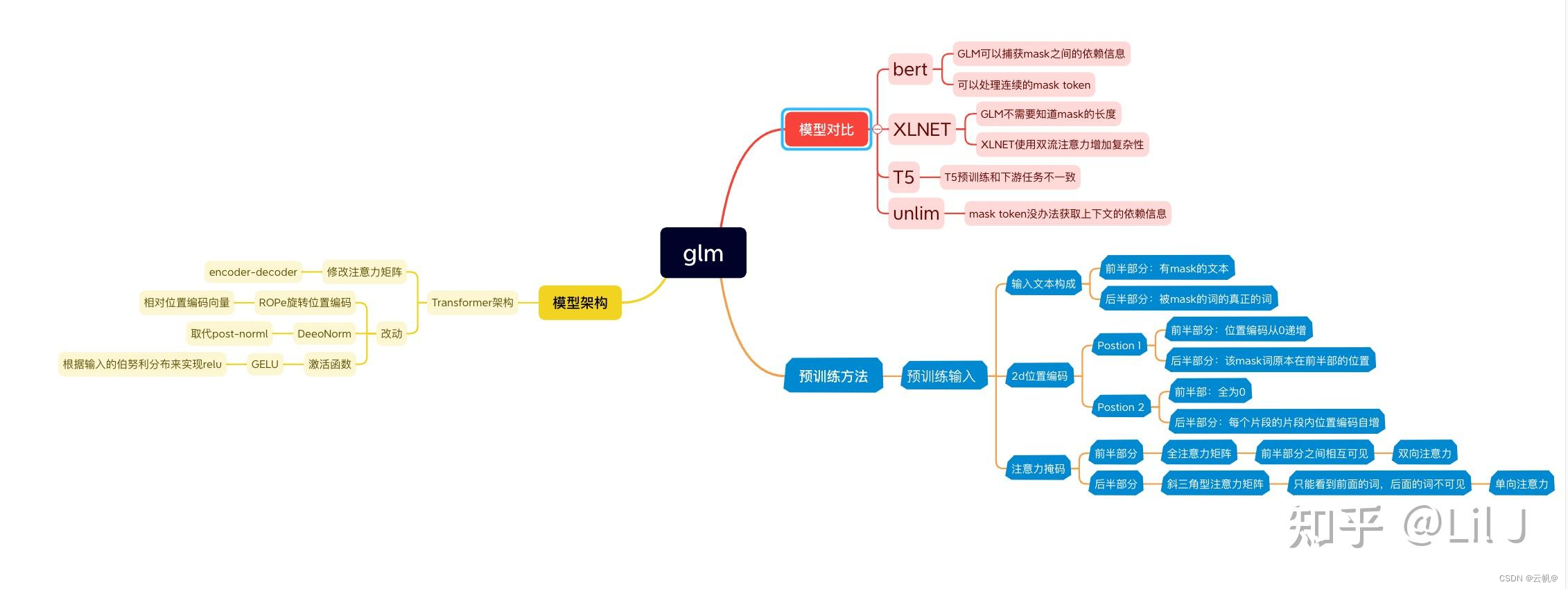
一、目录
- chatglm 是什么语言模型与transformer decoder 的区别
- 解释prefix LM与Cause LM
- chatglm(prefix LM)与decoder-only LM 核心区别
- glm 架构
- chatglm 预训练方式
- chatglm 微调
- chatglm与chatglm2、chatglm3的区别
- chatglm 激活函数采用gelu, 为什么chatglm2 采用swish 激活函数?
- prefixLm 与decoder-only LM的优缺点?
10 glm4 与chatglm3 的区别?
二、实现
- chatglm 是什么语言模型与transformer decoder 的区别
1. GLM 预训练方式:自回归的空白填充,并通过 GLM 通过添加 2D 位置编码和打乱片段顺序来改进空白填充预训练。
2. chatglm 为前缀语言模型(自回归空白填充的通用语言模型(GLM),prefix-LM。结构为:Prefix-LM中前半段深黑色的连线为双向语言模型的标准架构,而在后半段通过
mask attetnion矩阵使其成为递归生成的单向语言模型。
3. 模型架构为prefix decoder-only 模型架构,在输入上采用双向的注意力机制,在输出上采用单向注意力机制。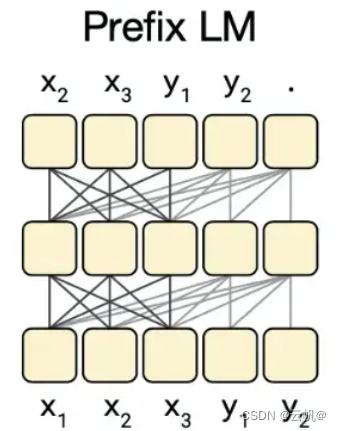
注意力为前缀注意力, 如输入x1 -x5, 第一时刻输出y1时,实际输入信息为x1-x3,第二第三时刻输出y2,y3 ,实际输入信息为x1-x3。第四时刻输出y4时,输入信息为x1-x4。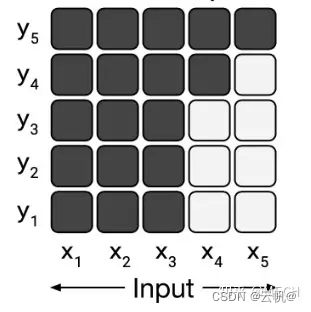
- decoder-only 架构,也称Cause架构。
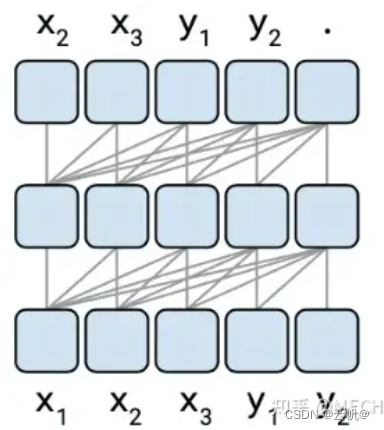
该类模型全程都是单向语言信息传输,其做法也是将attention后向信息部分mask掉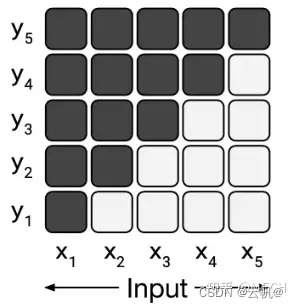
2 解释prefix LM与Cause LM
prefix LM,前缀语言模型,在输入序列的开头添加一个可学习的任务相关的前缀,然后使用该前缀和输入序列一起生成输出。用于一道模型生成适应特定任务的输出。
causal LM,因果语言模型,也成为自回归语言模型,根据之前生成的token预测下一个token,在生成文本时,模型只能根据已经生成的部分生成后续部分,不能访问未来的信息。
3. chatglm(prefix LM)与decoder-only LM 核心区别
核心区别:多头注意力mask 不同。 prefix LM 有前缀。 cause LM 没有前缀。
-
glm 架构
GLM使用Transformer,并对其架构进行了一些修改:
(1)重新安排了层归一化和残差连接的顺序 (将Post-LN改成Pre-LN),这对于大规模语言模型避免数值误差至关重要;
(2)使用单个线性层进行输出token预测;
(3)用GeLUs替换ReLU激活函数。 -
chatglm 预训练方式
GLM(General Language Model)提出了一种新的训练架构,旨在吸收自回归和自编码两种方法的优势。主要思想是用生成式预测的方式来完形填空。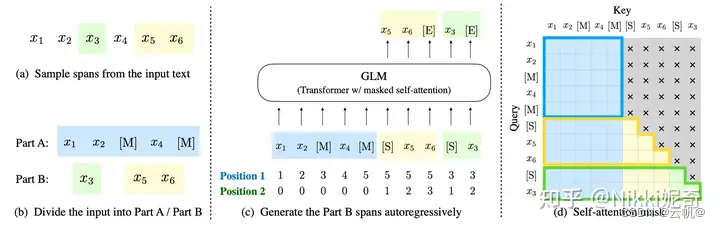
如图3所示,前面掩码,后面预测。(自回归填充)
输入文本构成: 前半部分:有mask的文本,后半部分:被mask的词的真正预测。
长文本生成具体包含以下两个目标:
sentence-level (句子级):从文档中随机掩码若干文本片段,每个文本片段必须为完整的句子,被掩码的词数量为整个文档长度的15%。这一目标是能针对seq2seq任务,其预测往往是完整的整个句子或者段落。
document-level (文档级):采样一个长度从原始文本长度的50%到100%的均匀分布中采样的片段。这预训练目标针对的是无条件的长文本生成。 -
chatglm 微调
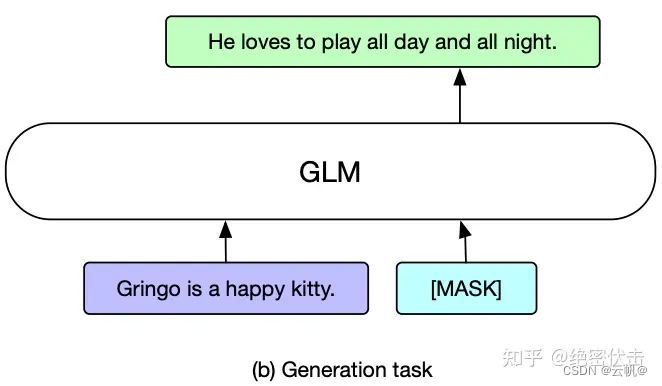
对于文本生成任务,给定的上下文构成了输入的 Part A,末尾附加了一个 mask 符号。模型自回归地生成 Part B 的文本。可以直接应用预训练的 GLM 进行无条件的生成,或者在下游的条件生成任务上对其进行微调。 -
chatglm与chatglm2、chatglm3的区别
- chatglm 与chatglm2、chatglm3不同,chatglm2与chatglm3 架构相同。
在 chatglm版本中,attention mask 分为两部分:Part A 和 Part B。Part A 部分是双向 Attention,Part B 部分是 Causal Attention。但在chatglm2 版本中,我们全部换成了 Causal Attention,不再区分是 Part A 还是 Part B,完全变成了 decoder-only 的架构。 - chatglm2改进点:1. 词表大小从15万528 缩小为6万5024 。
- 位置编码从每个模块编码升级为全局一份。
- 标准化有LayerNorm 改为RMSNorm。 采用FlashAttention, 长度2k -->32k,对话支持8k 数据。
- chatglm2 效果比chatglm 评分高,chatglm3 反而降低一些。
chatglm–>chatglm2: 改进点:
1. 训练数据: 1T -->1.4T
词表缩小:150528–>65024
2. 模型算子改进:
更强大的性能:基于 ChatGLM 初代模型的开发经验,我们全面升级了 ChatGLM2-6B 的基座模型(Prefix-LM->Decoder-Only)。
更长的上下文:基于 FlashAttention 技术,我们将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。
更高效的推理:基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
layerNorm—>RMSNorm
chatglm2–>chatglm3:改进点:
全新设计的 Prompt 格式
一些工具的开发。
训练数据更丰富。
- chatglm 与chatglm2、chatglm3不同,chatglm2与chatglm3 架构相同。
-
chatglm 激活函数采用gelu, 为什么chatglm2 采用swish 激活函数?
使用Swish作为GLU块的激活函数可以增强模型的非线性能力,并在某些情况下提供更好的性能和更快的收敛速度。 -
prefixLm 与decoder-only LM的优缺点?
prefixLM 是Encoder-Decoder模型的一个变型,在标准的encoder-decoder 中,encoder和decoder 各自使用一个独立的transformer。
而在PrefixLM中,Encoder和Decoder则共享了同一个Transformer结构,在Transformer内部通过Attention Mask机制来实现 。如图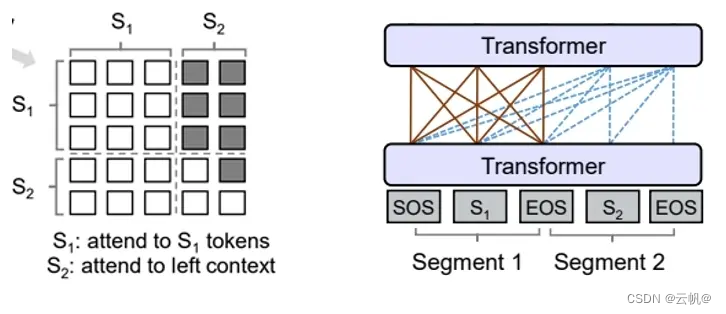
decoder -only 采用自回归模式,就是根据历史的token来预测下一个token,也是在Attention Mask这里做的手脚。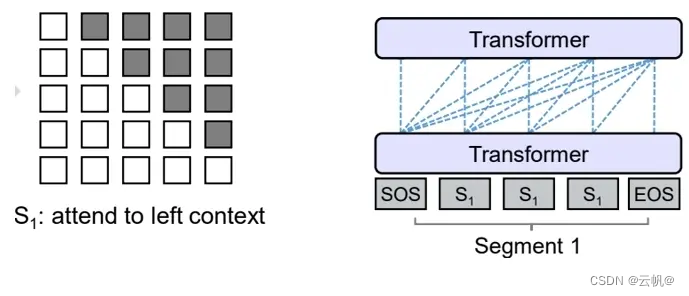
在多轮对话中,PrefixLM 会带来数据膨胀问题,影响模型训练效率。
在处理多轮对话的过程中,设有3轮对话,Q1A1,Q2A2,Q3A3,PrefixLM需要构建三条样本:
Q1->A1
Q1A1Q2->A2
Q1A1Q2A2Q3->A3
而这种数据构建方式带来了严重的数据膨胀问题,影响模型训练的效率。
Decoder-Only模型则可以利用Causal Mask的特性(每一个Token可以看到前面所有Token的真实输入),在一条样本中实现多轮对话:
样本构建:Q1 A1 Q2 A2 Q3 A3
Loss计算:只需要计算 A1 A2 和 A3 部分 -
glm4 与chatglm3 的区别?
待续