soft real-time Vs hard real-time scheduling
Real-Time CPU Scheduling
- Can present obvious challenges
- Soft real-time systems – Critical real-time tasks have the highest priority, but no guarantee as to when tasks will be scheduled
- Hard real-time systems – task must be serviced by its deadline
- Event latency – the amount of time that elapses from when an event occurs to when it is serviced.
- Two types of latencies affect performance
- Interrupt latency – time from arrival of interrupt to start of routine that services interrupt
- Dispatch latency – time for schedule to take current process off CPU and switch to another
软实时系统--关键实时任务具有最高优先级,但无法保证任务的调度时间
- 硬实时系统--任务必须在截止日期前完成
- 事件延迟 - 从事件发生到事件得到处理所需的时间。
- 有两种延迟会影响性能
- 中断延迟 - 从中断到达到中断服务例程开始的时间
- 调度延迟--调度将当前进程从 CPU 移除并切换到另一个进程的时间

Priority-based Scheduling
- For real-time scheduling, scheduler must support preemptive, priority-based scheduling
- But only guarantees soft real-time
- For hard real-time must also provide ability to meet deadlines
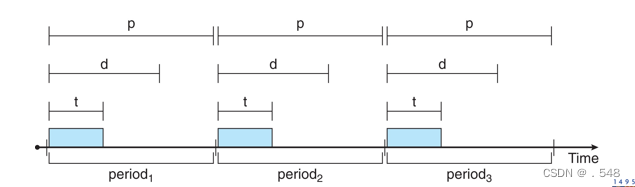
- Processes have new characteristics: periodic ones require CPU at constant intervals
- Has processing time t, deadline d, period p
- 0 ≤ t ≤ d ≤ p
- Rate of periodic task is 1/p
对于实时调度,调度器必须支持抢占式、基于优先级的调度
但只能保证软实时
对于硬实时,还必须提供满足截止日期要求的能力
进程具有新的特点:周期性进程以恒定的时间间隔需要 CPU
具有处理时间 t、截止日期 d、周期 p
0 ≤ t ≤ d ≤ p
周期任务的速率为 1/p
CPU Scheduler • The CPU scheduler selects from among the processes in ready queue, and allocates a CPU core to one of them • Queue may be ordered in various ways
• CPU scheduling decisions may take place when a process:
1. Switches from running to waiting state
2. Switches from running to ready state
3. Switches from waiting to ready
4. Terminates
• For situations 1 and 4, there is no choice in terms of scheduling. A new process (if one exists in the ready queue) must be selected for execution. • For situations 2 and 3, however, there is a choice.
Preemptive and Nonpreemptive Scheduling
- When scheduling takes place only under circumstances 1 and 4, the scheduling scheme is nonpreemptive.
- Otherwise, it is preemptive.
- Under Nonpreemptive scheduling, once the CPU has been allocated to a process, the process keeps the CPU until it releases it either by terminating or by switching to the waiting state.
- Virtually all modern operating systems including Windows, MacOS, Linux, and UNIX use preemptive scheduling algorithms.
当调度仅在第 1 和第 4 种情况下进行时,调度方案是非抢占式的。
否则,就是抢占式调度。
在非抢占式调度下,CPU 一旦分配给某个进程,该进程就会一直使用 CPU,直到通过终止或切换到等待状态来释放 CPU。
实际上,包括 Windows、MacOS、Linux 和 UNIX 在内的所有现代操作系统都使用抢占式调度算法。
- Preemptive scheduling can result in race conditions when data are shared among several processes.
- Consider the case of two processes that share data. While one process is updating the data, it is preempted so that the second process can run. The second process then tries to read the data, which are in an inconsistent state.
当多个进程共享数据时,抢占式调度可能会导致竞赛条件。
考虑两个进程共享数据的情况。当一个进程正在更新数据时,它被抢占,以便第二个进程可以运行。然后,第二个进程试图读取处于不一致状态的数据。
starvation
The situation in which a process or thread waits indefi nitely within a semaphore. Also, a scheduling risk in which a thread that is ready to run is never put onto the CPU due to the scheduling algorithm; it is starved for CPU time.
指的是进程或线程在信号量中无限期等待的情况。此外,它还指调度策略导致就绪线程无法被调度到 CPU 上执行的风险;它被 CPU 时间所“饿死”。
evaluation of scheduling algorithms FCFS SJF RR Prioring
First- Come, First-Served (FCFS) Scheduling

Suppose that the processes arrive in the order:
P2 , P3 , P1
- The Gantt chart for the schedule is:

- Waiting time for P1 = 6; P2 = 0; P3 = 3
- Average waiting time: (6 + 0 + 3)/3 = 3
- Much better than previous case
- Convoy effect - short process behind long process
Consider one CPU-bound and many I/O-bound processes
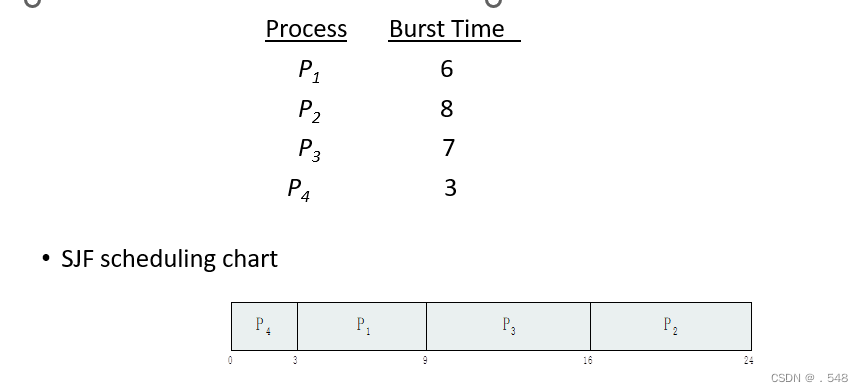
Shortest-Job-First (SJF) Scheduling
- Associate with each process the length of its next CPU burst
- Use these lengths to schedule the process with the shortest time
- SJF is optimal – gives minimum average waiting time for a given set of processes
- Preemptive version called shortest-remaining-time-first
- How do we determine the length of the next CPU burst?
- Could ask the user
- Estimate
为每个进程关联其下一次 CPU 突发的长度
使用这些长度来调度时间最短的进程
SJF 是最优的 - 为一组给定的进程提供最短的平均等待时间
抢占式版本称为 "剩余时间最短优先"。
通过询问用户和估计确定下一次cpu突发的长度
SJF算法从就绪队列中选择当前优先级最高的进程(如果有多个进程具有相同的优先级,则选择当前优先级最高的进程)。
如果就绪队列中没有进程,它从运行状态中选择一个进程。
定期检查和调整进程的优先级。
SJF也旨在最小化AWT,但它通过考虑进程的优先级而不是仅考虑它们的剩余时间来实现。
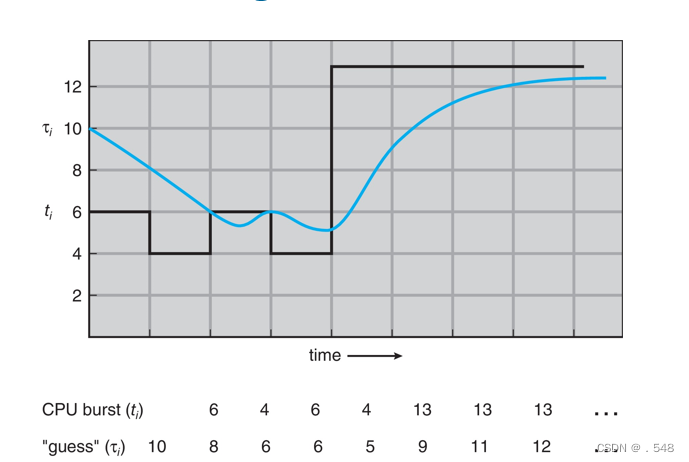
Determining Length of Next CPU Burst
- Can only estimate the length – should be similar to the previous one
- Then pick process with shortest predicted next CPU burst
- Can be done by using the length of previous CPU bursts, using exponential averaging

- Commonly, α set to ½
Shortest Remaining Time First Scheduling
Preemptive version of SJN(即SJF)
Whenever a new process arrives in the ready queue, the decision on which process to schedule next is redone using the SJN algorithm.
抢占式 SJN 版本
每当有新进程进入就绪队列,就会使用 SJN 算法重新决定下一个进程的调度。
Is SRT more “optimal” than SJN in terms of the minimum average waiting time for a given set of processes?
SRT算法安排剩余执行时间最短的进程下一个执行。
它为每个进程维护一个剩余CPU突发时间的估计。
当新进程到达或进程完成执行时,相应地更新估计。
SRT旨在最小化平均等待时间(AWT),假设估计是准确的。

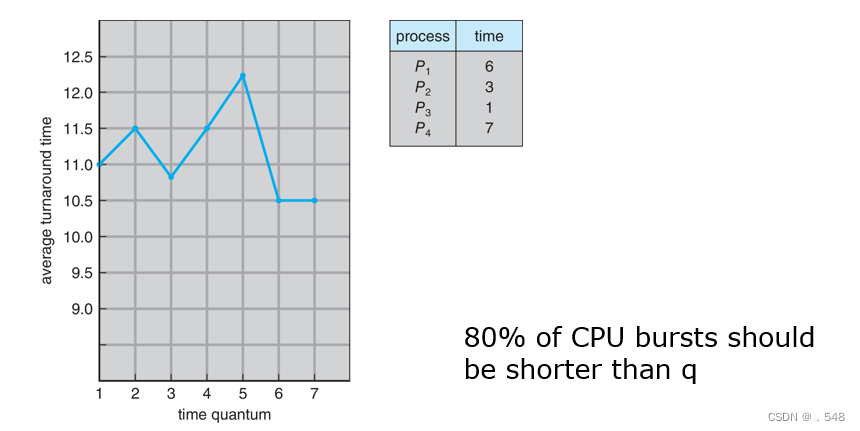
Round Robin (RR)
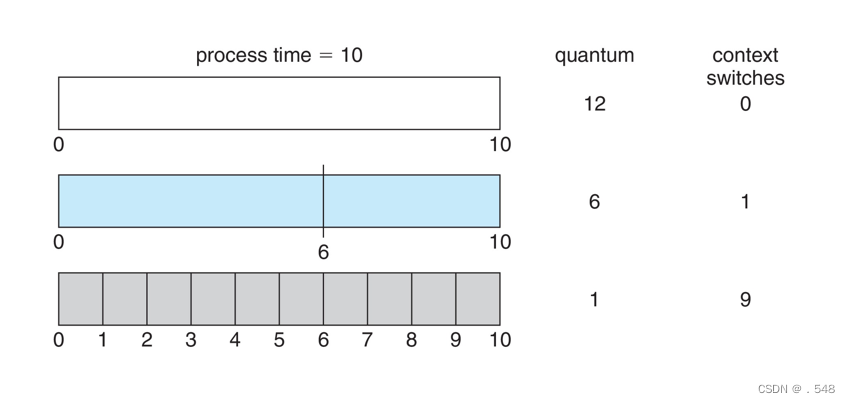
- Each process gets a small unit of CPU time (time quantum q), usually 10-100 milliseconds. After this time has elapsed, the process is preempted and added to the end of the ready queue.
- If there are n processes in the ready queue and the time quantum is q, then each process gets 1/n of the CPU time in chunks of at most q time units at once. No process waits more than (n-1)q time units.
- Timer interrupts every quantum to schedule next process
- Performance
- q large Þ FIFO (FCFS)
- q small Þ RR
- Note that q must be large with respect to context switch, otherwise overhead is too high
每个进程获得一个小单位的 CPU 时间(时间量子 q),通常为 10-100 毫秒。 过了这段时间后,进程就会被抢占并加入就绪队列的末尾。
如果就绪队列中有 n 个进程,而时间量子为 q,那么每个进程都会一次性获得 1/n 的 CPU 时间,每块最多 q 个时间单位。 没有进程的等待时间超过 (n-1)q 个时间单位。
计时器每隔一个量子中断一次,以安排下一个进程
q小FIFO q大RR
注意,相对于上下文切换,q 必须很大,否则开销太大
Example of RR with Time Quantum = 4

Priority Scheduling
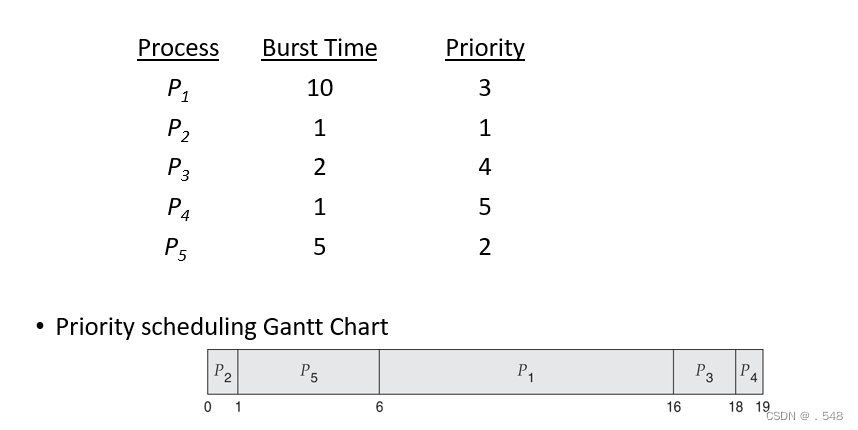
- A priority number (integer) is associated with each process
- The CPU is allocated to the process with the highest priority (smallest integer º highest priority)
- Preemptive
- Nonpreemptive
- SJF is priority scheduling where priority is the inverse of predicted next CPU burst time
- Problem º Starvation – low priority processes may never execute
- Solution º Aging – as time progresses increase the priority of the process
每个进程都有一个优先级编号(整数
CPU 分配给优先级最高的进程(最小整数 =最高优先级)
抢占式 非抢占式
SJF(最短作业优先)调度算法可以被视为一种特殊的优先级调度算法,优先级的分配是基于预测的CPU突发时间(即进程下一次需要CPU的时间长度)预测的CPU突发时间越短,进程的优先级就越高,这样它就越有可能被调度器选中执行。
问题 饥饿--低优先级进程可能永远不会执行
解决方案 老化--随着时间的推移提高进程的优先级
Priority Scheduling w/ Round-Robin

Scheduling Criteria
- CPU utilization – keep the CPU as busy as possible
- Throughput – # of processes that complete their execution per time unit
- Turnaround time – amount of time to execute a particular process
- Waiting time – amount of time a process has been waiting in the ready queue
- Response time – amount of time it takes from when a request was submitted until the first response is produced.
CPU 利用率 - 尽可能保持 CPU 的繁忙状态
吞吐量 - 每个时间单位内完成执行的进程数量
周转时间 - 执行特定进程所需的时间
等待时间 - 进程在就绪队列中等待的时间
响应时间 - 从提交请求到产生第一个响应所需的时间。
memory management
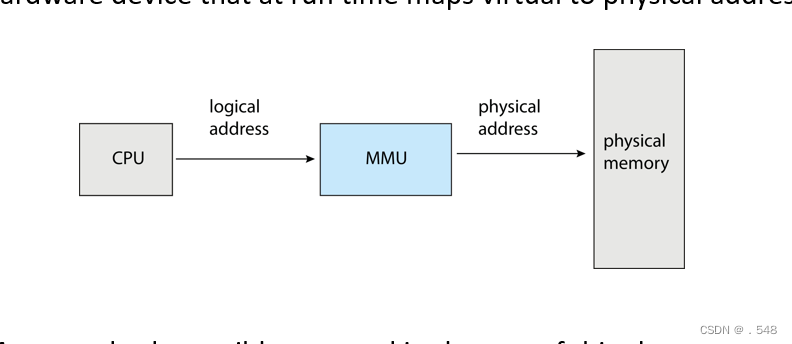
Memory-Management Unit (MMU)
- Hardware device that at run time maps virtual to physical address
- Many methods possible, covered in the rest of this chapter
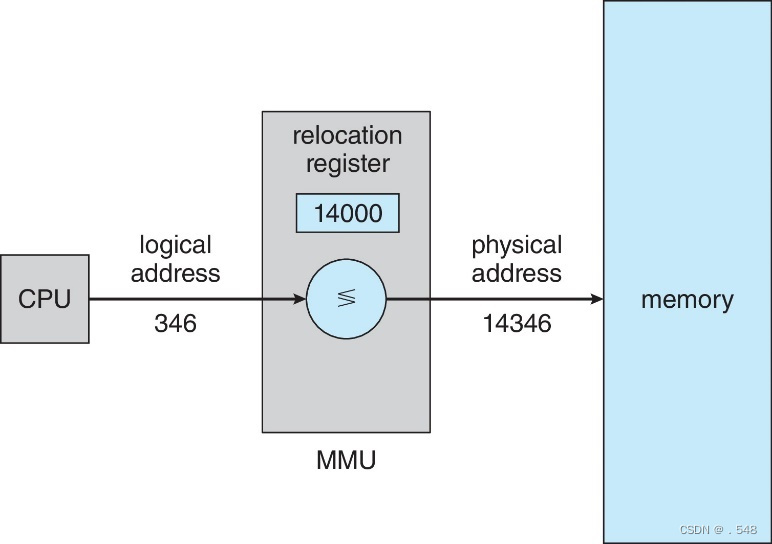
- Consider simple scheme. which is a generalization of the base-register scheme.
- The base register now called relocation register
- The value in the relocation register is added to every address generated by a user process at the time it is sent to memory
- The user program deals with logical addresses; it never sees the real physical addresses
- Execution-time binding occurs when reference is made to location in memory
- Logical address bound to physical addresses
考虑简单的方案,它是基寄存器方案的一般化。
基寄存器现在称为重定位寄存器
重新定位寄存器中的值在用户进程生成的每个地址被发送到内存时都会被加上
用户程序处理的是逻辑地址,从未见过真正的物理地址
当引用内存中的位置时,就会发生执行时绑定
逻辑地址绑定到物理地址
- Consider simple scheme. which is a generalization of the base-register scheme.
- The base register now called relocation register
- The value in the relocation register is added to every address generated by a user process at the time it is sent to memory
基寄存器现在称为重定位寄存器
用户进程生成的每个地址在发送到内存时,都会加上重定位寄存器中的值
Paging
- Physical address space of a process can be noncontiguous; process is allocated physical memory whenever the latter is available
- Avoids external fragmentation
- Avoids problem of varying sized memory chunks
- Divide physical memory into fixed-sized blocks called frames
- Size is power of 2, between 512 bytes and 16 Mbytes
- Divide logical memory into blocks of same size called pages
- Keep track of all free frames
- To run a program of size N pages, need to find N free frames and load program
- Set up a page table to translate logical to physical addresses
- Backing store likewise split into pages
进程的物理地址空间可以是非连续的;只要有物理内存,就会为进程分配物理内存
避免外部碎片
避免内存块大小不一的问题
将物理内存划分为固定大小的块,称为帧
大小为 2 的幂次,介于 512 字节和 16 兆字节之间
将逻辑内存划分为相同大小的块,称为页
跟踪所有空闲帧
要运行大小为 N 页的程序,需要找到 N 个空闲帧并加载程序
建立页表,将逻辑地址转换为物理地址
后备存储同样分为页
Address Translation Scheme
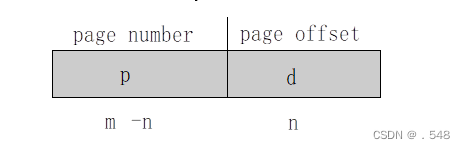
- Address generated by CPU is divided into:
- Page number (p) – used as an index into a page table which contains base address of each page in physical memory
- Page offset (d) – combined with base address to define the physical memory address that is sent to the memory unit
CPU 生成的地址分为
页码 (p) - 用作页表的索引,页表中包含物理内存中每个页的基地址
页偏移 (d) - 与基地址相结合,定义发送到内存单元的物理内存地址
-
- For given logical address space 2m and page size 2n
Paging Hardware
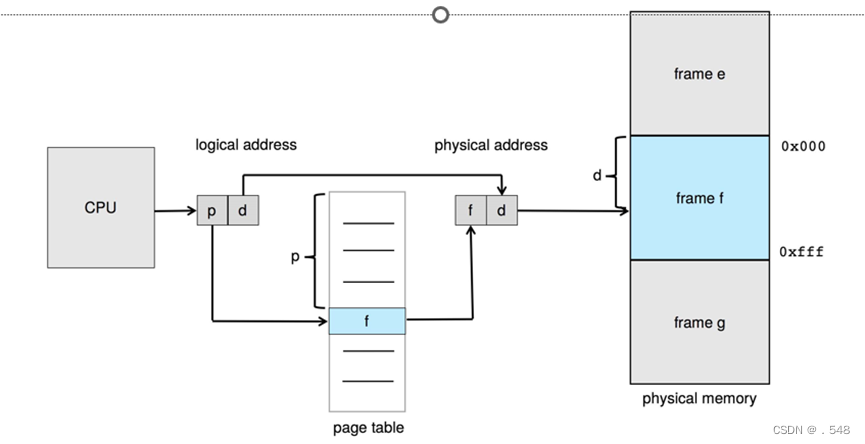
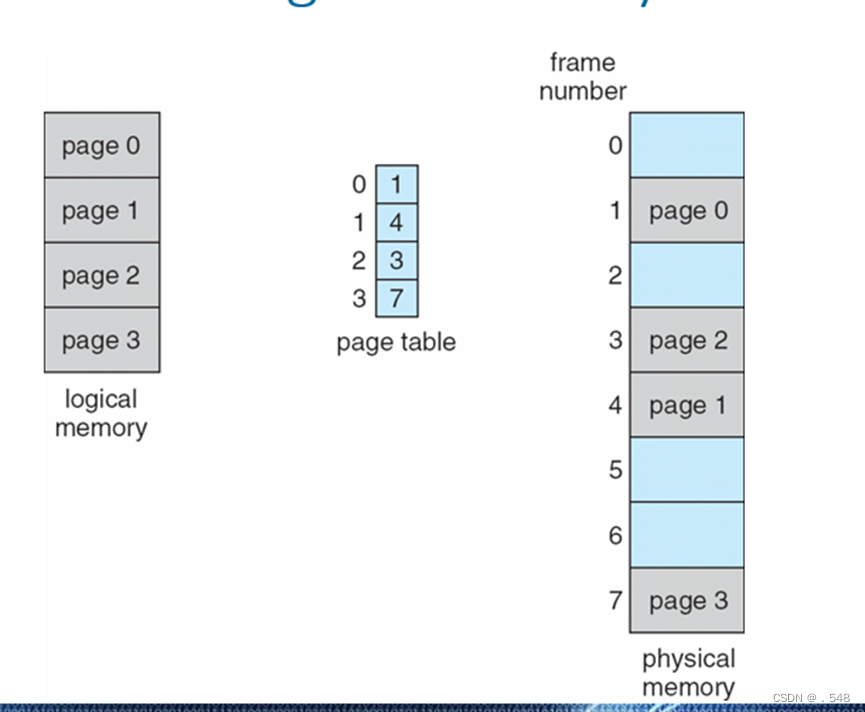
- Logical address: n = 2 and m = 4. Using a page size of 4 bytes and a physical memory of 32 bytes (8 pages)
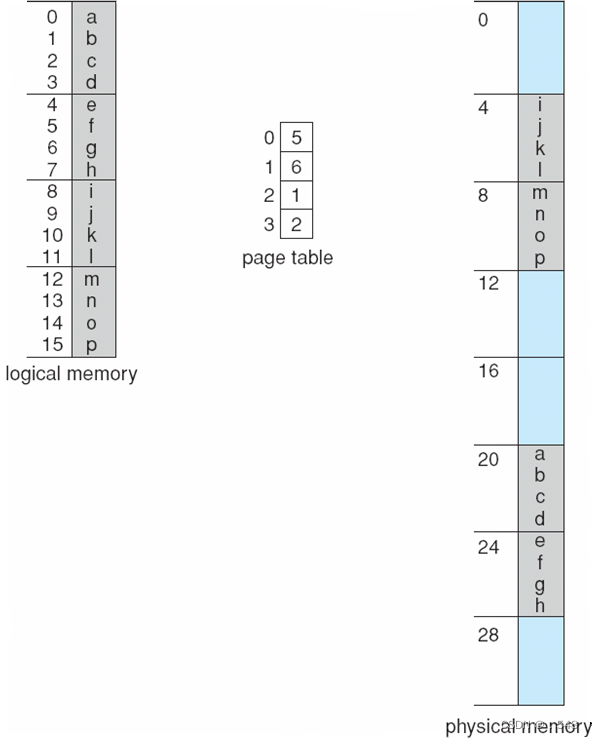
Paging -- Calculating internal fragmentation
- Page size = 2,048 bytes
- Process size = 72,766 bytes
- 35 pages + 1,086 bytes
- Internal fragmentation of 2,048 - 1,086 = 962 bytes
- Worst case fragmentation = 1 frame – 1 byte
- On average fragmentation = 1 / 2 frame size
- So small frame sizes desirable?
- But each page table entry takes memory to track
- Page sizes growing over time
- Solaris supports two page sizes – 8 KB and 4 MB
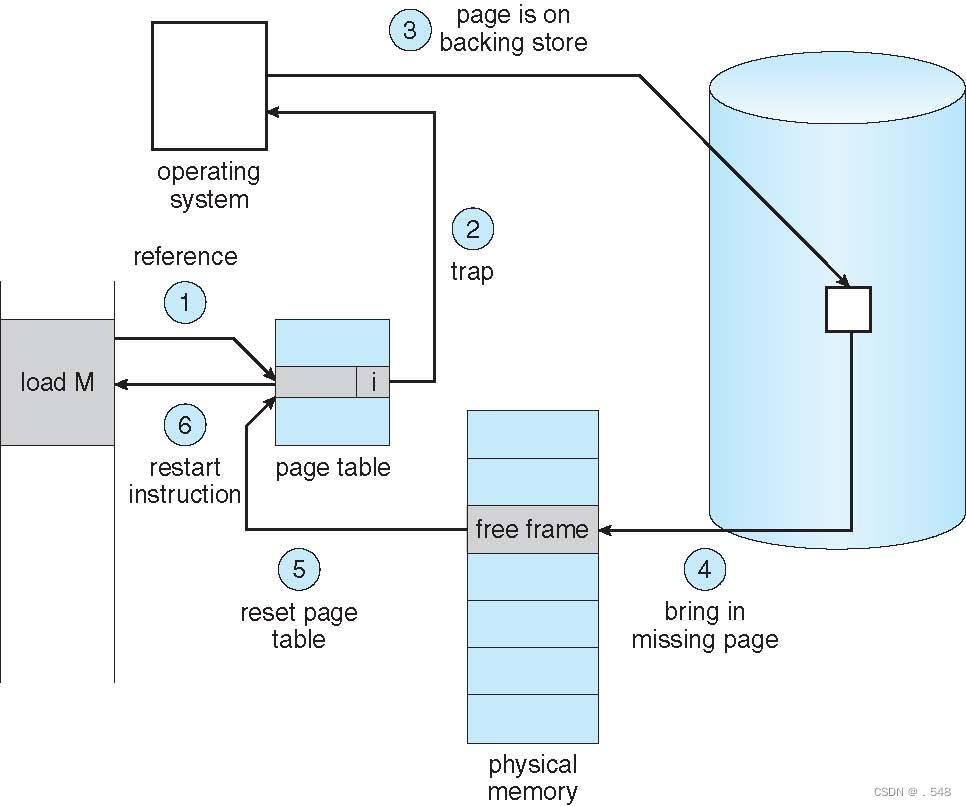
Steps in Handling Page Fault
- If there is a reference to a page, first reference to that page will trap to operating system
- Page fault
- Operating system looks at another table to decide:
- Invalid reference Þ abort
- Just not in memory
- Find free frame
- Swap page into frame via scheduled disk operation
- Reset tables to indicate page now in memory
Set validation bit = v - Restart the instruction that caused the page fault
如果存在对某个页面的引用,则对该页面的首次引用将向操作系统发出陷阱信号
页面故障
操作系统查看另一个表来决定:
无效引用 中止
只是不在内存中
查找空闲框架
通过计划的磁盘操作将页面交换到帧中
重置表以显示页面已在内存中设置验证位 = v
重启导致页面故障的指令
Page Replacement
- Prevent over-allocation of memory by modifying page-fault service routine to include page replacement
- Use modify (dirty) bit to reduce overhead of page transfers – only modified pages are written to disk
- Page replacement completes separation between logical memory and physical memory – large virtual memory can be provided on a smaller physical memory
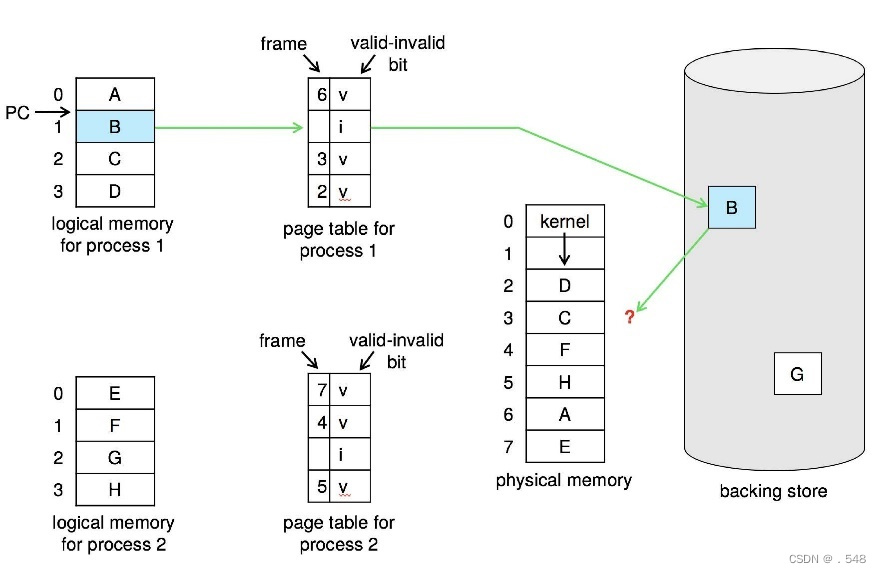
- 通过修改页面故障服务例程以包括页面替换,防止内存过度分配
- 使用修改(脏)位来减少页面传输的开销--只有修改过的页面才会写入磁盘
页面替换完成了逻辑内存和物理内存之间的分离--可以在较小的物理内存上提供较大的虚拟内存
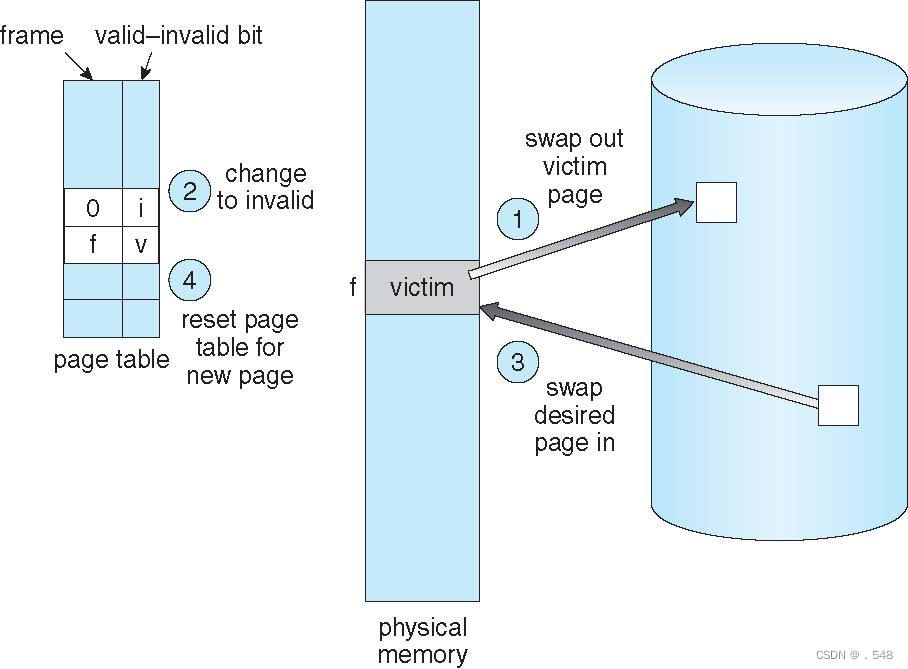
Basic Page Replacement
- Find the location of the desired page on disk
- Find a free frame:
- If there is a free frame, use it
- If there is no free frame, use a page replacement algorithm to select a victim frame
- Write victim frame to disk if dirty - Bring the desired page into the (newly) free frame; update the page and frame tables
- Continue the process by restarting the instruction that caused the trap
Note now potentially 2 page transfers for page fault – increasing EAT
Page and Frame Replacement Algorithms
- Frame-allocation algorithm determines
- How many frames to give each process
- Which frames to replace
- Page-replacement algorithm
- Want lowest page-fault rate on both first access and re-access
- Evaluate algorithm by running it on a particular string of memory references (reference string) and computing the number of page faults on that string
- String is just page numbers, not full addresses
- Repeated access to the same page does not cause a page fault
- Results depend on number of frames available
In all our examples, the reference string of referenced page numbers
帧分配算法决定
为每个进程分配多少帧 替换哪些帧
页面替换算法
希望首次访问和再次访问的页面故障率最低
在特定的内存引用字符串(引用字符串)上运行算法,并计算该字符串上的页面故障次数,以此评估算法
字符串只是页码,而不是完整地址
重复访问同一页面不会导致页面故障
结果取决于可用帧数
在我们的所有示例中,引用页码的引用字符串
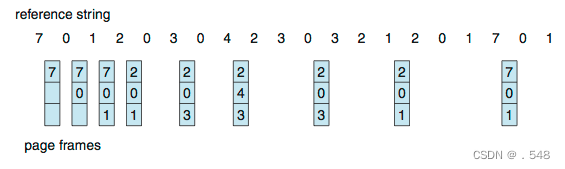
First-In-First-Out (FIFO) Algorithm
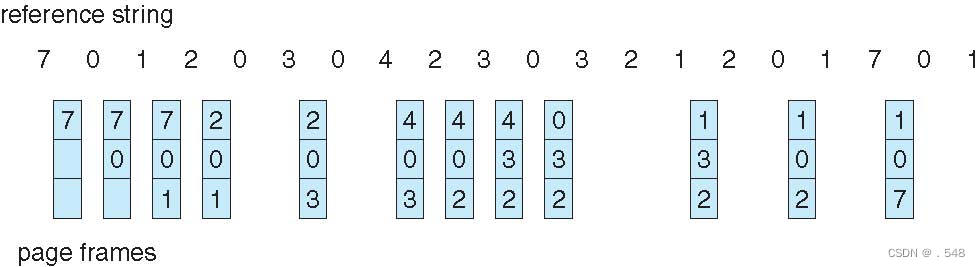
- Reference string: 7,0,1,2,0,3,0,4,2,3,0,3,0,3,2,1,2,0,1,7,0,1
- 3 frames (3 pages can be in memory at a time per process)
- page fault就是page frame发生多少次变化 每次从上往下记录,如果frame内数字已经满了,则从上往下先替换旧(指的是记录时间上的旧)的数字
- 当记录数字里面已经有了的时候,Hit跳过,

- Can vary by reference string: consider 1,2,3,4,1,2,5,1,2,3,4,5
- Adding more frames can cause more page faults!
- Belady’s Anomaly
- Adding more frames can cause more page faults!
- How to track ages of pages?
Just use a FIFO queue
Optimal Algorithm
- Replace page that will not be used for longest period of time
- 9 is optimal for the example
- How do you know this?
- Can’t read the future
Used for measuring how well your algorithm performs
替换未来最长时间内不会被使用的页
不是一个可以在实际系统中实现的实际算法。
Least Recently Used (LRU) Algorithm
- Use past knowledge rather than future
- Replace page that has not been used in the most amount of time
- Associate time of last use with each page
- 12 faults – better than FIFO but worse than OPT
- Generally good algorithm and frequently used
- 类似FIFO 有一点不同从上往下先替换旧(指的是reference string排序位置上)的数字
替换未使用时间最长的页面
将最后使用时间与每个页面相关联
12 次故障--好于先进先出,但差于 OPT
- Counter implementation
- Every page entry has a counter; every time page is referenced through this entry, copy the clock into the counter
- When a page needs to be changed, look at the counters to find smallest value
- Search through table needed
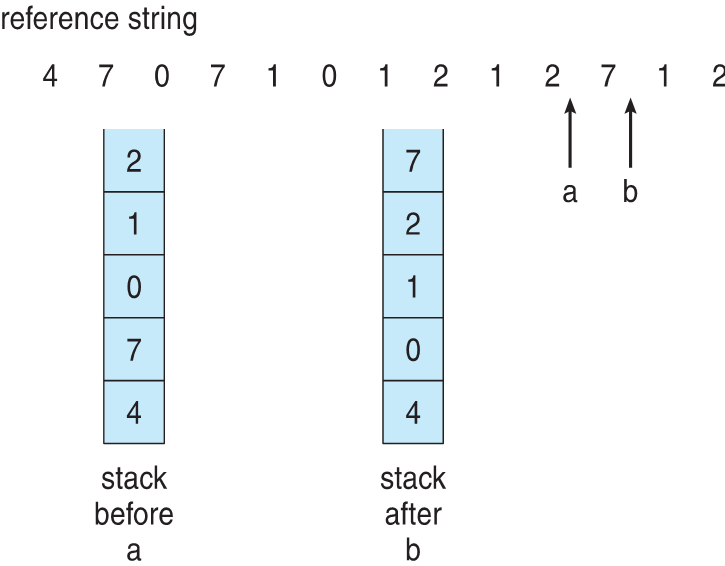
- Stack implementation
- Keep a stack of page numbers in a double link form:
- Page referenced:
- move it to the top
- requires 6 pointers to be changed
- But each update more expensive
No search for replacement
计数器的实现
每个页面条目都有一个计数器;每次通过该条目引用页面时,都会将时钟复制到计数器中
需要更改页面时,查看计数器以找到最小值 搜索所需的表格
堆栈实现
以双链接形式保存页码堆栈:页面引用:移到最上面 需要更改 6 个指针
但每次更新成本更高
无法搜索替换
- LRU and OPT are cases of stack algorithms that don’t have Belady’s Anomaly
- Use Of A Stack to Record Most Recent Page References
LRU Approximation Algorithms
- LRU needs special hardware and still slow
- Reference bit
- With each page associate a bit, initially = 0
- When page is referenced bit set to 1
- Replace any with reference bit = 0 (if one exists)
- We do not know the order, however
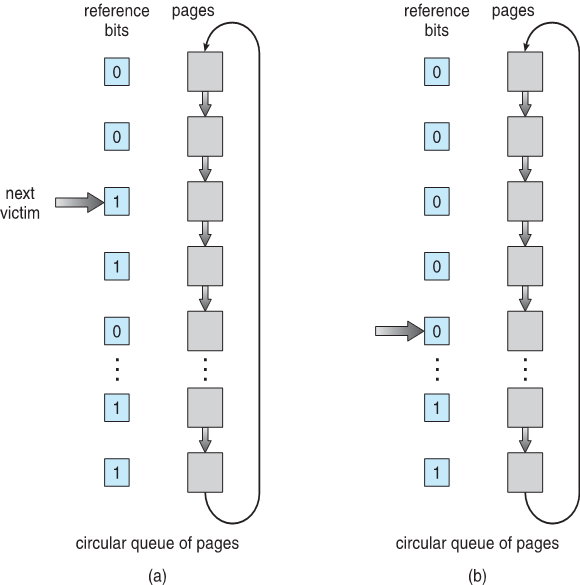
- Second-chance algorithm
- Generally FIFO, plus hardware-provided reference bit
- Clock replacement
- If page to be replaced has
- Reference bit = 0 -> replace it
- reference bit = 1 then:
- set reference bit 0, leave page in memory
- replace next page, subject to same rules
LRU 需要特殊硬件,速度仍然很慢
参考位
每个页面关联一个位,初始值 = 0
当页面被引用时,位设置为 1
替换任何参考位 = 0 的页面(如果存在的话)
但我们不知道顺序
二次机会算法
一般为 FIFO,加上硬件提供的参考位
时钟替换
如果要替换的页面有
参考位 = 0 -> 替换
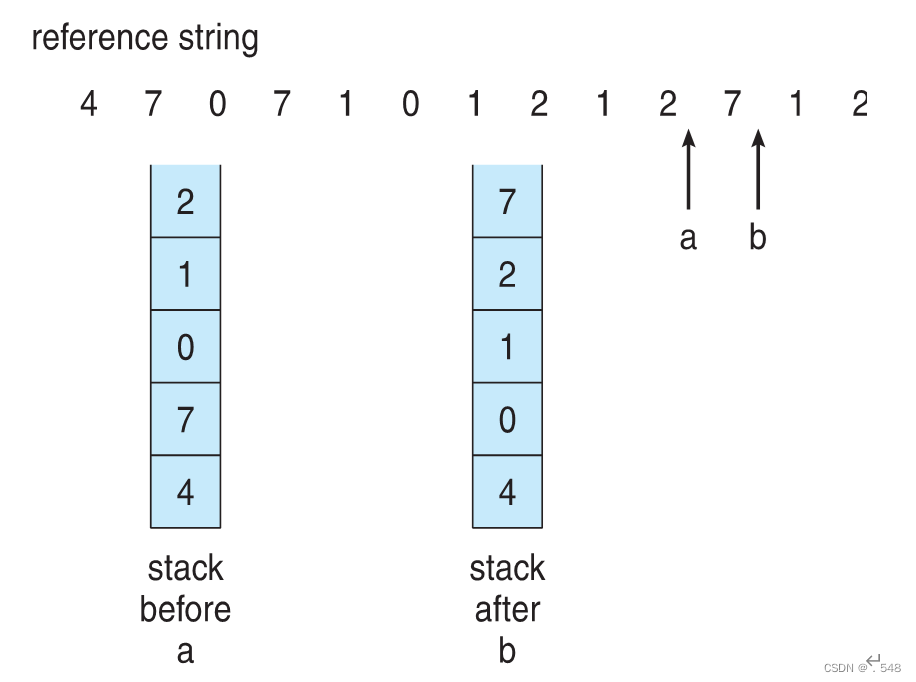
- LRU and OPT are cases of stack algorithms that don’t have Belady’s Anomaly
- Use Of A Stack to Record Most Recent Page References
LRU Approximation Algorithms
- LRU needs special hardware and still slow
- Reference bit
- With each page associate a bit, initially = 0
- When page is referenced bit set to 1
- Replace any with reference bit = 0 (if one exists)
- We do not know the order, however
- Second-chance algorithm
- Generally FIFO, plus hardware-provided reference bit
- Clock replacement
- If page to be replaced has
- Reference bit = 0 -> replace it
- reference bit = 1 then:
- set reference bit 0, leave page in memory
- replace next page, subject to same rules
LRU 需要特殊硬件,速度仍然很慢
参考位
每个页面关联一个位,初始值 = 0
当页面被引用时,位设置为 1
替换任何参考位 = 0 的页面(如果存在的话)
但我们不知道顺序
二次机会算法
一般为 FIFO,加上硬件提供的参考位
时钟替换
如果要替换的页面有
参考位 = 0 -> 替换
参考位 = 1,则
设置参考位 0,将页面保留在内存中
替换下一页,遵循相同规则
Enhanced Second-Chance Algorithm
- Improve algorithm by using reference bit and modify bit (if available) in concert
- Take ordered pair (reference, modify):
- (0, 0) neither recently used not modified – best page to replace
- (0, 1) not recently used but modified – not quite as good, must write out before replacement
- (1, 0) recently used but clean – probably will be used again soon
- (1, 1) recently used and modified – probably will be used again soon and need to write out before replacement
- When page replacement called for, use the clock scheme but use the four classes replace page in lowest non-empty class
Might need to search circular queue several times
协同使用参考位和修改位(如果有)来改进算法
取有序对(参考,修改):
(0, 0) 最近未使用也未修改 - 替换的最佳页面
(0, 1) 最近未使用但已修改--不太好,必须在替换前写出
(1,0) 最近使用过但没有修改--可能很快会再次使用
(1, 1) 最近使用过并修改过 - 可能很快会再次使用,需要在替换前写出
当需要替换页面时,使用时钟方案,但使用四个类 在最低的非空闲类中替换页面
可能需要多次搜索循环队列
Counting Algorithms
- Keep a counter of the number of references that have been made to each page
- Not common
- Lease Frequently Used (LFU) Algorithm:
- Replaces page with smallest count
- Most Frequently Used (MFU) Algorithm:
- Based on the argument that the page with the smallest count was probably just brought in and has yet to be used
记录每页被引用的次数 不常用
租赁常用 (LFU) 算法:替换计数最小的页面
最常使用 (MFU) 算法: 基于这样一个论点,即计数最小的页面可能刚刚被引入,尚未被使用
Page-Buffering Algorithms
- Keep a pool of free frames, always
- Then frame available when needed, not found at fault time
- Read page into free frame and select victim to evict and add to free pool
- When convenient, evict victim
- Possibly, keep list of modified pages
- When backing store otherwise idle, write pages there and set to non-dirty
- Possibly, keep free frame contents intact and note what is in them
- If referenced again before reused, no need to load contents again from disk
- Generally useful to reduce penalty if wrong victim frame selected
始终保持一个空闲帧池
然后在需要时提供框架,而不是在故障发生时找到框架
将页面读入空闲帧,然后选择受害者,将其驱逐并添加到空闲帧池中
方便时,驱逐受害者
可能的话,保留已修改页面的列表
当备用存储空闲时,将页面写入备用存储,并设置为非脏页面
可能的话,保持空闲帧内容不变,并记录其中的内容
如果在重复使用前再次引用,则无需再次从磁盘加载内容
如果选择了错误的受害帧,一般有助于减少处罚