作为流数据库,RisingWave 在大数据生态中通常扮演着流处理引擎的角色。它从各种数据源读取数据,并将其写入不同的目的地。在此过程中,RisingWave 清洗、转换和聚合数据,最终得出计算的结果。
RisingWave 为用户提供了丰富的交互和获取计算结果的方法。哪种是与 RisingWave 进行交互的最佳实践?答案自然是经典的:没有 Silver bullet,不同用户有着不同需求。
在这篇 blog 中,我们首先介绍与 RisingWave 交互的两种最常见的方法及其优缺点。然后,我们将引入一种专为 PostgreSQL 用户准备的与 RisingWave 交互的新形式。
1. 现有交互方法
1.1 直接在 RisingWave 中查询
在 RisingWave 中,流作业被表示为物化视图(MV)。这些 MV 将所有计算结果直接存储在数据库中,并随流作业的计算实时进行更新。你可以在各种 PostgreSQL 兼容的 Client 中通过简单的查询交互式地查询结果:
SELECT * FROM {target_mv};
这也是传统的数据库查询方式。同样你也可以使用各种 Java 或 Python API 以编程方式访问这些 MV。这种方法直接且易于实现,但这种查询需要一个额外的客户端来专门访问RisingWave,在需要频繁检索的场景中不算理想。
1.2 用 Sink 将结果写入目的地再从中查询
RisingWave 支持使用 Sink 将计算结果写入各种下游系统,如 Redis、S3、Kafka 和 PostgreSQL。写入后,你可以通过这些下游系统的 API 查询这些结果。如果此前已有合适的 Sink 系统,可以直接利用现有的部署,这是这种方案的巨大的优势。一旦配置好 Sink,RisingWave 会自动将流任务的计算结果更新到 Sink。
但如果你没有合适的 Sink 服务系统,那额外需要的部署则会增加现有架构的复杂性。
2. 为 PostgreSQL 用户提供的新方法
PostgreSQL 是一个强大且灵活的开源关系数据库管理系统,它以卓越的性能和可靠性而闻名。PostgreSQL 有一个强大的功能:外部数据封装器(Foreign Data Wrapper, FDW)。这个功能允许 PostgreSQL 连接到外部数据源,如数据库、文件和 API,将外部数据抽象为外表。查询时,这些外表中的数据就像真的存储在 PostgreSQL 内部一样。自版本 9.3 开始,postgres_fdw 扩展已经作为标准模块包含在 PostgreSQL 中,为多个 PostgreSQL 实例之间的无缝相互访问提供了有力工具。
RisingWave 作为 PostgreSQL 生态系统的一部分,从版本 1.9 开始支持 PostgreSQL 的 FDW。借助此支持,用户可以使用 postgres_fdw 扩展,将 RisingWave 的计算结果直接作为 PostgreSQL 中的外表访问。这意味着你可以对这些外表执行诸如聚合、选择和 Join 等操作,就像在普通的 PostgreSQL 表上一样。这种集成不需要为了获取计算结果所添加的额外客户端或 Sink 系统,在 RisingWave 和 PostgreSQL 之间夹起了一条无缝的直连信息通道。
3. 举例对比
我们以一个电子商务领域用例来做深入演示(该用例在另一篇文章《RisingWave 物化视图使用场景:订单数据看板》中也有介绍)。我们将用不同交互方法去获取订单在不同时间段的总支付金额。
在本用例中,要处理的原始数据都存储在 PostgreSQL 数据库中,我们将利用 RisingWave 的 postgres-cdc 功能从PostgreSQL读取,再在RisingWave中进行数据处理。
首先,让我们使用 postgres-cdc 连接器将数据从 PostgreSQL 导入 RisingWave。以下是实现这一步的示例代码:
--- 在 RisingWave 中运行
CREATE TABLE pg_orders (
o_orderkey BIGINT,
o_custkey INTEGER,
o_totalprice NUMERIC,
o_orderdate TIMESTAMP WITH TIME ZONE,
...
PRIMARY KEY (o_orderkey)
) WITH (
connector = 'postgres-cdc',
hostname = '127.0.0.1',
port = '5432',
username = 'postgresuser',
password = 'postgrespw',
database.name = 'mydb',
schema.name = 'public',
table.name = 'orders'
);
接下来,我们可以创建三个物化视图(MV),分别统计按分钟、小时和天的粒度计算订单的总支付金额。
--- 在 RisingWave 中运行
--- 分钟级
CREATE MATERIALIZED VIEW orders_total_price_per_min AS
SELECT date_trunc('minute', o_orderdate) minute, SUM(o_totalprice) totalprice
FROM pg_orders
GROUP BY date_trunc('minute', o_orderdate);
--- 小时级
CREATE MATERIALIZED VIEW orders_total_price_per_hour AS
SELECT date_trunc('hour', MINUTE) hour, SUM(totalprice) totalprice
FROM orders_total_price_per_min
GROUP BY date_trunc('hour', minute);
--- 天级
CREATE MATERIALIZED VIEW orders_total_price_per_day AS
SELECT date_trunc('day', hour) date, SUM(totalprice) totalprice
FROM orders_total_price_per_hour
GROUP BY date_trunc('day', hour);
现在,我们拥有了分别为分钟级、小时级和天级的三个物化视图,它们都是实时更新的。在此基础上,当我们需要计算过去七天的总收入时,可以尝试分别用上文的三种交互方法来计算。
3.1 方法一:直接在 RisingWave 中查询
第一种方法是简单地使用客户端登录到 RisingWave,并执行以下查询就可以获得所需结果:
--- 在 RisingWave 中运行
SELECT SUM(totalprice)
FROM orders_total_price_per_day
WHERE date BETWEEN date_trunc('day', NOW() - INTERVAL '7 days') AND date_trunc('day', NOW());
------
sum
---------------
1725458400.05
整个过程可以通过下图直观表示:
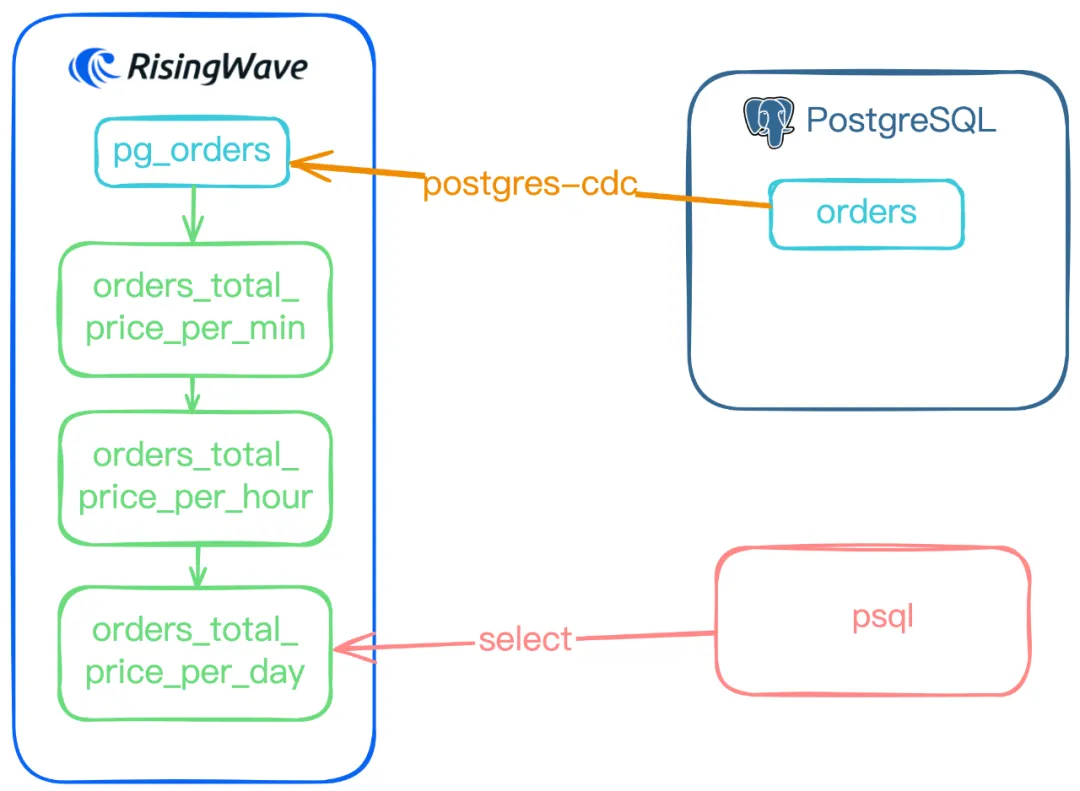
3.2 方法二:使用 Sink 导出并查询数据
要使用 RisingWave 的 Sink 传送并查询数据,你首先需要在 PostgreSQL 中创建一个表,作为 Sink 连接器写入数据的目的地:
--- 在 PostgreSQL 中运行
CREATE TABLE orders_total_price_per_day (
date timestamptz primary key,
totalprice numeric
);
接下来,在 RisingWave 中,用以下语句创建一个 Sink。这个 Sink 将把数据实时从 RisingWave 中的 orders_total_price_per_day 物化视图导出到 PostgreSQL 中的 orders_total_price_per_day 表:
--- 在 RisingWave 中运行
CREATE SINK orders_total_price_per_day
FROM orders_total_price_per_day
WITH (
connector = 'jdbc',
jdbc.url = 'jdbc:postgresql://127.0.0.1:5432/mydb?user=postgresuser&password=postgrespw',
table.name = 'orders_total_price_per_day',
type = 'upsert',
primary_key = 'date'
);
然后,就可以直接在 PostgreSQL 中查询:
--- 在 PostgreSQL 中运行
SELECT SUM(totalprice) AS total_price, DATE_TRUNC('day', NOW()) AS day
FROM orders_total_price_per_day
WHERE date BETWEEN DATE_TRUNC('day', NOW() - INTERVAL '7 days') AND DATE_TRUNC('day', NOW());
------
sum | day
---------------+---------------------
1725458400.05 | 2024-04-20 00:00:00
或者,你也可以把查询数据的 SELECT 请求在 RisingWave 中直接创建为一个 Sink,将最终查询结果直接写入 PostgreSQL。
--- 在 RisingWave 中运行
CREATE SINK orders_total_price_in_7_days
AS
SELECT SUM(totalprice) AS total_price, DATE_TRUNC('day', NOW()) AS day
FROM orders_total_price_per_day
WHERE date BETWEEN DATE_TRUNC('day', NOW() - INTERVAL '7 days') AND DATE_TRUNC('day', NOW())
WITH (
connector = 'jdbc',
jdbc.url = 'jdbc:postgresql://127.0.0.1:5432/mydb?user=postgresuser&password=postgrespw',
table.name = 'orders_total_price_in_7_days',
type = 'upsert',
primary_key = 'day'
);
整个过程可以通过下图直观表示:

3.3 方法三:使用 PostgreSQL FDW
第三种方法,也即本文的重点,是利用 PostgreSQL 的外部数据封装器 (FDW) 功能来实现。通过使用 postgres_fdw,你可以无缝访问和查询来自其他 PostgreSQL 数据库的数据。要使用此功能,你需要进行一些设置,并在 PostgreSQL 中创建一个外表,然后就可以轻松访问和查询数据:
--- 在 PostgreSQL 中运行
--- 安装 `postgres_fdw` 扩展
CREATE EXTENSION postgres_fdw;
--- 填写你自己的 RisingWave 服务器信息,这里将外部服务器命名为 `risingwave`
CREATE SERVER risingwave
FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (host '127.0.0.1', port '4566', dbname 'dev');
--- 为外部服务器创建一个用户映射,这里将 RisingWave 的用户 `root` 映射到 PostgreSQL 的用户 `postgresuser`
CREATE USER MAPPING FOR postgresuser
SERVER risingwave
OPTIONS (user 'root', password 'xxx');
--- 将 RisingWave 中 `public` 模式下所有表和物化视图的定义导入到 PostgreSQL 的 `public` 模式中,你也可以按需选择性的导入
IMPORT FOREIGN SCHEMA public
FROM SERVER risingwave INTO public;
通过运行上述语句,RisingWave 中的所有表和物化视图 (MV) 将被导入到 PostgreSQL 中,并作为外表可以被访问。你可以随时查验哪些表已经成功映射到 PostgreSQL:
--- 在 PostgreSQL 中运行
\d
------
List of relations
Schema | Name | Type | Owner
--------+-----------------------------+---------------+--------------
public | orders | table | postgresuser
public | orders_total_price_per_day | foreign table | postgresuser
public | orders_total_price_per_hour | foreign table | postgresuser
public | orders_total_price_per_min | foreign table | postgresuser
public | pg_orders | foreign table | postgresuser
可以看到,我们上面在 RisingWave 中创建的表和物化视图都被映射为 PostgreSQL 中的外表。如果希望导入特定的表或 MV,例如 orders_total_price_per_day,可以通过运行以下命令来实现:
--- 在 PostgreSQL 中运行
CREATE FOREIGN TABLE orders_total_price_per_day(
date timestamp with time zone,
totalprice NUMERIC
)
SERVER risingwave
OPTIONS (schema_name 'public', table_name 'orders_total_price_per_day');
虽然这种方法需要在 PostgreSQL 中进行一些配置,看起来更复杂,但只需要做一次 setup,而且它的参数并不复杂。如果使用 IMPORT FOREIGN SCHEMA,甚至不需要指定表和 MV 名称 —— PostgreSQL 会自动导入它们。一旦正确配置后,你就可以直接在 PostgreSQL 中查询远程数据,就像这些表是存储在本地的一样。
--- 在 PostgreSQL 中运行
SELECT SUM(totalprice)
FROM orders_total_price_per_day
WHERE date BETWEEN date_trunc('day', NOW() - INTERVAL '7 days') AND date_trunc('day', NOW());
------
sum
---------------
1725458400.05
这个流程的整个架构可以通过下图表示(这里假设所有表和物化视图都已导入):
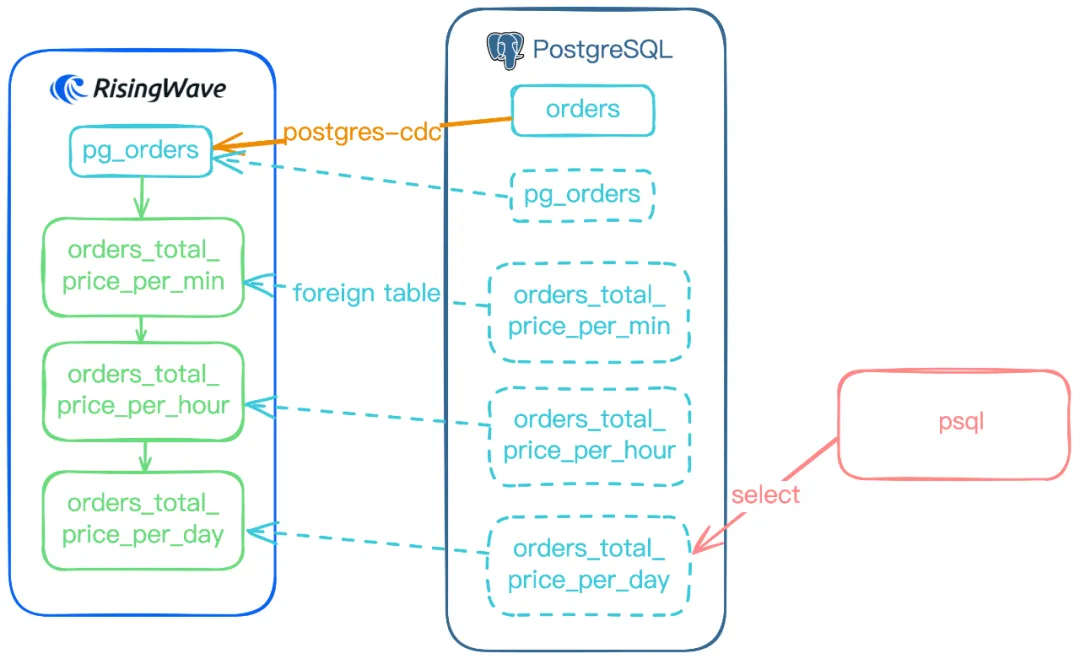
4. 外部数据封装器的优势
外部数据封装器 (FDW) 有两个显著优势。首先,它允许随时访问 RisingWave 的中间计算结果,无需额外设置。这意味着你可以直接在 PostgreSQL 中查询像 orders_total_price_per_hour 和 orders_total_price_per_min 这样的表,而无需额外配置。此方法特别适用于临时场景,比如调试。用户可能需要调试或临时检查数据,此时就无需额外添加 Sink 。其次,由于 FDW 是 PostgreSQL 的标准扩展,它支持 PostgreSQL 的几乎所有功能,例如将外表与普通表 Join。比如:你可以将 PostgreSQL 中的 orders 表与外表 orders_total_price_per_day 进行连接:
--- 在 PostgreSQL 中运行
SELECT count(*) totalcount, orders_total_price_per_day.date, orders_total_price_per_day.totalprice FROM orders_total_price_per_day JOIN orders ON date_trunc('day', orders.o_orderdate) = orders_total_price_per_day.date GROUP BY orders_total_price_per_day.date, orders_total_price_per_day.totalprice;
与其他解决方案不同的是,外部数据封装器在处理多个数据库时提供的体验更加无缝。一般来说,分析存在于两个数据库中的数据需要手动将一方的数据导入数据另一方,这无疑会很繁琐,但 FDW 优雅地解决了这个问题。FDW 允许你在单个查询中查询多个数据库中的数据,这种查询模式也被称为“联邦查询” (Federated Querying)。
5. 结论
在本文中,我们探讨了三种与 RisingWave 和 PostgreSQL 交互的方法:直接在 RisingWave 中查询;用 Sink 将数据导出并查询;以及使用 postgres_fdw。对于“PostgreSQL 与 RisingWave 交互的最佳实践是什么?”这个问题,针对不同用户,我们仍无法给出一个统一的答案。但我们至少可以确定一点:如果你需要 RisingWave 和 PostgreSQL 之间的丝滑集成,FDW 会是一个不错的选择。
6. 附录
如果你对不同 PostgreSQL 发行版中 CDC(流式数据采集)和 FDW 的支持情况感兴趣,我们整理了如下列表,表中信息截至 2024 年 4 月底。
| CDC | FDW | |
|---|---|---|
| AWS RDS for PostgreSQL | ✅ | ✅ |
| AWS Aurora PostgreSQL | ✅ | ✅ |
| Azure Database for PostgreSQL | ✅ | ✅ |
| GCP Cloud SQL For PostgreSQL | ✅ | ✅ |
| GCP AlloyDB for PostgreSQL | ✅ | ✅ |
| Aiven for PostgreSQL | ✅ | ✅ |
| Supabase | 部分情况下支持 | ✅ |
| Neon | 暂时不支持 | 暂时不支持 |
| TimescaleDB | 暂时不支持 | 暂时不支持 |
7. 关于 RisingWave
RisingWave 是一款开源的分布式流处理数据库,旨在帮助用户降低实时应用的开发成本。RisingWave 采用存算分离架构,提供 Postgres-style 使用体验,具备比 Flink 高出 10 倍的性能以及更低的成本。
👨🔬加入 RW 社区,欢迎关注公众号:RisingWave 中文开源社区
🧑💻快速上手 RisingWave,欢迎体验入门教程:github.com/risingwave
💻深入使用 RisingWave,欢迎阅读用户文档:zh-cn.risingwave.com/docs
🔍更多常见问题及答案,欢迎搜索留言: risingwavelabs/discussions