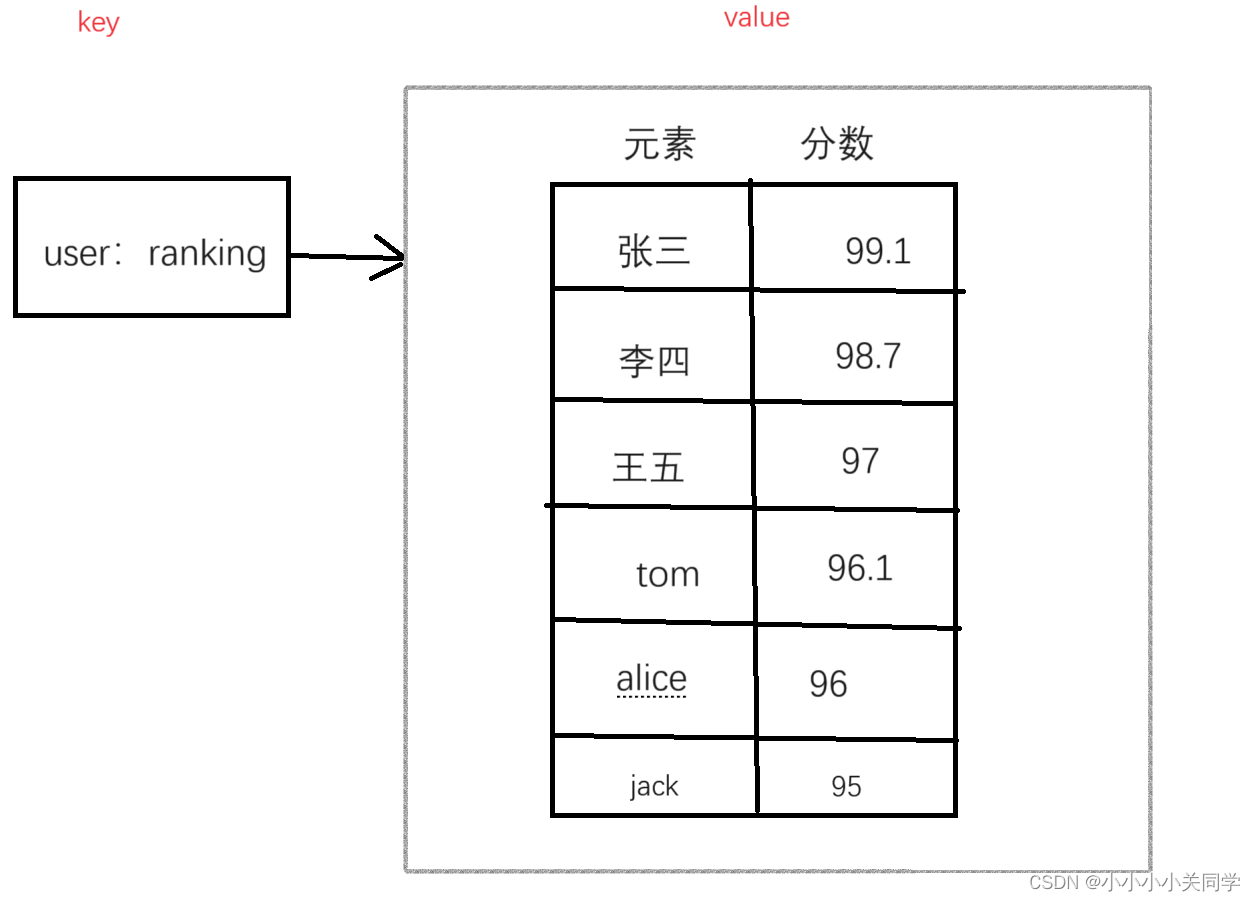
有序集合(Zset)与普通集合(Set)的主要区别在于 Zset 中的每个元素都会关联一个分值(score)。Zset 通过分值对元素进行排序,并且支持范围查询和按分值范围的操作。这使得 Zset 非常适合处理需要排序的数据。
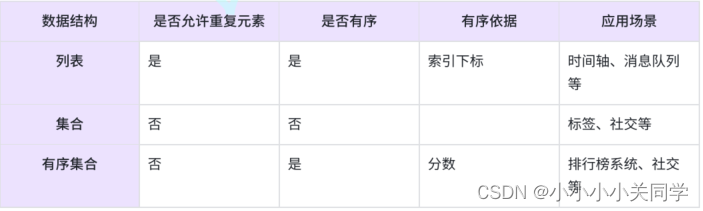
列表、集合、有序集合三者的异同点:
1. 常用命令
1.1 普通命令
1. ZADD
语法:ZADD key [NX | XX] [GT | LT] [CH] [INCR] score member [score member...]
NX:只添加新元素,不更新已存在的元素。XX:只更新已存在的元素,不添加新元素。GT:更新元素时仅在新分值大于当前分值时进行更新。LT:更新元素时仅在新分值小于当前分值时进行更新。CH:返回被修改的元素个数。INCR:对成员的分值进行累加操作。
127.0.0.1:6379> ZADD myzset 1 "one" 2 "two" 3 "three"
(integer) 3
127.0.0.1:6379> ZADD myzset 2.5 "two"
(integer) 0
2. ZRANGE
返回有序集合中指定区间内的元素,默认按照分值从小到大排序。带上WITHSCORES可以把分数也返回。
语法:ZRANGE key start stop [WITHSCORES]
此处的 [start,stop]为下标构成的区间.从0开始,支持负数.
127.0.0.1:6379> ZRANGE myzset 0 -1 WITHSCORES
1) "one"
2) "1"
3) "two"
4) "2.5"
5) "three"
6) "3"
3. ZREVRANGE
语法:ZREVRANGE key start stop [WITHSCORES]
key:有序集合的键。start:起始位置(按逆序计数,从 0 开始)。stop:结束位置(按逆序计数,可以使用 -1 表示最后一个元素)。WITHSCORES(可选):如果指定此选项,则会将成员的评分值一并返回。
返回值
- 默认情况下,返回指定范围内的成员列表,按评分值从高到低排序。
- 如果使用
WITHSCORES选项,则返回一个包含成员和评分值的列表。
127.0.0.1:6379> ZADD myzset 1 "one" 2 "two" 3 "three" 4 "four" 5 "five"
(integer) 5
127.0.0.1:6379> ZREVRANGE myzset 0 2 WITHSCORES
1) "five"
2) "5"
3) "four"
4) "4"
5) "three"
6) "3"
4. ZCARD
获取一个 zset 的基数(cardinality),即 zset 中的元素个数。
语法:ZCARD key
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZCARD myzset
(integer) 25. ZCOUNT
返回分数在 min 和 max之间的元素个数,默认情况下,min 和 max 都是包含的。
语法:ZCOUNT key min max
key:有序集合的键。min:分值范围的最小值,可以是具体的数值,也可以是-inf表示负无穷。max:分值范围的最大值,可以是具体的数值,也可以是+inf表示正无穷。
127.0.0.1:6379> ZADD myzset 1 "one" 2 "two" 3 "three" 4 "four" 5 "five"
(integer) 5
127.0.0.1:6379> ZCOUNT myzset 1 3
(integer) 3
127.0.0.1:6379> ZCOUNT myzset -inf +inf
(integer) 5
6. ZPOPMAX
语法:ZPOPMAX key [count]
key:有序集合的键。count:可选参数,表示要移除并返回的元素数量,默认值为 1。
返回值
- 默认情况下,返回有序集合中具有最高评分的元素及其评分值。如果指定了
count,则返回count个元素及其评分值。
127.0.0.1:6379> ZADD myzset 1 "one" 2 "two" 3 "three" 4 "four" 5 "five"
(integer) 5
127.0.0.1:6379> ZPOPMAX myzset
1) "five"
2) "5"
127.0.0.1:6379> ZPOPMAX myzset 3
1) "four"
2) "4"
3) "three"
4) "3"
5) "two"
6) "2"
7. BZPOPMAX
ZPOPMAX 的阻塞版本。
语法:BZPOPMAX key [key ...] timeout
key: 要操作的有序集合的键名。timeout: 如果所有指定的有序集合都为空,客户端将阻塞等待的最长时间(以秒为单位)。超时时间为0表示一直阻塞直到有数据可用,如果设置为正数,则表示等待的最长时间为该秒数。
8. ZPOPMIN与ZBPOPMIN
ZPOPMIN:删除并返回分数最低的 count 个元素。
ZBPOPMIN,ZPOPMIN的阻塞版本
9. ZRANK与ZRERANK
ZRANK 命令用于获取有序集合中指定成员的排名,排名从 0 开始计数(即第一名为 0,第二名为 1,依此类推)。
语法:ZRANK key member
key: 要操作的有序集合的键名。member: 要获取排名的成员。
返回值:
- 如果成员存在于有序集合中,返回成员的排名(从 0 开始)。
- 如果成员不存在于有序集合中,返回
nil。
注意事项
ZRANK是一个查询命令,用于获取有序集合中指定成员的排名。- 成员的排名是按照其分数从高到低的顺序进行排序的。
- 如果有多个成员具有相同的分数,它们在排名中的位置将根据其在有序集合中的存储顺序决定。
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZRANK myzset "three"
(integer) 2
redis> ZRANK myzset "four"
(nil)10. ZSCORE
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZSCORE myzset "one"
"1"11. ZREM
语法:ZREM key member [member ...] 删除指定的元素。
key: 要操作的有序集合的键名。member: 要移除的成员名。可以指定一个或多个成员。
12. ZREMRANGEBYRANK
按照排序,升序删除指定范围的元素,左闭右闭。
语法:ZREMRANGEBYRANK key start stop
key: 要操作的有序集合的键名。start: 起始排名(从 0 开始)。stop: 结束排名(从 0 开始)。
功能说明
ZREMRANGEBYRANK命令用于根据指定的排名范围删除有序集合中的成员。排名范围包含起始和结束排名。- 如果指定的排名范围超出了有序集合的实际排名范围(比如超过最后一个成员的排名),Redis 会自动截断范围,不会报错。
- 返回值为被成功移除的成员数量。
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZREMRANGEBYRANK myzset 0 1
(integer) 2
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "three"
2) "3"ZINCRBY key increment member
key: 要操作的有序集合的键名。increment: 增加的分数值,可以为负数,如果成员不存在则会自动创建并赋值。member: 要增加分数的成员。
返回值
- 执行命令成功后,返回成员增加后的新分数值(以字符串形式返回)。
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZINCRBY myzset 2 "one"
"3"
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "two"
2) "2"
3) "one"
4) "31.2 集合间操作
1. ZINTERSTORE - 求交集并存储结果
ZINTERSTORE destination numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE SUM|MIN|MAX]
- 功能:计算多个有序集合的交集,并将结果存储在一个新的有序集合
destination中。 - 参数解释:
destination:存储结果的目标有序集合的键名。numkeys:参与计算交集的有序集合的数量。key [key ...]:参与计算交集的有序集合的键名。WEIGHTS weight [weight ...](可选):指定权重,用于计算交集时调整每个有序集合中成员的分数。AGGREGATE SUM|MIN|MAX(可选):指定如何聚合多个有序集合中相同成员的分数,可以是 SUM(求和,默认)、MIN(取最小值)、MAX(取最大值)。

2. ZUNIONSTORE - 求并集并存储结果
ZUNIONSTORE destination numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE SUM|MIN|MAX]
- 功能:计算多个有序集合的并集,并将结果存储在一个新的有序集合
destination中。 - 参数解释:
destination:存储结果的目标有序集合的键名。numkeys:参与计算并集的有序集合的数量。key [key ...]:参与计算并集的有序集合的键名。WEIGHTS weight [weight ...](可选):指定权重,用于计算并集时调整每个有序集合中成员的分数。AGGREGATE SUM|MIN|MAX(可选):指定如何聚合多个有序集合中相同成员的分数,可以是 SUM(求和,默认)、MIN(取最小值)、MAX(取最大值)。
3. ZDIFFSTORE - 求差集并存储结果
ZDIFFSTORE destination key [key ...]
- 功能:计算第一个有序集合与其余有序集合的差集,并将结果存储在一个新的有序集合
destination中。 - 参数解释:
destination:存储结果的目标有序集合的键名。key [key ...]:参与计算差集的有序集合的键名。
2. 内部编码
Redis 通过对有序集合的元素数量和元素成员大小进行动态优化来选择不同的内部编码方式:
3.1 ziplist
当有序集合满足以下条件时,Redis 使用 ziplist(压缩列表)作为内部编码:
- 有序集合包含的成员数量少于
ZSET_MAX_ZIPLIST_ENTRIES(默认为 128)。 - 每个成员的长度(包括成员名和分数的存储开销)小于
ZSET_MAX_ZIPLIST_VALUE(默认为 64 字节)。
ziplist 是 Redis 的一种紧凑的连续内存结构,适合存储小型数据集。它可以在不引入额外指针和复杂结构的情况下实现快速的内存分配和访问。
3.2 skiplist
一旦有序集合的大小超过了 ziplist 的限制,Redis 将使用 skiplist 作为内部编码方式。skiplist 提供了更高效的插入、删除和范围查找操作,尤其是在处理大型数据集时表现更加优越。
127.0.0.1:6379> zadd zsetkey 50 e1 60 e2 30 e3
(integer) 3
127.0.0.1:6379> object encoding zsetkey
"ziplist"127.0.0.1:6379> zadd zsetkey 50 e1 60 e2 30 e3 ... 省略 ... 82 e129
(integer) 129
127.0.0.1:6379> object encoding zsetkey
"skiplist"127.0.0.1:6379> zadd zsetkey 50 "one string bigger than 64 bytes ... 省略 ..."
(integer) 1
127.0.0.1:6379> object encoding zsetkey
"skiplist"3. 使用场景
3.1. 排行榜和计分系统
有序集合最典型的使用场景之一是排行榜和计分系统。通过有序集合的分数(score)和成员(member)的结合,可以轻松实现各种排名功能:
-
实时排行榜:将用户按照分数高低排名,比如游戏中的积分排行榜或网站中的用户活跃度排行榜。
-
热门内容:根据某个指标(如点赞数、浏览量)将内容(文章、视频等)进行排行,展示热门和流行的内容。
-
计分系统:记录用户的行为得分,比如用户在应用中的交互行为,通过增减分数来评估用户活跃度和贡献度。
场景复现:
比如我们需要展示博客系统中的用户发布的博客的点赞热门:
假设有以下几个用户及其发布的博客的点赞数据:
- 用户ID "user1:article:1" 点赞数 1000
- 用户ID "user2:article:1" 点赞数 800
- 用户ID "user3:article:1" 点赞数 1200
- 用户ID "user4:article:1" 点赞数 950
使用 ZADD 命令向有序集合中添加用户博客的点赞数据:
# 向有序集合中添加用户博客的点赞数据
ZADD blog_likes 1000 "user1:article:1"
ZADD blog_likes 800 "user2:article:1"
ZADD blog_likes 1200 "user3:article:1"
ZADD blog_likes 950 "user4:article:1"
更新点赞数据
当用户点赞或取消点赞时,我们需要更新有序集合中的点赞数据。假设用户 "user2" 获得了额外的 200 个点赞:
# 用户 "user2" 获得了额外的 200 个点赞
ZINCRBY blog_likes 200 "user2:article:1"
再次查看点赞热榜
更新后,再次查看点赞热榜的前 3 名:
ZREVRANGE blog_likes 0 2 WITHSCORES
1) "user3:article:1"
2) "1200"
3) "user2:article:1"
4) "1000"
5) "user1:article:1"
6) "1000"
2. 社交网络中的关注关系
在社交网络中,有序集合可以用来存储用户的关注关系和粉丝列表:
-
关注关系:每个用户对应一个有序集合,集合中的成员是其关注的用户,分数可以是关注时间或其他衡量关系密度的指标。
-
粉丝列表:反向查询,通过用户的 ID 查找关注该用户的其他用户列表,也可以通过分数范围查询粉丝的关注度。
3. 渐进式遍历
渐进式遍历是一种逐步处理大量数据的方法,适用于需要在有限时间和资源内处理大数据集的场景。在 Redis 中,渐进式遍历主要用于有序集合(ZSET)和其他数据结构的扫描和遍历操作,通过分批次逐步处理数据来避免阻塞和性能下降。
为什么需要渐进式遍历
在处理大数据集时,直接遍历整个数据集可能会导致以下问题:
- 阻塞:一次性处理大量数据会导致服务器长时间阻塞,影响其他操作的执行。
- 内存消耗:大数据集的遍历可能会占用大量内存,导致内存溢出或性能下降。
- 响应时间:对用户来说,长时间的操作响应可能会带来不好的用户体验。
渐进式遍历通过将大数据集的处理分解为多个小批次,逐步进行,能够有效缓解上述问题。
使用 ZSCAN 进行渐进式遍历
ZSCAN 命令是 Redis 提供的用于有序集合(ZSET)的渐进式遍历工具。它允许在不阻塞服务器的情况下,逐步扫描有序集合中的元素。
基本用法
ZSCAN 的基本语法如下:
ZSCAN key cursor [MATCH pattern] [COUNT count]
key:要遍历的有序集合的键。cursor:游标,初始值为 0,每次调用ZSCAN都会返回一个新的游标,直到游标再次变为 0,表示遍历结束。MATCH pattern:匹配模式,可选,用于筛选出符合特定模式的元素。COUNT count:每次返回的元素个数提示,实际返回数量可能会大于或小于这个值。
假设我们有一个有序集合 blog_likes,其中存储了用户发布的博客的点赞数据。我们希望逐步遍历这个有序集合中的所有元素。
首先,向有序集合中添加一些数据:
ZADD blog_likes 1000 "user1:article:1"
ZADD blog_likes 800 "user2:article:1"
ZADD blog_likes 1200 "user3:article:1"
ZADD blog_likes 950 "user4:article:1"
使用 ZSCAN 命令逐步遍历这个有序集合:
# 第一次扫描,从游标 0 开始
ZSCAN blog_likes 0
# 返回结果示例:
1) "4"
2) 1) "user1:article:1"
2) "1000"
3) "user3:article:1"
4) "1200"
# 使用新的游标继续扫描
ZSCAN blog_likes 4
# 返回结果示例:
1) "0"
2) 1) "user2:article:1"
2) "800"
3) "user4:article:1"
4) "950"
每次调用 ZSCAN 都会返回一个新的游标和一些元素,直到游标再次变为 0,表示遍历结束。
注意:

![[C#][opencvsharp]C#使用opencvsharp进行年龄和性别预测支持视频图片检测](https://img-blog.csdnimg.cn/direct/ce6fe244d81a49caa29af93f58bb06a8.png)