文章目录
- 概述
- 什么是异常检测
- 异常检测应用
- 与二分类分类器的辨析
- 广义分布外检测(OOD)
- 异常检测分类
- Deep Learning for Feature Extraction(用于特征提取的深度学习)
- Learning Feature Representations of Normality(学习正常的特征表征)
- End-to-end anomaly score learning(端对端的异常分数学习)
- 异常检测方法介绍 -- 自编码器
- 什么是自编码器
- 基于生成对抗网络(GAN-Based)
- 基于伪造异常样本
- 基于知识蒸馏
- 基于内存查询
- 基于归一化流
概述
什么是异常检测
给定一组训练数据
{
x
1
,
x
2
,
.
.
.
.
.
.
,
x
N
}
\{x^1, x^2,......,x^N\}
{x1,x2,......,xN},需要找到一个检测输入 𝑥 与训练数据是否相似的方程。不同的方法使用不同的度量来衡量相似性。

用一个方程用来检测输入 x 和已有的数据是否相似。相似则正常,否则异常。
异常检测应用
- 欺诈检测
- 网络入侵检测
- 癌症检测
与二分类分类器的辨析
此处需要注意异常检测并不等于二分类分类器。
在异常检测中数据不能被简单的视为正常、异常两个类别。特别是在异常中,实际上是把异常尽可能的按照各自属性分为了具体的类。在一些极端的情况下,甚至无法找到异常的样本。

正常的数据中,它们都是宝可梦这一分类下的。
但是在异常数据中,亚古兽属于数码宝贝分类、幽幽子属于二次元人物分类、水壶更是属于日常用品分类,这是不能一概而论的。另外要是有某些不可名状的图片,TA们甚至无法被确定分到哪个类别中。
异常检测是这样的,二分类分类器只需要分成正常和异常就好了,而异常检测需要考虑的就很多了,需要分成各个明确的种类。
广义分布外检测(OOD)
红框就圈了这些。
在单类新颖性检测中,正常图像属于一类。具有语义偏移的图像将被视为异常。
在多类新颖性检测中,正常图像属于多个类。具有语义转换的图像将被视为异常。

异常检测分类
标题后面的汉语是我为了方便理解自个翻译的,不一定准确。
Deep Learning for Feature Extraction(用于特征提取的深度学习)
- 主要思路
旨在利用深度学习从高维或者线性不可分的数据中提取低维特征表示,用于后续的异常检测。特征提取和异常评分是完全分离的,相互独立。
人话:用深度学习从高维的数据提取出低维的特征,再对其异常评分。 - 优点
(1)大量的预训练深度模型和异常评分模型可直接使用。现有模型多
(2)深度特征提取器比线性方法更有效。 - 缺点:
(1)特征提取和异常评分是分离的,得到的异常评分可能次优。
(2)预训练模型只能接受特定的类型。
Learning Feature Representations of Normality(学习正常的特征表征)
- 主要思路
这类方法通过优化一般特征学习目标函数来学习数据的表示,该目标函数不是为异常检测而设计的,但学习到的高级特征能够用于异常检测,因为这些高级特征包含了数据的隐藏规律。
人话:优化特征学习函数。学到的高级特征可以用来异常检测。 - 优点
(1)产生正常样本的能力很强,但是产生异常样本的能力很弱,因此适用于异常检测。
(2)GANs 的现有工作大多可以用于异常检测。 - 缺点
(1)由于训练时可能存在难以收敛,模式坍塌等问题,有时训练难以进行。
(2)如果数据集分布复杂或存在 outliers查的意思是 异常值;离群值,会导致模型生成的数据点偏离主流特征。
(3)由于模型本身是为了合成数据设计而不是异常检测设计,因此结果可能是次优的。
End-to-end anomaly score learning(端对端的异常分数学习)
- 主要思路
旨在以端到端的方式学习标量异常分数。这种方法中的异常评分不依赖于现有的异常度量;它往往有一个直接学习异常分数的神经网络。
人话:有一个神经网络,在端到端的方式中直接学习异常分数。 - 优点
(1)这种模型是端到端式的对抗式优化。
(2)已有的对抗学习和分类模型有助于发展。 - 缺点
(1)很难生成近似于 未知异常样本 的参考样本。
(2)GAN 的不稳定可能导致生成样本的质量。
(3)应用局限于半监督的异常检测场景。
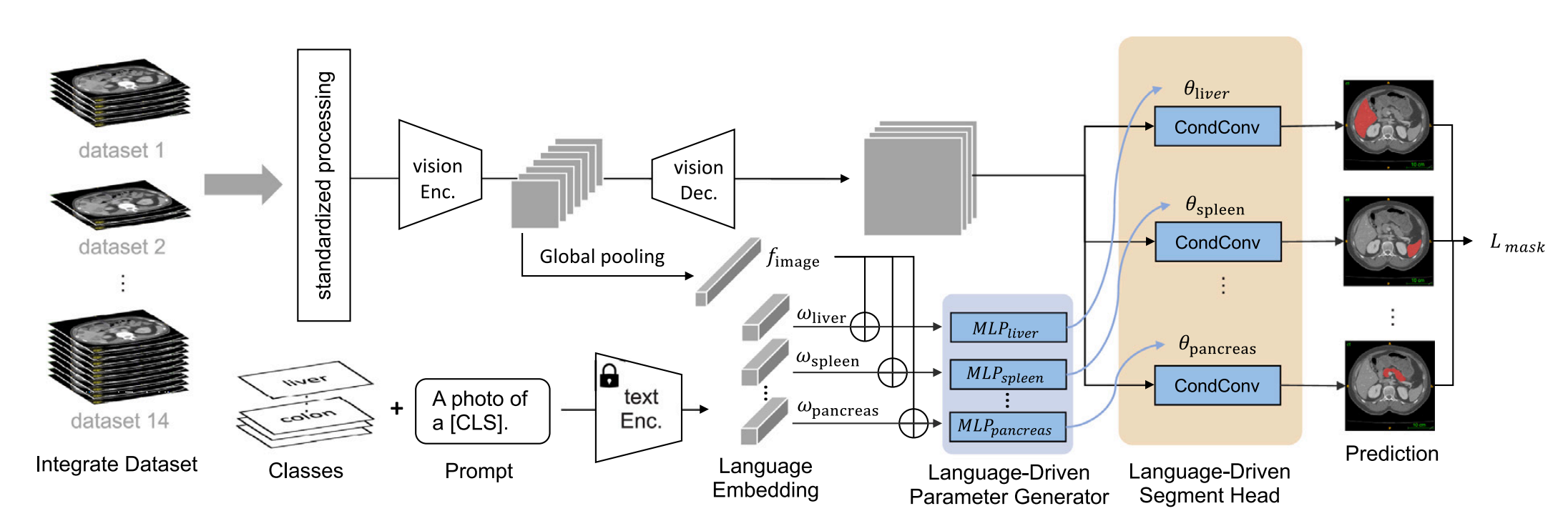
异常检测方法介绍 – 自编码器
什么是自编码器

如图中所示,自编码器是一种利用反向传播算法使得输出值接近输入值的神经网络。它先将输入压缩成潜在空间表征,然后通过这种表征来重构输出。自编码器分为两个部分:编码器和解码器。
(1)编码器将输入压缩成潜在空间表征,记为
h
=
f
(
x
)
h=f(x)
h=f(x)。
(2)解码器重构来自潜在空间表征的输入,记为
r
=
g
(
h
)
r=g(h)
r=g(h)。
综合上述两个部分,完整的自编码器可以由
g
(
f
(
x
)
)
=
r
g(f(x))=r
g(f(x))=r 表示。
在异常检测中,首先利用已有正常数据训练出自编码器。对于测试中的正常数据,可以通过这种自编码器被重建;但对于异常的数据,则会因为重建损失过大而无法被重建。如下面两张图示例。


基于生成对抗网络(GAN-Based)
太多公式和计算流程,我按顺序做一个概述性描述。……要是还是不想看就直接看步骤后的总结吧。
(1)在 GAN 的潜在空间中随机采样一个潜在向量
z
1
z_1
z1。
(2)生成器
G
G
G 用
z
1
z_1
z1 生成图像
G
(
z
1
)
G(z_1)
G(z1)。
(3)将
G
(
z
1
)
G(z_1)
G(z1) 和真实图像
x
x
x 比较,计算残差损失。
(4)分别对
G
(
z
1
)
G(z_1)
G(z1) 和
x
x
x 提取特征表示,计算判别损失。
(5)根据这两个损失和其它参数计算总损失,并更新潜在向量。
总结:将生成的图像与真实图像进行比较,计算残差损失和判别损失,并通过优化潜在向量来最小化这些损失,从而评估图像的异常程度。

基于伪造异常样本
- 学习表示阶段
使用了CutPaste来伪造异常。 - 异常检测阶段
异常检测流程包括两个子网络:重构子网络(Reconstructive sub-network)和判别子网络(Discriminative sub-network)。
首先,重构子网络通过训练学习将伪造异常图片还原成正常图片,隐式检测出异常区域并进行修复。
然后,重构子网络的输出和输入图像被连接并输入判别子网络中,判别子网络生成异常图。
基于知识蒸馏
教师网络是在图像分类任务上预训练的强大网络;学生网络是与教师网络结构一致,但是未经训练的“小白”网络。
让学生网络在多个特征尺度学习教师网络的正常特征,从而在检测异常样本时两个网络的特征展现出差异。
基于内存查询
在训练阶段,模型会记录典型的正常模式,并更新内存内容以表示正常数据元素。
在测试阶段,模型会根据输入选择一小部分正常内存项进行重构,以便与正常数据进行比较,从而突出异常情况。
在异常检测过程中,利用内存库M中的补丁特征,得到异常分数。
基于归一化流
通过可逆的分布将样本映射到特定分布(比如高斯分布),利用分布的概率公式来计算样本概率。