6月还有一周就要结束了,我们今天来总结2024年6月上半月发表的最重要的论文,重点介绍了计算机视觉领域的最新研究和进展。
Diffusion Models
1、Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation

LlamaGen,是一个新的图像生成模型,它将原始的大型语言模型的“下一个标记预测”范式应用于视觉生成领域。传统的自回归模型,如Llama,在视觉信号上没有归纳偏差,如果适当缩放,可以达到最先进的图像生成性能。论文LLM服务框架在优化图像生成模型的推理速度方面的有效性,并实现了326% - 414%的加速。
https://arxiv.org/abs/2406.06525
2、Margin-aware Preference Optimization for Aligning Diffusion Models without Reference

基于人类偏好的现代对齐技术,如RLHF和DPO,通常采用相对于参考模型的散度正则化来确保训练的稳定性。但这通常限制了模型在对齐过程中的灵活性,特别是当偏好数据和参考模型之间存在明显的分布差异时。
论文将重点放在最近的文本到图像扩散模型的对齐上,例如稳定扩散XL (SDXL),并发现由于视觉模式的非结构化性质,这种“参考不匹配”确实是对齐这些模型时的一个重要问题:例如,对特定风格方面的偏好很容易导致这种差异。
基于这一观察结果,提出了一种新的、记忆友好的扩散模型偏好对齐方法,该方法不依赖于任何参考模型,称为边缘感知偏好优化(MaPO)。
https://arxiv.org/abs/2406.06424
3、MLCM: Multistep Consistency Distillation of Latent Diffusion Model

将大型潜在扩散模型提炼成快速采样的模型正引起越来越多的研究兴趣。大多数现有的方法都面临着两难的境地,它们要么(i)依赖于不同采样预算的多个单独的蒸馏模型,要么(ii)以有限的(例如,2-4)和/或适度的采样步骤牺牲生成质量。
为了解决这些问题,论文将最近的多步一致性蒸馏(MCD)策略扩展到具有代表性的ldm,建立了用于低成本高质量图像合成的多步潜在一致性模型(MLCMs)方法。由于MCD的前景,MLCM可以作为各种采样步骤的统一模型。
https://arxiv.org/abs/2406.05768
4、AsyncDiff: Parallelizing Diffusion Models by Asynchronous Denoising

扩散模型因其在各种应用程序中的强大生成能力而引起了社区的极大兴趣。但是它们典型的多步顺序去噪特性导致了高累积延迟,从而排除了并行计算的可能性。
为了解决这个问题,论文引入了AsyncDiff,这是一个通用的即插即用加速方案,可以跨多个设备实现模型并行。我们的方法将繁琐的噪声预测模型分成多个组件,并将每个组件分配给不同的设备。
该策略显著降低了推理延迟,同时对生成质量的影响最小。具体来说,对于SD v2.1, AsyncDiff在四个NVIDIA A5000 gpu上实现了2.7倍的加速,CLIP分数仅略微降低0.38。
https://arxiv.org/abs/2406.06911
5、Simple and Effective Masked Diffusion Language Models
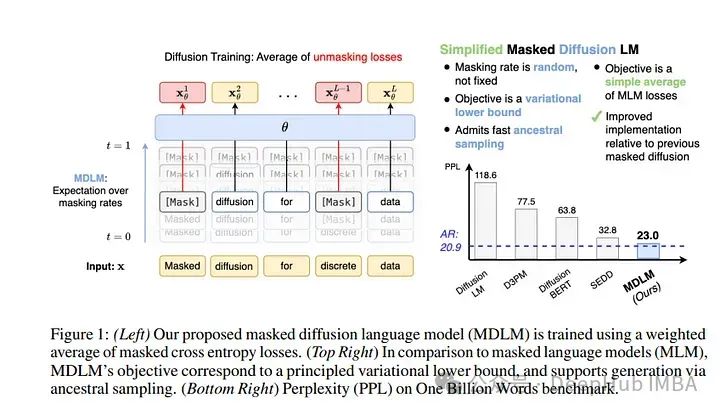
虽然扩散模型在生成高质量图像方面表现出色,但先前的工作报告了语言建模中扩散和自回归(AR)方法之间的显著性能差距。
论文证明了简单的掩蔽离散扩散比以前认为的更高效。应用了一个有效的训练配方,提高了掩蔽扩散模型的性能,并推导了一个简化的、rao - blackwell化的目标,从而带来了额外的改进。
https://arxiv.org/abs/2406.07524
6、Neural Gaffer: Relighting Any Object via Diffusion

单图像光源重建是一项具有挑战性的任务,涉及几何,材料和照明之间复杂的相互作用推理。许多先前的方法要么只支持特定类别的图像,比如人像,要么需要特殊的捕捉条件,比如使用手电筒。
论文提出了一种新的端到端2D重光照扩散模型,称为神经光栅,该模型采用任何物体的单张图像,并可以在任何新的环境光照条件下合成准确、高质量的重光照图像,只需在目标环境地图上调节图像生成器,而无需明确的场景分解。
我们的方法建立在一个预训练的扩散模型上,并在一个合成的重照明数据集上对其进行微调,揭示和利用扩散模型中存在的对照明的固有理解。我们在合成和原始的互联网图像上评估了我们的模型,并证明了它在泛化和准确性方面的优势。
https://arxiv.org/abs/2406.07520
7、Understanding Hallucinations in Diffusion Models through Mode Interpolation
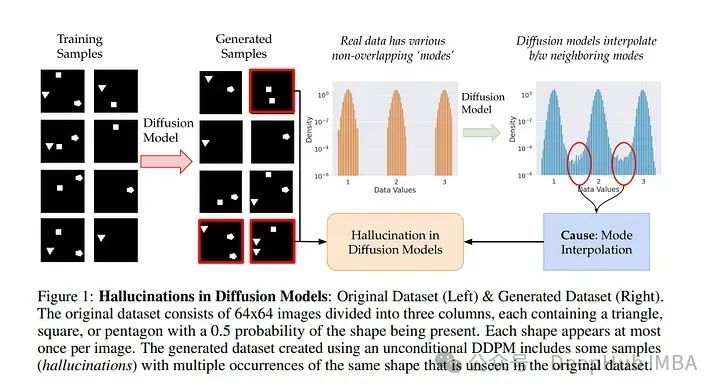
基于扩散过程的图像生成模型经常被认为表现出“幻觉”,即训练数据中永远不会出现的样本。但是这些幻觉是从哪里来的呢?本文研究扩散模型中一种特殊的失效模式,称之为模态插值。
具体来说,论文发现扩散模型在训练集中的附近数据模式之间平滑地“插值”,可以生成完全不在原始训练分布支持范围内的样本;这种现象导致扩散模型产生了真实数据中从未存在过的内容(即幻觉)。
通过对各种形状的人工数据集的实验,论文展示了幻觉如何导致从未存在过的形状组合的产生。最后证明了扩散模型实际上知道他们什么时候产生幻觉。
https://arxiv.org/abs/2406.09358
8、Hierarchical Patch Diffusion Models for High-Resolution Video Generation
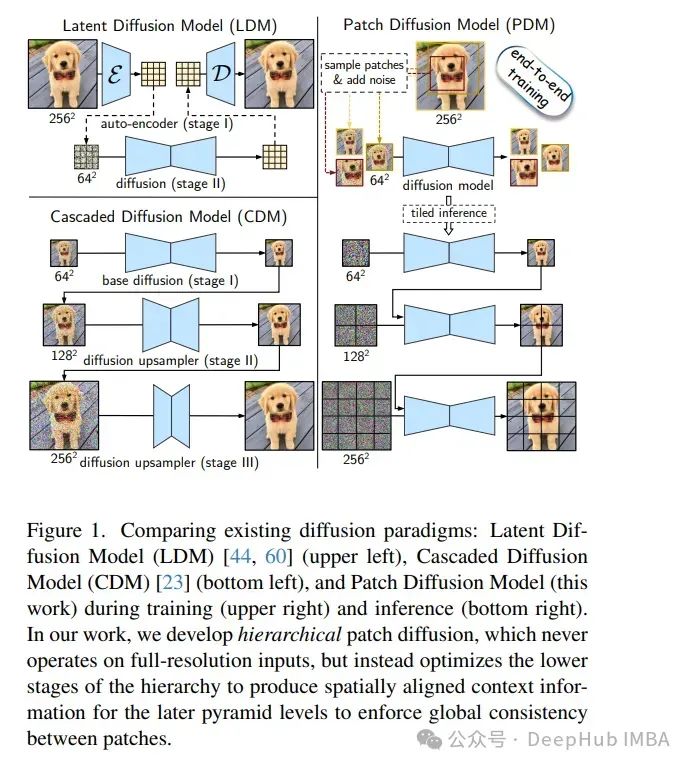
扩散模型在图像和视频合成中表现出了显著的性能。但是将它们扩展到高分辨率的输入是具有挑战性的,并且需要将扩散管道重组为多个独立的组件,这限制了可扩展性,并使下游应用复杂化。
论文以两种原则方式改进pdm,这使得它在训练期间非常高效,并解锁了高分辨率视频的端到端优化。
1、为了加强补丁之间的一致性,开发了深度上下文融合——一种以分层方式将上下文信息从低规模补丁传播到高规模补丁的架构技术。
2、为了加速训练和推理,提出了自适应计算,它将更多的网络容量和计算分配给粗糙的图像细节。结果模型在UCF-101 256²上的类条件视频生成中设置了新的最先进的FVD得分为66.32,Inception得分为87.68,超过了最近的方法100%以上。
https://arxiv.org/abs/2406.07792
9、Alleviating Distortion in Image Generation via Multi-Resolution Diffusion Models

本文通过集成一种新的多分辨率网络和时变层归一化,对扩散模型进行了创新的增强。
虽然传统方法依赖于卷积U-Net架构,但最近基于transformer的设计已经展示了卓越的性能和可扩展性。然而,对输入数据进行标记化(通过“补丁化”)的Transformer体系结构面临着视觉保真度和计算复杂性之间的权衡,这是由于涉及标记长度的自注意力操作的二次性质。
虽然更大的补丁尺寸可以提高注意力计算效率,但它们难以捕捉细粒度的视觉细节,从而导致图像失真。为了应对这一挑战,论文提出用多分辨率网络(DiMR)来增强扩散模型,这是一个跨多个分辨率细化特征的框架,从低分辨率到高分辨率逐步增强细节。
还引入了时间相关层归一化(TD-LN),这是一种参数高效的方法,将时间相关参数纳入层归一化,以注入时间信息并获得卓越的性能。
https://arxiv.org/abs/2406.09416
10、DiTFastAttn: Attention Compression for Diffusion Transformer Models
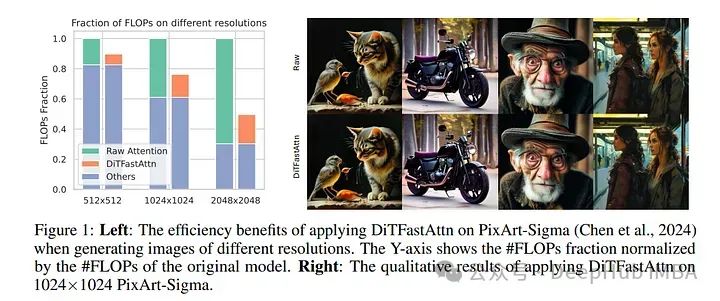
Diffusion transformer, DiT在图像和视频生成方面表现优异,但由于自注意力的二次复杂度而面临计算挑战。论文提出了一种新的训练后压缩方法DiTFastAttn来缓解DiT的计算瓶颈。
确定了DiT推理过程中注意力计算中的三个关键冗余:
空间冗余,即许多注意力集中在局部信息上。
时间冗余,相邻步骤的注意力输出高度相似。
条件冗余,其中条件和无条件推理表现出显著的相似性。
为了解决这些冗余问题,提出了三种技术:
窗口注意与残差缓存,以减少空间冗余。
时间相似性减少,利用步骤之间的相似性。
条件冗余消除,跳过条件生成过程中的冗余计算。
为了证明DiTFastAttn的有效性,论文将其应用于DiT, PixArt-Sigma用于图像生成任务,以及openora用于视频生成任务。评估结果表明,对于图像生成,减少了高达88%的flop,并在高分辨率生成时实现了高达1.6倍的加速。
https://arxiv.org/abs/2406.08552
Vision Language Models (VLMs)
1、An Image is Worth More Than 16x16 Patches: Exploring Transformers on Individual Pixels
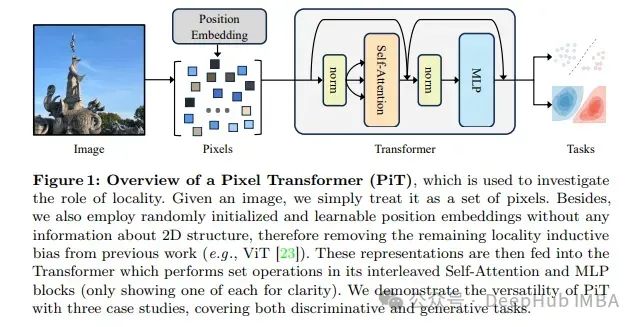
这篇文章我们已经介绍过了,就是Pixel Transformer
2、OpenVLA: An Open-Source Vision-Language-Action Model
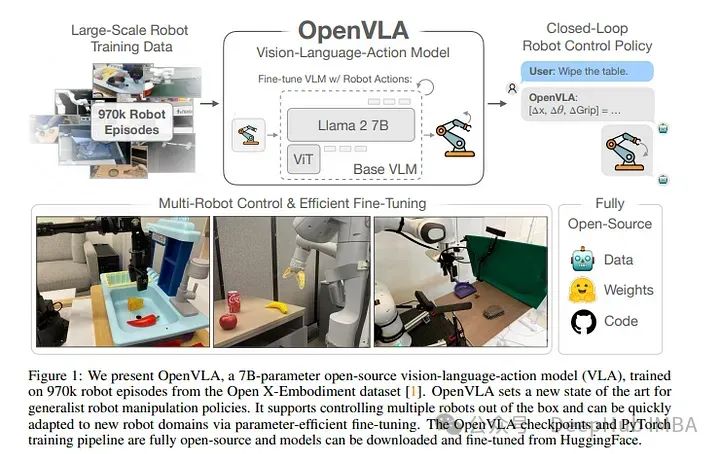
VLAs在机器人领域的广泛采用一直具有挑战性
现有的vla基本上是封闭的,无法向公众开放,先前的工作未能探索针对新任务有效微调VLAs的方法,这是采用的关键组成部分。
为了解决这些挑战,论文介绍了OpenVLA,这是一个7b参数的开源VLA,在970k个真实世界机器人演示的不同集合上进行了训练。OpenVLA建立在Llama 2语言模型的基础上,结合了一个视觉编码器,该编码器融合了DINOv2和SigLIP的预训练特征。
作为增加数据多样性和新模型组件的产物,OpenVLA在通才操作方面显示出强大的结果,在29个任务和多个机器人实施例中的绝对任务成功率优于RT-2-X (55B)等封闭模型16.5%,参数减少了7倍。
https://arxiv.org/abs/2406.09246
3、Commonsense-T2I Challenge: Can Text-to-Image Generation Models Understand Commonsense?

论文提出了一个新的评估文本到图像(T2I)生成模型生成符合现实生活中常见图像的能力的任务和基准,Commonsense-T2I
给定两个对抗性的文本提示,包含一组相同的动作词,但差异很小,比如“一个没有电的灯泡”和“一个有电的灯泡”,模型是否可以进行视觉常识推理,例如,相应地产生适合“灯泡未亮”和“灯泡亮”的图像。
数据集由专家精心手工管理,并使用细粒度标签(如常识类型和预期输出的可能性)进行注释,以帮助分析模型行为。
论文对各种最先进的(SOTA) T2I模型进行了基准测试,令人惊讶地发现,图像合成与真实照片之间仍然存在很大差距——即使DALL-E 3模型在Commonsense-T2I上也只能达到48.92%,而SDXL模型也只能达到24.92%的精度。
https://arxiv.org/abs/2406.07546
4、MuirBench: A Comprehensive Benchmark for Robust Multi-image Understanding
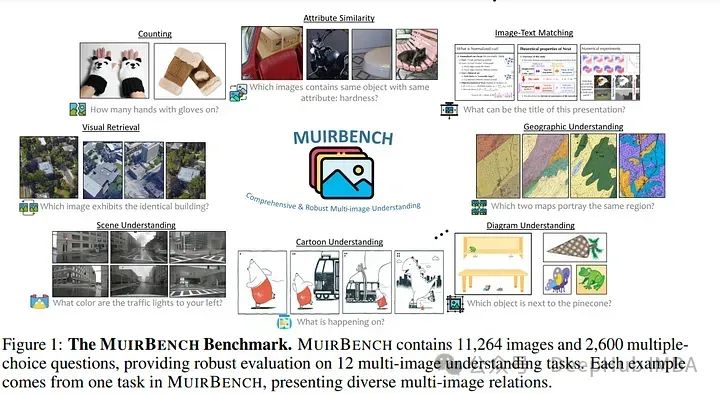
MuirBench是一个专注于多模式llm的鲁棒多图像理解能力的的基准。MuirBench由12个不同的多图像任务(例如,场景理解,排序)组成,涉及10类多图像关系(例如,多视图,时间关系)。
MuirBench由11,264张图像和2,600个选择题组成,以成对的方式创建,其中每个标准实例与具有最小语义差异的无法回答的变体配对,以便进行可靠的评估。
通过对20个最近的多模态llm进行评估,即使是像gpt - 40和Gemini Pro这样表现最好的模型,也很难解决MuirBench问题,准确率分别达到68.0%和49.3%。
https://arxiv.org/abs/2406.09411
Image Generation & Editing
1、GTR: Improving Large 3D Reconstruction Models through Geometry and Texture Refinement
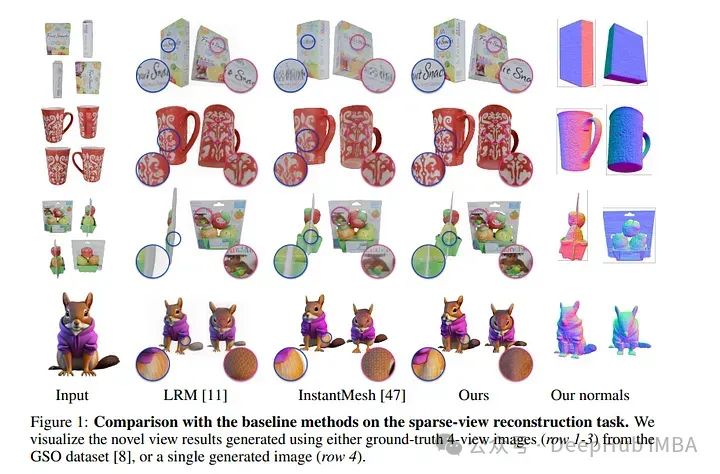
论文提出了一种基于多视图图像的三维网格重建方法。这个方法从大型重建模型(如LRM)中获得灵感,该模型使用基于Transformer的三平面生成器和在多视图图像上训练的神经辐射场(NeRF)模型。
https://arxiv.org/abs/2406.05649
2、IllumiNeRF: 3D Relighting without Inverse Rendering

论文提出了一种更简单光源合成方法:首先使用光照条件下的图像扩散模型重新为每个输入图像打光,然后用这些重新光照图像重建神经辐射场(NeRF),从这些图像中在目标光照下呈现新的视图。这个方法再多个基准测试中取得了最先进的结果。
https://arxiv.org/abs/2406.06527
3、Unified Text-to-Image Generation and Retrieval
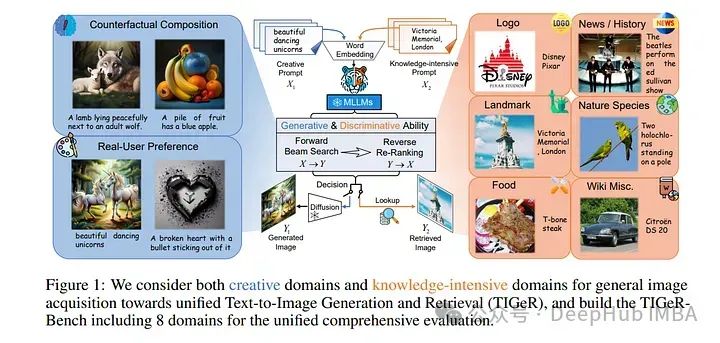
论文探索了mlm的内在判别能力,并引入了一种生成检索方法,以不需要训练的方式进行检索。随后,我们以自回归生成的方式将生成和检索统一起来,并提出了一个自主决策模块,在生成的图像和检索到的图像之间选择最匹配的图像作为文本查询的响应。
https://arxiv.org/abs/2406.05814
4、An Image is Worth 32 Tokens for Reconstruction and Generation

生成模型的最新进展突出了图像标记化在高效合成高分辨率图像中的关键作用。与直接处理像素相比,将图像转换为潜在表示的标记减少了计算量,提高了生成过程的有效性和效率。
先前的方法,如VQGAN,通常使用具有固定下采样因子的二维潜在网格。但是这些二维标记化在管理图像中存在的固有冗余方面面临挑战,其中相邻区域经常显示相似性。
为了克服这个问题,论文引入了一种基于transformer的一维标记器(TiTok),这是一种将图像标记为一维潜在序列的创新方法。TikTok提供了更紧凑的潜在表示,产生比传统技术更高效和有效的表示。
例如,一个256 x 256 x 3的图像可以减少到32个离散的标记,与之前的方法获得的256或1024个标记相比,这是一个显著的减少。尽管它的性质紧凑,但TiTok以最先进的方法实现了竞争性能。使用相同的生成器框架,TiTok获得了1.97 gFID,在ImageNet 256 x 256基准测试中显著优于MaskGIT基线4.21。
当涉及到更高的分辨率时,TiTok的优势变得更加明显。在ImageNet 512 x 512基准测试中,TiTok不仅优于最先进的扩散模型DiT-XL/2 (gFID 2.74 vs. 3.04),而且还将图像标记减少了64倍,从而使生成过程加快了410倍。
https://arxiv.org/abs/2406.07550
5、Toffee: Efficient Million-Scale Dataset Construction for Subject-Driven Text-to-Image Generation

论文提出了一种有效的方法来构建数据集,用于主题驱动的编辑和生成的方法Toffee。
数据集构建不需要任何主题级别的微调。在预训练两个生成模型后,能够生成无限数量的高质量样本。并构建了第一个用于主题驱动的图像编辑和生成的大规模数据集,其中包含500万图像对,文本提示和掩码。
这个数据集是之前最大数据集的5倍,但成本却降低了数万个GPU小时。为了测试所提出的数据集,论文还提出了一个能够进行主题驱动的图像编辑和生成的模型。通过简单地在数据集上训练模型,它得到了有竞争力的结果,说明了数据集构建框架的有效性。
https://arxiv.org/abs/2406.09305
Video Understanding Generation
1、Vript: A Video Is Worth Thousands of Words
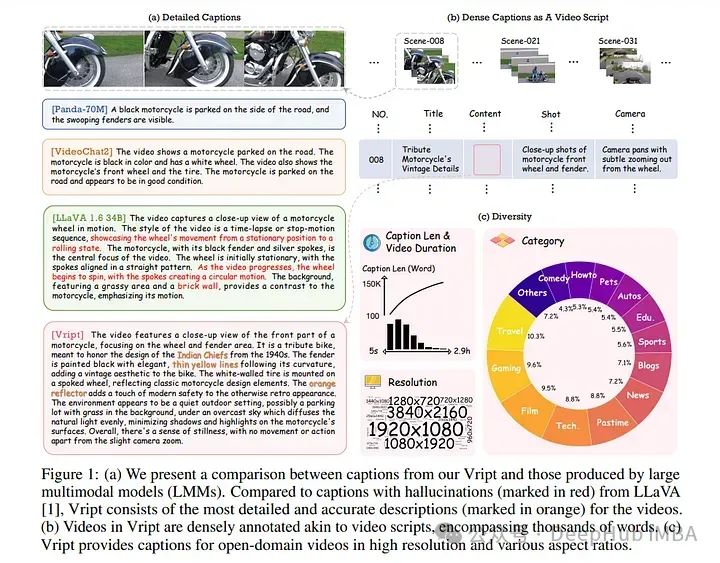
多模态学习的进步,需要高质量的视频文本数据集来提高模型性能。Vript通过精心注释的12K高分辨率视频语料库解决了这个问题,为超过420K的片段提供了详细、密集和类似脚本的字幕。
每个片段都有一个约145字的标题,比大多数视频文本数据集长10倍以上。与之前数据集中只记录静态内容的字幕不同,不仅记录了内容,还记录了摄像机操作,包括镜头类型(中景、特写等)和摄像机运动(平移、倾斜等),从而将视频字幕增强为视频脚本。
https://arxiv.org/abs/2406.06040
2、MotionClone: Training-Free Motion Cloning for Controllable Video Generation

基于运动的可控文本到视频生成涉及到控制视频生成的运动。以前的方法通常需要训练模型来编码运动线索或微调视频扩散模型。
当这些方法应用于训练域之外时,往往会导致次优运动生成。论文提出了MotionClone,这是一个无需训练的框架,可以从参考视频克隆运动来控制文本到视频的生成。
大量的实验表明,MotionClone在全局摄像机运动和局部物体运动中都表现得很熟练,在运动保真度、文本对齐和时间一致性方面具有显著的优势。
https://arxiv.org/abs/2406.05338
3、MMWorld: Towards Multi-discipline Multi-faceted World Model Evaluation in Videos
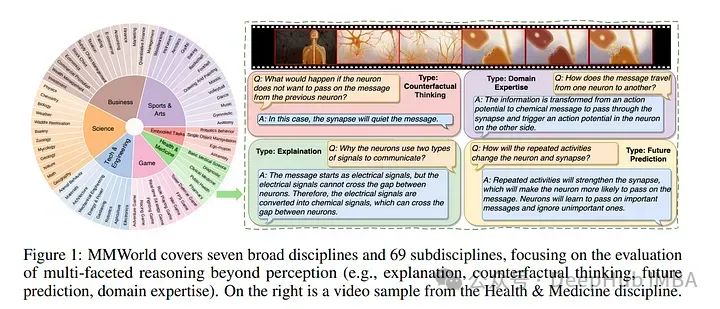
多模态语言语言模型(mllm)展示了“世界模型”的新兴能力——解释和推理复杂的现实世界动态。为了评估这些能力,论文假设视频是理想的媒介,因为它们包含了现实世界动态和因果关系的丰富表示。然后推出MMWorld,这是一个多学科、多面、多模态视频理解的新标杆。
MMWorld由一个人工注释的数据集和一个合成数据集组成,前者用于评估带有整个视频问题的mllm,后者用于分析单一感知模态下的mllm。MMWorld总共包含1,910个视频,跨越7个大学科和69个子学科,完成6,627对问答和相关字幕。
https://arxiv.org/abs/2406.08407
4、NaRCan: Natural Refined Canonical Image with Integration of Diffusion Prior to Video Editing
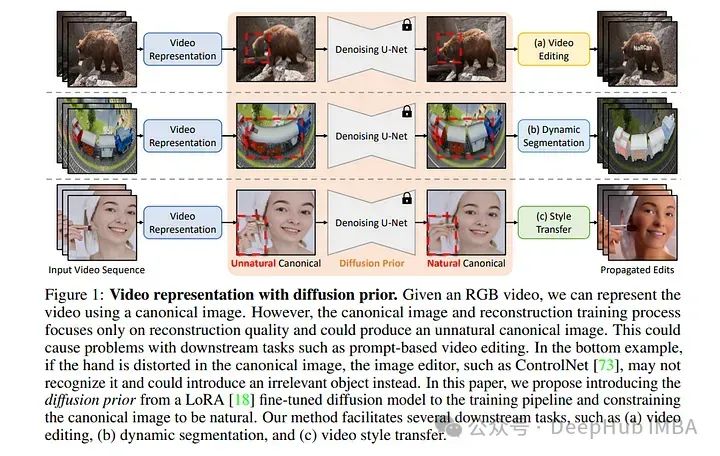
论文提出了一个视频编辑框架NaRCan,它集成了混合变形场和扩散,然后生成高质量的自然规范图像来表示输入视频。
利用单应性来建模全局运动,并使用多层感知器(mlp)来捕获局部残余变形,增强模型处理复杂视频动态的能力。
通过在训练的早期阶段之前引入扩散,模型可以确保生成的图像保持高质量的自然外观,使生成的规范图像适合视频编辑中的各种下游任务,这是当前基于规范的方法无法实现的功能。
另外还结合了低秩自适应(LoRA)微调,并引入了噪声和扩散先验更新调度技术,将训练过程加快了14倍。大量的实验结果表明,在各种视频编辑任务中优于现有的方法,并产生连贯和高质量的编辑视频序列。
https://arxiv.org/abs/2406.06523
5、TC-Bench: Benchmarking Temporal Compositionality in Text-to-Video and Image-to-Video Generation
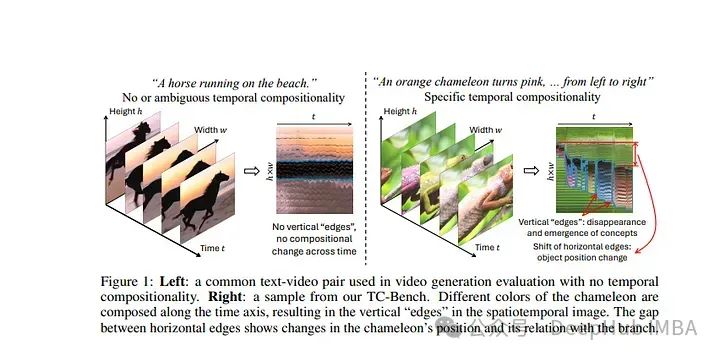
论文提出了TC-Bench,这是一个精心制作的文本提示、相应的真实视频和稳健评估指标的基准。
提示明确了场景的初始和最终状态,有效地减少了框架开发的模糊性,并简化了转换完成的评估。
通过收集与提示相对应的对齐的真实世界视频,将TC-Bench的适用性从文本条件模型扩展到可以执行生成帧插值的图像条件模型。论文还开发了新的指标来衡量生成视频中组件转换的完整性,与现有指标相比,这些指标与人类判断的相关性明显更高。
https://arxiv.org/abs/2406.08656
https://avoid.overfit.cn/post/d279d7b4b6c14bbb91de0d8fd786ecd8
作者:Youssef Hosni