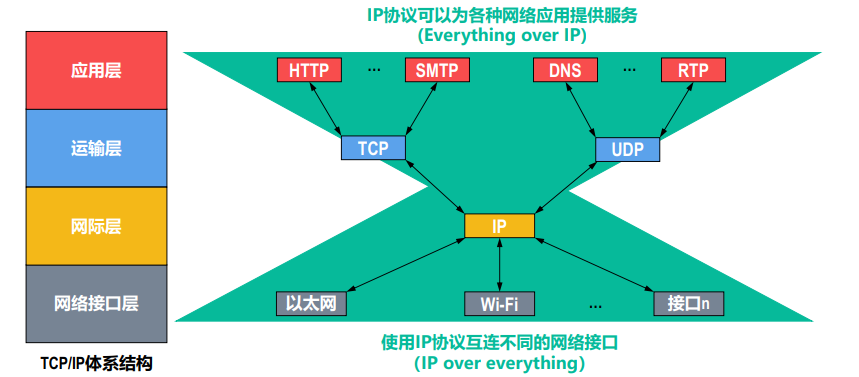
llamaIndex 做索引是默认存在内存中,由于索引需要通过网络调用 API,而且索引是比较耗时的操作,为了避免每次都进行索引,使用向量数据库进行 Embedding 存储以提高效率。首先将 Document 解析成 Node,索引时调用 Embedding API 生成 Node 的 Embedding 并存入 Chroma 向量数据,以便后续查询方便。
本文使用的 JinaAI的 Embedding Model,Document 解析 Node 用的是默认方式,按段落、句子进行切分,对于纯文本这样处理是可以,如果有图和表格,就要选用其他的策略。要注意的点是,如果不指定 Chroma Embedding 的模型, 默认使用的是 all-MiniLM-L6-v2 Embedding 模型,这样就会导致搜索时数据非常不准确,topk 都出不来。相似度算法设置为 Cosine,Chroma 默认的算法是 L2。
代码中使用的文档是官方的例子,paul_graham_essay.txt,代码只做了 Retrieve 这步,这步是 RAG 的核心。如果用中文把模型改成 cn 既可,JinaAI 这个 Embedding 模型,Ollama 也提供,如果需要大量索引,可以在本地搭建一个,JinaAI 免费 Token 数有限。
import chromadb
from llama_index.embeddings.jinaai import JinaEmbedding
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.core import StorageContext
from llama_index.core import Settings
from chromadb.utils import embedding_functions
## 访问 https://jina.ai 直接获取 API key
jinaai_api_key = "xxxx"
embed_model = JinaEmbedding(
api_key=jinaai_api_key,
model="jina-embeddings-v2-base-en",
)
documents = SimpleDirectoryReader("./data").load_data()
db = chromadb.PersistentClient(path="./chroma_db")
# create collection
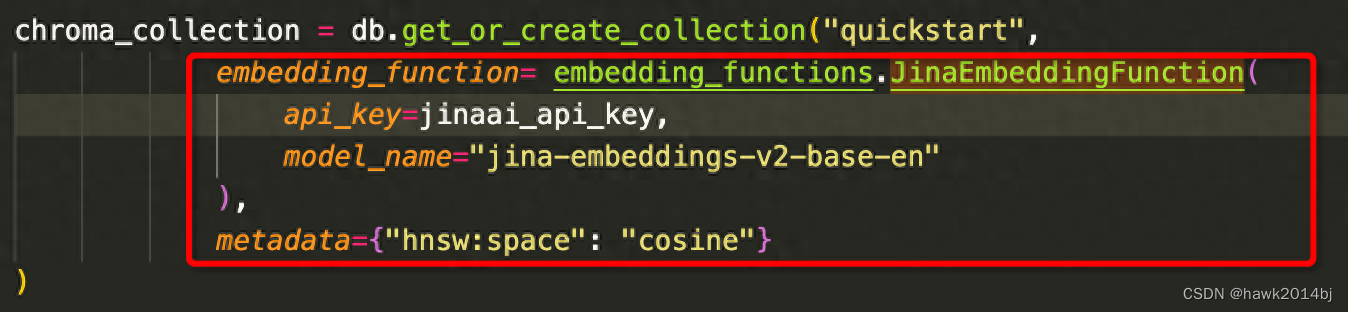
chroma_collection = db.get_or_create_collection("quickstart",
embedding_function= embedding_functions.JinaEmbeddingFunction(
api_key=jinaai_api_key,
model_name="jina-embeddings-v2-base-en"
),
metadata={"hnsw:space": "cosine"}
)
# assign chroma as the vector_store to the context
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
Settings.embed_model = embed_model
# create your index
index = VectorStoreIndex.from_documents(
documents, show_progress=True, storage_context=storage_context
)
search_query_retriever = index.as_retriever(similarity_top_k=5)
nodes = search_query_retriever.retrieve("what programming lanugage author used?")
print(len(nodes))