1. 项目介绍
本项目旨在利用先进的YOLOv8深度学习模型对麦穗进行高效、准确的检测。我们采用了GlobalWheat数据集,该数据集包含丰富的麦穗图像,为模型的训练提供了有力的数据支持。通过该实验,实现高准确率的麦穗识别,为农业生产提供智能化的监测手段。这一项目将有助于农民更准确地评估作物生长状况,优化种植策略,提高农业生产的效率和质量。
YOLOv8是目标检测领域的一款先进模型,它继承了YOLO系列的核心思想,即一次性对整个图像进行预测以实现快速目标检测。该模型在多个尺度上提供了不同大小的模型(N/S/M/L/X),以满足不同场景的需求。本实验采用YOLOv8n进行实验。
Swanhub是由极客工作室开发的一个开源模型协作分享社区。它为AI开发者提供了AI模型托管、训练记录、模型结果展示、API快速部署等功能。
-
YOLOv8模型:GitHub - YOLOv8
SwanHub:SwanHub - 创新的AI开源社区
SwanLab:SwanLab - 在线AI实验平台
项目团队:新疆大学大数据挖掘和智能计算实验室
2. 准备
2.1 安装python库
安装以下4个库
torch>=2.0.0 torchvision>=0.15.1 swanlab>=0.2.4 gradio>=3.50.2安装命令:
pip install torch>=2.0.0 torchvision>=0.15.1 swanlab>=0.2.4 gradio>=3.50.22.2 下载数据集
案例(全球麦穗数据集GlobalWheat):链接:https://pan.baidu.com/s/1HZB4na0q3u94CJyWVnRyZw
提取码:2g3n
GlobalWheat
--images
----train
------1.jpg
------2.jpg
----test
------1.jpg
------2.jpg
----vaildation
------1.jpg
------2.jpg
--labels
----train
------1.txt
------2.txt
----test
------1.txt
------2.txt
----vaildation
------1.txt
------2.txt它们各自的作用与意义:
-
GlobalWheat文件夹:该文件夹用于存储图片文件夹images与标签文件夹labels
-
images文件夹:该文件夹用于保存训练、测试、验证图片文件夹。
-
labels文件夹:该文件夹用于保存训练、测试、验证标签文件夹。
2.3 下载YOLOv8模型
模型链接:https://github.com/ultralytics/ultralytics
解压后得到ultralytics-main文件夹,并安装ultralytics库,命令如下:
pip install ultralytics2.4 创建文件目录
在ultralytics-main文件夹中创建app.py,main.py,将GlobalWheat文件夹导入,并在GlobalWheat文件夹中创建wheat.yaml

它们各自的作用分别是:
-
GlobalWheat:这个文件夹用于存储数据集
-
main.py:用于训练YOLOv8模型的脚本
-
app.py:运行Gradio Demo的脚本
-
wheat.yaml:保存数据集中训练、测试、验证集的绝对路径,以及类别。
3. 训练部分
3.1 模型训练
首先将yolov8.yaml文件导入模型,再进行模型训练。其中,data代表数据集路径,epoch代表训练次数,imgsz表示图片输入尺寸。
具体代码:
from ultralytics import YOLO
if __name__ == '__main__':
# 模型训练
model = YOLO("ultralytics/cfg/models/v8/yolov8.yaml")
model.load()
model.train(data="./GlobalWheat2020/wheat.yaml", epochs=50, imgsz=640)
3.2 初始化SwanLab
SwanLab是一个类似Tensorboard的开源训练图表可视化库,有着更轻量的体积与更友好的API,除了能记录指标,还能自动记录训练的logging、硬件环境、Python环境、训练时间等信息。

设置初始化配置参数:SwanLab库使用swanlab.init设置实验名、实验介绍、超参数等。
import swanlab
import torch
if __name__ == '__main__':
num_epochs = 50
lr = 0.01
batch_size = 16
num_classes = 1
# 设置device
try:
use_mps = torch.backends.mps.is_available()
except AttributeError:
use_mps = False
if torch.cuda.is_available():
device = "cuda"
elif use_mps:
device = "mps"
else:
device = "cpu"
# 初始化swanlab
swanlab.init(
experiment_name="yolov8", # 设置实验名
description="Train yolov8.", # 设置实验介绍
# 记录超参数
config={
"model" : "yolov8",
"optim" : "Adam",
"lr" : lr,
"batch_size" : batch_size,
"num_epochs" : num_epochs,
"num_class" : num_classes,
"device" : device,
}
)3.3 跟踪关键指标
swanlab库使用swanlab.log来记录关键指标。
例如:跟踪YOLOv8训练时的损失值,在ultralytics-main/ultralytics/engine/trainer.py中加入如下代码:
# 在trainer.py第一行加入
import swanlab
# 在trainer.py355行代码后加入
swanlab.log({"train_loss": self.loss_items[0]})3.4 main.py完整代码
根据上述模型训练和SwanLab初始化,编写main.py内容。
from ultralytics import YOLO
import swanlab
import torch
if __name__ == '__main__':
num_epochs = 50
lr = 0.01
batch_size = 16
num_classes = 1
# 检测是否支持mps
try:
use_mps = torch.backends.mps.is_available()
except AttributeError:
use_mps = False
# 检测是否支持cuda
if torch.cuda.is_available():
device = "cuda"
elif use_mps:
device = "mps"
else:
device = "cpu"
# 初始化swanlab
swanlab.init(
experiment_name="yolov8",
description="Train yolov8.",
config={
"model" : "yolov8",
"optim" : "Adam",
"lr" : lr,
"batch_size" : batch_size,
"num_epochs" : num_epochs,
"num_class" : num_classes,
"device" : device,
}
)
# 模型训练
model = YOLO("ultralytics/cfg/models/v8/yolov8.yaml")
model.load()
model.train(data="./GlobalWheat2020/wheat.yaml", epochs=50, imgsz=640, device="cuda")3.5 开始训练
运行main.py文件:

在训练开始后,ultralytics-main目录下会多一个swanlog文件夹,里面存放着训练过程数据。在训练结束后,打开终端,输入swanlab watch --logdir swanlog开启SwanLab实验看板:

点击http:127.0.0.1:5092,将在浏览器中看到实验看板。
默认页面是Project DashBoard,包含了项目信息和一个对比实验表格。

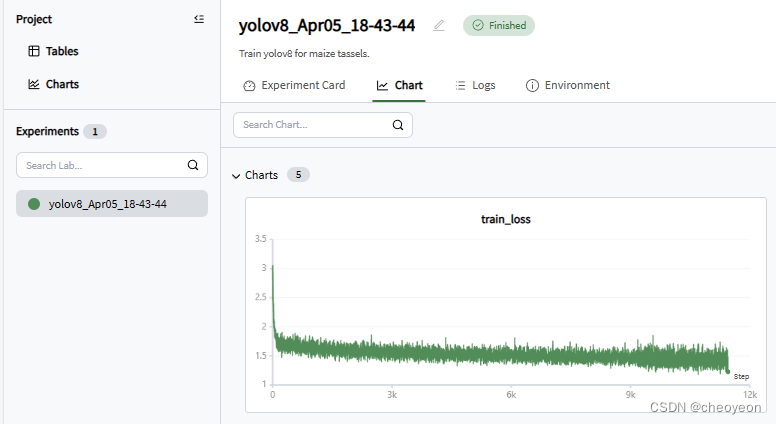
点击实验,会看到train_loss整体的变化曲线:
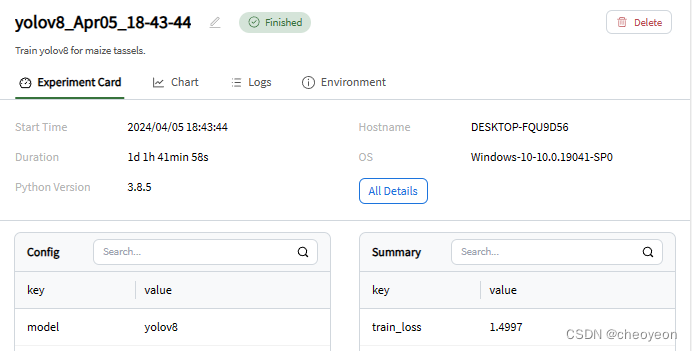
同时,可以点击Experiment Card、Logs、Environment
至此,完成了对YOLOv8模型的训练,以及对关键指标进行了追踪,得到了一个关于麦穗检测的权重文件,在runs/detect/train/weights目录下。
3.6 实验过程对比与分析
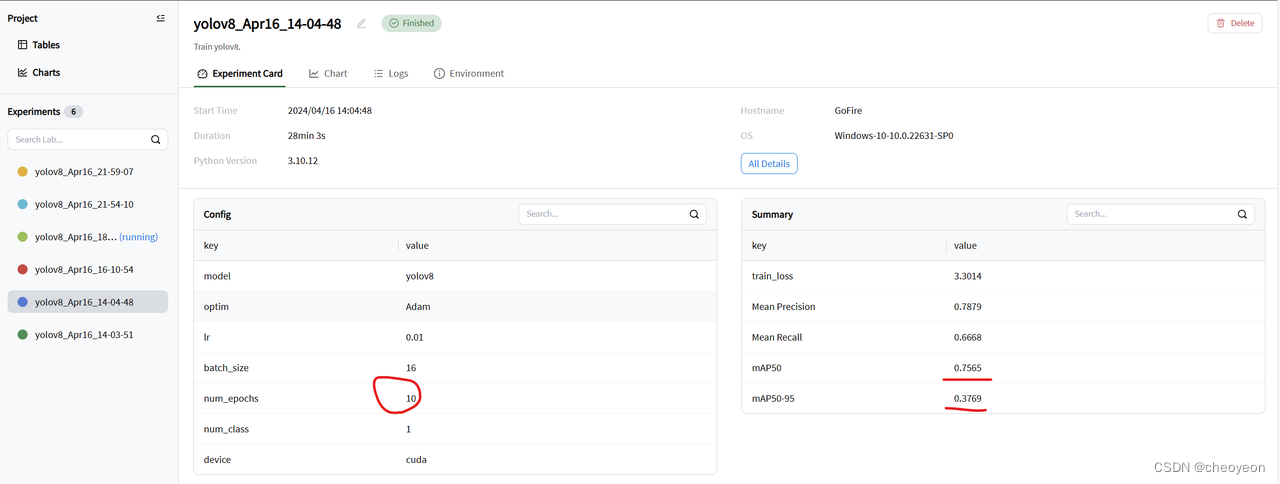
1. 了解GlobalWheat2020数据集之后,发现该数据集较大,训练时间会较长;如果epoch设置过多,可能会出现过拟合现象,而且导致不必要的资源浪费。因此,为了找到较为合适的epcoh,本实验首先预设epoch为10(较小)进行训练。epoch = 10时,通过使用swanlab对训练结果进行可视化后,可以得到检测任务中最重要的两个指标mAP50和mAP50-95分别为0.7565和0.3769;在chart中,train_loss虽然在整体趋势上收敛,但是在后段还是会出现部分起伏;而Mean Precision,Mean Recall,mAP50,mAP50-95,虽然在后段显示平稳趋势,但是在曲线前半部分均出现了平稳情况,但是整体趋势还是在保持上升,综上分析,说明epoch较小。

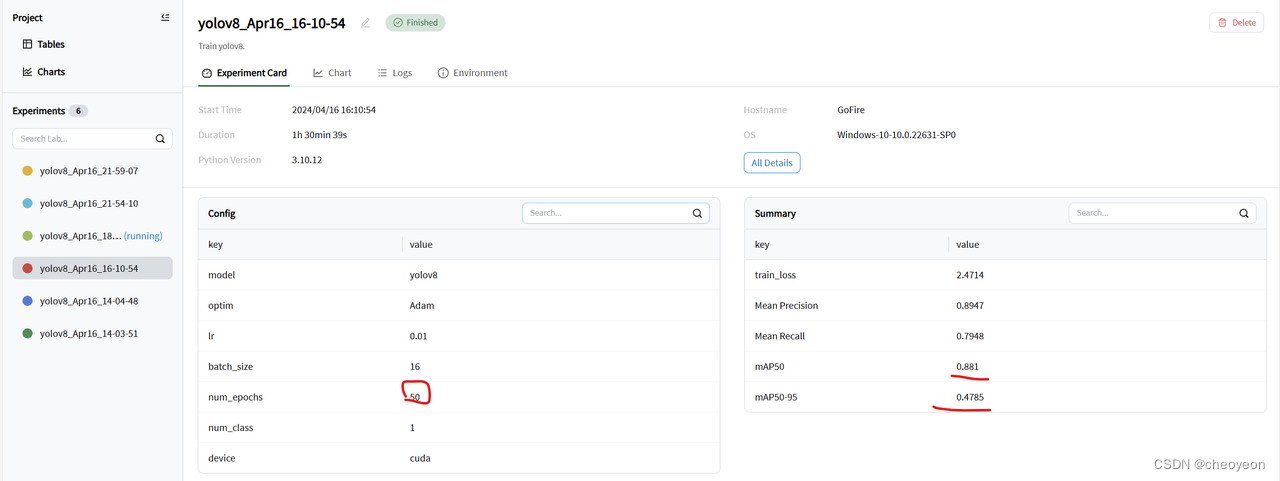
2. 根据以上结论,分析可得模型训练时设置的epoch较小,曲线趋势还没有稳定,因此,设置epoch为50,进行实验。结果如图所示,在epoch为50时,检测指标mAP50和mAP50-95分别为0.881和0.4785。相较于epoch为10,mAP50和mAP50-95分别增长了0.1245和0.1016。这说明将epoch调大,提高了模型的检测精度。如chart图所示,相较于epoch=10的chart图,train_loss不仅整体为下降趋势,而且在后段曲线的起伏更小;Mean Precision、Mean Recall、mAP50、mAP50-95也逐渐在趋于稳定。

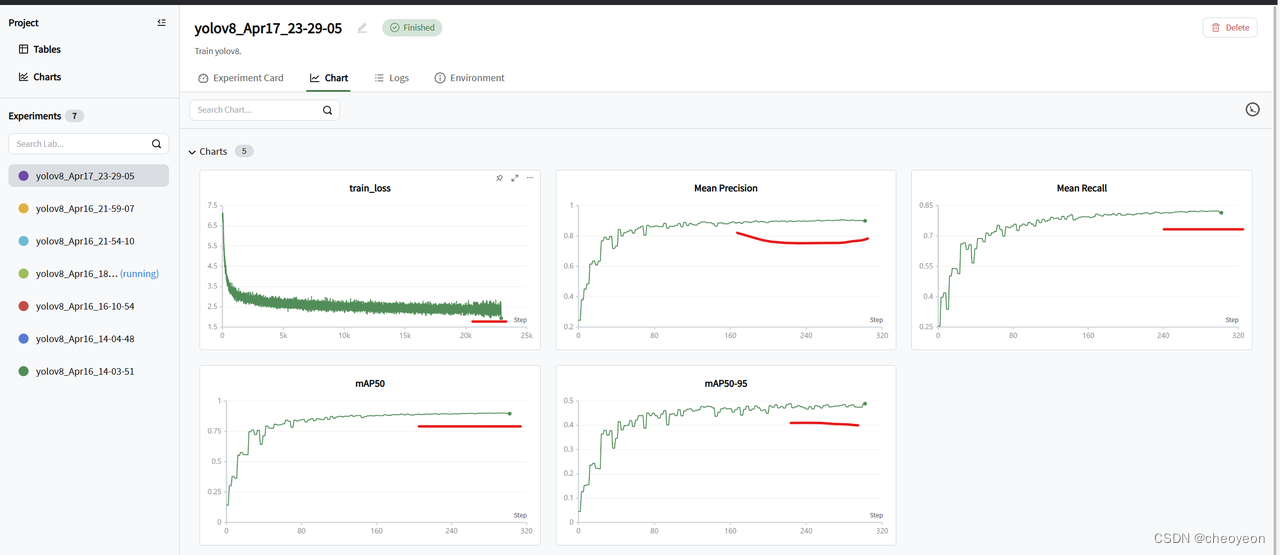
3. 由于设置epoch为50时,检测指标在后段都开始逐渐趋于稳定,因此,为了使检测指标Precision、Recall、mAP50,mAP50-95保持较为稳定的状态,本实验将epoch调至100,如图所示为训练后的结果。结果显示,当epoch=100时,mAP50和mAP50-95分别为0.8953和0.4889,相较于epoch=50都有所上升;并且,通过对训练损失曲线、Precision、Recall、mAP50和mAP50-95曲线的观察可知,损失曲线基本保持不变,而其他检测指标在曲线后段都已处于稳定状态,已没有明显的上升趋势,因此,本实验得出结论,在该数据集上,实验设置epoch为100为较优选择。

3.7 swanlab.Image()的使用
在YOLOv8中采用swanlab.Image()可以可视化训练后的效果图。
在train.py中,加入以下代码,首先初始化swanlab,在通过训练权重进行预测,即可得到检测效果图。
from ultralytics import YOLO
import swanlab
import torch
if __name__ == '__main__':
num_epochs = 10
lr = 0.01
batch_size = 16
num_classes = 1
# 设置device
if torch.cuda.is_available():
device = "cuda"
else:
device = "cpu"
# 初始化swanlab
swanlab.init(
experiment_name="yolov8",
description="Train yolov8.",
config={
"model": "yolov8",
"optim": "Adam",
"lr": lr,
"batch_size": batch_size,
"num_epochs": num_epochs,
"num_class": num_classes,
"device": device,
}
)
model = YOLO("runs/detect/train855/weights/best.pt")
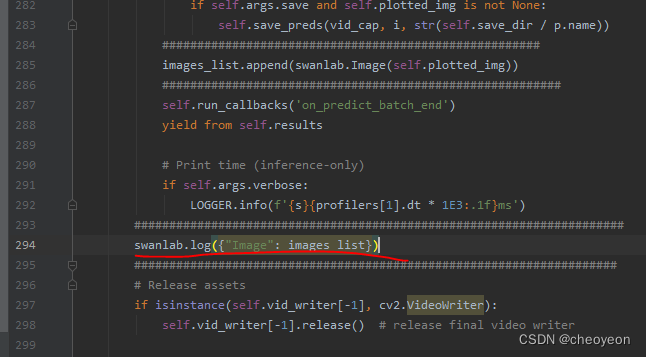
model.predict(source="dataset/images/val_dataset", save=True)使用swanlab.Image()进行可视化。在YOLOv8的predictor.py文件中,加入以下代码,所添加位置如图所示。
import swanlab
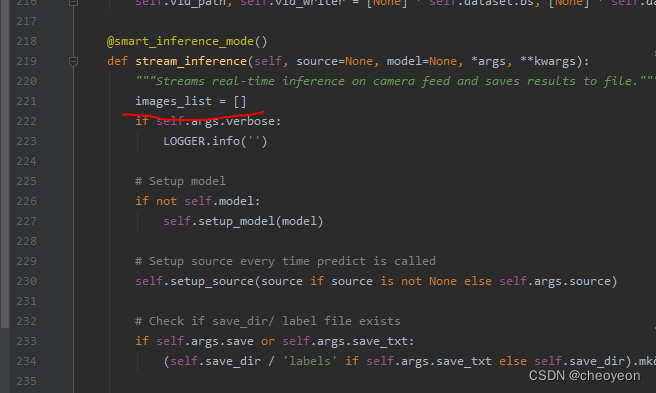
images_list = []
images_list.append(swanlab.Image(self.plotted_img))
swanlab.log({"Image": images_list})

添加完成后运行,运行结束后,在终端输入:swanlab watch --logdir ./swanlog,即可得到检测结果的可视化图,如下图所示。
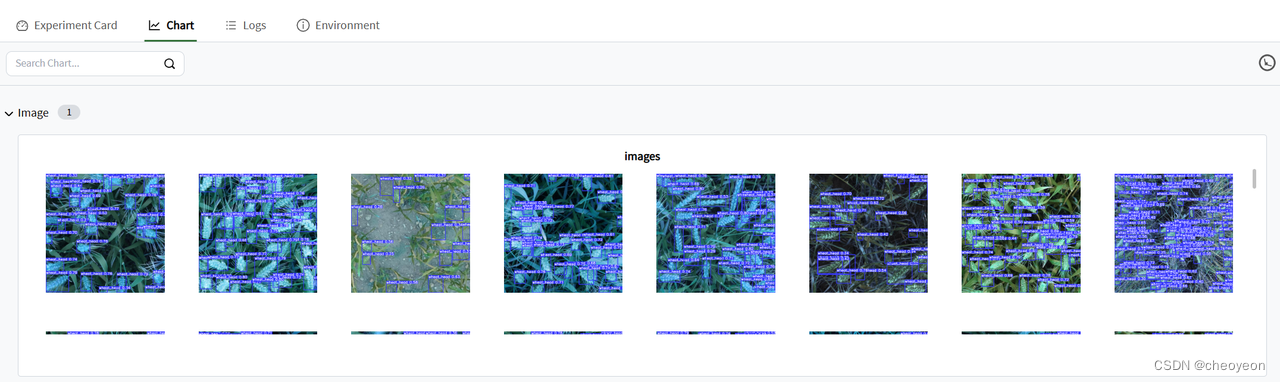
4. Gradio演示并上传至Swanhub
4.1 Gradio演示
Gradio是一个开源的Python库,旨在帮助数据科学家、研究人员和从事机器学习领域的开发人员快速创建和共享用于机器学习模型的用户界面。
在创建的app.py中编写如下代码:
import gradio as gr
from PIL import Image
from ultralytics import YOLO
def predict_image(img):
model = YOLO('./runs/detect/train/weights/best.pt')
results = model.predict(source=img, conf=0.25)
im_array = results[0].plot()
pil_img = Image.fromarray(im_array[..., ::-1])
return pil_img
if __name__ == '__main__':
# 创建Gradio界面
iface = gr.Interface(
fn=predict_image,
inputs=gr.Image(type='pil'),
outputs='image',
examples=["./GlobalWheat/images/validation/00bb861c1f4e7dacc4f04ecd0092e348bc08d408d1d98029126adf290b39f3af.jpg"],
title="wheat detection",
description="Upload an image to detect objects using Yolov8"
)
# 启动界面
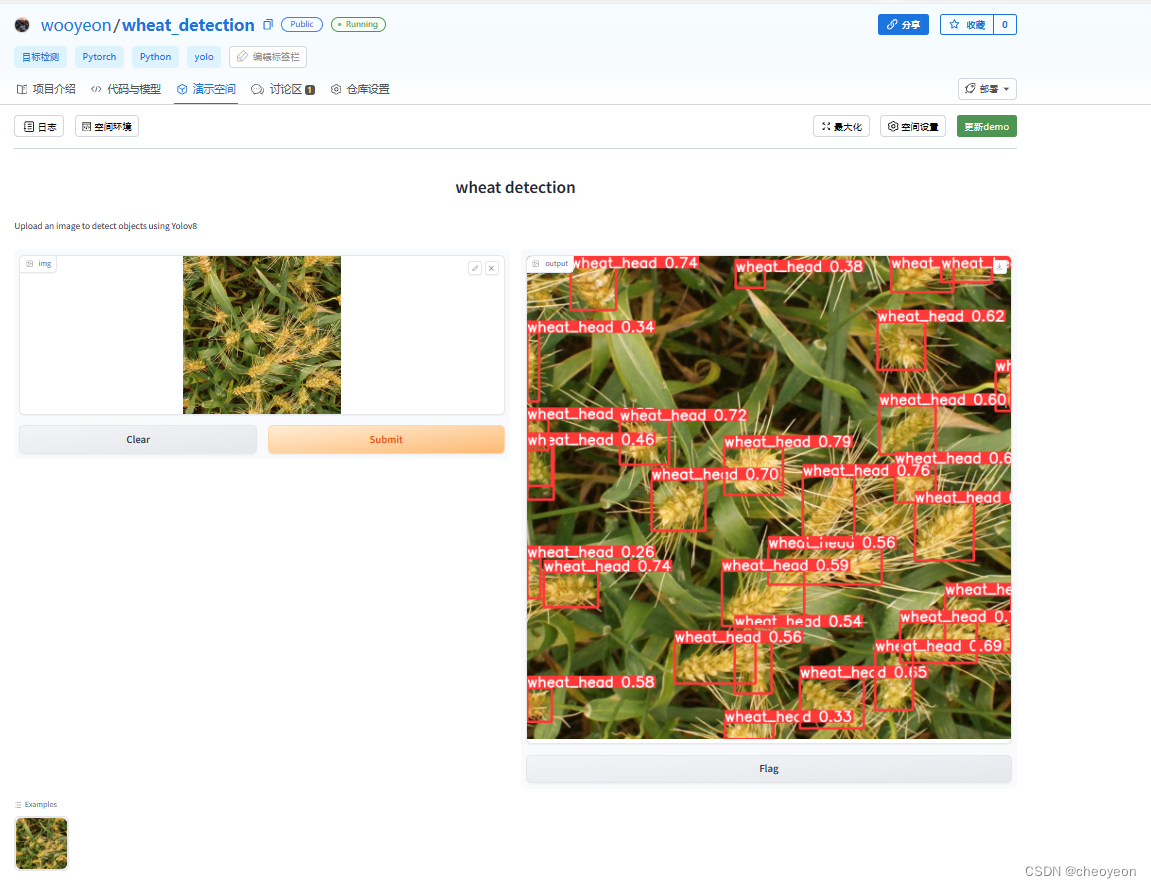
iface.launch()运行app.py后,可得到链接http://127/0.0.1:7860,点击打开

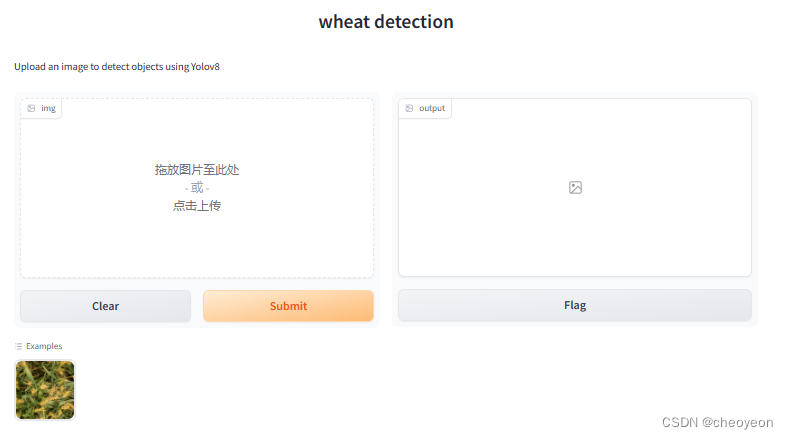
点击图片,再点击Submit,即可得到检测结果,如下图所示。

4.2 上传至Swanhub
Swanhub是由极客工作室开发的一个开源模型协作分享社区。它为AI开发者提供了AI模型托管、训练记录、模型结果展示、API快速部署等功能。https://swanhub.co/
4.2.1 注册登录Swanhub
https://swanhub.co/
4.2.2 创建仓库
根据SwanHub开源社区创建自己的仓库。点击创建仓库。
输入仓库名: Wheat_ear_detection。仓库描述:基于YOLOv8模型对麦穗进行检测,使用数据集为GlobalWheat2020。是否公开:公开。

创建文档:针对该项目创建相应的文档。主要包括:项目简介、功能特性、环境要求、效果展示等。
4.2.3 上传代码
将代码上传(建议最好不要将整个数据集一起上传,由于数据集很大会导致上传速度变慢,可以将GlobalWheat文件夹替换为Images文件夹,其中放部分展示图片即可。)
打开项目所在文件夹,右键,打开Open Git Bash here
git init # 初始化仓库
git config user.name "***" # 配置git的用户名
git config user.email "***.com" # 配置git的用户邮箱
git add . # 将项目添加到暂存区(全部代码)
git commit -m "first commit" # 添加注释(第一次提交)
git branch -M main # 进入主分支
# 添加远程仓库地址
git remote add origin https://swanhub.co/wooyeon/Wheat_ear_detection.git
git push -u origin main # 将项目上传到远程仓库
4.2.4 创建演示空间
选择Gradio、Aliyun、CPU on;y - 2 vCPU 8GB - 免费,点击创建。

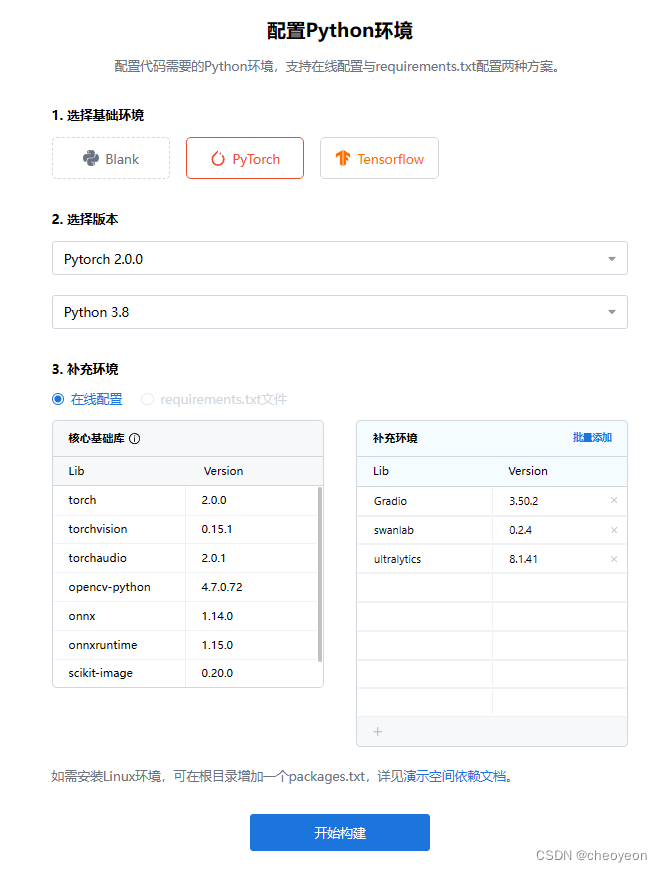
配置Python环境:PyTorch、Pytorch 2.0.0、Python3.8,并补充对应环境Gradio、swanlab、ultralytics。点击开始构建,提示成功即可。
Demo演示:
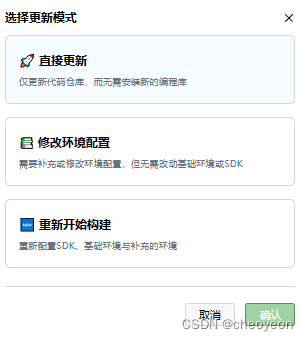
注意:如果在后续对代码,或者配置环境有所修改,都需要点击演示空间右上角绿色按钮(更新demo),根据自己情况,如果只修改了代码,直接更新即可。
5. 参考文章
PyTorch+SwanLab+Gradio+猫狗分类:轻松从可视化训练到Demo网站_gradio和pytorch-CSDN博客
SwanLab入门深度学习:YOLOv8自定义数据集检测_swamlab训练yolo-CSDN博客
YOLOv8(Ultralytics)集成SwanLab进行训练监控和可视化_swanlab yolov8-CSDN博客
Ultralytics x SwanLab:可视化YOLO模型训练_yolov10 ultralytics-CSDN博客