目录
一、实验目的
二、实验说明
三、实验过程
3.1 创建wordcount源码
3.1.1 实验说明
3.1.2 文件创建
3.2 Makefile文件创建与编译
3.3 主机配置文件建立与运行监测
3.3.1 主机配置文件建立
3.3.2 运行监测
三、实验结果与分析
4.1 实验结果
4.2 结果分析
4.2.1 原始结果分析
4.2.2 改进后的结果分析
五、实验总结与思考
5.1 实验思考
5.2 实验总结
END~
一、实验目的
1.1 掌握简单的程序编写,如 WordCount 中的 getWords、countWords、treeMerge
1.2 理解集群 WordCount 算法,实现多台主机 WordCount 算法的编译运行
二、实验说明
华为鲲鹏云主机、openEuler 20.03 操作系统;
安装 mpich-3.3.2.tar.gz;
安装 OpenBLAS-0.3.8.tar.gz;
四台主机名称及ip地址如下:
122.9.37.146 zzh-hw-0001
122.9.43.213 zzh-hw-0002
116.63.11.160 zzh-hw-0003
116.63.9.62 zzh-hw-0004
三、实验过程
3.1 创建wordcount源码
3.1.1 实验说明
实验将提供两个文件夹,第一个文件夹包含 100 个小文件,第二文件夹包含一个大文件。请针对这两种情况分别实现 WordCount 算法,同时把结果打印到屏幕上。WordCount 算法可分解为三步,分别为 getWords 、countWords 、treeMerge。
3.1.2 文件创建
注:以下步骤均需要在四台主机上进行
首先创建 wordcount 目录存放该程序的所有文件, 并进入 wordcount 目录,具体通过输入如下命令:
mkdir /home/zhangsan/wordcount
cd /home/zhangsan/wordcount
然后输入mkdir –p project_file/big_file 、mkdir –p project_file/small_file创建存放测试数据的目录。最后创建wordcount源码wordcount.cpp文件。输入vim wordcount.cpp,添加代码并输入:wq完成保存。
部分代码如下:
int rank;
int worldSize;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &worldSize);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
/*
* Word Count for big file
*/
{
struct timeval start, stop;
gettimeofday(&start, NULL);
std::string big_file = "./project_file/big_file/big_100.txt";
auto content = readFile(big_file);
auto partContent = getWords(content, rank, worldSize);
auto counts = countWords(partContent);
treeMerge(rank, worldSize, counts);
gettimeofday(&stop, NULL);
if (rank == 0) {
cout << "word count: "
<< (stop.tv_sec - start.tv_sec) * 1000.0 +
(stop.tv_usec - start.tv_usec) / 1000.0
<< " ms"<< endl;
}3.2 Makefile文件创建与编译
注:以下步骤四台主机均需要完成
首先输入vim Makefile ,进行编辑模式,输入如下内容,注意缩进:
CC = mpic++
CCFLAGS = -O2 -fopenmp
LDFLAGS = -lopenblas
all: wordcount
wordcount: wordcount.cpp
${CC} ${CCFLAGS} wordcount.cpp -o wordcount ${LDFLAGS}
clean:
rm wordcount然后输入make完成编译,结果如下,生成了一个可执行文件-wordcount

3.3 主机配置文件建立与运行监测
3.3.1 主机配置文件建立
注:该步骤需要在四台主机上运行
首先输入vim /home/zhangsan/wordcount/hostfile,编辑如下内容
zzh-hw-0001:4
zzh-hw-0002:4
zzh-hw-0003:4
zzh-hw-0004:4
此处对原教程的内容进行了改进,将处理机数量整体上从8个提升到了16个,观察运行时间的变化规律
3.3.2 运行监测
输入vim run.sh编写 run.sh 脚本,编辑内容如下:
app=${1}
if [ ${app} = "wordcount" ]; then
mpirun --hostfile hostfile -np ${2} ./wordcount
fi分别执行以下命令,查看 wordcount 运行结果(此步骤仅需在任意一台实现)
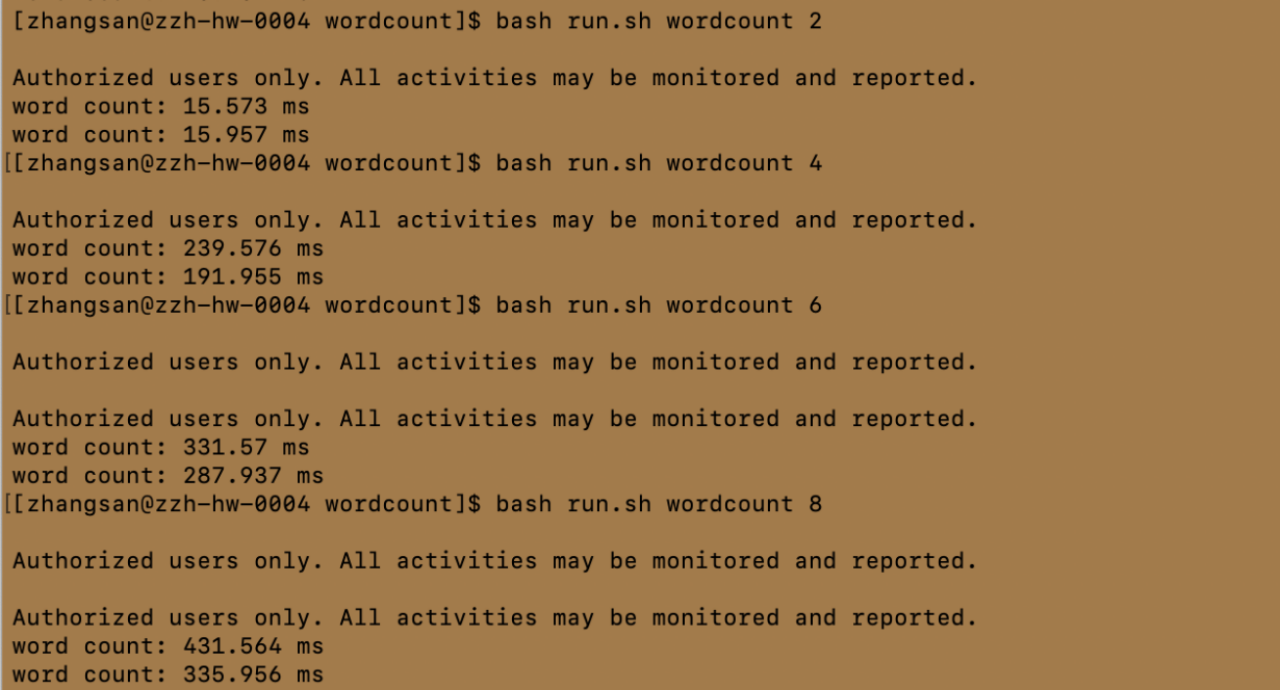
bash run.sh wordcount 2
bash run.sh wordcount 4
bash run.sh wordcount 6
bash run.sh wordcount 8
bash run.sh wordcount 10
bash run.sh wordcount 12
bash run.sh wordcount 14
bash run.sh wordcount 16三、实验结果与分析
4.1 实验结果
I 处理机数为2、4、6、8时
II 处理机数量为10、12、14、16时
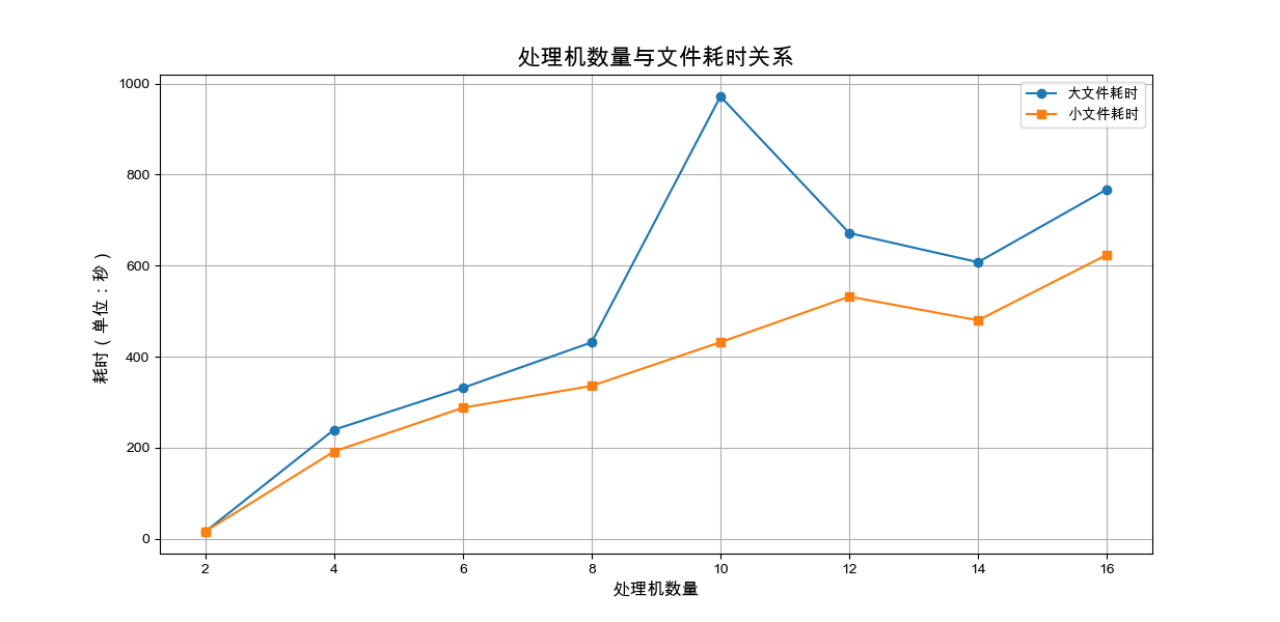
将上述结果进行可视化,观察耗时随处理机数量、文件大小的变化关系,如下:
由实验说明中指出第一个文件夹包含100 个小文件,于是尝试将文件
"./project_file/big_file/big_100.txt"改为 "./project_file/big_file/big_99.txt",观察结果变化

部分结果如下
4.2 结果分析
4.2.1 原始结果分析
由可视化结果知,此程序处理机数量增加,耗时反而增加,大文件小文件一致。考虑如下原因:
·通信开销:在分布式系统中,多个进程需要相互通信来协调工作。随着处理器数量的增加,通信开销可能会增加,特别是如果通信模式是全对全(all-to-all)或者需要频繁同步。
·负载不平衡:如果工作负载在各个处理器之间分配不均匀,一些处理器可能会早早完成任务而空闲,而其他处理器还在忙碌,这会导致整体性能下降。
4.2.2 改进后的结果分析
变化趋势依旧不变,仍然是处理机数量越多,耗时越长;仍然考虑通信开销及负载不平衡的原因。切换文件后,耗时依旧变化不大,可能是"./project_file/big_file/big_100.txt"和"./project_file/big_file/big_99.txt"大小差不多,导致最后的运行时间变化不大。
整个实验中,串行的耗时均小于并行的耗时,并没有很好的体现并行化的优势,我认为最可能的原因是用于计数的文件数据量及规模较小,导致并行化的通信开销等造成的性能下降幅度大于并行化处理造成的性能上升幅度。最终使得并行化效果不如串行。
五、实验总结与思考
5.1 实验思考
①实现 WordCount 算法中比较关键的是哪些?
·输入分割:将输入文本分割成单词或词元。
·映射(Map):生成每对(单词,1)。
·键(Key)设计:确保相同的单词映射到相同的键。
·归约(Reduce):对每个单词的所有出现次数进行汇总。
·并行处理:设计算法以支持并行处理,提高效率。
·性能优化:减少不必要的数据传输和计算,优化性能。
②WordCount 算法实现并行化的原理
首先将输入文件分割成多个数据块并分配给不同的进程进行数据分发。每个进程独立地对所接收的数据块执行WordCount操作,完成本地处理并生成局部的单词计数。随后,通过MPI的归约操作,如Reduce或全局汇总操作,例如Gather或Allgather,将所有进程的局部计数合并起来,形成全局的单词计数。最终,结果可以收集到一个主进程中,或者通过广播操作将结果分发到所有进程。
5.2 实验总结
在华为鲲鹏平台上实现WordCount程序的并行化实验中,我成功掌握了MPI并行编程的基本技巧,包括数据的分割、分布式处理、以及结果的归约合并。实验结果显示,随着并行化程度的提高,理论上处理速度应加快,但实际上观察到了耗时增加的现象。我认为有如下原因:
①通信开销:随着进程数量的增加,进程间的数据传输和同步所需的时间可能超过了单机处理的时间。
②负载不均衡:数据在不同进程间可能分配不均,导致部分进程空闲等待,而其他进程仍在处理数据。
③资源限制:硬件资源(如内存或CPU)的限制可能成为瓶颈,限制了并行化的效率。
通过这次实验,我认识到并行化并不是简单地增加进程数就能提升性能,而是需要细致地考虑数据分配、通信策略和资源管理等多个方面。未来,我计划进一步优化算法,比如通过动态负载平衡和减少通信开销来提高并行效率。
END~

享受过程就不要考虑结果
考虑结果就不要享受过程