一、什么是昇思MindSpore?
昇思MindSpore是一个全场景深度学习框架,详见基本介绍
那什么是深度学习呢?
深度学习是一种特殊的机器学习,主要是利用了多层神经网络模拟人脑,自动提取特征并进行预测。
什么是机器学习?
通过给“机器”喂养一些数据和答案,让其学习并训练处一套规则,新的数据可以通过这个规则,得出答案,这也是现在风靡全球的AI大模型的基本原理。
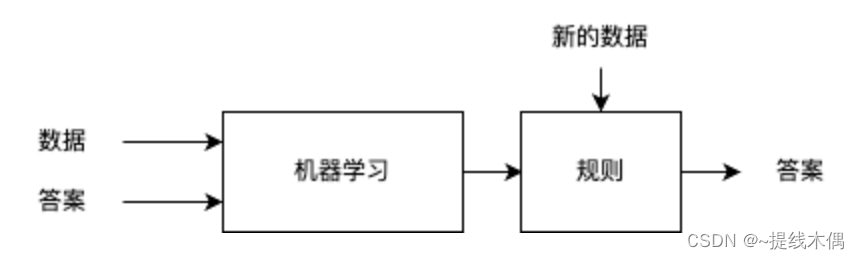
下图为现在已经发展成熟的完整流程

二、快速入门
1.准备工作
1.1环境准备
MindSpore提供基于Pipeline的数据引擎,通过数据集(Dataset)和数据变换(Transforms)实现高效的数据预处理。
预装mindspore(2.2.14)、numpy、pandas等依赖
%%capture captured_output
# 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
!pip uninstall mindspore -y
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
1.2数据变换Transforms导入
import mindspore
from mindspore import nn
from mindspore.dataset import vision, transforms # 使用mindspore.dataset提供的数据变换进行预处理
from mindspore.dataset import MnistDataset
1.3导入Mnist数据集
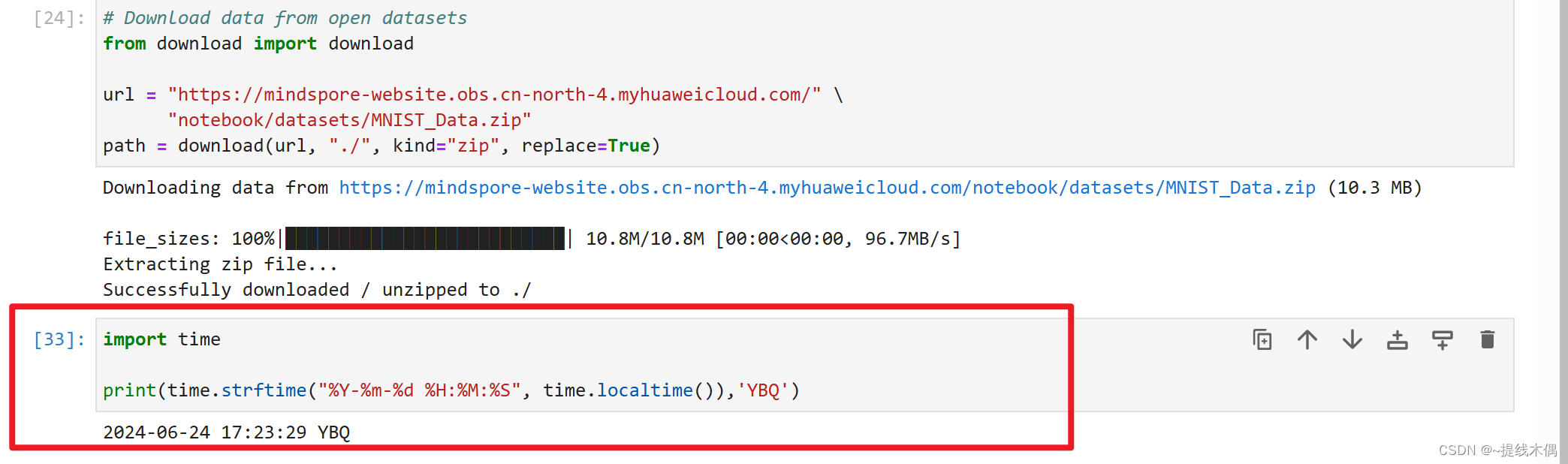
# Download data from open datasets
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)
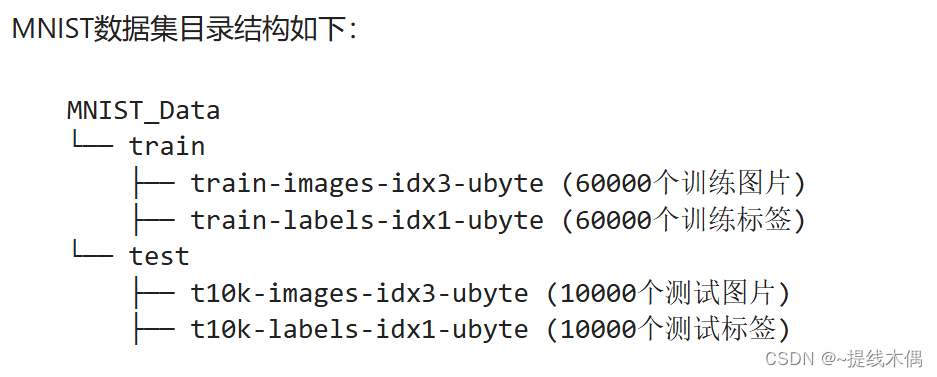
1.4使用(查看)数据集
1.4.1获得数据集对象
可以看到下面两个对象,分别为MNIST数据集train分支和test分支下的数据对象,获取到数据对象后,我们来查看一下这些数据的value等信息
train_dataset = MnistDataset('MNIST_Data/train')
test_dataset = MnistDataset('MNIST_Data/test')
1.4.2打印数据集中包含的数据列名
通过运行下面的代码,查看运行结果,结合上面的MNIST数据集train分支和test分支下的子分支,可以很直观的看出,数据集包含图片和标签
print(train_dataset.get_col_names())
print(test_dataset.get_col_names())
运行结果:
['image', 'label']
['image', 'label']
1.4.3对图像数据及标签进行变换处理
请看代码中的注释理解这段代码的作用
# 自定义一个函数 接受一个数据集(dataset)和批量大小(batch_size)作为输入,并返回经过一系列预处理和变换后的数据集
def datapipe(dataset, batch_size):
# 定义一个包含了三个图像处理变换(transforms)的列表image_transforms 将这些变换组合在一起,可以对图像进行一系列预处理操作,以便将其输入到深度学习模型中
image_transforms = [
vision.Rescale(1.0 / 255.0, 0),# 用于将图像的像素值从 [0, 255] 缩放到 [0, 1]
vision.Normalize(mean=(0.1307,), std=(0.3081,)), # 用于标准化图像数据
vision.HWC2CHW() # 用于改变图像的维度顺序
]
#将标签数据转换为 mindspore.int32 类型
label_transform = transforms.TypeCast(mindspore.int32) #transforms为mindspore.dataset提供的数据变换
# 使用上面定义的图像变换和标签变换,通过map方法作用到图像和标签数据集
dataset = dataset.map(image_transforms, 'image')
dataset = dataset.map(label_transform, 'label')
# 将经过变换的数据集按照 batch_size 参数指定的大小进行批处理
dataset = dataset.batch(batch_size)
# 返回经过处理后的数据集
return dataset
1.4.4使用自定义的变换处理
调用上面的自定义函数datapipe(dataset, batch_size),并传入参数
此处我们设置一个对照组,只处理train_dataset分支下的数据,比较处理前后数据集的shape和datatype有何不同
# Map vision transforms and batch dataset
train_dataset = datapipe(train_dataset, 64)
# test_dataset = datapipe(test_dataset, 64)
使用create_tuple_iterator 或create_dict_iterator对数据集进行迭代访问,查看数据和标签的shape和datatype
可以清晰的看到,经过变换处理后图片和标签数据的shape和datatype都发生了变化
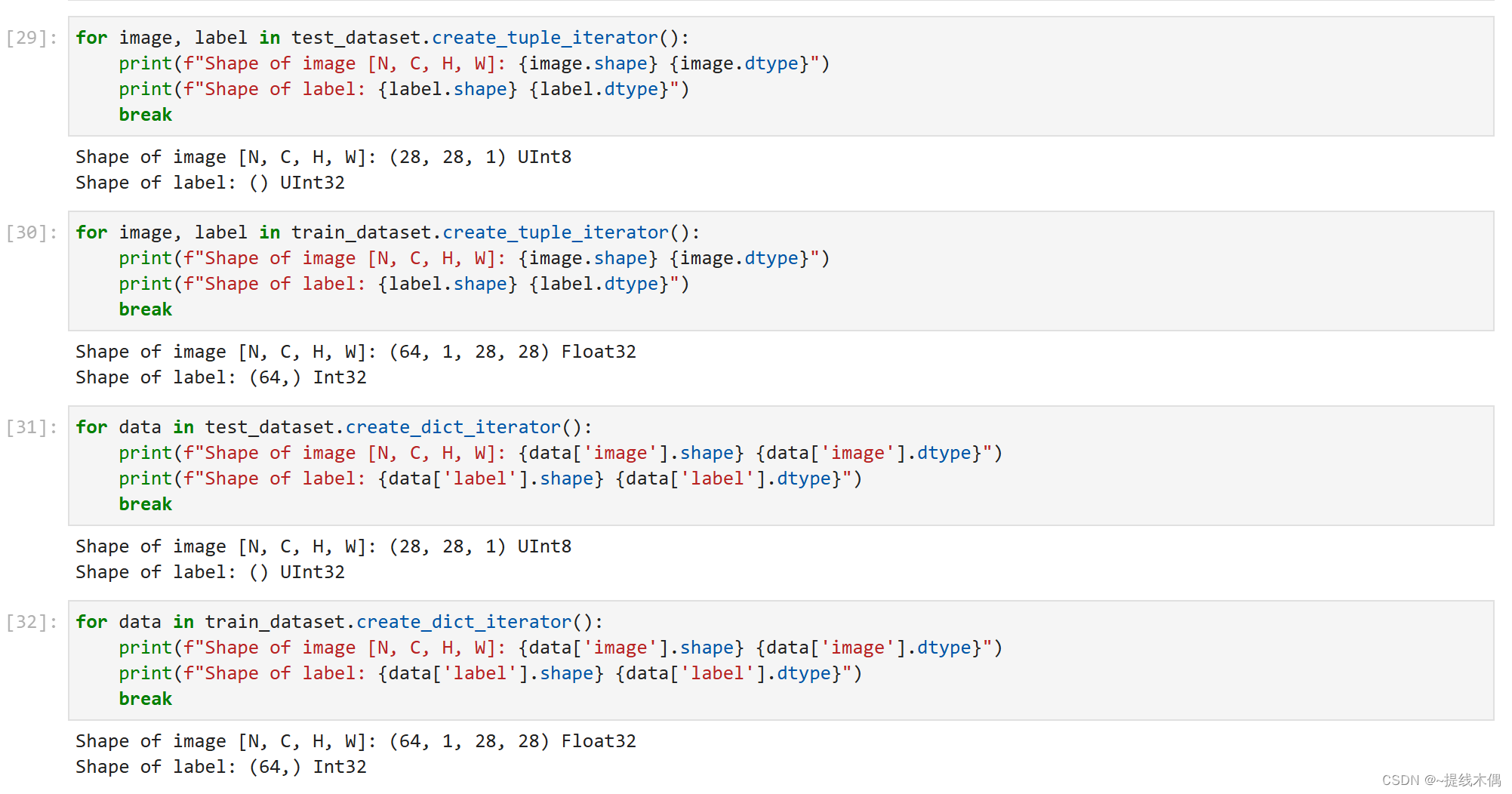
数据已经准备好了,明天继续网络构建!