背景
- OpenAI开源了一个全新的大模型调测工具:Transformer Debugger。这个工具可以帮助开发者调测大模型的推理情况,帮助我们理解模型的输出并提供一定的解释支持
- https://github.com/openai/transformer-debugger
应用场景
这一工具在多个领域展现出广泛的应用潜力:
- 科研人员:可以更直观地研究模型如何理解和生成文本。
- 开发者:能快速定位并修正模型中的偏误或不一致性。
- 教育界:利用其作为教学工具,展示语言模型的工作原理。
- 企业:进行模型审计,确保AI产品的公平性和准确性。
大语言模型难以调测和解释
-
大语言模型需要大量的计算资源来训练,包含了数以千亿的参数。因为其复杂性和“黑盒”性质,使得模型内的决策过程变得难以理解。尽管近年来出现了一些解释AI模型的方法和工具,但对于非常大和复杂的模型,这些方法往往效果有限或者难以应用。
-
特别的,对于指定的prompt,为什么大语言模型会输出特定的内容这个问题,在当前是非常难以理解但却非常有价值。如果能理解大模型的输出是什么样的机制或者由哪些网络决定的,可以帮助我们进一步优化大模型的训练质量。
-
Transformer Debugger则以可视化的形式帮助我们理解语言模型的推理过程
Transformer Debugger工具简介
OpenAI对TDB的解释如下
TDB允许在编码之前快速地探索模型的工作原理,它能够介入模型的前向传播过程,让我们可以直观地看到某个特定操作如何影响模型的行为。例如,我们可以利用它来探讨“为什么面对同一个输入提示,模型会选择输出Token A而不是Token B?”或是“为什么在某个特定的输入下,某个注意力机制(Attention Head)会偏好于Token T?”TDB通过识别对模型行为有显著影响的特定组成部分(如神经元、注意力机制头部、自编码器的潜在表示等),并自动提供这些组成部分被激活的原因解释,以及它们之间的联系,来帮助我们发现和理解复杂的模型内部工作机制

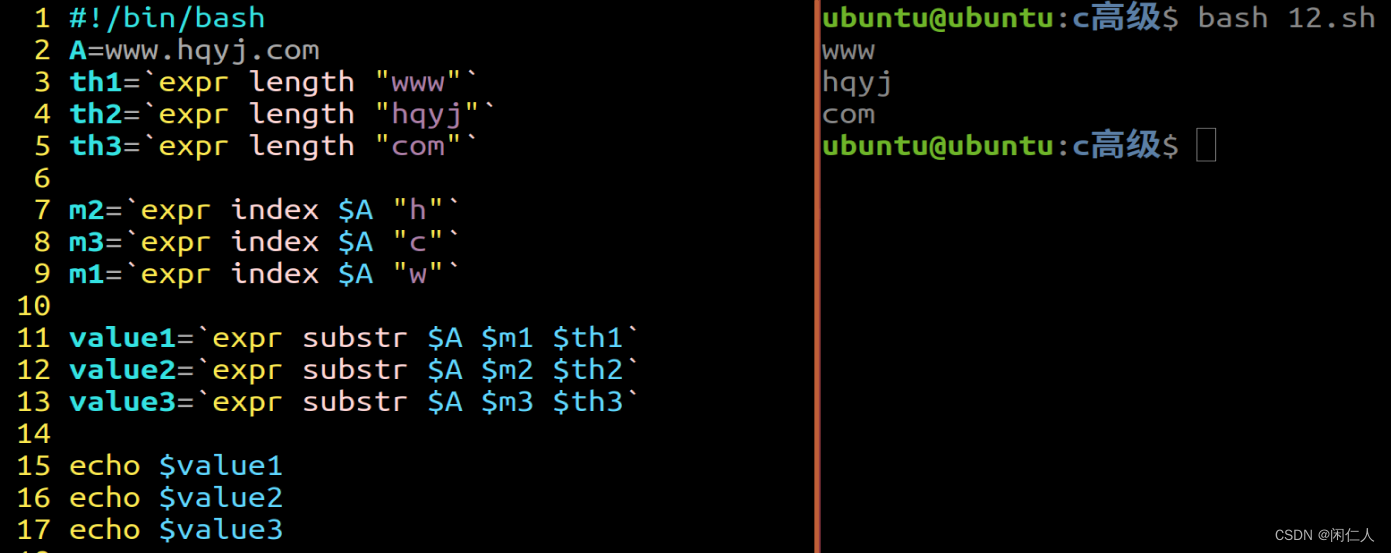
简单来说,当你输入某个prompt之后,模型会给出推理过程某个attention的结果,例如里面的attn_L9_9表示第9层的第9个attention的激活函数是0.67,以及它对后续输出的影响。如果你想看到具体的这个attention的作用,那么可以继续用下面的工具
神经元可视化(Neuron Viewer)
可以展示单个模型组件信息,包括模型的神经元、attention heads和autoencoder latents。这个组件可以帮助我们看到某个具体的模型模块的结果。例如点击上面的attn_L9_9就能得到下面的界面

- 最上面的Prompt of interest是指输入的prompt,
- 中间的Model-generated explantions是对当前选中单词的解释。
- 这里的使用青色和品红色来表示不同的Token间的注意力关系和激活程度。
- 亮青色代表一个Token接受了大量来自后续Token的注意力,
- 而亮品红色代表后续Token接受了来自当前Token的重要信息
问题
- 该项目难以二次开发维护新得到模型,模型需要拆解权重,层结构等