最近由于需要图像文字识别的简单业务,研究了一下,一是用大厂的文字识别api,如百度腾讯等,但这种免费版只有有限的调用次数,如百度只有每月只有1000次调用额度,个人也够用,但由于业务量大,所以再看看其他本地识别的模型,现在做的比较完善的就是paddleocr,于是开始了一段折磨之旅
paddleocr官方github:GitHub - PaddlePaddle/PaddleOCR: Awesome multilingual OCR toolkits based on PaddlePaddle (practical ultra lightweight OCR system, support 80+ languages recognition, provide data annotation and synthesis tools, support training and deployment among server, mobile, embedded and IoT devices)![]() https://github.com/PaddlePaddle/PaddleOCR我的安装在云服务器win10 server2022版,在此之前已经安装了python3.12.3,所以只需要安装paddleocr即可
https://github.com/PaddlePaddle/PaddleOCR我的安装在云服务器win10 server2022版,在此之前已经安装了python3.12.3,所以只需要安装paddleocr即可
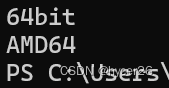
在此之前,先确认cpu架构是否是64位,执行下面python指令
python -c "import platform;print(platform.architecture()[0]);print(platform.machine())"输出为如下,第一行输出的是”64bit”,第二行输出的是”x86_64”、”x64”或”AMD64”即可:
1. 我们打开上面的网址,找到文档教程-》快速开始,点进来之后,下拉有个安装步骤,看起来挺简单的,两步就行
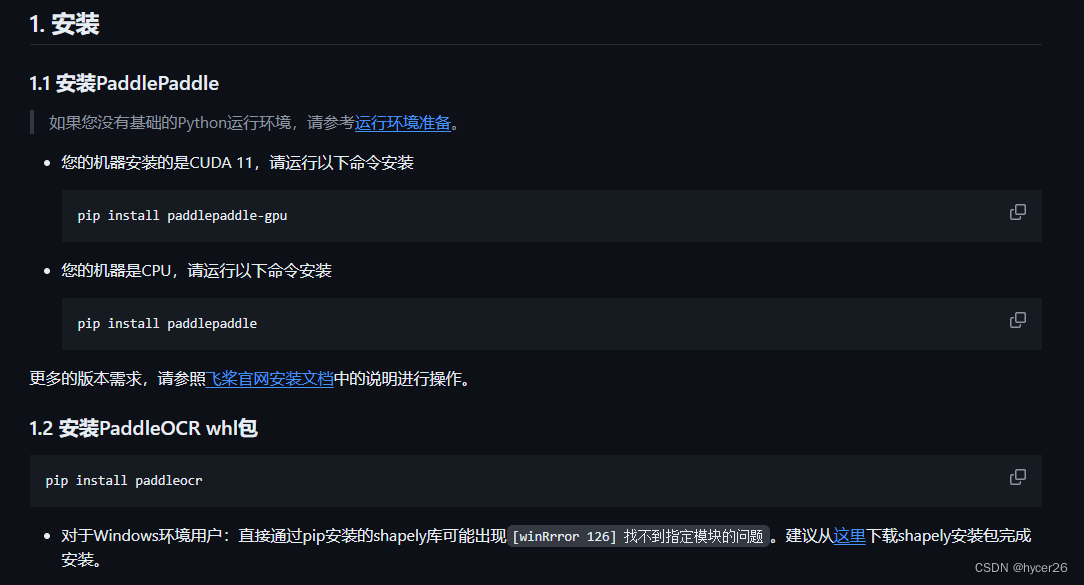
先说明安装paddleocr之前必须先安装paddlepaddle(飞浆)框架,它是百度研发的深度学习框架,我们只需要成功安装它,之后只会用到paddlerocr,你可以理解paddlerocr是paddlepaddle的子集,是通过模型训练出来的针对图像文字识别的开源库,也说明paddleocr依赖于paddlepaddle。如下官网:
paddlepaddle官网:飞桨PaddlePaddle-源于产业实践的开源深度学习平台飞桨致力于让深度学习技术的创新与应用更简单。具有以下特点:同时支持动态图和静态图,兼顾灵活性和效率;精选应用效果最佳算法模型并提供官方支持;真正源于产业实践,提供业界最强的超大规模并行深度学习能力;推理引擎一体化设计,提供训练到多端推理的无缝对接;唯一提供系统化技术服务与支持的深度学习平台![]() https://www.paddlepaddle.org.cn根据上面的安装教程,由于我的服务器没有英伟达显卡,所以我装cpu版本的paddlepaddle一切顺利,再安装paddleocr第一次报错
https://www.paddlepaddle.org.cn根据上面的安装教程,由于我的服务器没有英伟达显卡,所以我装cpu版本的paddlepaddle一切顺利,再安装paddleocr第一次报错
ModuleNotFoundError: No module named 'patch_ng'
它的意思是找不到patch_ng的模块,网上有个教程是手动安装patch_ng,我试了再安装paddleocr还是报一样的错
pip install patch_ng接着我又找到一个说法是python3.12会有问题,可以安装python3.9解决,于是我将3.12卸载,并把安装目录删除,本身我不太想装太老的python版本,我就从3.11开始往下试(由于我并没有在安装时记录每一步安装和报错截图,所以只能回忆踩坑经历)
2. 我先成功安装好3.11和paddlepaddle最新版本,再安装paddleocr后第二次报错
'libpaddle' is not defined ImportError: DLL load failed while importing libpaddle
开始我只搜了一下网上有没有解决方法,看到一个说法是:没有安装2015 Redistributable库,下载地址:Download Microsoft Visual C++ 2015 Redistributable Update 3 from Official Microsoft Download Center
我查看了一下我的电脑是已经装了的,但我还是将它卸载后重新安装,但还是报这个错,于是我认为可能是python版本不对,我将3.10/3.9都按相同的方法进行安装,(tips:卸载后一定记得把之前的安装目录删除,不然如果又安装在同一个文件夹下,会报错Could not install packages due to an OSError; [Errno 2] No such file or directory: "")
但还是报相同的'libpaddle'错,于是又在网上查询,有一个说法是paddlepaddle2.6开始有些机器会报'libpaddle'错,必须降版本,于是按照说法将paddlepaddle的版本降到了2.4
3. 安装2.4后,开始第三次报错
Your machine doesn't support AVX, but the installed PaddlePaddle is avx core
这个报错是说我的机器不支持avx,但安装的paddlepaddle版本是一个只支持avx指令集的框架,我用cpuz看了下,确实不支持,很老的cpu了
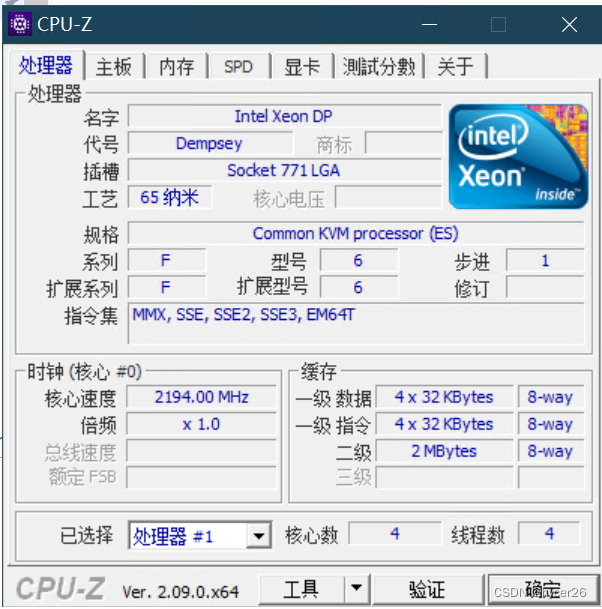
于是我在网上又搜了下解决方法,是说可以装个noavx的paddlepaddle版本,而支持的python版本最高版本也只有3.8,又开始重复步骤,卸载3.9安装3.8.10的版本python,并安装支持noavx最高版本为2.4.2的paddlepaddle
由于不支持avx指令集,只能用以下命令安装
-
cpu、mkl版本noavx机器下载paddlepaddle包:
python -m pip download paddlepaddle==2.4.2 -f https://www.paddlepaddle.org.cn/whl/windows/mkl/noavx/stable.html --no-index --no-deps -
cpu、openblas版本noavx机器下载paddlepaddle包:
python -m pip download paddlepaddle==2.4.2 -f https://www.paddlepaddle.org.cn/whl/windows/openblas/noavx/stable.html --no-index --no-deps -
最后进行安装,使用如下命令:
python -m pip install .\paddlepaddle-2.4.2-cp38-cp38-win_amd64.whl -i https://mirror.baidu.com/pypi/simple
成功安装后,命令行进行python,输入下面的代码,出现 PaddlePaddle is installed successfully!,说明安装成功
import paddle
paddle.utils.run_check()4. 感觉已经成功一半了,接下来就是安装paddleocr了,结果开始第四次报错
TypeError: Descriptors cannot be created directly.If this call came from a _pb2.py file
TypeError: Descriptors cannot be created directly.
If this call came from a _pb2.py file, your generated code is out of date and must be regenerated with protoc >= 3.19.0.
If you cannot immediately regenerate your protos, some other possible workarounds are:
1. Downgrade the protobuf package to 3.20.x or lower.
2. Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and will be much slower).
网上查了下,解决方法是降protobuf版本降级至3.20,pip安装低版本的即可
pip install protobuf==3.20 -i https://mirror.baidu.com/pypi/simple5. 再次重新安装paddleocr,开始第五次报错
name 'predict_system' is not defined
因为我安装paddleocr没有指定版本,默认是最新版2.7.5,但好像这个版本可能会出上面这个报错,解决方法是降级,我安装的是2.7.0版本,成功运行
pip install paddleocr==2.7.0.0 -i https://mirror.baidu.com/pypi/simple随便截了一张图进行测试,如下图进行ocr文字识别

代码如下:
from paddleocr import PaddleOCR, draw_ocr
ocr = PaddleOCR(use_angle_cls=True, use_gpu=False)
img_path = r'testocr.PNG'
result = ocr.ocr(img_path, cls=True)
for line in result:
print(line)输出结果:
[[[[373.0, 27.0], [552.0, 27.0], [552.0, 51.0], [373.0, 51.0]], ('示例-高精Al翻译', 0.9320504069328308)], [[[29.0, 51.0], [86.0, 51.0], [86.0, 77.0], [29.0, 77.0]], ('原文:', 0.9745678305625916)], [[[31.0, 91.0], [544.0, 90.0], [544.0, 113.0], [31.0, 114.0]], ('天下事有
难易乎?为之,则难者亦易矣;不为,则易者亦难矣', 0.9740261435508728)], [[[31.0, 140.0], [104.0, 140.0], [104.0, 165.0], [31.0, 165.0]], ('Al翻译:', 0.9500085115432739)], [[[33.0, 182.0], [536.0, 182.0], [536.0, 202.0], [33.0, 202.0]], ('Isthereanythingdifficultoreasyintheworld?Doit,', 0.9869545698165894)], [[[34.0, 212.0], [514.0, 213.0], [514.0, 234.0], [34.0, 233.0]], ('andthedifficultthingbecomeseasy;Donotdoit,', 0.9875576496124268)], [[[34.0, 245.0], [386.0, 245.0], [386.0, 265.0], [34.0, 265.0]], ('andtheeasythingbecomesdifficult.', 0.9863361120223999)], [[[471.0, 288.0], [526.0, 288.0], [526.0, 310.0], [471.0, 310.0]], ('去试试', 0.9974588751792908)]]看起来还是蛮准确的,不错
安装过程中给我一路折腾,我以为我的cpu太老可能使用不了这个本地模型,但结局是好的,初步能运行起,之后遇到其他问题再记录。