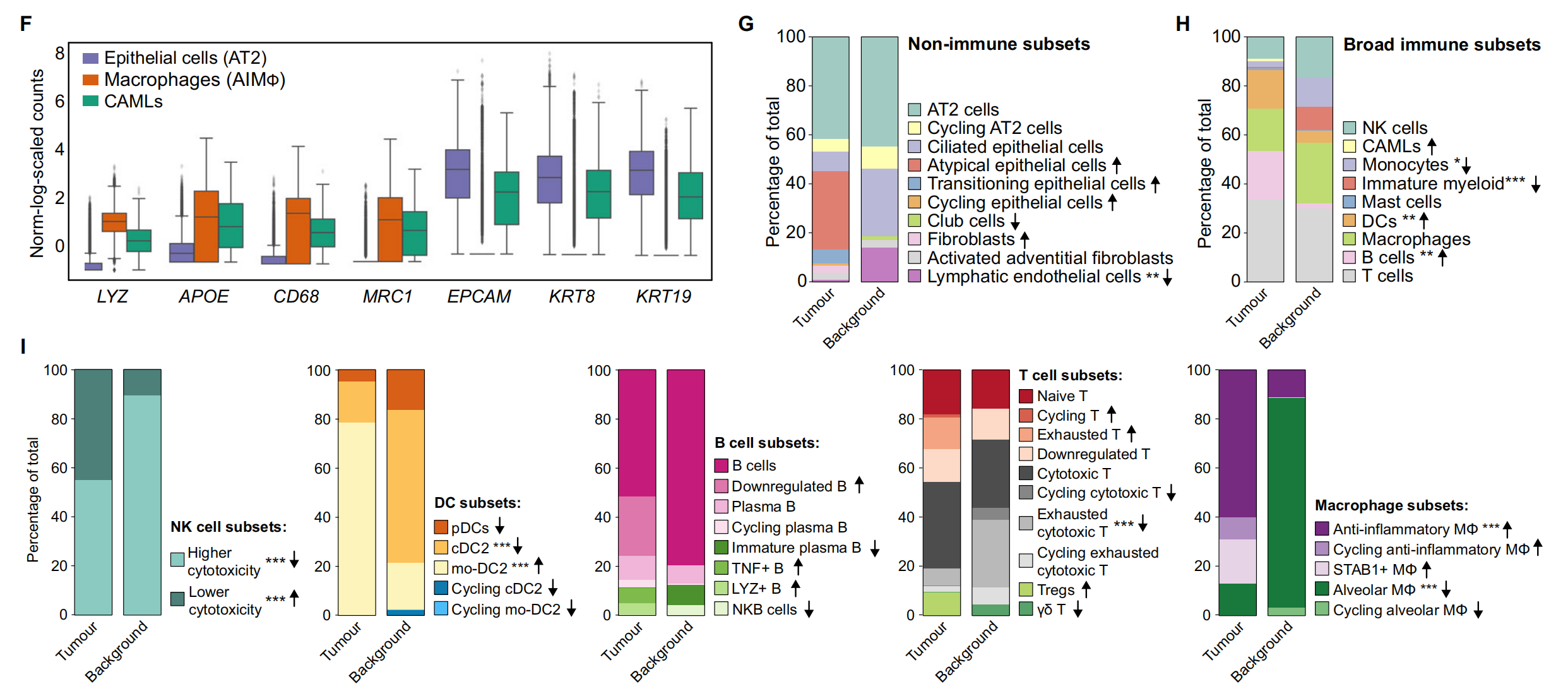
1、整体架构
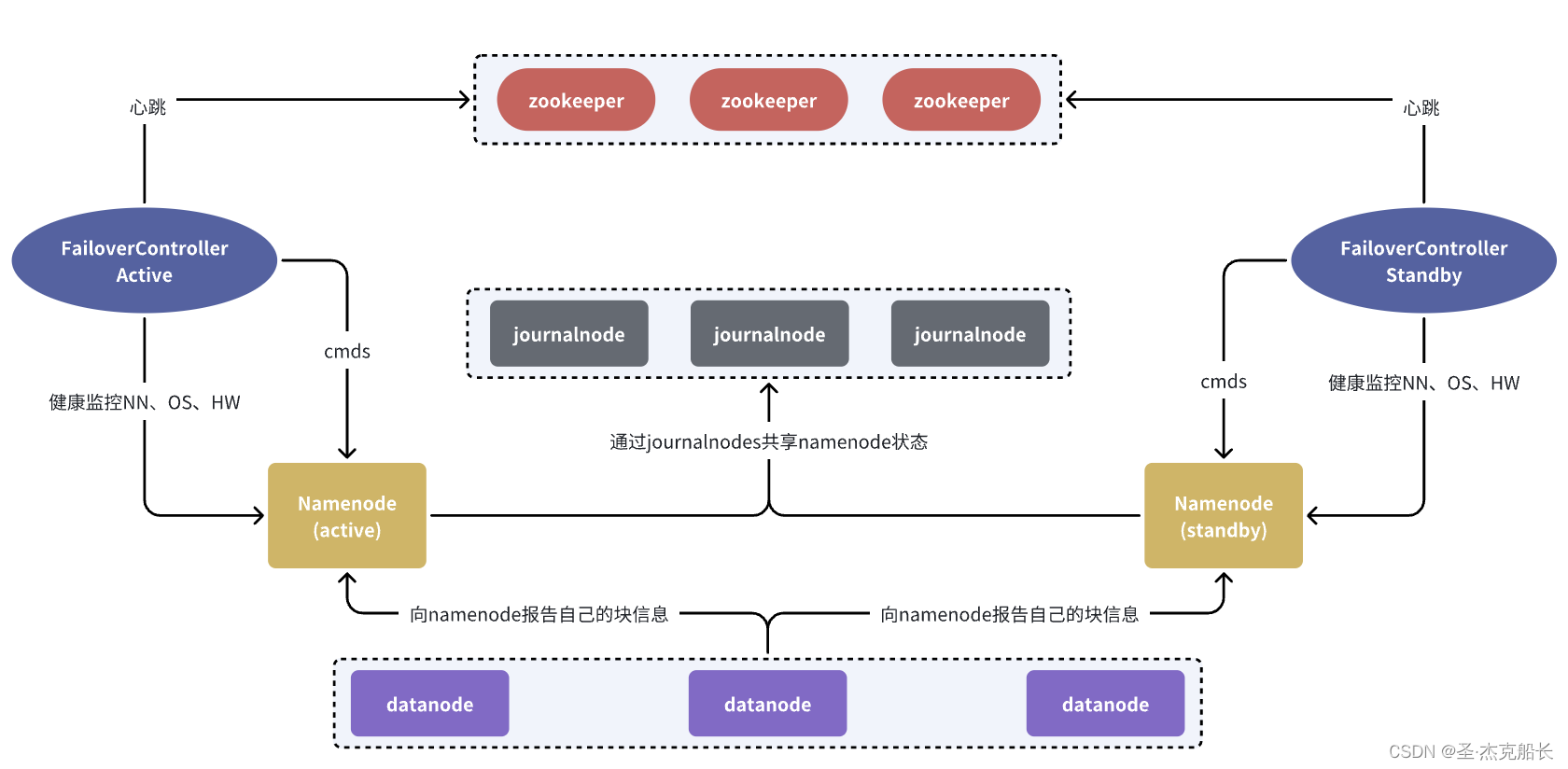
2、角色简介
2.1、namenode
NameNode 是 HDFS 集群中的核心组件,负责管理文件系统的元数据、处理客户端请求、管理数据块、确保数据完整性和高可用性。由于其重要性,NameNode 的性能和可靠性直接影响整个 HDFS 集群的性能和可靠性。在生产环境中,通常会采取多种措施来保障 NameNode 的高可用性和稳定性。具体功能如下:
1)NameNode 主要负责管理 HDFS 的元数据(metadata),包括文件系统的目录结构、文件名、文件大小、权限等。它维护了整个文件系统的命名空间,并记录文件到块(block)的映射关系,以及每个块所在的 DataNode 信息。
2)当客户端请求访问 HDFS 中的文件时,NameNode 会处理这些请求并提供相关的元数据。例如,当客户端想要读取文件时,NameNode 会提供文件所在的块和相应 DataNode 的位置信息。
3)块分配:当文件写入 HDFS 时,NameNode 会为文件分配新的块,并选择合适的 DataNode 来存储这些块。块副本管理:HDFS 默认会为每个块存储多个副本(通常是 3 个),以提高数据的可靠性。NameNode 负责确保每个块有足够数量的副本,如果某个块的副本丢失,NameNode 会启动块副本的重新复制。
4)NameNode 维护着每个块的校验和(checksum),以确保数据的完整性。当客户端读取数据时,会进行校验以检测和修复数据损坏。
5)NameNode 负责监控集群中 DataNode 的状态,并进行故障检测和恢复。如果检测到某个 DataNode 失效,NameNode 会重新分配块副本,确保数据的可靠性和可用性。
6)NameNode 负责管理 HDFS 的快照和检查点功能。快照允许用户在特定时间点捕获文件系统的状态,提供数据保护和恢复能力。检查点(Checkpoint)是指 NameNode 将其内存中的元数据快照写入磁盘,以减少系统启动时的恢复时间。
2.2、datanode
DataNode 是 HDFS 集群中执行数据存储和管理的工作节点,负责实际的数据块存储、读取、写入、校验和复制。它与 NameNode 协作,保证数据的可靠性、可用性和一致性。在生产环境中,通常会有多个 DataNode 组成 HDFS 集群,以提供分布式存储和高容错能力。
1)DataNode 是 HDFS 集群中存储实际数据块的节点。文件在 HDFS 上被拆分成若干个数据块(通常每个块 128MB 或 256MB),这些块被分散存储在多个 DataNode 上。
2)DataNode 负责管理其本地磁盘上的数据块。它会定期向 NameNode 报告其存储的所有数据块的列表,以便 NameNode 可以更新其元数据。
3)为了提供高可用性和容错能力,HDFS 会为每个数据块存储多个副本(通常是 3 个)。这些副本分布在不同的 DataNode 上。DataNode 负责存储这些副本,并在必要时进行复制。
4)当客户端请求读取或写入数据时,DataNode 会直接与客户端进行交互:读取:客户端从 DataNode 读取所需的数据块。写入:当客户端写入新数据时,DataNode 接受数据块并存储在其本地磁盘上,同时会根据 NameNode 的指示,将数据块的副本复制到其他 DataNode。
5)DataNode 负责校验和(checksum)的计算和验证,以确保数据块在存储和传输过程中没有损坏。每个数据块在存储时会计算其校验和,DataNode 定期对存储的数据块进行校验以检测和修复数据损坏。
6)DataNode 会定期向 NameNode 发送心跳信号,报告其健康状态和可用存储容量。如果 NameNode 没有收到某个 DataNode 的心跳信号,就会认为该 DataNode 已失效,并开始数据恢复流程。
7)当某个 DataNode 失效或某个数据块副本损坏时,NameNode 会指示其他 DataNode 进行数据块的复制和重新平衡,以确保数据的高可用性和均衡分布。DataNode 负责执行这些复制和重新平衡任务。
8)当客户端或 NameNode 指示删除某个文件时,DataNode 会删除其本地磁盘上存储的相应数据块,并通知 NameNode 更新其元数据。
2.3、journalnode
JournalNode在高可用(High Availability,HA)配置中起着关键作用。具体而言,JournalNode的主要功能是帮助管理和协调NameNode的日志写入,以确保系统在主NameNode(Active NameNode)发生故障时,备用NameNode(Standby NameNode)能够无缝接管。以下是JournalNode的详细作用
1)日志写入:在HDFS HA配置中,所有的NameNode操作(如创建文件、删除文件等)都会生成编辑日志(Edit Logs)。这些日志记录了文件系统的元数据变化。
同步日志:当Active NameNode执行任何文件系统操作时,它会将相应的编辑日志同步写入到所有JournalNode中。这些日志记录了元数据的变更操作,JournalNode负责持久化这些变更日志。
2)Quorum机制:JournalNode集群通常由奇数个节点组成(如3个或5个),以便通过Quorum机制(多数投票机制)保证日志的可靠写入和一致性。在写入编辑日志时,Active NameNode必须等待超过半数的JournalNode成功写入日志,这样即使有少数节点发生故障,系统依然能够保证数据的一致性。
3)日志同步:Standby NameNode会不断地从JournalNode拉取最新的编辑日志,并将这些日志应用到自身的元数据中,以保持与Active NameNode的同步。这一机制确保Standby NameNode始终拥有最新的文件系统状态。故障切换:当Active NameNode发生故障时,Standby NameNode可以通过从JournalNode获取的最新编辑日志迅速接管,从而实现无缝故障切换。JournalNode确保了Standby NameNode接管时的元数据是最新的,避免数据丢失或不一致。
4)日志持久化:JournalNode将接收到的编辑日志持久化到本地存储中,这些日志是NameNode操作的序列化记录。即使JournalNode发生重启或故障,只要大多数JournalNode节点仍然可用,系统的编辑日志依然是安全的。
2.4、failovercontroller
通过自动和手动的故障切换、仲裁机制和健康监控,它确保了 NameNode 的高可用性和可靠性,保证在 Active NameNode 发生故障时,Standby NameNode 能够自动接管,保持 HDFS 集群的高可用性。以下是 FailoverController 的详细作用:
1)FailoverController 通过定期检查 Active NameNode 的健康状况,来检测其是否处于正常工作状态。如果检测到 Active NameNode 出现故障,FailoverController 会触发故障切换流程。
2)当 Active NameNode 出现故障时,FailoverController 负责将 Standby NameNode 切换为 Active 状态。这一过程包括:
- 确保 Standby NameNode 拥有最新的元数据状态。
- 更新元数据锁,以防止同时有多个 Active NameNode。
- 向集群中的 DataNode 和其他客户端通知新的 Active NameNode。
3)在一个高可用的 HDFS 集群中,通常会有一个 Quorum Journal Manager (QJM) 或者 Zookeeper 作为仲裁机制,以确保只有一个 Active NameNode。FailoverController 使用这种仲裁机制来避免脑裂 (Split-Brain) 问题,即确保不会同时有两个 Active NameNode 存在。
4)FailoverController 也支持手动切换操作。管理员可以通过命令手动触发 NameNode 之间的切换,通常在维护或升级过程中使用
5)FailoverController 定期对 NameNode 的健康状况进行监控,确保 Active NameNode 的可用
2.5、zookeeper
在 HDFS 高可用架构中,ZooKeeper(ZK)扮演着重要的角色,主要用于以下几个方面:
1)ZooKeeper 作为分布式协调服务,帮助管理 HDFS 集群中的各个组件的状态和配置信息。在 HDFS 高可用部署中,ZooKeeper 负责:
协调故障恢复:监控 NameNode 和 ZooKeeper Failover Controller (ZKFC) 的状态,确保在发生故障时能够进行快速的故障转移和恢复。
管理元数据:存储和管理 NameNode 的元数据信息,包括活动 NameNode 和备用 Standby NameNode 的信息,确保只有一个 NameNode 处于活动状态。
2)在 HDFS 的高可用架构中,ZooKeeper 负责管理 NameNode 的选举过程。具体来说,它提供了以下功能:主节点选举:通过 ZooKeeper 的临时顺序节点和 Watcher 机制,协助 NameNode 在故障或启动时进行主节点(Active NameNode)的选举。
避免脑裂:使用 ZooKeeper 的选举机制避免出现多个活动的 NameNode,从而防止数据一致性和服务可用性问题。
3)ZooKeeper 用于在 NameNode 之间同步状态和元数据信息。例如:元数据持久化:存储 NameNode 的持久化数据,如命名空间信息、数据块位置等。领导者选举:在故障切换时,确保新选举出的主节点能够迅速恢复到活动状态,继续提供服务。
4)ZooKeeper 也用于管理和存储 HDFS 集群的配置信息。这些配置信息可以包括 HDFS 的命名空间配置、HA 配置、以及其他服务相关的配置,确保集群中所有节点都能获取到一致的配置信息。
5)通过 ZooKeeper 的 Watcher 机制,能够及时监控和检测 NameNode 和 ZKFC 的状态变化,包括节点的加入、退出以及状态的变化。这对于集群的实时健康状态监控和故障诊断至关重要。