数据集Dataset
心得体会
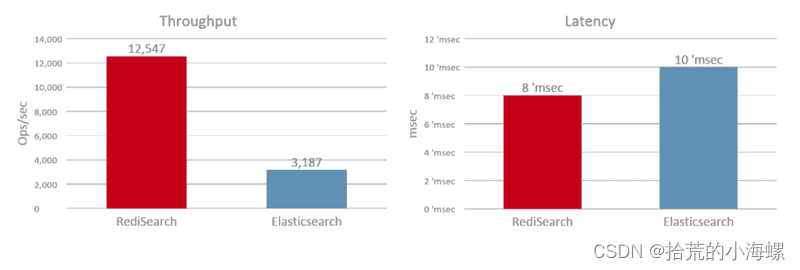
- 昇思提供了丰富的数据集,文本、图像、音频等都有内置
- MindSpore的Pipeline设计和并行处理能力使得数据预处理更加高效
- 可通过
GeneratorDataset接口实现自定义方式的数据集加载 - 可迭代的数据集,可以通过迭代的方式逐步获取数据样本,生成器
generator也属于可迭代的数据集类型
笔记
- 数据获取
import numpy as np
from mindspore.dataset import vision
from mindspore.dataset import MnistDataset, GeneratorDataset
import matplotlib.pyplot as plt
# Download data from open datasets
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)
这里找数据集:https://www.mindspore.cn/docs/zh-CN/r2.3.0rc2/api_python/mindspore.dataset.html
2.数据迭代
# shuffle 消除数据排列造成的分布不均问题,及打乱数据顺序
train_dataset = MnistDataset("MNIST_Data/train", shuffle=True)
def visualize(dataset):
figure = plt.figure(figsize=(4, 4))
cols, rows = 3, 3
plt.subplots_adjust(wspace=0.5, hspace=0.5)
for idx, (image, label) in enumerate(dataset.create_tuple_iterator()):
figure.add_subplot(rows, cols, idx + 1)
plt.title(int(label))
plt.axis("off")
plt.imshow(image.asnumpy().squeeze(), cmap="gray")
if idx == cols * rows - 1:
break
plt.show()

3. 数据预处理
#图像统一除以255,数据类型由uint8转为了float32
train_dataset = train_dataset.map(vision.Rescale(1.0 / 255.0, 0), input_columns='image')