背景
随着数字化建设的持续深入,企业的业务规模迎来了高速发展,其数据规模也呈现爆炸式增长,如果继续使用传统解决方案,将所有数据存储在一个表中,对数据的查询和维护效率将是一个巨大的挑战,在这个背景下,表分区技术应运而生。
分区的其核心思想是将数据按照某个特定的标准分成多个物理块,每个物理块即为一个分区,从而使数据的存储和管理更加高效,可帮助我们我们实现稳定的存储增长、高性能和易维护。
优势
- 提升查询性能: 通过将数据分成多个分区,查询只需要访问特定分区的数据,避免扫描全表,减少磁盘I/O,从而加速查询操作,降低响应时间。
- 提升运维便利: 分区使得数据维护操作更加精确,例如我们按年分区,要删除指定年份的数据,无需使用性能开销极大的 DELETE FROM … WHERE year=2001,而是直接使用 DROP TABLE table_partition_2001来快速删除分区数据(几乎无开销)。
- 提升可用性和扩展性:表分区允许根据业务需求进行定制,例如按时间、业务部门等进行分区,单个分区出现故障,其他分区数据仍可用,且修复成本更低;同时避免单表的无限增长而导致性能下降,为系统的可扩展性提供了更好的基础。
何时分区
在决定是否对表进行分区时,需要综合考虑以下几个因素,以确保分区对系统性能和数据管理带来实际的好处:
- 查询模式相对固定:例如经常按业务部门查询,可将其作为分区键以最大限度地减少查询所需扫描的数据规模,例如对超大数据量的表(如 500 GB 以上,非绝对标准)收益较为明显,可明显地降低查询耗时,提升查询效率。
- 数据按时间有序:例如日志数据,使用时间作为分区键可以使查询按时间范围过滤更加高效,同时方便对访问量极低的旧数据进行管理和归档。
设计表分区策略
设计适当的表分区策略是确保分区表性能最大化的关键一步,以下是一些步骤和考虑因素,可帮助您制定有效的分区策略:
- 分析查询需求:分析查询需求,重点关注经常被查询的数据的过滤条件,以选择适当的分区键,使得满足这些过滤条件的数据能够集中在同一分区中,从而优化查询性能。
- 确认数据类型:推荐使用 STRING 或时间类型的列作为分区键,通常可以帮助在数据均衡和分区数量上取得较好的平衡。
- 权衡分区规模:常规情况下,单个分区的数据量控制在 500GB 内,如果集群的 CPU 核数较多,可适当提升,此外,我们还需要关注数据的增长趋势,例如数据按时间增长,时间则是一个优秀的分区键,查询按时间范围过滤时会更高效。
- 选择分区策略:ArgoDB 支持范围分区和单值分区:
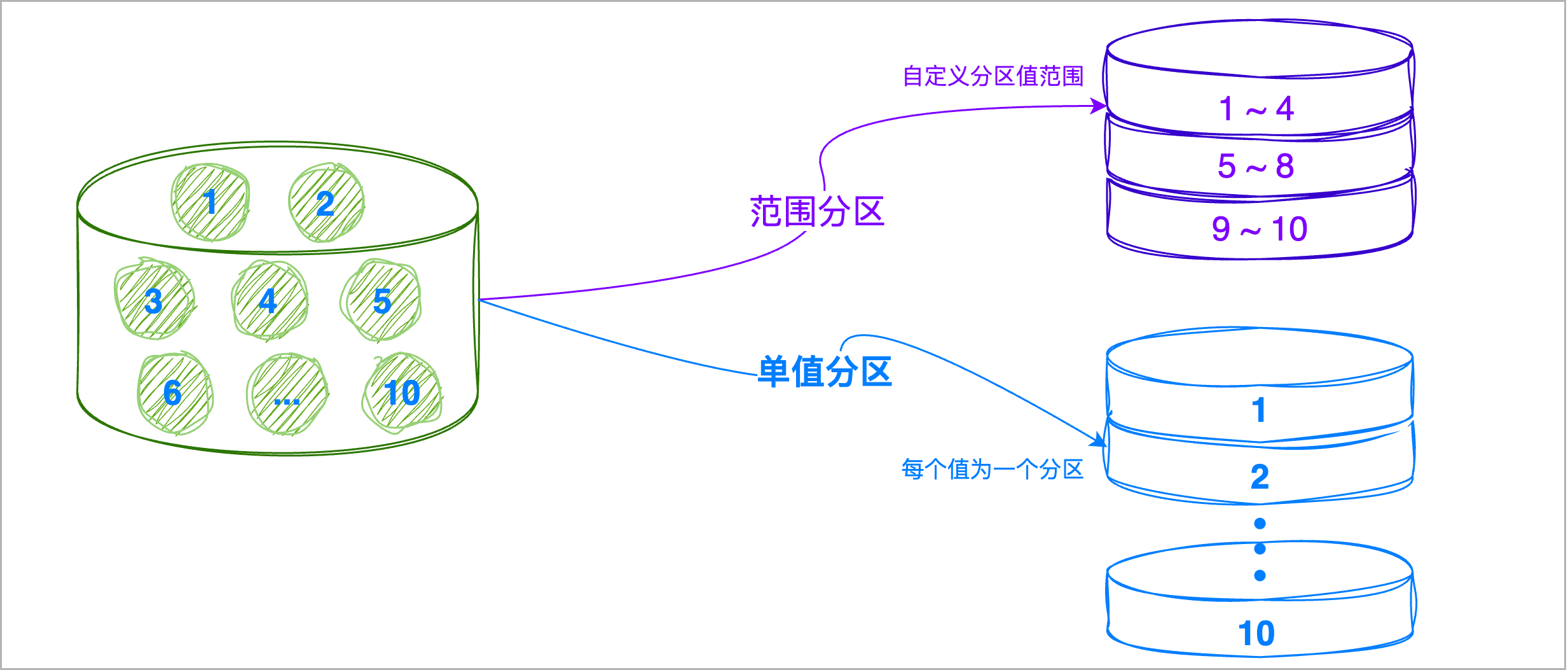
| 分区类型 | 说明 |
|---|---|
| 范围分区 | 按照分区键的值范围来划分分区,执行分区时可基于列值分布均衡度和查询需求来自由划分范围,可避免分区间的数据规模差距过大,提升查询效率。 |
| 单值分区 | 将拥有相同分区键值的记录划分在同一分区中,适用于列基数较少(例如城市名)且分布较为均衡的场景。 |
最佳实践
创建分区表
本案例中,我们以 TPC-DS 样例数据集为例,演示在搭建销售数据分析的数据仓库过程中,遇到的数据分区需求和具体流程。目前,我们的事实表 store_sales 的规模已经增长到了约 2.88 亿条数据(约 20 GB)且持续增长中,日常的报表分析会使用销售日期来作为过滤条件进行,我们希望优化按销售日期范围查询的性能,简化后的 ER 图如下:

操作流程
1. 选择分区键。
基于前面的介绍和场景需求,我们优先选择与时间关联的列作为分区键,而通过上面简化的 ER 图可以得知,store_sales 表虽然没有直接存储时间信息,但是通过外键(ss_sold_date_sk)关联到名为 date_dim 维度表的 d_date_sk 列,所以初步选择 ss_sold_date_sk 作为分区键。
2. 了解分区键的数据特性。
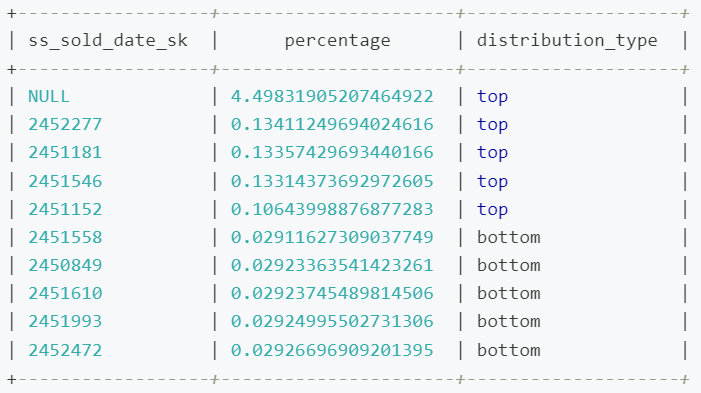
初步选择分区键后,我们还需要关注分区键 ss_sold_date_sk 的数据分布情况,为后续的分区设置提供参考,例如通过下述语句,查看 ss_sold_date_sk 列值中,排名前 5 个和倒数 5 个的数据占比辅助判断数据分布情况。
WITH partition_percentages AS (
SELECT ss_sold_date_sk, COUNT(*) * 100.0 / SUM(COUNT(*)) OVER() AS percentage
FROM store_sales
GROUP BY ss_sold_date_sk
)
SELECT ss_sold_date_sk, percentage, 'top' AS distribution_type
FROM partition_percentages
ORDER BY percentage DESC
LIMIT 5
UNION ALL
SELECT ss_sold_date_sk, percentage, 'bottom' AS distribution_type
FROM partition_percentages
ORDER BY percentage ASC
LIMIT 5;
输出结果如下,可以看到数据在时间分布上相对均衡,只有一个特殊 NULL 值占比约 4.5%,那么我们在分区时基本可以依据自然时间(如月份或季度)来划分,如果某些时间点对应的数据非常多,可在分区时适当调整其对应的分区范围。
除上述方法外,您还可以通过数据采样、标准差、直方图等方法来辅助判断数据分布的均衡情况。
3. 选择分区策略和分区规模。
i. 首先,我们查询候选的分区键(ss_sold_date_sk)的去重数来判断是否适用于单值分区。
SELECT COUNT(DISTINCT ss_sold_date_sk) AS distinct_count FROM store_sales;
返回结果为 1823,该列的基数较大,如果选择单值分区会导致数据过于分散,所以此处我们选择分区策略为范围分区。
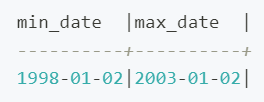
ii. 接下来,我们关联查询事实表 store_sales 和维度表 date_dim,查看候选的分区键的值范围,即日期分布范围。
SELECT MIN(d.d_date) AS min_date, MAX(d.d_date) AS max_date
FROM store_sales s
JOIN date_dim d ON s.ss_sold_date_sk = d.d_date_sk;
输出结果如下,日期跨度为 5 年。
iii. 权衡并确认分区规模。
通过前面的分析,我们的查询通常是按照季度或月度数据来分析并输出报表,结合我们前面掌握候选的分区键的数据分布情况,同时考虑到分区数量不宜过多以避免维护的复杂性和额外的负载,权衡分区数和各分区预计包含的数据规模后,最终确定按照季度来划分数据:
数据的时间跨度为 5 年,按照季度划分则预计会创建 20 个分区,每个分区包含约 1400 万条(约 1 GB)的数据。
4. 通过 Beeline 登录至 ArgoDB 数据库,执行表分区操作。
注意:关于如何通过 Beeline 登录数据库,请参考Inceptor/ArgoDB如何连接数据库。
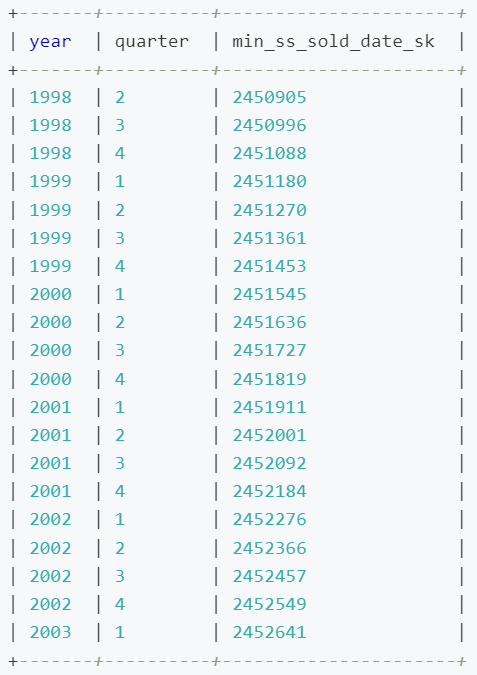
i. 由于 store_sales 表的 ss_sold_date_sk 存储的不是具体时间,我们先通过下述语句找出各分区对应的键值。
-- 创建分区时采用 VALUES LESS THAN 语法,所以开始时间为数据范围内的第二季度第一天,即 1998-04-01
SELECT DISTINCT YEAR(d.d_date) AS year,
QUARTER(d.d_date) AS quarter,
MIN(s.ss_sold_date_sk) AS min_ss_sold_date_sk
FROM store_sales s
JOIN date_dim d ON s.ss_sold_date_sk = d.d_date_sk
WHERE d.d_date BETWEEN '1998-04-01' AND '2003-01-02'
GROUP BY year, quarter
ORDER BY year, quarter;
输出结果如下:
ii. 确定分区键值后,执行下述命令创建分区表,详细语法可参考开发者指南中的定义分区章节。
CREATE TABLE store_sales_partition(
ss_sold_time_sk INTEGER ,
ss_item_sk INTEGER NOT NULL,
ss_customer_sk INTEGER ,
ss_cdemo_sk INTEGER ,
ss_hdemo_sk INTEGER ,
ss_addr_sk INTEGER ,
ss_store_sk INTEGER ,
ss_promo_sk INTEGER ,
ss_ticket_number BIGINT NOT NULL,
ss_quantity INTEGER ,
ss_wholesale_cost FLOAT ,
ss_list_price FLOAT ,
ss_sales_price FLOAT ,
ss_ext_discount_amt FLOAT ,
ss_ext_sales_price FLOAT ,
ss_ext_wholesale_cost FLOAT ,
ss_ext_list_price FLOAT ,
ss_ext_tax FLOAT ,
ss_coupon_amt FLOAT ,
ss_net_paid FLOAT ,]
ss_net_paid_inc_tax FLOAT ,
ss_net_profit FLOAT )
PARTITIONED BY RANGE(ss_sold_date_sk INTEGER) (
PARTITION p1998q1 VALUES LESS THAN (2450905),
PARTITION p1998q2 VALUES LESS THAN (2450996),
PARTITION p1998q3 VALUES LESS THAN (2451088),
PARTITION p1998q4 VALUES LESS THAN (2451180),
PARTITION p1999q1 VALUES LESS THAN (2451270),
PARTITION p1999q2 VALUES LESS THAN (2451361),
PARTITION p1999q3 VALUES LESS THAN (2451453),
PARTITION p1999q4 VALUES LESS THAN (2451545),
PARTITION p2000q1 VALUES LESS THAN (2451636),
PARTITION p2000q2 VALUES LESS THAN (2451727),
PARTITION p2000q3 VALUES LESS THAN (2451819),
PARTITION p2000q4 VALUES LESS THAN (2451911),
PARTITION p2001q1 VALUES LESS THAN (2452001),
PARTITION p2001q2 VALUES LESS THAN (2452092),
PARTITION p2001q3 VALUES LESS THAN (2452184),
PARTITION p2001q4 VALUES LESS THAN (2452276),
PARTITION p2002q1 VALUES LESS THAN (2452366),
PARTITION p2002q2 VALUES LESS THAN (2452457),
PARTITION p2002q3 VALUES LESS THAN (2452549),
PARTITION p2002q4 VALUES LESS THAN (2452641),
PARTITION pmax VALUES LESS THAN (MAXVALUE))
STORED AS HOLODESK
WITH PERFORMANCE;
5. 在业务低峰期执行下述命令,将 TXT 格式的外表数据写入至刚刚创建的分区表中。
-- 开启数据动态写入,即写入时基于分区键的值自动将数据放置到对应分区中
set hive.exec.dynamic.partition=true;
set stargate.dynamic.partition.enabled=true;
-- 执行数据写入操作
INSERT INTO store_sales_partition
PARTITION (ss_sold_date_sk)
SELECT
ss_sold_time_sk,
ss_item_sk,
ss_customer_sk,
ss_cdemo_sk,
ss_hdemo_sk,
ss_addr_sk,
ss_store_sk,
ss_promo_sk,
ss_ticket_number,
ss_quantity,
ss_wholesale_cost,
ss_list_price,
ss_sales_price,
ss_ext_discount_amt,
ss_ext_sales_price,
ss_ext_wholesale_cost,
ss_ext_list_price,
ss_ext_tax,
ss_coupon_amt,
ss_net_paid,
ss_net_paid_inc_tax,
ss_net_profit,
ss_sold_date_sk
FROM tpcds_text_100.store_sales;
注意:执行时间由集群负载、数据规模等因素共同决定,您可以登录 DBA Service,在查询页面中查看任务执行进度。

6. (可选)数据导入执行完成后,通过 SELECT COUNT(*) FROM store_sales_partition 来确认数据条目数与原表一致。
性能对比
接下来,我们选择一个典型的查询场景,即查询特定季度的销售数据并计算净利润,并使用分区前后的情况来进行对比,以展示分区对于查询性能的影响。
注:为更好地展示分区前后的性能对比,本案例使用的机器资源存在一定限制,因此查询响应时间仅供演示参考,真实业务场景中分区前的查询效率和速度会更高。
分区前
在分区之前,我们将数据存储在单一的大表 store_sales 中,假设我们查询 1999 年第一季度的净利润,查询 SQL 如下:
SELECT SUM(ss_net_profit) AS net_profit_1999q1
FROM store_sales
WHERE ss_sold_date_sk >= ( -- 通过子查询获取开始时间对应的 ss_sold_date_sk
SELECT MIN(d_date_sk)
FROM date_dim
WHERE d_year = 1999 AND d_qoy = 1
)
AND ss_sold_date_sk < ( -- 通过子查询获取结束时间对应的 ss_sold_date_sk
SELECT MIN(d_date_sk)
FROM date_dim
WHERE d_year = 1999 AND d_qoy = 2
);
等待查询执行完成,命令行将返回查询结果和耗时,具体如下:

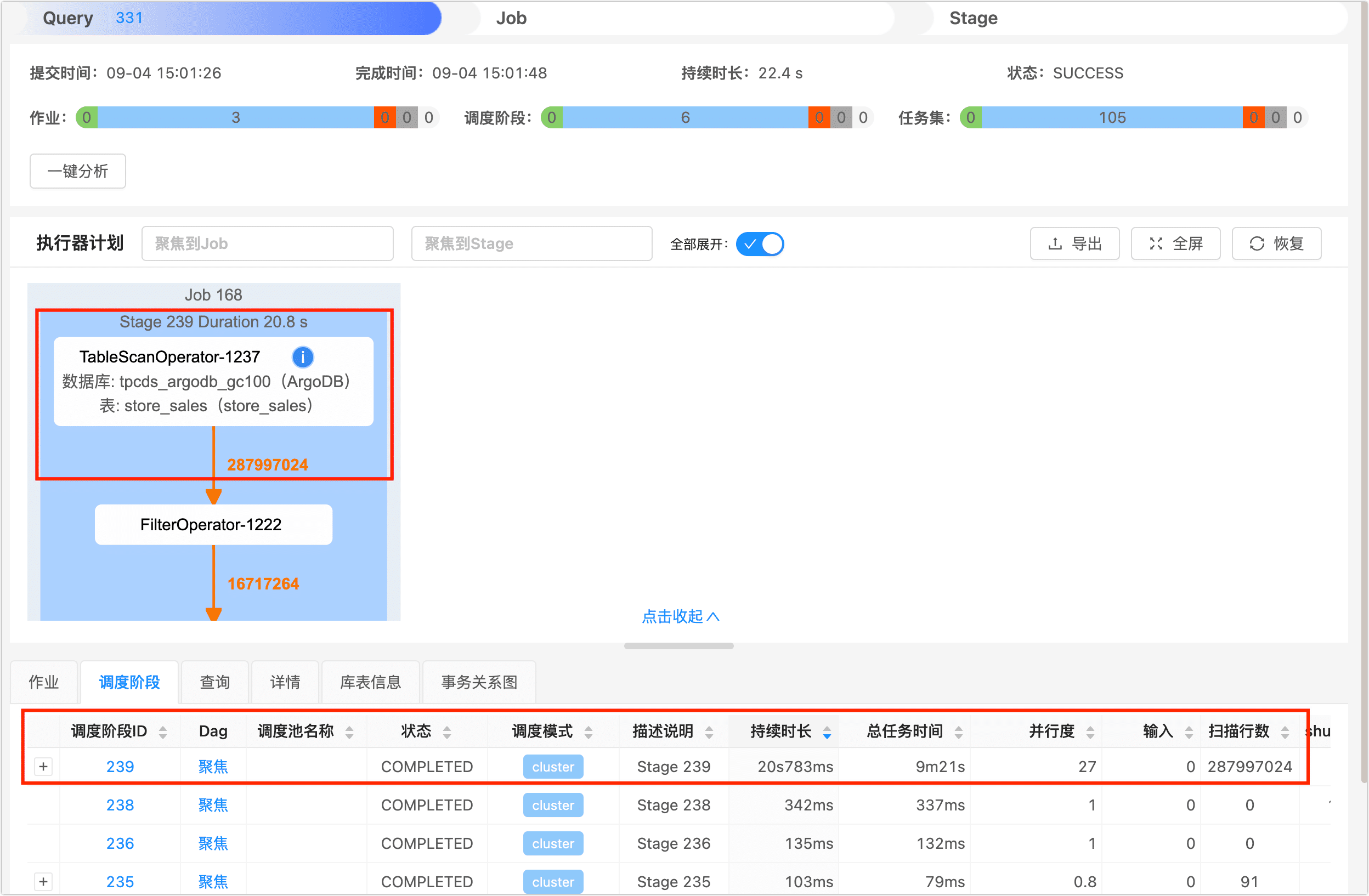
本次查询耗时约为 28.5 秒,为了进一步了解查询任务在任务执行的各阶段的耗时情况,我们登录到 DBA Service 平台,在查询页面找到并单击刚刚执行完成的查询作业,然后单击调度阶段页签,可以看到该查询任务被分为 4 个调度阶段,时间主要花费在了 ID 为 1679 的调度阶段上,原因是它为了取出满足 WHERE 条件的数据,执行了全表扫描,即扫描行数为 287997024(约 2.87 亿)。
分区后
而在执行表分区后,我们使用分区表 store_sales_partition 执行相同的查询,本次查询只扫描了 16200992(约 1600 万)条记录,整体仅耗时为 6.9 秒,相较于之前查询速度提升了 4 倍以上。
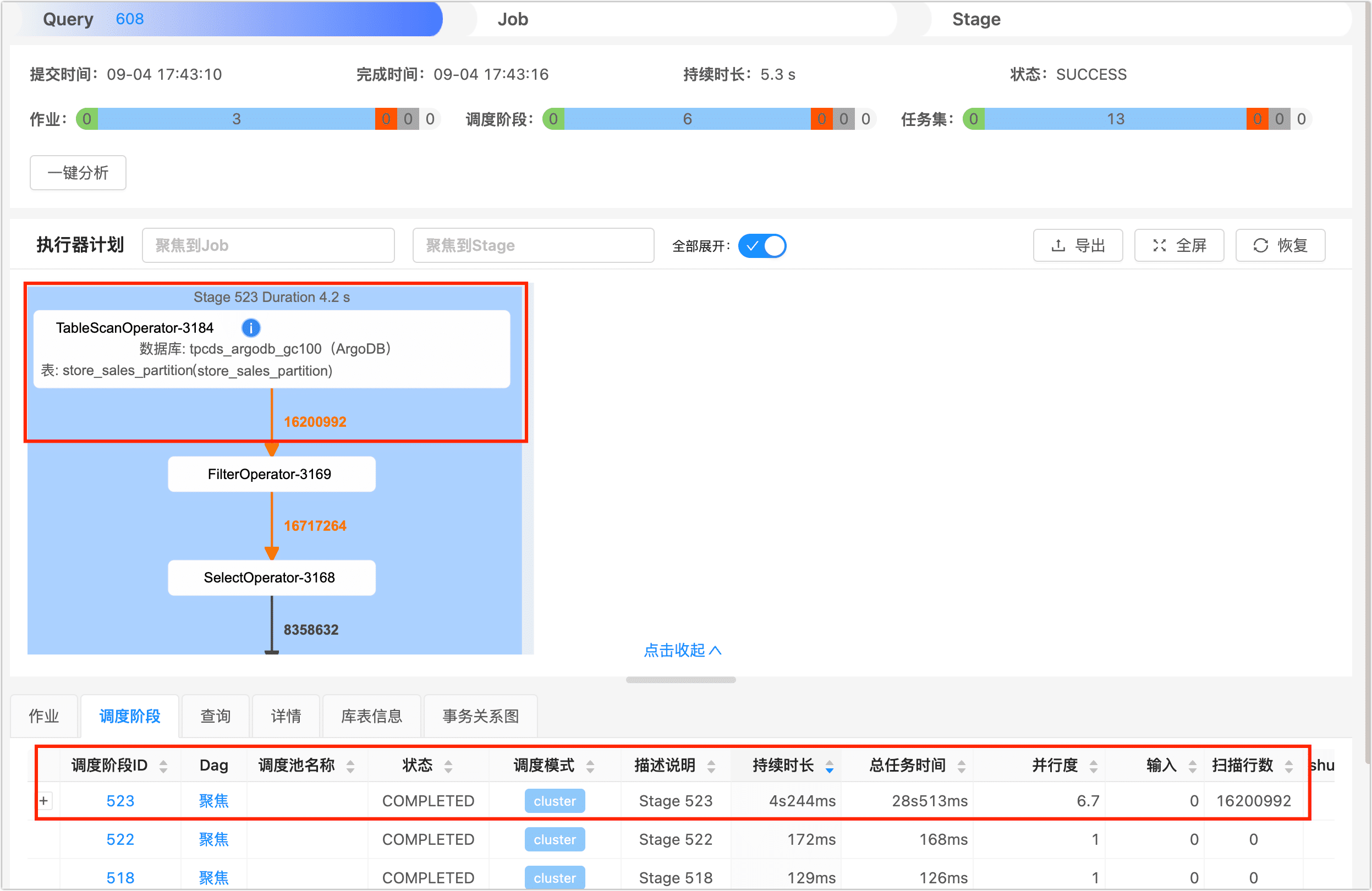
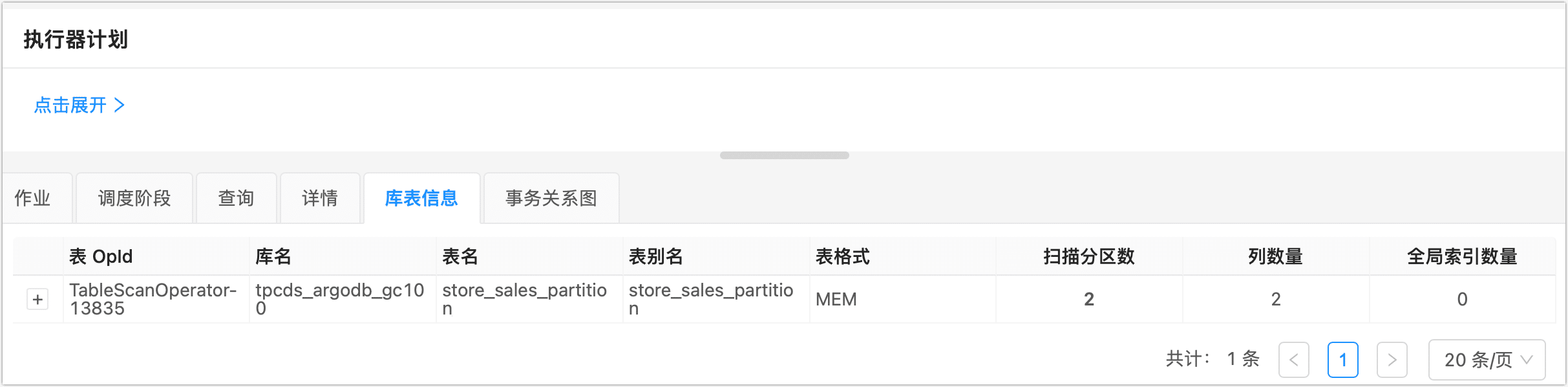
单击库表信息页签,可以看到本次查询的扫描分区数、列数和索引数等信息。
通过比较分区前后的查询性能,我们可以得出以下结论:
- 分区后的查询性能更优:由于分区表的优化,查询性能得到了显著提升。
- 分区使得查询范围更精确:分区键的使用使得查询范围更加精确,避免了不必要的数据扫描,从而提高了查询效率。
通过以上的性能对比,我们可以看到分区表的优势,特别是在处理大量数据和复杂查询时,分区能够显著提升查询性能和响应时间。这也强调了在数据模型设计和查询优化中合理使用分区的重要性。
维护分区表
对数据表执行分区操作,不仅可以更好地服务于查询,还可以帮助您更有效地维护历史数据,保障查询性能、数据管理和存储效率的持续优化。
- 性能保持:随着时间的推移,分区表可以保持查询性能的稳定。由于数据被分割成多个分区,查询通常只需要扫描特定分区,而不是整个表,从而提高了查询性能。
- 数据管理:分区表使得数据管理更加灵活。您可以轻松地添加、删除或迁移分区,而不会影响整个表。这对于数据归档、数据清理以及数据的日常维护非常有用。
- 节省存储:通过仅加载和保留必要的分区,避免不必要的数据持续占用存储资源。
接下来,我们通过几个案例演示如何维护分区数据:
删除旧分区
如果某些数据已经不再需要,您可以轻松地删除旧的分区,释放存储空间,且此操作相较于原先基于条件过滤数据并删除,其开销极低,示例如下:
ALTER TABLE store_sales_partition
DROP PARTITION p2000q1;
添加新分区
假设您的分区表按季度分区,现在要添加一个新的季度分区,例如第四季度,随后您可以将新的数据加载至该分区:
ALTER TABLE store_sales_partition_noncluster
ADD PARTITION p2003q4 VALUES LESS THAN (2452733);
提示:如果您在创建分区表时设置了 MAXVALUE 分区,我们需要先将 MAXVALUE 对应的分区删除才可以继续创建新分区。更多关于分区的的操作,请参考开发者指南中定义分区章节。