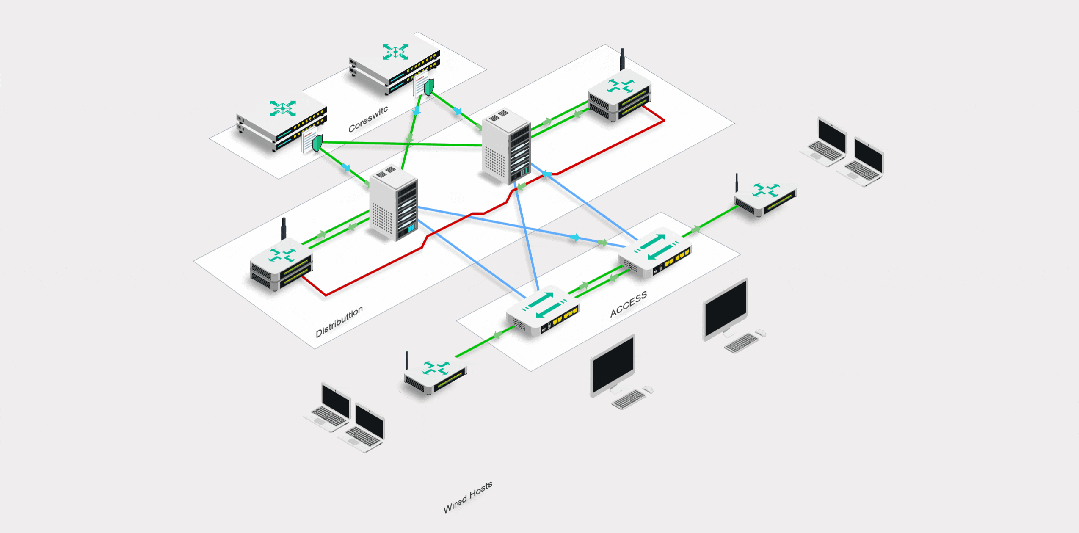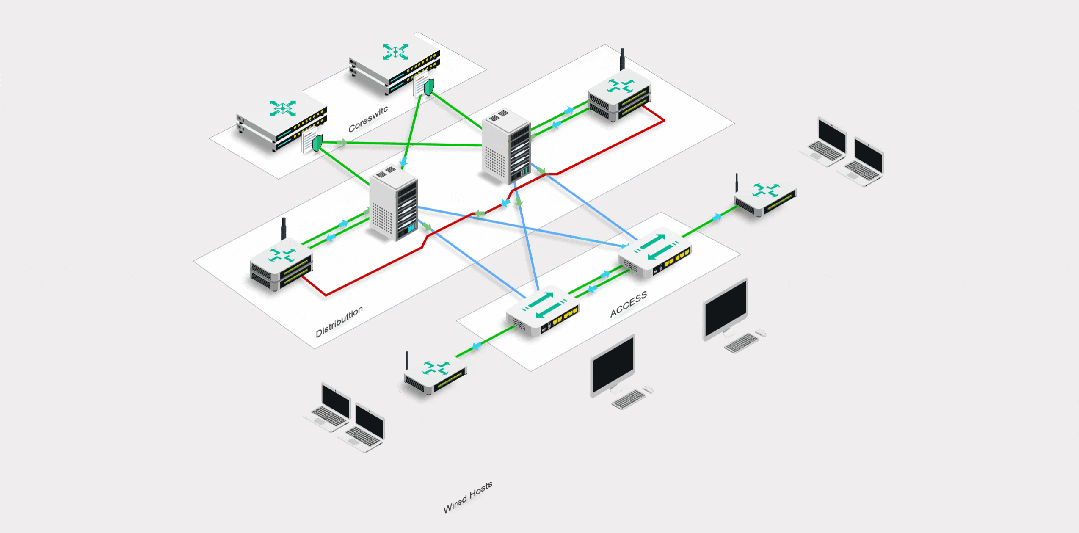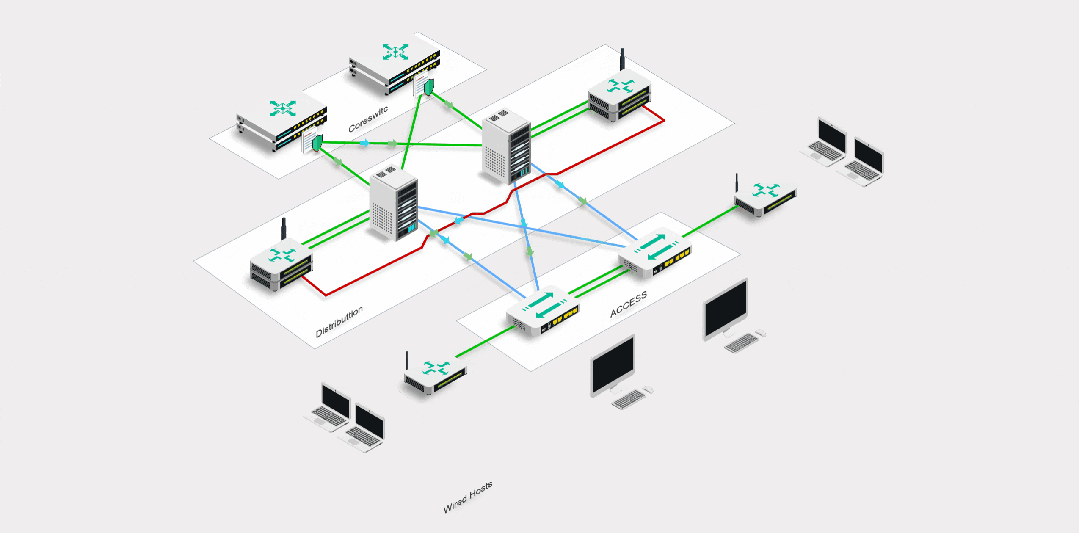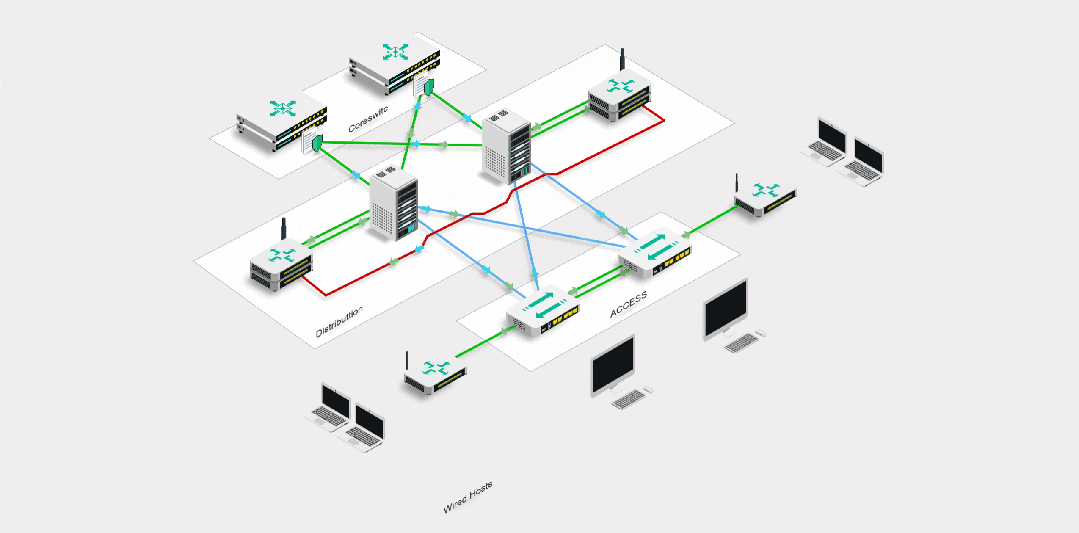
1、视图
视图(逻辑视图,logical views)是封装了一个或多个SELECT语句的存储查询(stored queries)。视图在执行时动态访问和计算数据库数据。视图是只读的,可以引用任何表和其他视图的组合。
视图可用于以下目的:
- 通过对用户隐藏复杂的SELECT语句来简化访问或提供安全访问。例如,您可以创建一个视图,该视图只显示各种表中用户需要的数据,同时在这些表中隐藏敏感数据。
- 将可能随时间变化的表结构的细节封装在一致的用户界面后面。
与物化视图不同,逻辑视图不是物化的,这意味着它们不将数据存储在磁盘上。因此,它们具有以下局限性:
- 当底层表数据发生变化时,Doris不需要刷新视图数据。但是,通过视图访问和计算数据可能会产生一些开销。
- 视图不支持插入、删除或更新操作。
创建视图
创建逻辑视图的语法如下:
CREATE VIEW [IF NOT EXISTS]
[db_name.]view_name
(column1[ COMMENT "col comment"][, column2, ...])
AS query_stmt
解释:
- 视图是逻辑的,没有物理存储。视图上的所有查询都等同于视图对应子查询上的查询。
query_stmt是任何受支持的SQL语句。
Example:
在example_db数据库中创建名为example_view的视图:
CREATE VIEW example_db.example_view (k1, k2, k3, v1)
AS
SELECT c1 as k1, k2, k3, SUM(v1) FROM example_table
WHERE k1 = 20160112 GROUP BY k1,k2,k3;
创建带有注释的视图:
CREATE VIEW example_db.example_view
(
k1 COMMENT "first key",
k2 COMMENT "second key",
k3 COMMENT "third key",
v1 COMMENT "first value"
)
COMMENT "my first view"
AS
SELECT c1 as k1, k2, k3, SUM(v1) FROM example_table
WHERE k1 = 20160112 GROUP BY k1,k2,k3;
2、物化视图
物化视图是预先计算(根据定义的SELECT语句)并存储在Doris中的一个特殊表中的数据集。
物化视图的出现主要是为了满足用户。它可以分析任意维度的原始详细数据,也可以快速分析和查询固定维度。
2.1 何时使用物化视图
- 分析需求,包括详细的数据查询和固定维度的查询。
- 查询只涉及表中一小部分列或行。
- 查询包含一些耗时的处理操作,如长时间的聚合操作。
- 查询需要匹配不同的前缀索引。
2.2 优点
- 对于那些经常重复使用相同子查询结果的查询,性能得到了很大的提高
- Doris自动维护物化视图的数据,无论是新的导入还是删除操作,都可以保证基表和物化视图表的数据一致性。不需要任何额外的人工维护成本。
- 查询时,自动匹配最优的物化视图,直接从物化视图读取数据。
对物化视图数据的自动维护将导致一些维护开销,稍后将在物化视图的限制中解释这一点。
2.3 物化视图VS Rollup
在物化视图功能出现之前,用户通常使用Rollup功能通过预聚合来提高查询效率。但是,Rollup有一定的局限性。它不能基于明细模型进行预聚合。
物化视图涵盖了Rollup的功能,同时还支持更丰富的聚合功能。物化视图实际上是Rollup的超集。
换句话说,以前由ALTER TABLE ADD ROLLUP语法支持的功能现在可以通过CREATE MATERIALIZED VIEW实现。
2.4 使用物化视图
Doris系统为物化视图提供了一套完整的DDL语法,包括创建、查看和删除。DDL的语法与PostgreSQL和Oracle一致。
2.4.1 创建一个物化视图
在这里,您必须首先根据查询语句的特征决定创建哪种物化视图。这并不是说您的物化视图定义与您的查询语句之一完全相同。这里有两个原则:
- 从查询语句中抽象出来,使用多个查询共享的分组和聚合方法作为物化视图的定义。
- 没有必要为所有维度组合创建实体化视图。
首先,第一点,如果一个物化视图被抽象,并且多个查询可以匹配到这个物化视图。这种物化视图效果最好。因为维护物化视图本身也会消耗资源。
如果物化视图只适合特定查询,而其他查询不使用此物化视图。物化视图不仅占用集群的存储资源,而且无法提供更多的查询服务,因此成本效益不高。
因此,用户需要将自己的查询语句和数据维度信息结合起来,抽象出一些物化视图的定义。
第二点是,在实际的分析查询中,并不是所有的维度分析都会被覆盖。因此,对于常用的维度组合,创建一个物化的视图就足够了,从而达到空间和时间的平衡。
创建物化视图是一个异步操作,这意味着在用户成功提交创建任务后,Doris将在后台计算现有数据,直到创建成功。
具体语法可以通过以下命令查看:
HELP CREATE MATERIALIZED VIEW
在Doris 2.0中,我们对物化视图做了一些增强(在本文的最佳实践4中进行了描述)。我们建议用户在正式的生产环境中使用物化视图之前,先在测试环境中检查预期的查询是否能够命中期望的物化视图。
如果您不知道如何验证查询是否命中物化视图,可以阅读本文的最佳实践1。
同时,我们不建议用户在同一个表上创建多个形状相似的物化视图,这可能会导致多个物化视图之间的冲突,导致查询命中失败(这个问题将在新的优化器中得到改善)。建议用户首先验证物化视图和查询是否满足需求,是否可以在测试环境中正常使用。
2.4 2 支持聚合函数
物化视图函数目前支持的聚合函数有:
-
SUM, MIN, MAX (Version 0.12)
-
COUNT, BITMAP_UNION, HLL_UNION (Version 0.13)
-
AGG_STATE (Version 2.0)
一些最初不支持的聚合函数将被转换为agg_state类型以实现预聚合。
2.4.3 更新策略
为了保证物化视图表和基表之间的数据一致性,Doris将基表上的导入、删除等操作都同步到物化视图表上。并通过增量更新来提高更新效率。通过事务确保原子性。
例如,如果用户通过INSERT命令将数据插入到基表中,则该数据将同步插入到物化视图中。当基表和物化视图表都被成功写入时,INSERT命令将成功返回。
2.4.4 查询自动匹配
成功创建物化视图后,不需要更改用户的查询,也就是说,它仍然是查询的基表。Doris会根据当前查询语句自动选择最优的物化视图,从物化视图中读取数据并进行计算。
用户可以使用EXPLAIN命令检查当前查询是否使用了物化视图。
物化视图中的聚合与查询中的聚合的匹配关系:

当位图和hll的聚合函数在查询中匹配物化视图后,将根据物化视图的表结构重写查询的聚合操作符。有关详细信息,请参见示例2。
2.4.5 查询物化视图
检查当前表有哪些物化视图,以及它们的表结构是什么。通过以下命令:
MySQL [test]> desc mv_test all;
+-----------+---------------+-----------------+----------+------+-------+---------+--------------+
| IndexName | IndexKeysType | Field | Type | Null | Key | Default | Extra |
+-----------+---------------+-----------------+----------+------+-------+---------+--------------+
| mv_test | DUP_KEYS | k1 | INT | Yes | true | NULL | |
| | | k2 | BIGINT | Yes | true | NULL | |
| | | k3 | LARGEINT | Yes | true | NULL | |
| | | k4 | SMALLINT | Yes | false | NULL | NONE |
| | | | | | | | |
| mv_2 | AGG_KEYS | k2 | BIGINT | Yes | true | NULL | |
| | | k4 | SMALLINT | Yes | false | NULL | MIN |
| | | k1 | INT | Yes | false | NULL | MAX |
| | | | | | | | |
| mv_3 | AGG_KEYS | k1 | INT | Yes | true | NULL | |
| | | to_bitmap(`k2`) | BITMAP | No | false | | BITMAP_UNION |
| | | | | | | | |
| mv_1 | AGG_KEYS | k4 | SMALLINT | Yes | true | NULL | |
| | | k1 | BIGINT | Yes | false | NULL | SUM |
| | | k3 | LARGEINT | Yes | false | NULL | SUM |
| | | k2 | BIGINT | Yes | false | NULL | MIN |
+-----------+---------------+-----------------+----------+------+-------+---------+--------------+
您可以看到当前mv_test表有三个物化视图:mv_1、mv_2和mv_3,以及它们的表结构。
2.4.6 删除物化视图
如果用户不再需要物化视图,您可以通过**DROP 删除物化视图**。 DROP MATERIALIZED VIEW
用户可以通过命令查看已创建的物化视图:
SHOW CREATE MATERIALIZED VIEW
取消创建物化视图
CANCEL ALTER TABLE MATERIALIZED VIEW FROM db_name.table_name
2.5 最佳实践1
物化视图的使用一般分为以下几个步骤:
- 创建一个物化视图
- 异步检查物化视图是否已被构造
- 查询和自动匹配物化视图
首先是第一步:创建一个物化视图
假设用户有一个销售记录列表,其中存储了交易id、销售人员、销售商店、销售时间和每个交易的金额。表建立语句和插入数据语句是:
create table sales_records
(record_id int, seller_id int, store_id int, sale_date date, sale_amt bigint)
distributed by hash(record_id)
properties("replication_num" = "1");
insert into sales_records values(1,1,1,"2020-02-02",1);
sales_records的表结构如下:
MySQL [test]> desc sales_records;
+-----------+--------+------+-------+---------+--- ----+
| Field | Type | Null | Key | Default | Extra |
+-----------+--------+------+-------+---------+--- ----+
| record_id | INT | Yes | true | NULL | |
| seller_id | INT | Yes | true | NULL | |
| store_id | INT | Yes | true | NULL | |
| sale_date | DATE | Yes | false | NULL | NONE |
| sale_amt | BIGINT | Yes | false | NULL | NONE |
+-----------+--------+------+-------+---------+--- ----+
此时,如果用户经常对不同商店的销售量执行分析查询,则可以为sales_records表创建一个物化视图,对销售商店进行分组,并对相同销售商店的销售额求和。创建语句如下:
MySQL [test]> create materialized view store_amt
as select store_id, sum(sale_amt)
from sales_records
group by store_id;
后端返回到下图,表示创建物化视图的任务已成功提交。
Query OK, 0 rows affected (0.012 sec)
步骤2:检查物化视图是否已构建完成
由于创建物化视图是一个异步操作,用户提交创建物化视图的任务后,需要通过命令异步检查物化视图是否已经构造完成。命令如下:
SHOW ALTER TABLE ROLLUP FROM db_name; (Version 0.12)
SHOW ALTER TABLE MATERIALIZED VIEW FROM db_name; (Version 0.13)
其中db_name为参数,需要使用实际的数据库名称代替。该命令的结果是显示该数据库下创建物化视图的所有任务。结果如下:
+-------+---------------+---------------------+--- ------------------+---------------+--------------- --+----------+---------------+-----------+-------- -------------------------------------------------- -------------------------------------------------- -------------+----------+---------+
| JobId | TableName | CreateTime | FinishedTime | BaseIndexName | RollupIndexName | RollupId | TransactionId | State | Msg | Progress | Timeout |
+-------+---------------+---------------------+--- ------------------+---------------+--------------- --+----------+---------------+-----------+-------- -------------------------------------------------- -------------------------------------------------- -------------+----------+---------+
| 22036 | sales_records | 2020-07-30 20:04:28 | 2020-07-30 20:04:57 | sales_records | store_amt | 22037 | 5008 | FINISHED | | NULL | 86400 |
+-------+---------------+---------------------+--- ------------------+---------------+--------------- --+----------+---------------+-----------+-------- ----------------------------------------
其中,TableName指的是物化视图的数据来自哪个表,RollupIndexName指的是物化视图的名称。一个比较重要的指标是State。
当创建物化视图的任务State 变为FINISHED时,意味着物化视图已经成功创建。这意味着在查询时可以自动匹配这个物化视图。
第三步:查询
创建物化视图后,当用户查询不同商店的销售额时,将直接从刚刚创建的物化视图store_amt中读取聚合的数据。达到提高查询效率的效果。
用户的查询仍然指定查询sales_records表,例如:
SELECT store_id, sum(sale_amt) FROM sales_records GROUP BY store_id;
上面的查询将自动匹配store_amt。用户可以使用以下命令检查当前查询是否与相应的物化视图匹配。
EXPLAIN SELECT store_id, sum(sale_amt) FROM sales_records GROUP BY store_id;
+----------------------------------------------------------------------------------------------+
| Explain String |
+----------------------------------------------------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS: |
| <slot 4> `default_cluster:test`.`sales_records`.`mv_store_id` |
| <slot 5> sum(`default_cluster:test`.`sales_records`.`mva_SUM__`sale_amt``) |
| PARTITION: UNPARTITIONED |
| |
| VRESULT SINK |
| |
| 4:VEXCHANGE |
| offset: 0 |
| |
| PLAN FRAGMENT 1 |
| |
| PARTITION: HASH_PARTITIONED: <slot 4> `default_cluster:test`.`sales_records`.`mv_store_id` |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 04 |
| UNPARTITIONED |
| |
| 3:VAGGREGATE (merge finalize) |
| | output: sum(<slot 5> sum(`default_cluster:test`.`sales_records`.`mva_SUM__`sale_amt``)) |
| | group by: <slot 4> `default_cluster:test`.`sales_records`.`mv_store_id` |
| | cardinality=-1 |
| | |
| 2:VEXCHANGE |
| offset: 0 |
| |
| PLAN FRAGMENT 2 |
| |
| PARTITION: HASH_PARTITIONED: `default_cluster:test`.`sales_records`.`record_id` |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 02 |
| HASH_PARTITIONED: <slot 4> `default_cluster:test`.`sales_records`.`mv_store_id` |
| |
| 1:VAGGREGATE (update serialize) |
| | STREAMING |
| | output: sum(`default_cluster:test`.`sales_records`.`mva_SUM__`sale_amt``) |
| | group by: `default_cluster:test`.`sales_records`.`mv_store_id` |
| | cardinality=-1 |
| | |
| 0:VOlapScanNode |
| TABLE: default_cluster:test.sales_records(store_amt), PREAGGREGATION: ON |
| partitions=1/1, tablets=10/10, tabletList=50028,50030,50032 ... |
| cardinality=1, avgRowSize=1520.0, numNodes=1 |
+----------------------------------------------------------------------------------------------+
从底部test.sales_records(store_amt)可以看出,该查询命中了store_amt物化视图。值得注意的是,如果表中没有数据,那么物化视图可能不会被命中。
2.6 最佳实践2 PV,UV
业务场景:计算广告的UV和PV
假设用户的原始广告点击数据存储在Doris中,那么对于广告PV和UV查询,可以通过创建bitmap_union的物化视图来提高查询速度。
使用下面的语句首先创建一个表,该表存储广告点击数据的详细信息,包括每次点击的点击事件、点击了什么广告、点击了什么渠道以及点击的用户是谁。
MySQL [test]> create table advertiser_view_record
(time date, advertiser varchar(10), channel varchar(10), user_id int)
distributed by hash(time)
properties("replication_num" = "1");
insert into advertiser_view_record values("2020-02-02",'a','a',1);
原始广告点击数据表结构为:
MySQL [test]> desc advertiser_view_record;
+------------+-------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+-------------+------+-------+---------+-------+
| time | DATE | Yes | true | NULL | |
| advertiser | VARCHAR(10) | Yes | true | NULL | |
| channel | VARCHAR(10) | Yes | false | NULL | NONE |
| user_id | INT | Yes | false | NULL | NONE |
+------------+-------------+------+-------+---------+-------+
4 rows in set (0.001 sec)
2.6.1 创建一个物化视图
由于用户要查询广告的UV值,即需要对同一广告的用户进行精确的去重复,所以用户的查询一般为:
SELECT advertiser, channel, count(distinct user_id)
FROM advertiser_view_record
GROUP BY advertiser, channel;
对于这种uv搜索场景,我们可以使用bitmap_union创建一个物化视图,提前实现精确的重复数据删除效果。
在Doris中,count(distinct)聚合的结果与bitmap_union_count聚合的结果完全相同。并且bitmap_union_count等于bitmap_union计算计数的结果,所以如果查询涉及count(distinct),您可以通过创建具有bitmap_union聚合的物化视图来加快查询速度。
对于这种情况,您可以创建一个物化视图,该视图根据广告和通道分组准确地删除user_id的重复数据。
MySQL [test]> create materialized view advertiser_uv as
select advertiser, channel, bitmap_union(to_bitmap(user_id))
from advertiser_view_record
group by advertiser, channel;
Query OK, 0 rows affected (0.012 sec)
注意:因为
user_id本身是INT类型,所以在Doris中直接调用bitmap_union。首先需要通过to_bitmap函数将字段转换为位图类型,然后才能进行bitmap_union聚合。
创建完成后,广告点击时间表和物化视图表的表结构如下:
MySQL [test]> desc advertiser_view_record all;
+------------------------+---------------+----------------------+-------------+------+-------+---------+--------------+
| IndexName | IndexKeysType | Field | Type | Null | Key | Default | Extra |
+------------------------+---------------+----------------------+-------------+------+-------+---------+--------------+
| advertiser_view_record | DUP_KEYS | time | DATE | Yes | true | NULL | |
| | | advertiser | VARCHAR(10) | Yes | true | NULL | |
| | | channel | VARCHAR(10) | Yes | false | NULL | NONE |
| | | user_id | INT | Yes | false | NULL | NONE |
| | | | | | | | |
| advertiser_uv | AGG_KEYS | advertiser | VARCHAR(10) | Yes | true | NULL | |
| | | channel | VARCHAR(10) | Yes | true | NULL | |
| | | to_bitmap(`user_id`) | BITMAP | No | false | | BITMAP_UNION |
+------------------------+---------------+----------------------+-------------+------+-------+---------+--------------+
2.6.2 自动查询匹配
当创建物化视图表时,在查询广告UV时,Doris将自动从刚刚创建的物化视图advertiser_uv中查询数据。例如,原来的查询语句如下:
SELECT advertiser, channel, count(distinct user_id)
FROM advertiser_view_record
GROUP BY advertiser, channel;
选择物化视图后,实际查询将转换为:
SELECT advertiser, channel, bitmap_union_count(to_bitmap(user_id))
FROM advertiser_uv
GROUP BY advertiser, channel;
通过EXPLAIN命令可以检查Doris是否匹配物化视图:
mysql [test]>explain SELECT advertiser, channel, count(distinct user_id) FROM advertiser_view_record GROUP BY advertiser, channel;
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Explain String |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS: |
| <slot 9> `default_cluster:test`.`advertiser_view_record`.`mv_advertiser` |
| <slot 10> `default_cluster:test`.`advertiser_view_record`.`mv_channel` |
| <slot 11> bitmap_union_count(`default_cluster:test`.`advertiser_view_record`.`mva_BITMAP_UNION__to_bitmap_with_check(`user_id`)`) |
| PARTITION: UNPARTITIONED |
| |
| VRESULT SINK |
| |
| 4:VEXCHANGE |
| offset: 0 |
| |
| PLAN FRAGMENT 1 |
| |
| PARTITION: HASH_PARTITIONED: <slot 6> `default_cluster:test`.`advertiser_view_record`.`mv_advertiser`, <slot 7> `default_cluster:test`.`advertiser_view_record`.`mv_channel` |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 04 |
| UNPARTITIONED |
| |
| 3:VAGGREGATE (merge finalize) |
| | output: bitmap_union_count(<slot 8> bitmap_union_count(`default_cluster:test`.`advertiser_view_record`.`mva_BITMAP_UNION__to_bitmap_with_check(`user_id`)`)) |
| | group by: <slot 6> `default_cluster:test`.`advertiser_view_record`.`mv_advertiser`, <slot 7> `default_cluster:test`.`advertiser_view_record`.`mv_channel` |
| | cardinality=-1 |
| | |
| 2:VEXCHANGE |
| offset: 0 |
| |
| PLAN FRAGMENT 2 |
| |
| PARTITION: HASH_PARTITIONED: `default_cluster:test`.`advertiser_view_record`.`time` |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 02 |
| HASH_PARTITIONED: <slot 6> `default_cluster:test`.`advertiser_view_record`.`mv_advertiser`, <slot 7> `default_cluster:test`.`advertiser_view_record`.`mv_channel` |
| |
| 1:VAGGREGATE (update serialize) |
| | STREAMING |
| | output: bitmap_union_count(`default_cluster:test`.`advertiser_view_record`.`mva_BITMAP_UNION__to_bitmap_with_check(`user_id`)`) |
| | group by: `default_cluster:test`.`advertiser_view_record`.`mv_advertiser`, `default_cluster:test`.`advertiser_view_record`.`mv_channel` |
| | cardinality=-1 |
| | |
| 0:VOlapScanNode |
| TABLE: default_cluster:test.advertiser_view_record(advertiser_uv), PREAGGREGATION: ON |
| partitions=1/1, tablets=10/10, tabletList=50075,50077,50079 ... |
| cardinality=0, avgRowSize=48.0, numNodes=1 |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
在EXPLAIN的结果中,您首先可以看到VOlapScanNode命中了advertiser_uv。也就是说,查询直接扫描物化视图的数据。匹配成功。
其次,user_id字段的count(distinct)计算被重写为bitmap_union_count。即通过位图实现精确重复数据删除的效果。
2.7 最佳实践3
业务场景:匹配更丰富的前缀索引
用户的原始表有三列(k1、k2、k3)。其中,k1、k2为前缀索引列。此时,如果用户查询条件中包含where k1=a and k2=b,则可以通过索引加速查询。
但是在某些情况下,用户的过滤条件不能匹配前缀索引,例如k3=c。这样就不能通过索引来提高查询速度。
这个问题可以通过创建一个以k3为第一列的物化视图来解决。
2.7.1 创建一个物化视图
CREATE MATERIALIZED VIEW mv_1 as
SELECT k3, k2, k1
FROM tableA
ORDER BY k3;
上述语法创建完成后,完整的细节数据保留在物化视图中,物化视图的前缀索引为k3列。表结构如下:
MySQL [test]> desc tableA all;
+-----------+---------------+-------+------+------+-------+---------+-------+
| IndexName | IndexKeysType | Field | Type | Null | Key | Default | Extra |
+-----------+---------------+-------+------+------+-------+---------+-------+
| tableA | DUP_KEYS | k1 | INT | Yes | true | NULL | |
| | | k2 | INT | Yes | true | NULL | |
| | | k3 | INT | Yes | true | NULL | |
| | | | | | | | |
| mv_1 | DUP_KEYS | k3 | INT | Yes | true | NULL | |
| | | k2 | INT | Yes | false | NULL | NONE |
| | | k1 | INT | Yes | false | NULL | NONE |
+-----------+---------------+-------+------+------+-------+---------+-------+
2.7.2 查询匹配
此时,如果用户的查询有k3列,则过滤条件为,例如:
select k1, k2, k3 from table A where k3=1;
此时,查询将直接从刚刚创建的mv_1物化视图读取数据。物化视图在k3上有一个前缀索引,查询效率也得到了提高。
2.8 最佳实践4
在Doris 2.0中,我们对物化视图支持的表达式做了一些增强。这个例子将主要反映新版本的物化视图对各种表达式的支持和早期过滤。
2.8.1 创建一个基表并插入一些数据。
create table d_table (
k1 int null,
k2 int not null,
k3 bigint null,
k4 date null
)
duplicate key (k1,k2,k3)
distributed BY hash(k1) buckets 3
properties("replication_num" = "1");
insert into d_table select 1,1,1,'2020-02-20';
insert into d_table select 2,2,2,'2021-02-20';
insert into d_table select 3,-3,null,'2022-02-20';
2.8.2 创建一些物化视图。
create materialized view k1a2p2ap3ps as
select abs(k1)+k2+1,sum(abs(k2+2)+k3+3)
from d_table
group by abs(k1)+k2+1;
create materialized view kymd as
select year(k4),month(k4)
from d_table
where year(k4) = 2020; // Filter with where expression in advance to reduce the amount of data in the materialized view.
2.8.3 使用一些查询来测试是否成功命中物化视图。
select abs(k1)+k2+1, sum(abs(k2+2)+k3+3) from d_table group by abs(k1)+k2+1; // hit k1a2p2ap3ps
select bin(abs(k1)+k2+1), sum(abs(k2+2)+k3+3) from d_table group by bin(abs(k1)+k2+1); // hit k1a2p2ap3ps
select year(k4),month(k4),day(k4) from d_table; // cannot hit the materialized view because the where condition does not match
select year(k4)+month(k4) from d_table where year(k4) = 2020; // hit kymd
限制
- 如果物化视图中不存在delete语句的condition列,则不能执行删除操作。如果需要删除数据,请先删除物化视图,再删除数据。
- 单个表上太多的物化视图将影响导入的效率:当导入数据时物化视图和基表数据将同步更新。如果一个表有超过10个物化视图,导入速度可能会很慢。缓慢。这就好像一个导入需要同时导入10个表数据一样。
- 对于Unique Key数据模型,物化视图只能更改列的顺序,不能执行聚合。因此,不可能通过在Unique Key模型上创建物化视图来对数据执行粗粒度聚合操作。
- 目前,一些优化器对SQL的重写行为可能会导致无法命中物化视图。例如,
k1+1-1改写为k1, between改写为<=and>=,day改写为dayofmonth。此时需要手动调整查询和物化视图的语句。
3、异步物化视图
3.1 物化视图的构建和维护
3.1.1 创建物化视图
准备两个表和数据:
use tpch;
CREATE TABLE IF NOT EXISTS orders (
o_orderkey integer not null,
o_custkey integer not null,
o_orderstatus char(1) not null,
o_totalprice decimalv3(15,2) not null,
o_orderdate date not null,
o_orderpriority char(15) not null,
o_clerk char(15) not null,
o_shippriority integer not null,
o_comment varchar(79) not null
)
DUPLICATE KEY(o_orderkey, o_custkey)
PARTITION BY RANGE(o_orderdate)(
FROM ('2023-10-17') TO ('2023-10-20') INTERVAL 1 DAY)
DISTRIBUTED BY HASH(o_orderkey) BUCKETS 3
PROPERTIES ("replication_num" = "1");
insert into orders values
(1, 1, 'ok', 99.5, '2023-10-17', 'a', 'b', 1, 'yy'),
(2, 2, 'ok', 109.2, '2023-10-18', 'c','d',2, 'mm'),
(3, 3, 'ok', 99.5, '2023-10-19', 'a', 'b', 1, 'yy');
CREATE TABLE IF NOT EXISTS lineitem (
l_orderkey integer not null,
l_partkey integer not null,
l_suppkey integer not null,
l_linenumber integer not null,
l_quantity decimalv3(15,2) not null,
l_extendedprice decimalv3(15,2) not null,
l_discount decimalv3(15,2) not null,
l_tax decimalv3(15,2) not null,
l_returnflag char(1) not null,
l_linestatus char(1) not null,
l_shipdate date not null,
l_commitdate date not null,
l_receiptdate date not null,
l_shipinstruct char(25) not null,
l_shipmode char(10) not null,
l_comment varchar(44) not null
)
DUPLICATE KEY(l_orderkey, l_partkey, l_suppkey, l_linenumber)
PARTITION BY RANGE(l_shipdate)
(FROM ('2023-10-17') TO ('2023-10-20') INTERVAL 1 DAY)
DISTRIBUTED BY HASH(l_orderkey) BUCKETS 3
PROPERTIES ("replication_num" = "1");
insert into lineitem values
(1, 2, 3, 4, 5.5, 6.5, 7.5, 8.5, 'o', 'k', '2023-10-17', '2023-10-17', '2023-10-17', 'a', 'b', 'yyyyyyyyy'),
(2, 2, 3, 4, 5.5, 6.5, 7.5, 8.5, 'o', 'k', '2023-10-18', '2023-10-18', '2023-10-18', 'a', 'b', 'yyyyyyyyy'),
(3, 2, 3, 6, 7.5, 8.5, 9.5, 10.5, 'k', 'o', '2023-10-19', '2023-10-19', '2023-10-19', 'c', 'd', 'xxxxxxxxx');
创建物化视图
CREATE MATERIALIZED VIEW mv1
BUILD DEFERRED REFRESH AUTO ON MANUAL
partition by(l_shipdate)
DISTRIBUTED BY RANDOM BUCKETS 2
PROPERTIES ('replication_num' = '1')
AS
select l_shipdate, o_orderdate, l_partkey, l_suppkey, sum(o_totalprice) as sum_total
from lineitem
left join orders on lineitem.l_orderkey = orders.o_orderkey and l_shipdate = o_orderdate
group by
l_shipdate,
o_orderdate,
l_partkey,
l_suppkey;
具体语法可以查看CREATE ASYNC MATERIALIZED VIEW
3.1.2 查看物化视图元信息
select * from mv_infos("database"="tpch") where Name="mv1";
物化视图的独特特性可以通过mv_info()查看。
与表相关的属性,仍然通过SHOW TABLES查看
3.1.3 刷新物化视图
物化视图支持不同的刷新策略,例如定时刷新和手动刷新。它还支持不同的刷新粒度,如完全刷新、分区粒度的增量刷新等。这里我们以手动刷新物化视图的部分分区为例。
首先,检查物化视图分区的列表
SHOW PARTITIONS FROM mv1;
刷新名为p_20231017_20231018的分区
REFRESH MATERIALIZED VIEW mv1 partitions(p_20231017_20231018);
具体的语法可以查看REFRESH MATERIALIZED VIEW
3.1.4 job管理
每个物化视图默认都有一个负责刷新数据的job,该job用于描述物化视图的刷新策略和其他信息。每次触发刷新时,都会生成一个job,task用于描述特定的刷新信息,例如刷新所用的时间、刷新了哪些分区等
在物化视图中查看job
select * from jobs("type"="mv") order by CreateTime;
具体的语法可查看jobs(“type”=“mv”)
暂停物化视图作业调度:
PAUSE MATERIALIZED VIEW JOB ON mv1;
具体的语法可查看PAUSE MATERIALIZED VIEW JOB
RESUME物化视图作业调度
RESUME MATERIALIZED VIEW JOB ON mv1;
具体语法可以查看RESUME MATERIALIZED VIEW JOB
在物化视图中查看tasks:
select * from tasks("type"="mv");
取消视图物化task
CANCEL MATERIALIZED VIEW TASK realTaskId on mv1;
具体的语法可以查看CANCEL MATERIALIZED VIEW TASK
3.1.5 修改物化视图
修改物化视图的属性:
ALTER MATERIALIZED VIEW mv1 set("grace_period"="3333");
修改物化视图的名称,物化视图的刷新方法,以及物化视图的唯一属性都可以通过 ALTER ASYNC MATERIALIZED VIEW
物化视图本身也是一个Table,因此与Table相关的属性(例如副本的数量)仍然可以通过与ALTER TABLE相关的语法进行修改。
3.1.6 删除物化视图
DROP MATERIALIZED VIEW mv1;
物化视图具有专用的删除语法,不能通过删除表删除。
DROP ASYNC MATERIALIZED VIEW
3.2 物化视图的使用
可以查看查询异步物化视图
注意
- 异步物化视图只支持在Nereids优化器中使用
- 当前判断物化视图和基表是否同步仅支持
OlapTable。对于其它外表,会直接认为是同步的。例如,物化视图的基表全是外表。在查询mv_infos()时,SyncWithBaseTables会永远为 1(true)。在刷新物化视图时需要手动刷新指定的分区或指定complete刷新全部分区。
4、查询异步物化视图
4.1 概述
Doris的异步物化视图采用了一种基于SPJG (SELECT-PROJECT-JOIN-GROUP-BY)模式结构信息的算法,用于透明重写。
Doris可以分析查询SQL的结构信息,自动搜索合适的物化视图,并尝试透明重写,利用最优的物化视图来表达查询SQL。
通过利用预先计算的物化视图结果,可以显著提高查询性能并降低计算成本。
使用来自TPC-H的三个表:lineitem、orders和partsupp,让我们描述直接查询物化视图和使用物化视图进行透明查询重写的功能。
CREATE TABLE IF NOT EXISTS lineitem (
l_orderkey integer not null,
l_partkey integer not null,
l_suppkey integer not null,
l_linenumber integer not null,
l_quantity decimalv3(15,2) not null,
l_extendedprice decimalv3(15,2) not null,
l_discount decimalv3(15,2) not null,
l_tax decimalv3(15,2) not null,
l_returnflag char(1) not null,
l_linestatus char(1) not null,
l_shipdate date not null,
l_commitdate date not null,
l_receiptdate date not null,
l_shipinstruct char(25) not null,
l_shipmode char(10) not null,
l_comment varchar(44) not null
)
DUPLICATE KEY(l_orderkey, l_partkey, l_suppkey, l_linenumber)
PARTITION BY RANGE(l_shipdate)
(FROM ('2023-10-17') TO ('2023-10-20') INTERVAL 1 DAY)
DISTRIBUTED BY HASH(l_orderkey) BUCKETS 3
PROPERTIES ("replication_num" = "1");
insert into lineitem values
(1, 2, 3, 4, 5.5, 6.5, 7.5, 8.5, 'o', 'k', '2023-10-17', '2023-10-17', '2023-10-17', 'a', 'b', 'yyyyyyyyy'),
(2, 4, 3, 4, 5.5, 6.5, 7.5, 8.5, 'o', 'k', '2023-10-18', '2023-10-18', '2023-10-18', 'a', 'b', 'yyyyyyyyy'),
(3, 2, 4, 4, 5.5, 6.5, 7.5, 8.5, 'o', 'k', '2023-10-19', '2023-10-19', '2023-10-19', 'a', 'b', 'yyyyyyyyy');
CREATE TABLE IF NOT EXISTS orders (
o_orderkey integer not null,
o_custkey integer not null,
o_orderstatus char(1) not null,
o_totalprice decimalv3(15,2) not null,
o_orderdate date not null,
o_orderpriority char(15) not null,
o_clerk char(15) not null,
o_shippriority integer not null,
o_comment varchar(79) not null
)
DUPLICATE KEY(o_orderkey, o_custkey)
PARTITION BY RANGE(o_orderdate)(
FROM ('2023-10-17') TO ('2023-10-20') INTERVAL 1 DAY)
DISTRIBUTED BY HASH(o_orderkey) BUCKETS 3
PROPERTIES ("replication_num" = "1");
insert into orders values
(1, 1, 'o', 9.5, '2023-10-17', 'a', 'b', 1, 'yy'),
(1, 1, 'o', 10.5, '2023-10-18', 'a', 'b', 1, 'yy'),
(2, 1, 'o', 11.5, '2023-10-19', 'a', 'b', 1, 'yy'),
(3, 1, 'o', 12.5, '2023-10-19', 'a', 'b', 1, 'yy');
CREATE TABLE IF NOT EXISTS partsupp (
ps_partkey INTEGER NOT NULL,
ps_suppkey INTEGER NOT NULL,
ps_availqty INTEGER NOT NULL,
ps_supplycost DECIMALV3(15,2) NOT NULL,
ps_comment VARCHAR(199) NOT NULL
)
DUPLICATE KEY(ps_partkey, ps_suppkey)
DISTRIBUTED BY HASH(ps_partkey) BUCKETS 3
PROPERTIES (
"replication_num" = "1"
);
insert into partsupp values
(2, 3, 9, 10.01, 'supply1'),
(4, 3, 10, 11.01, 'supply2'),
(2, 3, 10, 11.01, 'supply3');
4.2 直接查询物化视图
物化视图可以看作是一个表,并且可以像查询普通表一样进行查询。
定义物化视图的语法,详细信息可以在CREATE-ASYNC-MATERIALIZED-VIEW 中找到
物化视图定义:
CREATE MATERIALIZED VIEW mv1
BUILD IMMEDIATE REFRESH AUTO ON SCHEDULE EVERY 1 hour
DISTRIBUTED BY RANDOM BUCKETS 3
PROPERTIES ('replication_num' = '1')
AS
SELECT t1.l_linenumber,
o_custkey,
o_orderdate
FROM
(SELECT * FROM lineitem WHERE l_linenumber > 1) t1
LEFT OUTER JOIN orders ON l_orderkey = o_orderkey;
查询语句:可以对具有附加过滤条件和聚合的物化视图执行直接查询。
SELECT l_linenumber,
o_custkey
FROM mv1
WHERE l_linenumber > 1 and o_orderdate = '2023-12-31';
4.3 透明重写功能
4.3.1 Join rewriting
连接重写指的是查询和物化中使用的表是相同的。在这种情况下,优化器将尝试透明重写,要么将物化视图的输入与查询连接起来,要么将连接放在查询的WHERE子句的外层。
这种重写模式支持多表连接,支持的连接类型如下:
- INNER JOIN
- LEFT OUTER JOIN
- RIGHT OUTER JOIN
- FULL OUTER JOIN
- LEFT SEMI JOIN
- RIGHT SEMI JOIN
- LEFT ANTI JOIN
- RIGHT ANTI JOIN
例1:
下面的情况可以进行透明的重写。条件l_linenumber > 1允许上拉,通过使用物化视图的预计算结果来表达查询,从而实现透明重写。
CREATE MATERIALIZED VIEW mv2
BUILD IMMEDIATE REFRESH AUTO ON SCHEDULE EVERY 1 hour
DISTRIBUTED BY RANDOM BUCKETS 3
PROPERTIES ('replication_num' = '1')
AS
SELECT t1.l_linenumber,
o_custkey,
o_orderdate
FROM (SELECT * FROM lineitem WHERE l_linenumber > 1) t1
LEFT OUTER JOIN orders
ON l_orderkey = o_orderkey;
查询语句:
SELECT l_linenumber,
o_custkey
FROM lineitem
LEFT OUTER JOIN orders
ON l_orderkey = o_orderkey
WHERE l_linenumber > 1 and o_orderdate = '2023-10-18';
Case 2:
当查询和物化视图之间的连接类型不匹配时,将发生JOIN派生。在物化可以提供查询所需的所有数据的情况下,仍然可以通过下推谓词补偿连接外部的谓词来实现透明重写。
例如:
物化视图定义:
CREATE MATERIALIZED VIEW mv3
BUILD IMMEDIATE REFRESH AUTO ON SCHEDULE EVERY 1 hour
DISTRIBUTED BY RANDOM BUCKETS 3
PROPERTIES ('replication_num' = '1')
AS
SELECT
l_shipdate, l_suppkey, o_orderdate
sum(o_totalprice) AS sum_total,
max(o_totalprice) AS max_total,
min(o_totalprice) AS min_total,
count(*) AS count_all,
count(distinct CASE WHEN o_shippriority > 1 AND o_orderkey IN (1, 3) THEN o_custkey ELSE null END) AS bitmap_union_basic
FROM lineitem
LEFT OUTER JOIN orders ON lineitem.l_orderkey = orders.o_orderkey AND l_shipdate = o_orderdate
GROUP BY
l_shipdate,
l_suppkey,
o_orderdate;
查询语句:
SELECT
l_shipdate, l_suppkey, o_orderdate,
sum(o_totalprice) AS sum_total,
max(o_totalprice) AS max_total,
min(o_totalprice) AS min_total,
count(*) AS count_all,
count(distinct CASE WHEN o_shippriority > 1 AND o_orderkey IN (1, 3) THEN o_custkey ELSE null END) AS bitmap_union_basic
FROM lineitem
INNER JOIN orders ON lineitem.l_orderkey = orders.o_orderkey AND l_shipdate = o_orderdate
WHERE o_orderdate = '2023-10-18' AND l_suppkey = 3
GROUP BY
l_shipdate,
l_suppkey,
o_orderdate;
4.3.2 Aggregate rewriting
在查询和物化视图的定义中,聚合的维度可以是一致的,也可以是不一致的。可以通过在WHERE子句中使用维度中的字段来过滤结果。
物化视图中使用的维度需要包含查询中使用的维度,查询中使用的度量可以使用物化视图的度量来表示。
Case 1:
下面的情况可以进行透明的重写。查询和物化视图使用一致的维度进行聚合,从而允许使用维度中的字段来过滤结果。查询将尝试在物化视图中使用SELECT后的表达式。
物化视图定义:
CREATE MATERIALIZED VIEW mv4
BUILD IMMEDIATE REFRESH AUTO ON SCHEDULE EVERY 1 hour
DISTRIBUTED BY RANDOM BUCKETS 3
PROPERTIES ('replication_num' = '1')
AS
SELECT
o_shippriority, o_comment,
count(distinct CASE WHEN o_shippriority > 1 AND o_orderkey IN (1, 3) THEN o_custkey ELSE null END) AS cnt_1,
count(distinct CASE WHEN O_SHIPPRIORITY > 2 AND o_orderkey IN (2) THEN o_custkey ELSE null END) AS cnt_2,
sum(o_totalprice),
max(o_totalprice),
min(o_totalprice),
count(*)
FROM orders
GROUP BY
o_shippriority,
o_comment;
查询:
SELECT
o_shippriority, o_comment,
count(distinct CASE WHEN o_shippriority > 1 AND o_orderkey IN (1, 3) THEN o_custkey ELSE null END) AS cnt_1,
count(distinct CASE WHEN O_SHIPPRIORITY > 2 AND o_orderkey IN (2) THEN o_custkey ELSE null END) AS cnt_2,
sum(o_totalprice),
max(o_totalprice),
min(o_totalprice),
count(*)
FROM orders
WHERE o_shippriority in (1, 2)
GROUP BY
o_shippriority,
o_comment;
Case 2:
可以透明地重写以下查询:查询和实体化使用不一致的聚合维度,但物化视图中使用的维度包含查询中使用的维度。查询可以使用维度中的字段过滤结果。
查询将尝试使用SELECT之后的函数进行上卷,例如物化视图的bitmap_union最终将上卷为bitmap_union_count,从而与查询中的计数(distinct)的语义保持一致。
物化视图定义:
CREATE MATERIALIZED VIEW mv5
BUILD IMMEDIATE REFRESH AUTO ON SCHEDULE EVERY 1 hour
DISTRIBUTED BY RANDOM BUCKETS 3
PROPERTIES ('replication_num' = '1')
AS
SELECT
l_shipdate, o_orderdate, l_partkey, l_suppkey,
sum(o_totalprice) AS sum_total,
max(o_totalprice) AS max_total,
min(o_totalprice) AS min_total,
count(*) AS count_all,
bitmap_union(to_bitmap(CASE WHEN o_shippriority > 1 AND o_orderkey IN (1, 3) THEN o_custkey ELSE null END)) AS bitmap_union_basic
FROM lineitem
LEFT OUTER JOIN orders ON lineitem.l_orderkey = orders.o_orderkey AND l_shipdate = o_orderdate
GROUP BY
l_shipdate,
o_orderdate,
l_partkey,
l_suppkey;
查询语句:
SELECT
l_shipdate, l_suppkey,
sum(o_totalprice) AS sum_total,
max(o_totalprice) AS max_total,
min(o_totalprice) AS min_total,
count(*) AS count_all,
count(distinct CASE WHEN o_shippriority > 1 AND o_orderkey IN (1, 3) THEN o_custkey ELSE null END) AS bitmap_union_basic
FROM lineitem
LEFT OUTER JOIN orders ON lineitem.l_orderkey = orders.o_orderkey AND l_shipdate = o_orderdate
WHERE o_orderdate = '2023-10-18' AND l_partkey = 3
GROUP BY
l_shipdate,
l_suppkey;
对聚合上卷函数的临时支持如下:
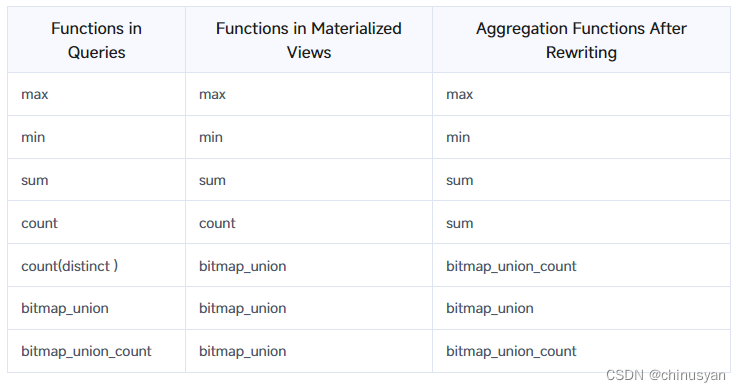
4.4 查询部分透明重写(即将推出)
当物化视图中的表数量大于查询时,如果物化视图满足对多于查询的表进行JOIN消除的条件,则还可以进行透明重写。例如:
物化视图定义:
CREATE MATERIALIZED VIEW mv6
BUILD IMMEDIATE REFRESH AUTO ON SCHEDULE EVERY 1 hour
DISTRIBUTED BY RANDOM BUCKETS 3
PROPERTIES ('replication_num' = '1')
AS
SELECT
l_linenumber,
o_custkey,
ps_availqty
FROM lineitem
LEFT OUTER JOIN orders ON L_ORDERKEY = O_ORDERKEY
LEFT OUTER JOIN partsupp ON l_partkey = ps_partkey
AND l_suppkey = ps_suppkey;
查询语句:
SELECT
l_linenumber,
o_custkey,
ps_availqty
FROM lineitem
LEFT OUTER JOIN orders ON L_ORDERKEY = O_ORDERKEY;
4.5 Union Rewriting (Coming soon)
当物化视图不足以为查询提供所有数据时,它可以通过组合原始表和物化视图来使用Union返回数据。例如:
物化视图定义:
CREATE MATERIALIZED VIEW mv7
BUILD IMMEDIATE REFRESH AUTO ON SCHEDULE EVERY 1 hour
DISTRIBUTED BY RANDOM BUCKETS 3
PROPERTIES ('replication_num' = '1')
AS
SELECT
o_orderkey,
o_custkey,
o_orderstatus,
o_totalprice
FROM orders
WHERE o_orderkey > 10;
查询语句:
SELECT
o_orderkey,
o_custkey,
o_orderstatus,
o_totalprice
FROM orders
WHERE o_orderkey > 5;
修改结果:
SELECT *
FROM mv
UNION ALL
SELECT
o_orderkey,
o_custkey,
o_orderstatus,
o_totalprice
FROM orders
WHERE o_orderkey > 5 AND o_orderkey <= 10;
4.6 附加功能
透明重写后的数据一致性问题
grace_period的单位是秒,指的是物化视图和底层基表中的数据不一致所允许的时间。
例如,将grace_period设置为0意味着需要物化视图与基表数据保持一致,然后才能将其用于透明重写。至于外部表,由于无法感知数据的更改,因此将物化视图与它们一起使用。不管外部表中的数据是否是最新的,这个物化视图都可以用于透明重写。如果外部表配置了HMS元数据源,它就能够感知数据更改。配置元数据源和启用数据更改感知功能将在后续迭代中得到支持。
将grace_period设置为10意味着在物化视图中的数据和基表中的数据之间允许10秒的延迟。如果在物化视图中的数据和基表中的数据之间存在最多10秒的延迟,那么物化视图仍然可以在该时间范围内用于透明重写。
对于物化视图中的内部表,您可以通过设置grace_period属性来控制透明重写所使用的数据的最大延迟。参考CREATE-ASYNC-MATERIALIZED-VIEW
查看和调试透明重写命中信息
您可以使用以下语句查看物化视图透明重写的命中信息。它将显示透明重写过程的简明概述。
explain <query_sql>返回的信息如下,提取物化视图的相关信息:
| MaterializedView |
| MaterializedViewRewriteSuccessAndChose: |
| Names: mv5 |
| MaterializedViewRewriteSuccessButNotChose: |
| |
| MaterializedViewRewriteFail: |
| Name: mv4 |
| FailSummary: Match mode is invalid, View struct info is invalid |
| Name: mv3 |
| FailSummary: Match mode is invalid, Rewrite compensate predicate by view fail, View struct info is invalid |
| Name: mv1 |
| FailSummary: The columns used by query are not in view, View struct info is invalid |
| Name: mv2 |
| FailSummary: The columns used by query are not in view, View struct info is invalid
MaterializedViewRewriteSuccessAndChose: 透明重写成功,由CBO选择的物化视图名称列表。
MaterializedViewRewriteSuccessButNotChose: 透明重写成功,但最终CBO没有选择物化视图名称列表。
MaterializedViewRewriteFail: 列出透明的重写失败并总结原因。
如果您想知道关于物化视图候选、重写和最终选择过程的详细信息,您可以执行以下语句。它将提供透明重写过程的详细分解。
explain memo plan <query_sql>
4.7 相关环境变量
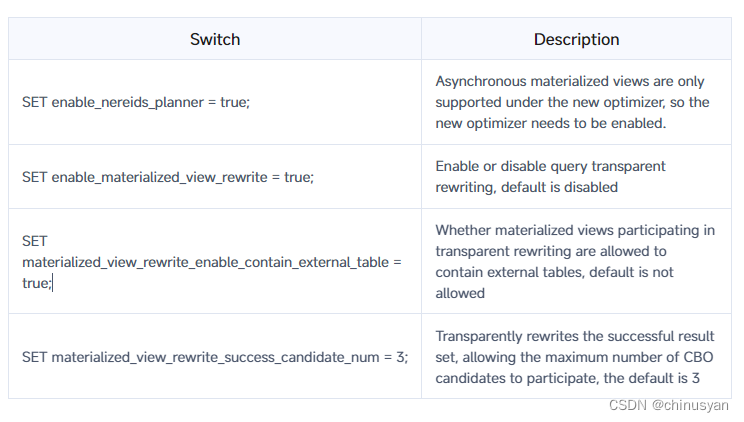
4.8 限制
- 物化视图定义语句只允许
SELECT、FROM、WHERE、JOIN和GROUP BY子句。JOIN的输入可以包括简单的GROUP BY(对单个表进行聚合)。支持的JOIN操作类型包括INNER和LEFT OUTER JOIN。对其他类型JOIN操作的支持将逐渐增加。 - 基于外部表的物化视图不能保证查询结果的强一致性。
- 不支持使用非确定性函数来构建物化视图,包括
rand,now,current_time,current_date,random,uuid等。 - 透明重写不支持窗口函数。
- 查询和物化视图中存在
LIMIT,并且暂时不支持透明重写。 - 目前,物化视图定义不能利用视图或其他物化视图。
- 当查询或物化视图没有数据时,不支持透明重写。
- 目前,
WHERE子句补偿支持以下场景:物化视图没有WHERE子句,但查询有,或者物化视图有WHERE子句,而查询的WHERE子句是物化视图的超集。范围条件补偿目前还不支持,但将逐渐增加。



![[保姆级教程]在uniapp中使用vant框架](https://img-blog.csdnimg.cn/direct/e25eca52e58b46b7be63d5b529004fe6.png)