引用
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空 间,它和它引用的变量共用同一块内存空间。
一个变量可以有多个引用:
int main() {
//一个变量可以有多个引用
int a = 10;
int& b = a;
int& c = a;
int& d = a;
return 0;
}引用相当于给这个变量取别名,在西游记中孙悟空是孙悟空,齐天大圣也是孙悟空,弼马温也是孙悟空,孙行者也是孙悟空,斗战胜佛也是孙悟空,这些别名都是在指同一个猴子。
C++中的引用就相当于在给引用实体取别名
引用在定义的时候必须初始化:

对引用不初始化是会报错的
注意:引用类型必须和引用实体是同种类型的
引用一旦引用实体,就不能再引用其他实体:
int main() {
int a = 10;
int& b = a;
int c = 20;
b = c;
cout << "a=" << a<<endl;
cout << "b=" << b << endl;
cout << "c=" << c << endl;
return 0;
}
//输出结果a=20,b=20,c=20b是a的别名,将c赋值给b,就相当于给a赋值,所以a,b,c的值都是20
所以引用一旦引用实体后就不能引用其他实体,否知就是将其他实体的内容拷贝到引用里面
引用做参数:
交换两个数
void swap(int& x, int& y) {
int tmp = x;
x = y;
y = tmp;
}在C语言中交换两个参数需要用到指针,比较麻烦,这里使用引用就比较方便
当引用做参数时,实参传过来,相当于x,y就是实参的别名,对引用进行修改也就是对实参进行修改
私货:
typedef struct ListNode {
int val;
struct nextNode* next;
}*PNode;
void ListPushBack(PNode& phead, int x);定义一个链表的节点,重定义节点指针类型为PNode,用PNode类型做引用的类型,所以改变phead就可以改变其里面的内容。
传值和传引用比较效率:
#include<iostream>
using namespace std;
struct A {int arr[10000];};//定义一个字节数比较大的结构体
void mothed1(A a) {};//传值的方法
void mothed2(A& a) {};//传引用的方法
void test() {
A a;//创建一个结构体
size_t begin1 = clock();//记录传值方法开始的时间
for (size_t i = 0; i < 10000; i++)//进行10000次传值
{
mothed1(a);
}
size_t end1 = clock();//记录传值结束的时间
size_t begin2 = clock();//记录传引用开始的时间
for (size_t i = 0; i < 10000; i++)//进行10000次传引用
{
mothed2(a);
}
size_t end2 = clock();//记录传引用结束的时间
cout << end1 - begin1 << endl;//计算传值所花费的时间
cout << end2 - begin2 << endl;//计算传引用所花费的时间
}
int main() {
test();//调用测试函数
}//结果为6,0显然传引用的效率高于传值
引用做返回值:
传值返回:
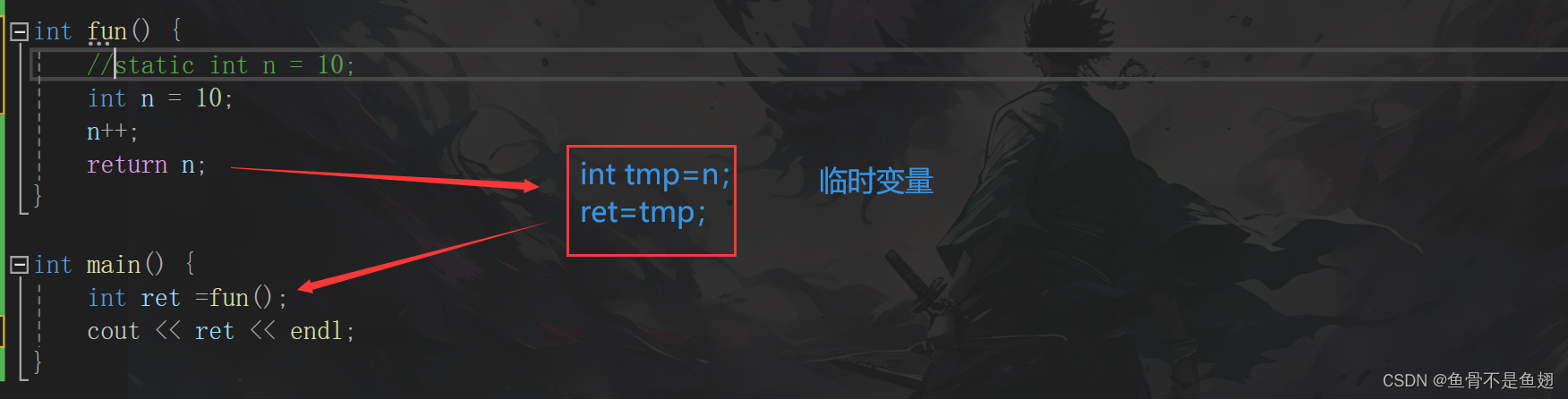
当返回值不是引用时,编译器都会生成临时变量
不管n时是否是static修饰的还是其他别的类型,只要是传值返回都要生成临时变量
传引用返回:
减少拷贝,提高效率,不会生成临时变量
struct A { int arr[10000]; };//定义一个结构体
A a;//创建一个结构体
A mothed1() { return a; };//实现一个传值返回函数
A& mothed2() { return a; };//实现一个传引用返回函数
void test() {
size_t begin1 = clock();//获取开始时间
for (size_t i = 0; i < 10000; i++)//调用10000传值返回函数
{
mothed1();
}
size_t end1 = clock();//获取结束时间
size_t begin2 = clock();//获取开始时间
for (size_t i = 0; i < 10000; i++)//调用10000次传引用返回函数
{
mothed2();
}
size_t end2 = clock();//获取结束时间
cout << end1 - begin1 << endl;//计算传值返回所用的时间
cout << end2 - begin2 << endl;//计算传引用返回所用的时间
}
int main() {
test();
}
//输出结果为18,0传值返回和传引用返回有很大差异,传引用返回的效率远高于传值返回
传引用返回的问题:
int& fun() {
int n = 10;
n++;
return n;
}
int main() {
int ret=fun();
cout<< ret;
return 0;
}当引用作为返回值时,没有临时变量,提高了效率。
当引用返回值用整形接收时,是将引用的内容拷贝到ret里面
当fun函数结束时,fun的函数栈帧会被销毁,也就是失去了访问权限
当ret指向的栈帧没有被清理时,结果不变
当ret指向的栈帧被清理后,结果为随机值
ret指向的空间没有保障
当传引用返回用引用接收:
int& fun() {
int n = 10;
n++;
return n;
}
int main() {
int &ret=fun();
cout<< ret<<endl;
printf("<<<<<<<<<<<<<\n");
rand();
cout << ret;
return 0;
}当返回值用引用接收时,ret指向引用的那块空间,在不被清理的时候,ret的值侥幸正确,当被清理时,就会ret的值就会变成随机值,就算没被清理,当调用其他函数时,栈帧会被覆盖,那就毫无疑问的变成随机值了
返回引用的实体是被static修饰的:
int& fun() {
static int n = 10;
n++;
return n;
}
int main() {
int &ret=fun();
cout<< ret<<endl;
printf("<<<<<<<<<<<<<\n");
rand();
cout << ret;
return 0;
}这时候使用引用返回是安全的
因为这时候的n是在静态区,fun结束,函数栈帧销毁对静态区的n没有影响
对引用的扩充使用:
typedef struct SeqList
{
int a[10];
size_t size;
}SqList;//定义一个简易的静态顺序表
int SLGet(SeqList* ps, int pos) {//获取对应下标的值
assert(pos >= 0 && pos < 10);
return ps->a[pos];
}
void Modify(SeqList* ps, int pos, int val) {//修改对应下标的值
assert(pos >= 0 && pos < 10);
ps->a[pos] = val;
}
int main() {
SeqList s;
Modify(&s, 0, 1);
cout << SLGet(&s, 0)<<endl;
int ret = SLGet(&s, 0);
Modify(&s, 0, ret + 5);
cout << SLGet(&s, 0) << endl;
return 0;
}这样用c语言的指针写比较麻烦
#include<assert.h>
typedef struct SeqList
{
int a[10];
size_t size;
}*SeqList;
int& SLAt(SeqList& ps, int pos) {
assert(pos >= 0 && pos < 10);
return ps->a[pos];
}
int main() {
SeqList s;
SLAt(s, 0) = 10;
cout << SLAt(s, 0) << endl;
SLAt(s, 0)++;
cout << SLAt(s, 0) << endl;
SLAt(s, 0) -= 3;
cout << SLAt(s, 0) << endl;
}引用做返回值有获取和修改返回值的功能,就可以实现指针的功能
#include<iostream>
#include<assert.h>
using namespace std;
struct SeqList
{
int a[100];
size_t size;
int& at(int pos) {
assert(pos >= 0 && pos < 100);
return a[pos];
}
int& operator[](int pos) {
assert(pos >= 0 && pos < 100);
return a[pos];
}
};
int main() {
SeqList s;
s.at(0) = 10;
s.at(0)++;
cout << s.at(0)<<endl;
s[0] = 20;
s[0]++;
cout << s[0] << endl;
return 0;
}常引用:
1.权限不能扩大
int main() {
//权限不能扩大
const int a = 10;
//int& b = a;
const int& c = a;
}a是const修饰变量,不能被修改,所以他的别名也必须被const修饰,保证权限不被扩大
2.const修饰的变量可以赋值
int main() {
const int a = 10;
int b = a;
}const修饰的a相当于常量,不能被修改,但是可以赋值,相当于将a的内容拷贝到b里面
3.引用过程中权限可以缩小和偏移
int main() {
int a = 10;
int& b = a;//权限平移
const int& c = a;//权限缩小
b++;
//c++;
}上述权限平移可以执行原来的修改,但是权限缩小就不能修改了
int& fun1() {
static int x = 10;
return x;
}
int main() {
int& ret = fun1();//权限的平移
const int& ret1 = fun1();//权限的缩小
return 0;
}ret和ret1均为x的别名
4.给常量取别名
int main() {
const int& a = 10;
}a是不能被修改的
5.隐式类型转化


6.临时变量具有常属性
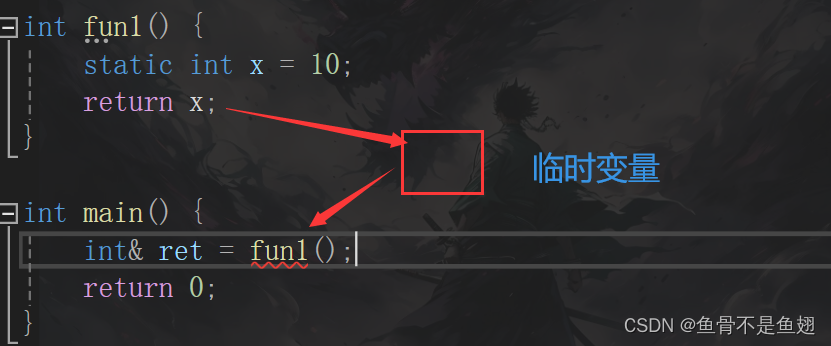
所以ret需要const修饰
引用和指针的不同点:
1. 引用概念上定义一个变量的别名,指针存储一个变量地址。
2. 引用在定义时必须初始化,指针没有要求
3. 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何 一个同类型实体
4. 没有NULL引用,但有NULL指针
5. 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32 位平台下占4个字节)
6. 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
7. 有多级指针,但是没有多级引用
8. 访问实体方式不同,指针需要显式解引用,引用编译器自己处理
9. 引用比指针使用起来相对更安全