选择题
-
SVM中的什么是支持向量? 【 正确答案: D】
A. 数据集中的所有样本
B. 模型参数
C. 模型的预测输出
D. 训练数据中离决策边界最近的样本点 -
支持向量机(SVM)算法的主要目标是: 【 正确答案: C】
A. 最小化间隔
B. 最小化损失函数
C. 最大化间隔
D. 最大化损失函数 -
在SVM中,什么是间隔(margin)? 【 正确答案: B】
A. 样本之间的距离
B. 决策边界到支持向量的距离
C. 特征空间的维度
D. 核函数的度数 -
假设输入为300*400的彩色(RGB)图像,使用全连接神经网络。如果第一个隐藏层有150个神经元,那么这个隐藏层一共有多少参数(包括偏置参数)? 【 正确答案: D】
A.3,600,150
B.1200150
C.18,000,150
D.54,000,150
神经网络在以下哪些应用领域中得到广泛使用? 【 正确答案: D】
A.图像识别
B.语音识别
C.自然语言处理
D.所有以上领域
-
下面那个不是卷积神经网络? 【 正确答案: D】
A. AlexNet
B. ResNet
C. VGG16
D. Transformer -
以下哪项不是神经网络的基本组成部分?【 正确答案: D】
A. 神经元
B. 权重
C. 激活函数
D. 编译器 -
多层感知机(MLP)主要用于解决哪类问题? 【 正确答案: B】
A. 线性可分问题
B. 非线性问题
C. 数据存储问题
D. 网络安全问题 -
卷积网络的下采样的作用是什么 【 正确答案: A】
A. 降维
B. 获得细粒度特征表示
C. 获得边缘特征
D. 将二维转换为一维 -
以下说法哪些是不正确的? 【 正确答案: A C】
A.神经网络的参数可以初始化为同一个很小的值
B.当采用Sigmoid函数做为激活函数时,神经网络在反向传播时,容易面临梯度弥散问题
C.三层的神经网络是一个深度网络模型
D.深度学习往往需要更多的数据,才能学习到好的网络参数 -
训练集、验证集和测试集在神经网络训练中的作用是什么 【 正确答案: AC】
A.训练集用于训练模型
B.验证集用于调整模型参数
C.测试集用于最终评估模型性能
D.验证集用于最终评估模型性能
填空题
-
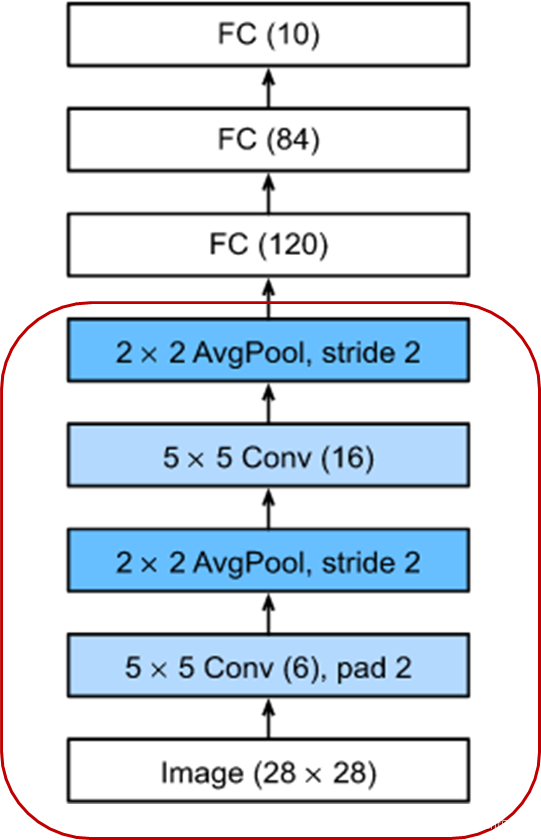
请输出第二个卷积层后的特征图的宽高 【 正确答案: 10】
-
在神经网络中,【 正确答案: 神经元】是处理信息的基本单元【 正确答案: 权重】是连接各个神经元的参数,表示它们之间的连接强度,而【 正确答案: 激活函数】是用于决定神经元是否应该被激活的函数。
判断题
- 相对于神经网络,支持向量机能在少量样本情况下获得很好解【正确答案:正确】
- 支持向量机算法是一种用于解决分类问题的无监督学习算法。【正确答案:错误】
- 支持向量机算法对于大规模数据集来说非常高效,不会受到计算开销的影响。【正确答案:错误】
- 支持向量机算法可以用于解决回归问题,不仅局限于分类问题。【正确答案:正确】
- 支持向量机算法对噪声敏感,容易受到异常值的影响。【正确答案:错误】
- 支持向量机算法只能用于二分类问题,无法扩展到多类别分类。【正确答案:错误】
- 支持向量机中的超平面是通过最大化间隔来选择的,间隔表示数据点到决策边界的距离。【正确答案:正确】
- 支持向量机算法中,软间隔(Soft Margin)允许模型在训练集中存在一些误分类的样本。【正确答案:正确】
- 支持向量机算法在训练过程中一定会找到全局最优解。【正确答案:错误】
- 支持向量机算法对特征的尺度不敏感,无需进行特征缩放。【正确答案:错误】
- 支持向量机的核函数用于将数据映射到高维空间,以解决非线性可分的问题。【正确答案:正确】
简答题
-
LDA和PCA有何不同?在什么情况下你更倾向于使用LDA而不是PCA?
- 目标不同,LDA的目标是最大化不同类别间的差异,PCA的目标是最大化数据集的方差。
- LDA更适合分类问题。
-
什么是“支持向量”?支持向量机的基本原理是什么?支持向量机有什么特点?
- 支持向量是训练数据中距离超平面最近的样本点。
- 监督学习算法。
- 适用于多分类问题。
-
简述软间隔SVM和硬间隔SVM的异同点。
- 基本原理相同,都是找到超平面分隔数据点。
- 目标都是最大化间隔。
- 软间隔允许有分类错误。
- 硬间隔对数据要求严格,对数据敏感。
-
SVM如何实现非线性分类?核函数的作用是什么?
- 通过引入核函数实现非线性分类。
- 实现映射到高维空间。
- 引入非线性决策边界。
-
集成学习的方法大致可分为哪两大类? Bagging 模型与Boosting 模型有何异同点?分别有哪些典型的算法?
- Bagging和Boosting。
- Bagging是并行集成学习方法,Boosting是串行集成学习方法。
- Bagging有随机森林算法,Boosting有AdaBoost算法。
-
讨论超参数调优的方法和重要性。
- 优化神经网络性能的关键步骤。
- 避免过拟合或欠拟合。
-
分析一个过拟合的网络,并提出解决策。
- 训练数据上表现很好,但在新数据上表现不佳。
- 增加数据集的大小和多样性;使用L1,L2正则化技术;减少模型复杂性
-
讨论网络架构在特定应用中的重要性。
- 网络架构在神经网络的特定应用中起着决定性作用。
- 如对于图像,可以用CNN卷积神经网络。
- 对于文本,可以用RNN循环神经网络。
-
选择一个应用案例,比如图像识别,分析其网络设计和实施的关键因素。
- 在图像识别中,选择网络结构非常重要,需要选择CNN卷积神经网络。
- 可以适当使用Dropout技术,避免过拟合。
-
基于当前趋势,预测深度学习未来的发展方向。
- 增强学习的集成,用于更复杂的决策过程。
- 自动化机器学习(AutoML)在网络架构和超参数调优中的应用。
- 更加高效和环保的模型,以减少碳足迹。
- 神经网络的可解释性和透明性的提升。
- 以及跨模态学习,即结合不同类型的数据(如图像、文本和声音)的深度学习模型。
-
假设一个简单神经网络的单个神经元,其初始权重为 0.5,学习率为 0.01。给定输入 x = 1.5 和目标输出 y = 0.6,使用均方误差损失函数和简单的线性激活函数,计算一次迭代后的权重更新值。
- 首先进行前向传播,计算预测值:0.5 * 1.5 = 0.75
- 然后计算损失:1/2(0.75-0.6)^2 = 0.01125
- 计算损失函数对权重的梯度:1.5 * (0.75-0.6) = 0.225
- 更新权重:0.5 - 0.01 * 0.225 = 0.49775
-
描述构建和训练一个简单前馈网络的步骤。
- 设计网络架构,输入层、隐藏层(数量和大小)和输出层。
- 初始化网络的权重和偏置。
- 选择一个损失函数和优化器。
- 训练网络。
-
讨论损失函数和优化器的选择及其重要性。
- 损失函数衡量了模型的预测值与真实值之间的差距。
- 优化器决定了网络如何更新其权重以减少损失。
-
请简述单层感知机的工作原理。
- 单层感知机是一种简单的线性分类器,由输入层和输出层组成,但没有隐藏层。
-
请阐述损失函数和反向传播在神经网络学习中的作用。
- 损失函数在神经网络中用来衡量模型的预测结果与实际结果之间的差异。
- 其值越小,表示模型的性能越好。
- 反向传播是一种优化算法,用于最小化损失函数。
-
激活函数ReLU、 Sigmoid和Tanh的特点。
- Sigmoid将输入映射到0和1之间。
- ReLU在正值时保持梯度不变,负值时为0。
- Tanh将输入映射到-1和1之间。
-
解释如何构建一个基本的MLP模型。
- 首先,确定输入层的大小,这通常取决于数据特征的数量。
- 接着,添加一个或多个隐藏层,这些隐藏层可以有不同数量的神经元,并选择合适的激活函数(如ReLU或Sigmoid)。
- 最后,设置输出层,其神经元数量应与预期输出的格式相匹配。
- 在构建模型后,选择一个损失函数和优化器,用于训练模型。
-
设计一个全连接神经网络来识别手写数字
- 可以设计一个包含输入层、若干隐藏层和输出层的全连接神经网络模型。