序言
StarRocks 存算分离借助对象存储来实现计算和存储能力分离,而存算分离版本 StarRocks 一般来说有以下三方面成本:
- 计算成本,也即机器使用成本,尤其是运行在公有云上时
- 存储成本,该部分与对象存储上存储的数据量相关
- API 访问成本,这部分与访问对象存储各种 API 的频率相关
优化数据导入模式
在存算分离中,我们推荐积攒更大批量的数据,使用低频大批量写入来代替高频微批写入,从而可以降低对象存储如 S3 的写入次数,以达到降低降低成本的作用。同时,降低写入频次还可以降低后台数据版本 Compaction 的频率,进一步降低对象存储的写入次数。
除此之外,对于某些导入模型,例如 Routine Load,我们还可以降低 Job 的并发 Task 数量来降低对象存储的写入频率,我们可以观察 BE 日志中每个 Task 的单次 KafKa 消费数据量,如果发现量较小,那我们就可以降低 并发 Task 数量来降低对象存储写入次数。
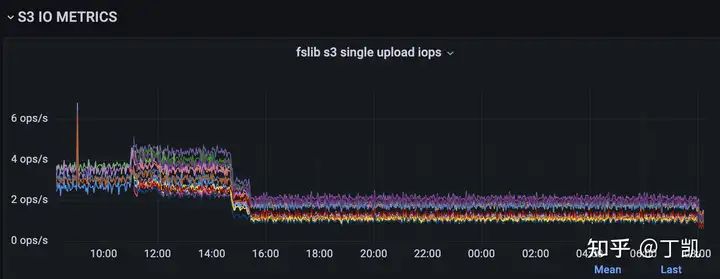
例如,下面的例子就展示了一个真实用户案例,该用户存在大量 Routine Load Job,优化之前每个 Job 的并发度为3,导致每小时可产生约15-20w 次 S3 PUT Object 调用请求。我们分析了它的 Job,发现每个 Task 单次只能从 Kafka 消费 数百行数据,于是我们果断调整了任务的并发数,从3降低为1,通过监控我们也发现,每个 BE 节点上的 IOPS 有了明显的下降,如下图所示(约从15:00 完成调整):
优化分桶数
简单解释下分桶数过多对于成本的负面影响:
- 导入时,会将数据根据分桶键 Hash 写入所有 Tablet,每个 Tablet 都会产生 S3 的 PUT Object 调用。因此,分桶数越多,PUT Object 调用也就越多
- Compaction 也会产生写入,原理同上
- 查询时,如果使用独立的 Warehouse 服务查询,首次查询时都会访问 S3,而 Tablet 越多,产生的 S3 GET Object 请求也就相应地增加。
因此,我们也需要根据业务模式和成本来合理选择创建表时的分桶数,我们一般建议:
- 如果可以,尽量创建分区表
- 根据数据量来决定分桶数,原则上我们一般建议每 1-3GB 数据量对应一个 Tablet,当然,需要还要从业务性能层面再来测试下这种策略的分桶数是否满足性能需求
读取成本优化
云上对象存储一般也会对 GET Object 调用收费(读取带宽与读取次数),因此,我们也需要特别关注该方面的成本消耗,针对这方面,我们有以下建议:
- 开启 Cache,并根据业务访问模式尽量设置合适的 Cache 策略(如选择合适大小的 disk 以及 partition_duration 等参数)
- 在新版本(3.1.7 or 3.2.2 之后)中,开启 Block Cache,能带来更高的效率和更低的成本
存储成本优化
由于 StarRocks 使用了多版本存储机制,用户通过 show data 命令看到的表的大小与表实际在对象存储可能会有所差距,因此,我们建议用户应当特别关注在对象存储上实际占据的存储容量。
目前可能有以下几点原因会造成对象存储实际消耗超过用户 show data 看到的大小:
- 导入或者 Compaction 任务失败时产生了垃圾数据未清理(在后续版本包含垃圾数据自动清理能力),如果遇到该情况,可以使用社区提供的垃圾数据清理工具扫描并清理(慎重使用,避免误删数据)
- Compaction 或者 Vacuum 不及时造成了历史版本回收不及时,此时应该重点关注并优先解决 Compaction 跟不上的问题
无论如何,我们都建议用户在日常的巡检中特别关注对象存储实际的数据使用。