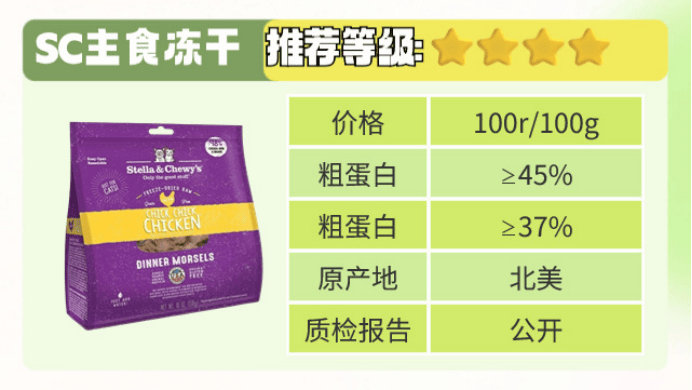
组织严重依赖数据分析和自动化来提高运营效率。在本文中,我们将使用 Python(一种用于通用编程的高级编程语言)的示例来研究数据分析和自动化的基础知识。

什么是数据分析?
数据分析是指检查、清理、转换和建模数据的过程,以便识别有用的信息、得出结论并支持决策。这是一项重要的活动,有助于将原始数据转化为可操作的见解。以下是数据分析涉及的关键步骤:
- 收集:从不同来源收集数据。
- 清理:删除或纠正收集的数据集中的不准确和不一致性。
- 转换:将收集的数据集转换为适合进一步分析的格式。
- 建模:在转换后的数据集上应用统计或机器学习模型。
- 可视化:使用合适的工具(例如 MS Excel 或 Python 的 matplotlib 库)创建图表、图形等,以直观的方式呈现调查结果。
数据自动化的重要性
数据自动化涉及使用技术来执行与处理大型数据集相关的重复性任务,并且只需极少的人工干预。自动化这些流程可以大大提高效率,从而为分析师节省时间,让他们可以更专注于复杂的任务。它的一些常见应用领域包括:
- 数据提取:自动从各种来源收集和存储数据。
- 数据清理和转换:在对收集的数据集执行建模或可视化等其他操作之前,使用脚本或工具(例如 Python Pandas 库)对其进行预处理。
- 报告生成:创建自动报告或仪表板,每当新记录到达我们的系统等时,它们就会自行更新。
- 数据集成: 将从多个来源获得的信息结合起来,以便在决策过程中进一步分析时获得整体视图。
Python 数据分析简介
Python是一种广泛用于数据分析的编程语言,因为它简单易读,并且有大量可用于统计计算的库。以下是一些简单示例,演示了如何使用 Python 读取大型数据集以及执行基本分析:

读取大型数据集
将数据集读入您的环境是任何数据分析项目的初始阶段之一。在这种情况下,我们将需要提供强大数据操作和分析工具的 Pandas 库。
Python
将pandas 导入为 pdbr
br
# 定义大数据集的文件路径br
file_path = '路径/到/large_dataset.csv'br
br
# 指定块大小(每个块的行数)br
块大小= 100000br
br
# 初始化一个空列表来存储结果br
结果= []br
br
# 分块迭代数据集br
对于 pd中的块.read_csv (file_path ,chunksize = chunk_size ): br
# 对每个块进行基本分析br
# 示例:计算特定列的平均值br
chunk_mean = chunk [ 'column_name' ]. mean ()br
结果.append ( chunk_mean )br
br
# 从每个块的结果计算总体平均值br
总体平均值=总和(结果)/ 长度(结果)br
打印(f'column_name 的总体平均值:{overall_mean}')br
基础数据分析
加载数据后,重要的是对其进行一些初步检查,以熟悉其内容。
执行聚合分析
有时您可能希望对整个数据集执行更高级的聚合分析。例如,假设我们想通过分块处理来查找整个数据集中某一列的总和。
Python
# 初始化一个变量来存储累计和br
累计总和= 0br
br
# 分块迭代数据集br
对于 pd中的块.read_csv (file_path ,chunksize = chunk_size ): br
# 计算当前块的特定列的总和br
chunk_sum = chunk [ 'column_name' ]. sum ()br
累积总和+=块总和br
br
打印(f'column_name 的累计总和:{cumulative_sum}')分块处理缺失值
在数据预处理过程中,缺失值很常见。这里是使用每个块的平均值填充缺失值的一个例子。
Python
# 初始化一个空的 DataFrame 来存储处理后的块br
已处理的数据块= []br
br
# 分块迭代数据集br
对于 pd中的块.read_csv (file_path ,chunksize = chunk_size ): br
# 使用块的平均值填充缺失值br
chunk . fillna ( chunk . mean (), inplace = True )br
processing_chunks.append ( chunk )br
br
# 将所有处理过的块连接成一个 DataFramebr
处理后的数据= pd.concat (处理后的块,轴= 0 )br
打印(processed_data.head())区块的最终统计数据
有时,需要从所有块中获取总体统计数据。此示例说明如何通过聚合每个块的结果来计算整个列的平均值和标准差。
Python
将numpy 导入为 npbr
br
# 初始化变量来存储累计总和和计数br
累计总和= 0br
累计计数= 0br
平方和= 0br
br
br
# 分块迭代数据集br
对于 pd中的块.read_csv (file_path ,chunksize = chunk_size ): br
# 计算当前块的总和和计数br
chunk_sum = chunk [ 'column_name' ]. sum ()br
chunk_count = chunk [ 'column_name' ]. count ()br
chunk_squared_sum = ( chunk [ 'column_name' ] ** 2 ).sum ()复制代码br
br
累积总和+=块总和br
累积计数+=块计数br
squared_sum += chunk_squared_sumbr
br
# 计算平均值和标准差br
总体平均值=累积总和 / 累积计数br
总体标准差= np.sqrt ( (平方和/累计计数) - (总体平均值** 2 )) br
打印(f'column_name 的总体平均值:{overall_mean}')br
print ( f'column_name 的总体标准差:{overall_std}' )结论
使用 Python 分块读取大型数据集有助于高效地处理和分析数据,而不会占用过多的系统内存。通过利用 Pandas 的分块功能,可以在大型数据集上完成涉及数据分析的各种任务,同时确保可扩展性和效率。提供的示例说明了如何分部分读取大型数据集、解决缺失值以及执行聚合分析;从而为使用 Python 处理大量数据奠定了坚实的基础。



![深入理解Qt属性系统[Q_PROPERTY]](https://img-blog.csdnimg.cn/img_convert/45d23b8c079fb5decb293fb6167841c0.png)