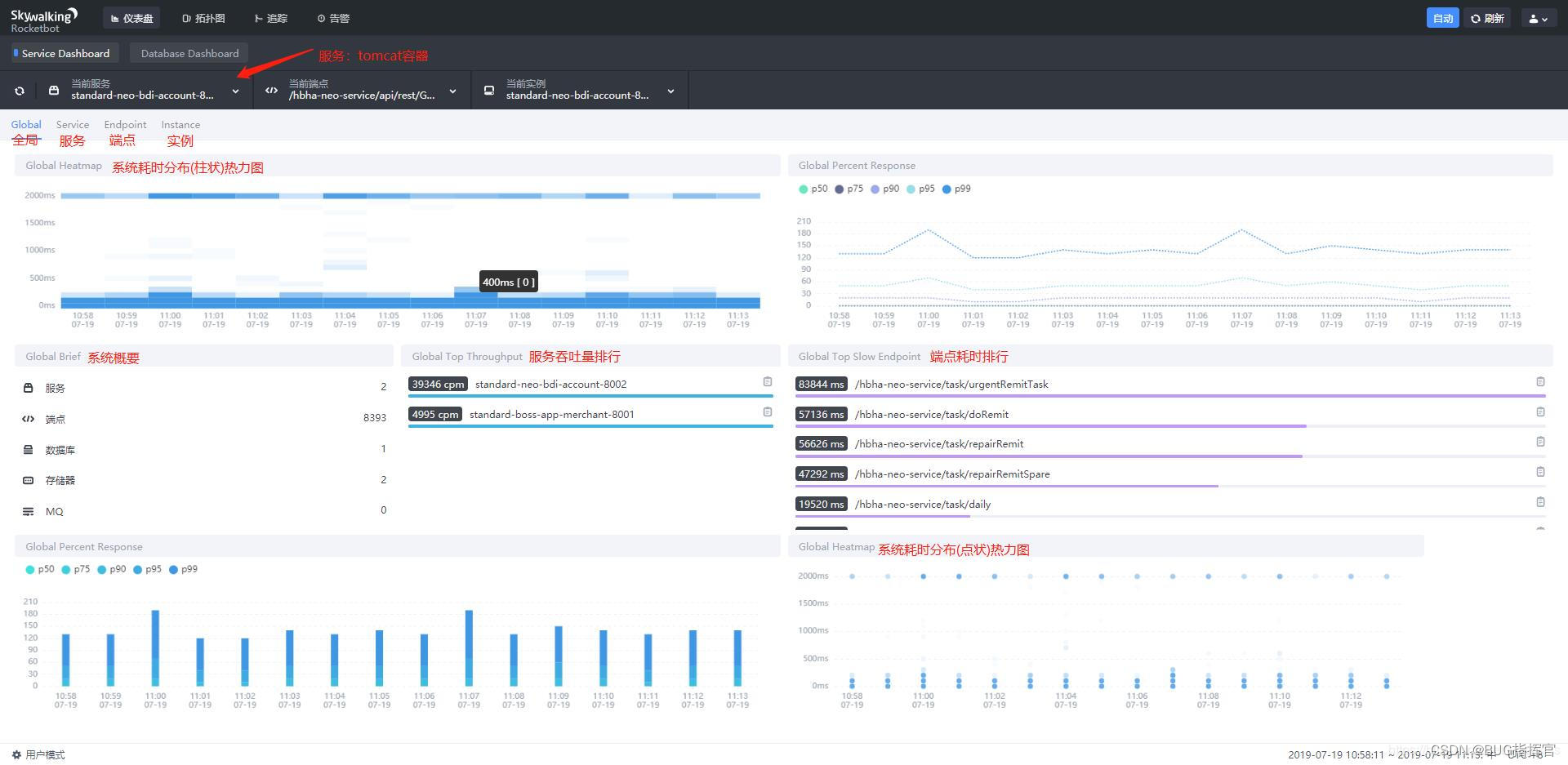
目录
1、用户缓冲区概念
2、用户缓冲区刷新策略
3、用户缓冲区的好处
4、内核缓冲区
5、验证内核缓冲区
6、用户缓冲区存放的位置
7、全缓冲
结语
前言:
Linux下的内核缓冲区存在于系统中,该缓冲区和用户层面的缓冲区不过同一个概念,用户层面的缓冲区称之为用户缓冲区,而系统中也有自己的缓冲区即内核缓冲区,两者虽然同为缓冲区却差之毫厘谬以千里,了解内核缓冲区前先谈谈用户缓冲区。
1、用户缓冲区概念
用户缓冲区是用户空间的标准库(stdio.h)缓冲区的缩写,也就是说标准库会提供一个缓冲区用来存放用户调用文件操作相关的库函数所产生或者接收到的数据,用户缓冲区是程序员在调用库函数时接触最频繁的,比如调用scanf、printf以及其他与文件流相关的函数,并不是直接把数据输入到目的地,中途先把数据放到用户缓冲区内,然后通过刷新缓冲区才能把数据送到目的地,示意图如下:
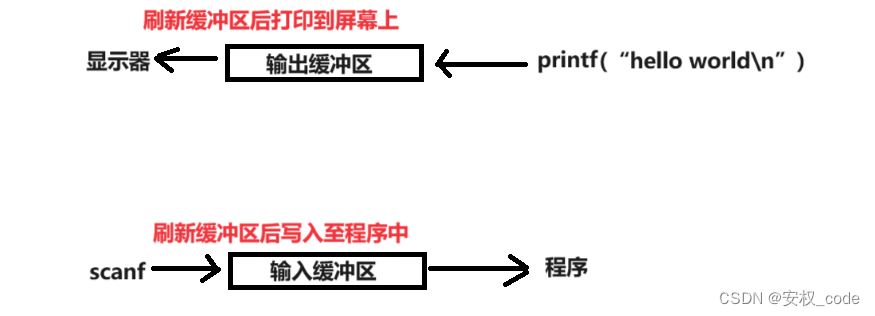
2、用户缓冲区刷新策略
有三种刷新用户缓冲区的策略:
1、无缓冲:只要把数据写到缓冲区内就会自动刷新缓冲区,比如系统函数write和read。
2、行缓冲:遇到\n时自动刷新缓冲区,打印到屏幕上时用行缓冲。
3、全缓冲:缓冲区满了才会自动刷新,比如将数据写入磁盘文件。
补充:进程结束时会自动刷新缓冲区。
3、用户缓冲区的好处
1、提高效率,有了缓冲区后,数据就不必频繁的传输,也不必频繁的进行系统调用,因为处理少量的数据可以先把数据放到缓冲区内,然后统一进行传输,减少了小块数据的传输次数,以至于提高系统效率。
2、同一格式化,意思是所有的int类型、float类型都需要转换成字符串的形式存放到缓冲区内,接收方只需要采用字符串形式的处理方式统一处理。
4、内核缓冲区
上述说到printf以及其他各种文件流函数会经过用户缓冲区然后再到硬件文件(显示器就是一个硬件文件),其实经过了用户缓冲区后还要调用系统函数wrtie,通过wrtie将用户缓冲区的内容写到内核缓冲区内,最后由系统自动刷新内核缓冲区,才把内容写进硬件文件中,很明显这个内核缓冲区是在系统里的,并且因为库函数接口自动帮助我们调用底层函数,所以这些细节上层并不是关系,因此完整的流程图如下:
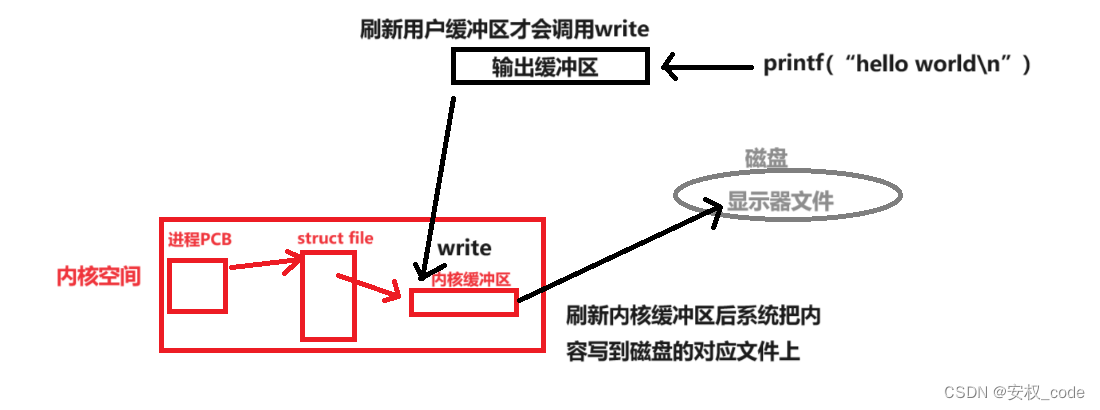
只有当最后一步把数据写到磁盘上的显示器文件时,才算是真正的在屏幕上打印出来。注意:刷新内核缓冲区由系统自动完成。
5、验证内核缓冲区
通过上图可以发现printf库函数和用户缓冲区“打交道”,wrtie系统函数和内核缓冲区“打交道”,所以通过下面测试代码,可以证明内核缓冲区和用户缓冲区是两个缓冲区,示例代码如下:
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int main()
{
const char *fstr = "hello fwrite";
const char *str = "hello write";
// C
printf("hello printf"); // stdout -> 1
sleep(1);
fprintf(stdout, "hello fprintf"); // stdout -> 1
sleep(1);
fwrite(fstr, strlen(fstr), 1, stdout); // fwrite, stdout->1
sleep(1);
// 操作提供的系统函数
write(1, str, strlen(str)); // 1
close(1); //关闭该进程的显示器文件
sleep(2);
//fork();
return 0;
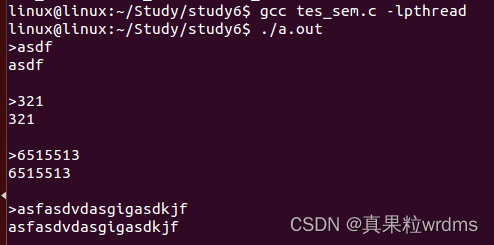
}运行结果:

从运行结果可以发现,只有调用wrtie的数据被打印出来了,前面的三句话都没被打印出来,原因就是close(1)这句代码,并且细心观察会发现所有字符串内容都没加‘\n’,这就导致写入用户缓冲区时不会立刻刷新用户缓冲区,错过了这次的刷新,下次刷新只能等该进程结束时才会自动刷新用户缓冲区了,但是在该进程结束前就关闭了1号文件描述符(即显示器文件),导致之前堆积在用户缓冲区里的数据刷新后找不到对应的内核缓冲区了,因此最终的现象就是用户缓冲区的内容全部没打印在屏幕上。
但是write的数据却正常打印了,原因就是write跳过了用户缓冲区,直接往内核缓冲区里写,并且在close关闭前会自动刷新内核缓冲区,所以close虽然关闭了1号文件描述符,但是write的数据已经写到显示器文件里了,因此可以正常打印write负责的数据。
6、用户缓冲区存放的位置
我们使用的用户缓冲区存放在c语言标准库为我们封装好的指针FILE* fp所指向的结构体里,示意图如下:
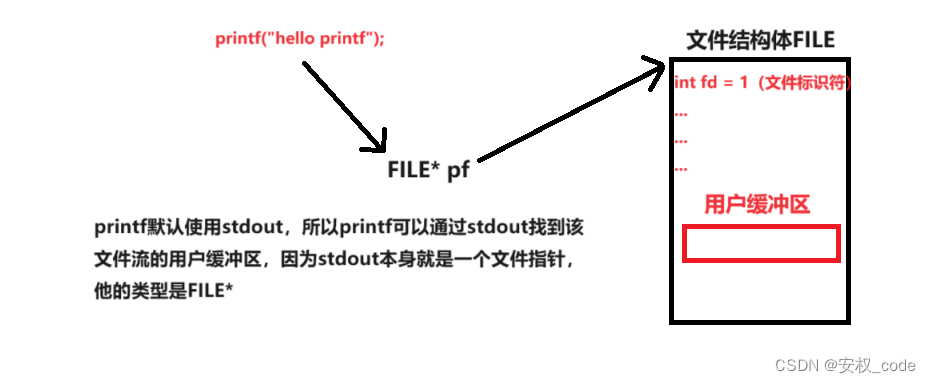
该结构体里包含了大量的文件相关信息,其中就包括文件描述符以及用户缓冲区,因为printf是默认使用stdout文件流指针的,所以即使不传文件指针给printf也可以在屏幕上打印。
7、全缓冲
当进程里的文件描述符1被重定向至文件中,这时候stdout打印方式从行缓冲变成了全缓冲,即遇到\n后不会刷新用户缓冲区了,只有把用户缓冲区写满才会刷新,或者当进程结束的时候才会刷新缓冲区,让缓冲区里的内容读进文件里。
示例代码如下:
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int main()
{
const char *fstr = "hello fwrite\n";
const char *str = "hello write\n";
// C
printf("hello printf\n"); // stdout -> 1
sleep(1);
fprintf(stdout, "hello fprintf\n"); // stdout -> 1
sleep(1);
fwrite(fstr, strlen(fstr), 1, stdout); // fread, stdout->1
sleep(1);
// 操作提供的systemcall
write(1, str, strlen(str)); // 1
sleep(2);
//close(1);
fork();
return 0;
}运行结果:
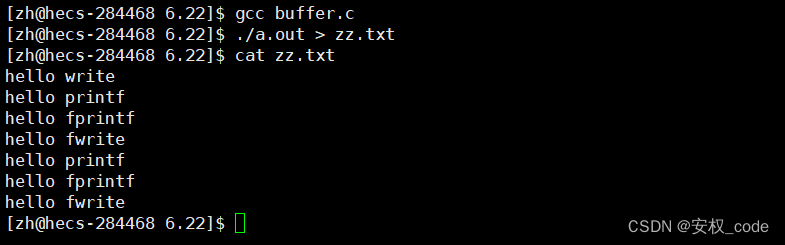
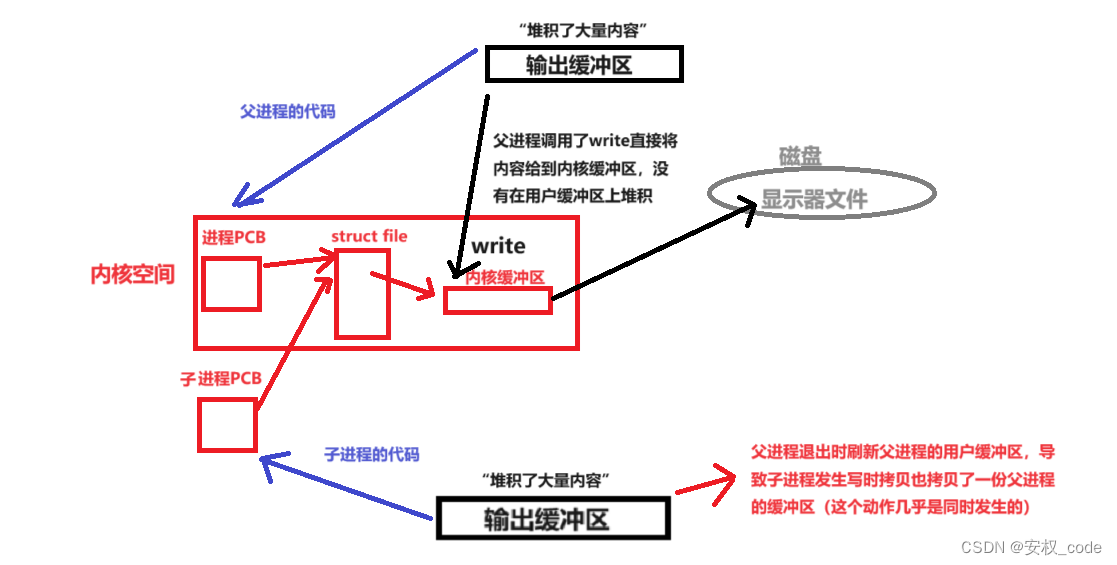
从结果发现调用库函数打印的数据在文件中写了两份,而调用系统函数打印的数据只写了一份,根本原因很简单,就是因为程序的末尾使用fork创建了子进程,但是具体为什么创建子进程后会让有些数据打印两份有些数据打印一份呢?
原因如下:
1、文件是全缓冲,所以数据会在缓冲区内堆积。
2、进程退出的时候会刷新缓冲区,会引发写时拷贝,因此会给另一个进程拷贝一份缓冲区的内容。
3、write负责的数据没有写两份的原因是write是系统调用接口(一个struct file只有一个内核缓冲区),他跳过用户缓冲区,并把数据写到内核缓冲区内,所以不会引发写时拷贝。
示意图如下:
结语
以上就是关于内核缓冲区以及用户缓冲区的全部讲解,理解内核缓冲区的前提是了解文件流流向的整个过程,因此必须了解c标准库提供给用户的标准库缓冲区又称用户缓冲区的概念,并且若想拿到缓冲区里的内容给到“下一站”,则必须刷新缓冲区。

![yocto系列讲解[实战篇]94 - 添加libhybris库和测试示例](https://img-blog.csdnimg.cn/f64e1f114d7045eaa57a680daec4395b.png)