First Fit Algorithm Best Fit Algorithm
First Fit Algorithm Best Fit Algorithm

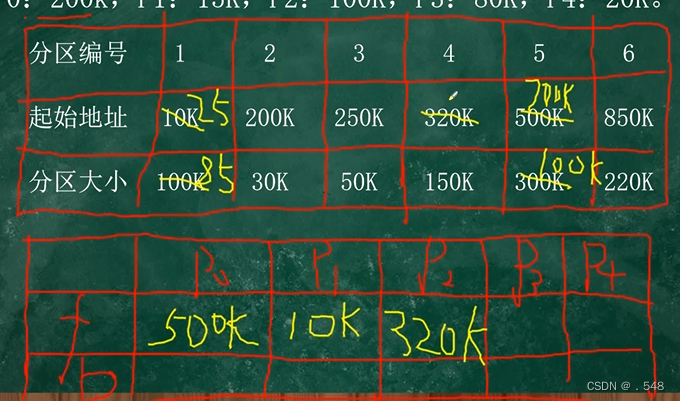
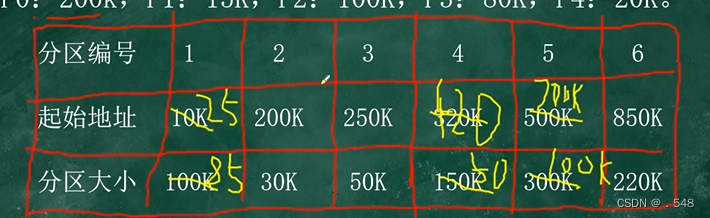
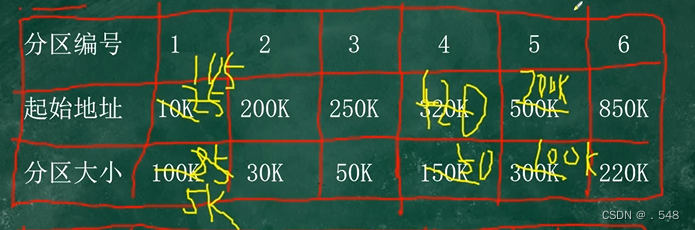
FFA:按照起始地址从小到大(本题为分区编号)找到第一个能装下进程的起始地址填入第二个表

此时 原表中将起始地址+进程大小 分区大小-进程大小

如此继续

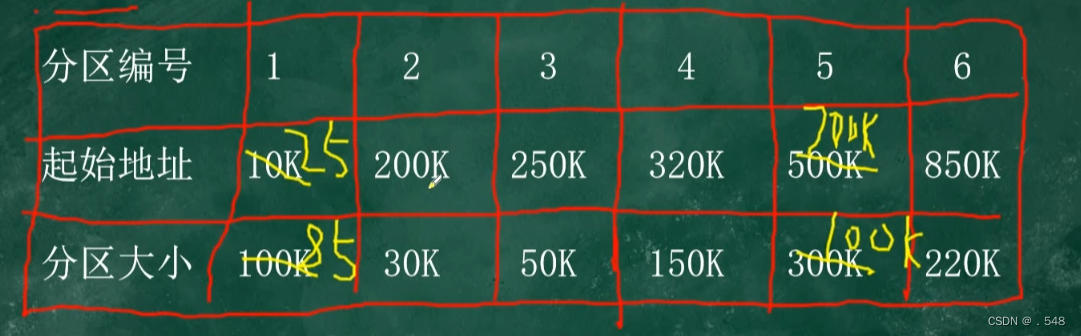
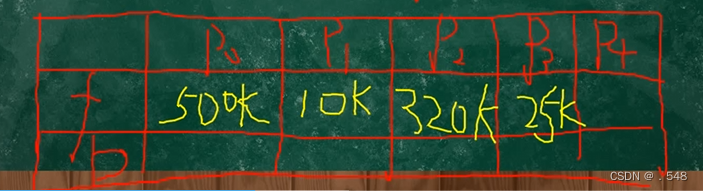

BFA:按分区大小排序 从小到大 找到第一个能装下的 剩余步骤和FFA一样


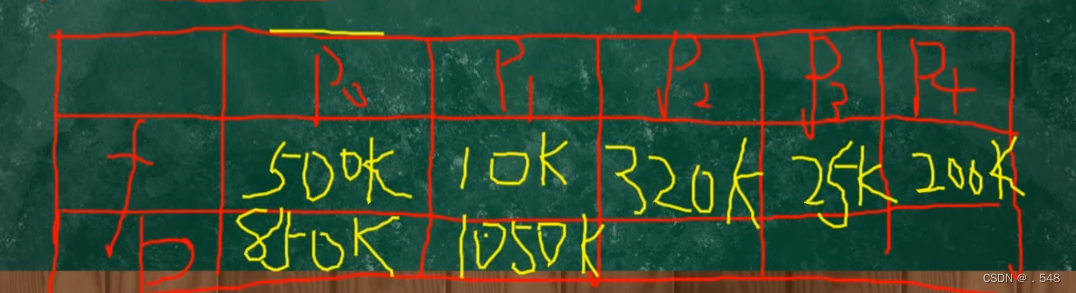
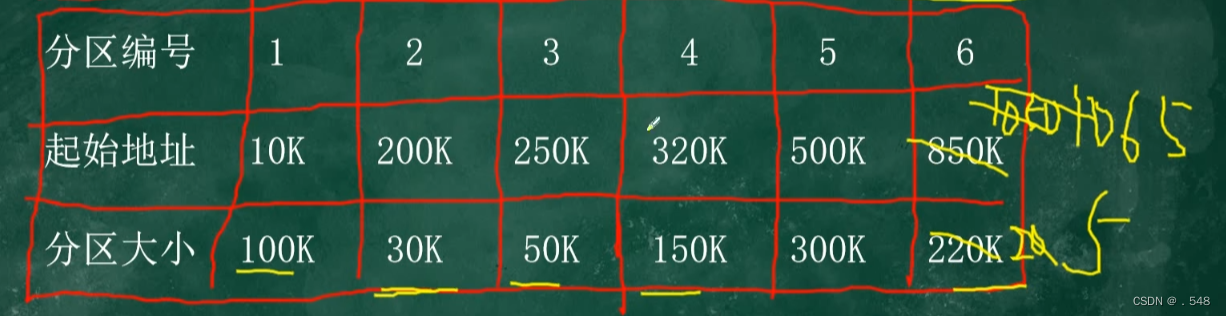


装满了可以直接忽略 因为后续不能再分配了



P0 P1 P2 P3 P4
FFA 500K 10K 320K 25K 200K
BFA 850K 1050K 10K 320K 200K
如果是next fit 每次分区的时候按照分区编号,找到第一个能装下的,但注意,从第二个开始,每次搜索的时候从上一次使用的分区开始而不是从头开始
worst fit 与best fit 相反 按分区大小从大到小,找到第一个能装下