Apache Sqoop 是一个开源工具,用于在 Apache Hadoop 和关系型数据库(如 MySQL、Oracle、PostgreSQL 等)之间高效传输数据。Sqoop 可以将结构化数据从关系型数据库导入到 Hadoop 的 HDFS、Hive 和 HBase 中,也可以将数据从 Hadoop 导出到关系型数据库。

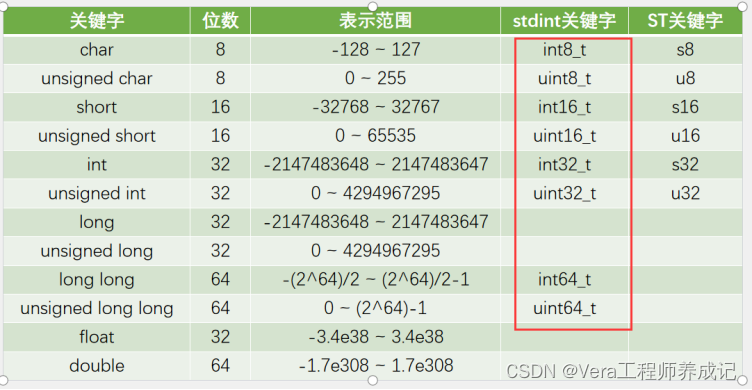
1、架构
Sqoop 的架构主要由以下几个部分组成:
- 客户端(Client):用户通过命令行或脚本向 Sqoop 提交导入/导出任务。
- 连接器(Connector):用于连接不同类型的关系型数据库,提供数据访问和操作接口。每种数据库类型对应一个连接器。
- MapReduce 框架:Sqoop 利用 Hadoop MapReduce 框架实现数据的并行导入和导出。
- 元数据存储:Sqoop 存储和管理任务的元数据,如任务配置、执行状态等。
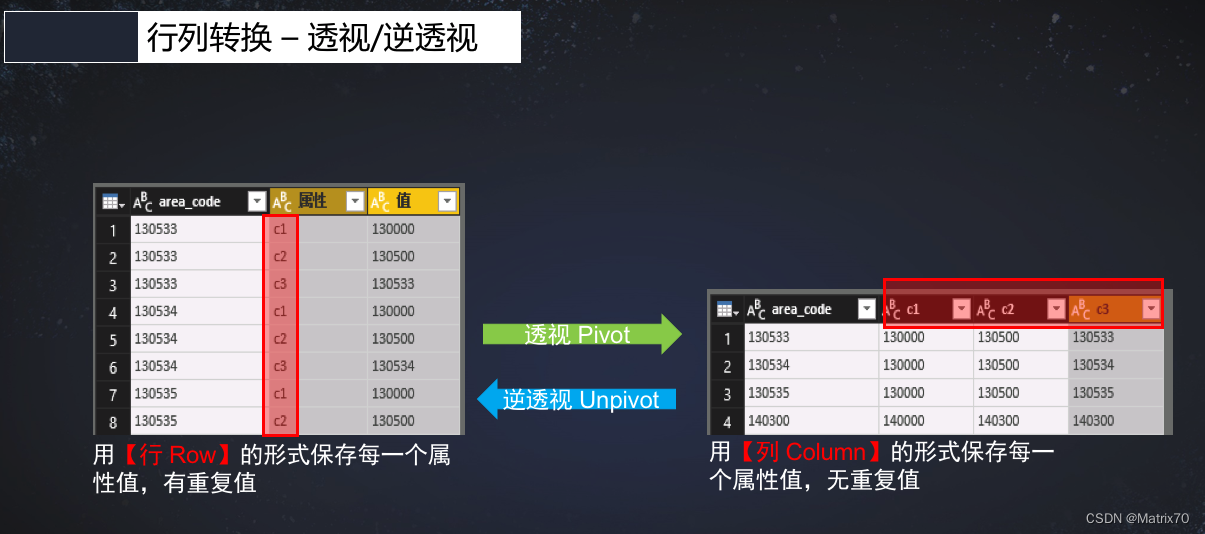
架构图如下:
+--------------------+
| Sqoop |
| +----------------+ |
| | Client | |
| +----------------+ |
| +----------------+ |
| | Connector | |
| +----------------+ |
| +----------------+ |
| | MapReduce Jobs | |
| +----------------+ |
+--------------------+
2、 基本工作流程
Sqoop 的数据导入和导出流程如下:
-
导入数据(Import):
- 用户在客户端提交导入命令,指定数据库连接信息和目标 HDFS 位置。
- Sqoop 解析命令并生成相应的 MapReduce 作业。
- MapReduce 作业并行读取数据库表的数据,将数据导入到 HDFS、Hive 或 HBase 中。
-
导出数据(Export):
- 用户在客户端提交导出命令,指定 HDFS 数据源和目标数据库。
- Sqoop 解析命令并生成相应的 MapReduce 作业。
- MapReduce 作业并行读取 HDFS 上的数据,将数据导出到关系型数据库表中。
3、使用场景
Sqoop 适用于以下几种常见的使用场景:
- 数据仓库构建:将关系型数据库中的数据导入到 Hadoop HDFS 或 Hive 中,便于大数据分析和处理。
- 数据备份和迁移:在不同的数据库系统之间迁移数据,或将数据从 Hadoop 导出到关系型数据库进行备份。
- 数据整合:将来自多个数据源的数据导入到 Hadoop 进行整合和分析。
4、优越点
Sqoop 作为一种数据同步工具,具有以下优越点:
- 高效并行处理:利用 Hadoop MapReduce 框架实现数据的并行处理,提高数据导入和导出的效率。
- 广泛的数据库支持:内置多种数据库连接器,支持主流的关系型数据库,如 MySQL、Oracle、PostgreSQL 等。
- 灵活的数据传输:支持多种数据传输方式,可以将数据导入到 HDFS、Hive、HBase 中,也可以将数据导出到关系型数据库。
- 增量导入:支持基于时间戳或自增列的增量导入,只导入新增加或更新的数据,减少数据传输量。
- 简单易用:通过简单的命令行接口,用户可以方便地定义和执行数据同步任务。
- 集成性好:与 Hadoop 生态系统的其他组件(如 Hive、HBase)无缝集成,便于在大数据平台上进行数据处理和分析。
5、安装部署
安装 Apache Sqoop 需要以下几个步骤,包括下载、安装、配置以及测试。以下是详细的安装流程:
1. 前提条件
在安装 Sqoop 之前,需要确保以下软件已经安装并配置:
- Java:Sqoop 需要 JDK 6 或更高版本。可以通过以下命令检查 Java 版本:
java -version - Hadoop:Sqoop 需要 Hadoop 环境。确保 Hadoop 已经正确安装并配置好 HDFS。
2. 下载 Sqoop
从 Apache Sqoop 的官方网站下载最新的稳定版本。可以使用 wget 命令下载:
wget https://downloads.apache.org/sqoop/1.4.7/sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
你也可以访问 Apache Sqoop 下载页面 选择合适的版本进行下载。
3. 解压 Sqoop
下载完成后,解压 Sqoop 压缩包到你希望安装的目录:
tar -xzf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
mv sqoop-1.4.7.bin__hadoop-2.6.0 /usr/local/sqoop
4. 配置环境变量
将 Sqoop 的 bin 目录添加到系统的 PATH 环境变量中。编辑 ~/.bashrc 文件:
nano ~/.bashrc
在文件末尾添加以下行:
export SQOOP_HOME=/usr/local/sqoop
export PATH=$PATH:$SQOOP_HOME/bin
保存并关闭文件后,执行以下命令使环境变量生效:
source ~/.bashrc
5. 配置 Sqoop
编辑 Sqoop 的配置文件 sqoop-env.sh,位于 $SQOOP_HOME/conf 目录下:
cd $SQOOP_HOME/conf
cp sqoop-env-template.sh sqoop-env.sh
nano sqoop-env.sh
在 sqoop-env.sh 文件中,配置 Hadoop 和 HBase 的相关环境变量:
# Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/usr/local/hadoop
# Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/usr/local/hadoop
# Set the path to where bin/hbase is available
# export HBASE_HOME=/usr/local/hbase
# Set the path to where bin/hive is available
# export HIVE_HOME=/usr/local/hive
# Set the path for where zookeper config dir is
# export ZOOCFGDIR=/usr/local/zookeeper
根据你的 Hadoop 安装目录设置 HADOOP_COMMON_HOME 和 HADOOP_MAPRED_HOME。
6. 安装 JDBC 驱动
Sqoop 需要适当的 JDBC 驱动程序与各种数据库进行通信。下载所需的 JDBC 驱动并将其放入 Sqoop 的 lib 目录。例如,若要连接 MySQL 数据库:
wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-8.0.26.tar.gz
tar -xzf mysql-connector-java-8.0.26.tar.gz
cp mysql-connector-java-8.0.26/mysql-connector-java-8.0.26.jar $SQOOP_HOME/lib
7. 测试安装
安装完成后,可以通过以下命令测试 Sqoop 是否正确安装:
sqoop version
如果输出 Sqoop 的版本信息,表示安装成功。
6、使用示例:同步 Mysql 数据到 Hive
下面是一个详细的通过 Sqoop 将 MySQL 数据同步到 Hive 表的案例,包括任务优化、参数传递,以及代码解释。
环境准备
- 安装 Sqoop:确保 Sqoop 已安装并正确配置。
- 配置 Hive:Hive 已安装并正确配置。
- MySQL 准备:确保 MySQL 数据库和表已经创建,并且可以通过网络访问。
MySQL 数据库示例
假设 MySQL 数据库 testdb 中有一个表 users,表结构如下:
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(50),
email VARCHAR(50),
created_at TIMESTAMP
);
Hive 表准备
在 Hive 中创建一个对应的表 users:
CREATE TABLE users (
id INT,
name STRING,
email STRING,
created_at TIMESTAMP
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
Sqoop 导入命令
以下是一个 Sqoop 导入命令的示例,包括任务优化和参数传递:
sqoop import \
--connect jdbc:mysql://localhost/testdb \
--username root \
--password password \
--table users \
--hive-import \
--hive-table users \
--split-by id \
--num-mappers 4 \
--fields-terminated-by ',' \
--lines-terminated-by '\n' \
--null-string '\\N' \
--null-non-string '\\N' \
--map-column-java id=Integer,name=String,email=String,created_at=Timestamp \
--verbose
参数解释
--connect jdbc:mysql://localhost/testdb:MySQL 数据库连接字符串。--username root和--password password:MySQL 的用户名和密码。--table users:MySQL 中要导入的表名。--hive-import:表示将数据导入到 Hive 中。--hive-table users:Hive 中的目标表名。--split-by id:指定用于数据分片的列,这里选择id列。--num-mappers 4:指定并行的 Mapper 数量,这里设置为 4。--fields-terminated-by ',':指定字段分隔符为逗号。--lines-terminated-by '\n':指定行分隔符为换行符。--null-string '\\N'和--null-non-string '\\N':指定 NULL 值的表示方式。--map-column-java:映射 Java 数据类型到 Hive 数据类型。--verbose:启用详细日志输出,便于调试。
任务优化
-
并行度优化:
- 使用
--num-mappers参数增加 Mapper 数量,以并行处理数据,提高导入速度。 - 选择一个合适的分片键(如
id),确保数据在 Mapper 之间均匀分布。
- 使用
-
数据分隔符:
- 使用
--fields-terminated-by和--lines-terminated-by参数,指定数据文件的字段和行分隔符,确保数据格式正确。
- 使用
-
NULL 值处理:
- 使用
--null-string和--null-non-string参数,明确表示 NULL 值,避免数据导入过程中出现问题。
- 使用
-
数据类型映射:
- 使用
--map-column-java参数,明确 MySQL 列到 Hive 列的数据类型映射,确保数据类型兼容。
- 使用
执行任务
在命令行执行上述 Sqoop 命令,将 MySQL 数据库 testdb 中的 users 表数据导入到 Hive 中的 users 表。
sqoop import \
--connect jdbc:mysql://localhost/testdb \
--username root \
--password password \
--table users \
--hive-import \
--hive-table users \
--split-by id \
--num-mappers 4 \
--fields-terminated-by ',' \
--lines-terminated-by '\n' \
--null-string '\\N' \
--null-non-string '\\N' \
--map-column-java id=Integer,name=String,email=String,created_at=Timestamp \
--verbose
通过上述步骤和优化策略,使用 Sqoop 可以高效地将 MySQL 数据同步到 Hive 表。Sqoop 提供了丰富的参数配置,用户可以根据具体需求进行优化和调整,确保数据同步任务高效稳定地执行。
7、性功优化
对 Sqoop 进行性能优化是确保数据导入和导出任务高效执行的关键。以下是一些常见的性能优化策略:
1. 增加并行度
MapReduce 并行度
- 增加 Mapper 数量:Sqoop 使用 MapReduce 框架并行处理数据传输任务。可以通过
--num-mappers参数增加 Mapper 数量,以提高数据传输速度。通常,Mapper 数量与目标数据库的分区数量相匹配。例如:--num-mappers 8 - 减少单个 Mapper 的数据量:确保每个 Mapper 处理的数据量适中,避免因单个 Mapper 处理数据过多而导致性能瓶颈。
分片机制
- 自定义分片键:使用
--split-by参数指定合适的分片键,确保数据在 Mapper 之间均匀分布。通常选择一个唯一且分布均匀的列作为分片键。例如:--split-by id
2. 优化数据库配置
索引和分区
- 创建索引:为分片键创建索引,提高数据检索速度。
- 使用分区:如果目标表是分区表,可以利用分区提高数据插入效率。
并发连接限制
- 增加数据库连接池大小:确保数据库能够处理足够的并发连接。对于 MySQL,可以调整
max_connections参数。
3. 调整 Sqoop 参数
批量导入
- 批量大小:使用
--batch和--batch-size参数设置批量导入模式,减少每次提交的事务数量。例如:--batch --batch-size 1000
JDBC 参数
- 自定义 JDBC 参数:通过
--driver参数指定数据库驱动,并配置适当的 JDBC 参数。例如,对于 MySQL,可以配置连接超时、字符编码等参数。
4. 优化网络和硬件资源
网络带宽
- 网络带宽:确保 Sqoop 服务器和数据库服务器之间有足够的网络带宽,避免网络成为瓶颈。
硬件资源
- 硬件配置:增加 Sqoop 服务器的 CPU、内存和磁盘 I/O 能力,确保足够的硬件资源支持高并发数据传输。
5. 数据库表设计
列存储
- 列存储格式:对于 Hive,可以使用列存储格式(如 ORC、Parquet),提高数据查询性能。
数据压缩
- 数据压缩:使用适当的压缩格式(如 Gzip、Snappy),减少数据传输量。
示例配置
以下是一个综合应用上述优化策略的 Sqoop 导入命令示例:
sqoop import \
--connect jdbc:mysql://localhost/testdb \
--username root \
--password password \
--table users \
--target-dir /user/hadoop/users \
--num-mappers 8 \
--split-by id \
--batch \
--batch-size 1000 \
--driver com.mysql.jdbc.Driver \
--fetch-size 1000 \
--direct \
--verbose
对 Sqoop 进行性能优化需要综合考虑并行度、数据库配置、网络和硬件资源等因素。通过合理调整 Mapper 数量、自定义分片键、优化数据库索引和分区、调整批量导入参数等策略,可以显著提高 Sqoop 数据传输任务的执行效率。此外,监控和分析任务执行情况,及时调整优化策略,也是保持 Sqoop 高效运行的关键。
总结
Sqoop 是一个功能强大、易于使用的数据同步工具,适用于多种数据传输和同步场景。其高效的并行处理能力、广泛的数据库支持和灵活的传输方式,使其成为 Hadoop 生态系统中不可或缺的一部分。通过 Sqoop,用户可以方便地在关系型数据库和 Hadoop 之间进行数据迁移和同步,有效支持大数据分析和处理。
![[SAP ABAP] 追加内表数据](https://img-blog.csdnimg.cn/direct/47730ae445c844d7b90b3ca829cb0874.png)