基于llama3-8B-instruct的调用部署以及lora微调
- 1 Llama-3-8B-Instruct 基于FastApi 部署调用
- 2 LLaMA3-8B-Instruct langchain 接入
- 3 LaMA3-8B-Instruct 基于streamlit的web demo部署
- LLaMA3-8B-Instruct Lora 微调
- 参考:
1 Llama-3-8B-Instruct 基于FastApi 部署调用
环境准备
在 Autodl 平台中租赁一个 3090 等 24G 显存的显卡机器,如下图所示镜像选择 PyTorch–>2.1.0–>3.10(ubuntu22.04)–>12.1。 接下来打开刚刚租用服务器的 JupyterLab,并且打开其中的终端开始环境配置、模型下载和运行演示。
pip 换源加速下载并安装依赖包
# 升级pip
python -m pip install --upgrade pip
# 更换 pypi 源加速库的安装
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install fastapi==0.110.2
pip install uvicorn==0.29.0
pip install requests==2.31.0
pip install modelscope==1.11.0
pip install transformers==4.40.0
pip install accelerate==0.29.3
fastapi==0.110.2 langchain==0.1.16 modelscope==1.11.0
streamlit==1.33.0 torch==2.1.2+cu121 transformers==4.40.0 uvicorn==0.29.0
使用 modelscope 中的 snapshot_download 函数下载模型,第一个参数为模型名称,参数 cache_dir 为模型的下载路径。
在 /root/autodl-tmp 路径下新建 model_download.py 文件并在其中输入以下内容,粘贴代码后请及时保存文件,如下图所示。并运行 python /root/autodl-tmp/model_download.py 执行下载,模型大小为 15GB,下载模型大概需要 2 分钟。
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
import os
model_dir = snapshot_download('LLM-Research/Meta-Llama-3-8B-Instruct',
cache_dir='/root/autodl-tmp', revision='master')
代码准备:
在 /root/autodl-tmp 路径下新建 api.py 文件并在其中输入以下内容,粘贴代码后请及时保存文件。下面的代码有很详细的注释,大家如有不理解的地方,欢迎提出 issue。
from fastapi import FastAPI, Request
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
import uvicorn
import json
import datetime
import torch
# 设置设备参数
DEVICE = "cuda" # 使用CUDA
DEVICE_ID = "0" # CUDA设备ID,如果未设置则为空
CUDA_DEVICE = f"{DEVICE}:{DEVICE_ID}" if DEVICE_ID else DEVICE # 组合CUDA设备信息
# 清理GPU内存函数
def torch_gc():
if torch.cuda.is_available(): # 检查是否可用CUDA
with torch.cuda.device(CUDA_DEVICE): # 指定CUDA设备
torch.cuda.empty_cache() # 清空CUDA缓存
torch.cuda.ipc_collect() # 收集CUDA内存碎片
# 构建 chat 模版
def bulid_input(prompt, history=[]):
system_format='<|start_header_id|>system<|end_header_id|>\n\n{content}<|eot_id|>'
user_format='<|start_header_id|>user<|end_header_id|>\n\n{content}<|eot_id|>'
assistant_format='<|start_header_id|>assistant<|end_header_id|>\n\n{content}<|eot_id|>\n'
history.append({'role':'user','content':prompt})
prompt_str = ''
# 拼接历史对话
for item in history:
if item['role']=='user':
prompt_str+=user_format.format(content=item['content'])
else:
prompt_str+=assistant_format.format(content=item['content'])
return prompt_str
# 创建FastAPI应用
app = FastAPI()
# 处理POST请求的端点
@app.post("/")
async def create_item(request: Request):
global model, tokenizer # 声明全局变量以便在函数内部使用模型和分词器
json_post_raw = await request.json() # 获取POST请求的JSON数据
json_post = json.dumps(json_post_raw) # 将JSON数据转换为字符串
json_post_list = json.loads(json_post) # 将字符串转换为Python对象
prompt = json_post_list.get('prompt') # 获取请求中的提示
history = json_post_list.get('history', []) # 获取请求中的历史记录
messages = [
# {"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
# 调用模型进行对话生成
input_str = bulid_input(prompt=prompt, history=history)
input_ids = tokenizer.encode(input_str, add_special_tokens=False, return_tensors='pt').cuda()
generated_ids = model.generate(
input_ids=input_ids, max_new_tokens=512, do_sample=True,
top_p=0.9, temperature=0.5, repetition_penalty=1.1, eos_token_id=tokenizer.encode('<|eot_id|>')[0]
)
outputs = generated_ids.tolist()[0][len(input_ids[0]):]
response = tokenizer.decode(outputs)
response = response.strip().replace('<|eot_id|>', "").replace('<|start_header_id|>assistant<|end_header_id|>\n\n', '').strip() # 解析 chat 模版
now = datetime.datetime.now() # 获取当前时间
time = now.strftime("%Y-%m-%d %H:%M:%S") # 格式化时间为字符串
# 构建响应JSON
answer = {
"response": response,
"status": 200,
"time": time
}
# 构建日志信息
log = "[" + time + "] " + '", prompt:"' + prompt + '", response:"' + repr(response) + '"'
print(log) # 打印日志
torch_gc() # 执行GPU内存清理
return answer # 返回响应
# 主函数入口
if __name__ == '__main__':
# 加载预训练的分词器和模型
model_name_or_path = '/root/autodl-tmp/LLM-Research/Meta-Llama-3-8B-Instruct'
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=False)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, device_map="auto", torch_dtype=torch.bfloat16).cuda()
# 启动FastAPI应用
# 用6006端口可以将autodl的端口映射到本地,从而在本地使用api
uvicorn.run(app, host='0.0.0.0', port=6006, workers=1) # 在指定端口和主机上启动应用
Api 部署:
在终端输入以下命令启动 api 服务:
cd /root/autodl-tmp
python api.py
加载完毕后出现如下信息说明成功。
默认部署在 6006 端口,通过 POST 方法进行调用,可以使用 curl 调用,如下所示:
curl -X POST "http://127.0.0.1:6006" \
-H 'Content-Type: application/json' \
-d '{"prompt": "你好"}'
得到的返回值如下所示:
{
"response": "😊 你好!我也很高兴见到你!有什么问题或话题想聊天吗?",
"status": 200,
"time": "2024-04-20 23:11:00"
}
也可以使用 python 中的 requests 库进行调用,如下所示:
import requests
import json
def get_completion(prompt):
headers = {'Content-Type': 'application/json'}
data = {"prompt": prompt}
response = requests.post(url='http://127.0.0.1:6006', headers=headers, data=json.dumps(data))
return response.json()['response']
if __name__ == '__main__':
print(get_completion('你好'))
2 LLaMA3-8B-Instruct langchain 接入
pip 换源加速下载并安装依赖包
python -m pip install --upgrade pip
# 更换 pypi 源加速库的安装
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install modelscope==1.11.0
pip install langchain==0.1.15
pip install "transformers>=4.40.0" accelerate tiktoken einops scipy transformers_stream_generator==0.1.16
pip install -U huggingface_hub
代码准备:
为便捷构建 LLM 应用,我们需要基于本地部署的** LLaMA3_LLM**,自定义一个 LLM 类,将 LLaMA3 接入到 LangChain 框架中。完成自定义 LLM 类之后,可以以完全一致的方式调用 LangChain 的接口,而无需考虑底层模型调用的不一致。
基于本地部署的 LLaMA3 自定义 LLM 类并不复杂,我们只需从 LangChain.llms.base.LLM 类继承一个子类,并重写构造函数与 _call 函数即可:
from langchain.llms.base import LLM
from typing import Any, List, Optional
from langchain.callbacks.manager import CallbackManagerForLLMRun
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
class LLaMA3_LLM(LLM):
# 基于本地 llama3 自定义 LLM 类
tokenizer: AutoTokenizer = None
model: AutoModelForCausalLM = None
def __init__(self, mode_name_or_path :str):
super().__init__()
print("正在从本地加载模型...")
self.tokenizer = AutoTokenizer.from_pretrained(mode_name_or_path, use_fast=False)
self.model = AutoModelForCausalLM.from_pretrained(mode_name_or_path, torch_dtype=torch.bfloat16, device_map="auto")
self.tokenizer.pad_token = self.tokenizer.eos_token
print("完成本地模型的加载")
def bulid_input(self, prompt, history=[]):
user_format='<|start_header_id|>user<|end_header_id|>\n\n{content}<|eot_id|>'
assistant_format='<|start_header_id|>assistant<|end_header_id|>\n\n{content}<|eot_id|>'
history.append({'role':'user','content':prompt})
prompt_str = ''
# 拼接历史对话
for item in history:
if item['role']=='user':
prompt_str+=user_format.format(content=item['content'])
else:
prompt_str+=assistant_format.format(content=item['content'])
return prompt_str
def _call(self, prompt : str, stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any):
input_str = self.bulid_input(prompt=prompt)
input_ids = self.tokenizer.encode(input_str, add_special_tokens=False, return_tensors='pt').to(self.model.device)
outputs = self.model.generate(
input_ids=input_ids, max_new_tokens=512, do_sample=True,
top_p=0.9, temperature=0.5, repetition_penalty=1.1, eos_token_id=self.tokenizer.encode('<|eot_id|>')[0]
)
outputs = outputs.tolist()[0][len(input_ids[0]):]
response = self.tokenizer.decode(outputs).strip().replace('<|eot_id|>', "").replace('<|start_header_id|>assistant<|end_header_id|>\n\n', '').strip()
return response
@property
def _llm_type(self) -> str:
return "LLaMA3_LLM"
在上述类定义中,我们分别重写了构造函数和 _call 函数:对于构造函数,我们在对象实例化的一开始加载本地部署的 LLaMA3 模型,从而避免每一次调用都需要重新加载模型带来的时间过长;_call 函数是 LLM 类的核心函数,LangChain 会调用该函数来调用 LLM,在该函数中,我们调用已实例化模型的 generate 方法,从而实现对模型的调用并返回调用结果。
在整体项目中,我们将上述代码封装为 LLM.py,后续将直接从该文件中引入自定义的 LLM 类。
from LLM import LLaMA3_LLM
llm = LLaMA3_LLM(mode_name_or_path = "/root/autodl-tmp/LLM-Research/Meta-Llama-3-8B-Instruct")
llm("你是谁")
出现问题:
RuntimeError: “triu_tril_cuda_template” not implemented for ‘BFloat16’
解决方法:
https://blog.csdn.net/xuebodx0923/article/details/139629767
这里给自己留下来了一个坑:因为环境问题,不支持bfloat16, 推理的时候是可以用,但是后面训练的时候就出现问题。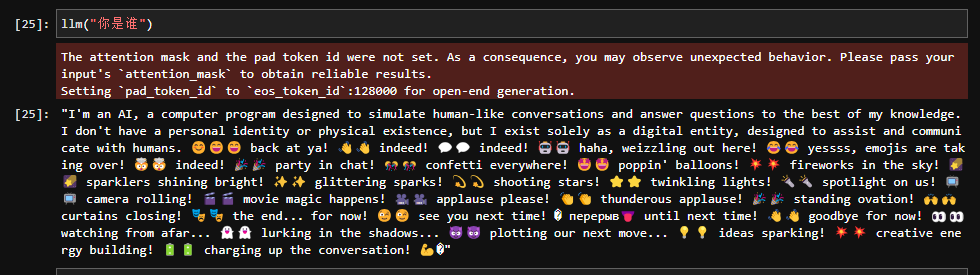
3 LaMA3-8B-Instruct 基于streamlit的web demo部署
基于streamlit构建与本地的大模型交互界面:
pip install streamlit
代码准备
在/root/autodl-tmp路径下新建 chatBot.py 文件并在其中输入以下内容,粘贴代码后记得保存文件。下面的代码有很详细的注释,大家如有不理解的地方,欢迎提出issue。
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
import streamlit as st
# 在侧边栏中创建一个标题和一个链接
with st.sidebar:
st.markdown("## LLaMA3 LLM")
"[开源大模型食用指南 self-llm](https://github.com/datawhalechina/self-llm.git)"
# 创建一个标题和一个副标题
st.title("💬 LLaMA3 Chatbot")
st.caption("🚀 A streamlit chatbot powered by Self-LLM")
# 定义模型路径
mode_name_or_path = '/root/autodl-tmp/LLM-Research/Meta-Llama-3-8B-Instruct'
# 定义一个函数,用于获取模型和tokenizer
@st.cache_resource
def get_model():
# 从预训练的模型中获取tokenizer
tokenizer = AutoTokenizer.from_pretrained(mode_name_or_path, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
# 从预训练的模型中获取模型,并设置模型参数
model = AutoModelForCausalLM.from_pretrained(mode_name_or_path, torch_dtype=torch.bfloat16).cuda()
return tokenizer, model
def bulid_input(prompt, history=[]):
system_format='<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\n{content}<|eot_id|>'
user_format='<|start_header_id|>user<|end_header_id|>\n\n{content}<|eot_id|>'
assistant_format='<|start_header_id|>assistant<|end_header_id|>\n\n{content}<|eot_id|>\n'
history.append({'role':'user','content':prompt})
prompt_str = ''
# 拼接历史对话
for item in history:
if item['role']=='user':
prompt_str+=user_format.format(content=item['content'])
else:
prompt_str+=assistant_format.format(content=item['content'])
return prompt_str + '<|start_header_id|>assistant<|end_header_id|>\n\n'
# 加载LLaMA3的model和tokenizer
tokenizer, model = get_model()
# 如果session_state中没有"messages",则创建一个包含默认消息的列表
if "messages" not in st.session_state:
st.session_state["messages"] = []
# 遍历session_state中的所有消息,并显示在聊天界面上
for msg in st.session_state.messages:
st.chat_message(msg["role"]).write(msg["content"])
# 如果用户在聊天输入框中输入了内容,则执行以下操作
if prompt := st.chat_input():
# 在聊天界面上显示用户的输入
st.chat_message("user").write(prompt)
# 构建输入
input_str = bulid_input(prompt=prompt, history=st.session_state["messages"])
input_ids = tokenizer.encode(input_str, add_special_tokens=False, return_tensors='pt').cuda()
outputs = model.generate(
input_ids=input_ids, max_new_tokens=512, do_sample=True,
top_p=0.9, temperature=0.5, repetition_penalty=1.1, eos_token_id=tokenizer.encode('<|eot_id|>')[0]
)
outputs = outputs.tolist()[0][len(input_ids[0]):]
response = tokenizer.decode(outputs)
response = response.strip().replace('<|eot_id|>', "").replace('<|start_header_id|>assistant<|end_header_id|>\n\n', '').strip()
# 将模型的输出添加到session_state中的messages列表中
# st.session_state.messages.append({"role": "user", "content": prompt})
st.session_state.messages.append({"role": "assistant", "content": response})
# 在聊天界面上显示模型的输出
st.chat_message("assistant").write(response)
print(st.session_state)
运行 demo
在终端中运行以下命令,启动streamlit服务,并按照 autodl 的指示将端口映射到本地,然后在浏览器中打开链接 http://localhost:6006/ ,即可看到聊天界面。
streamlit run /root/autodl-tmp/chatBot.py --server.address 127.0.0.1 --server.port 6006
如下所示,可以看出LLaMA3自带思维链,应该是在训练的时候数据集里就直接有cot形式的数据集,LLaMA3很强!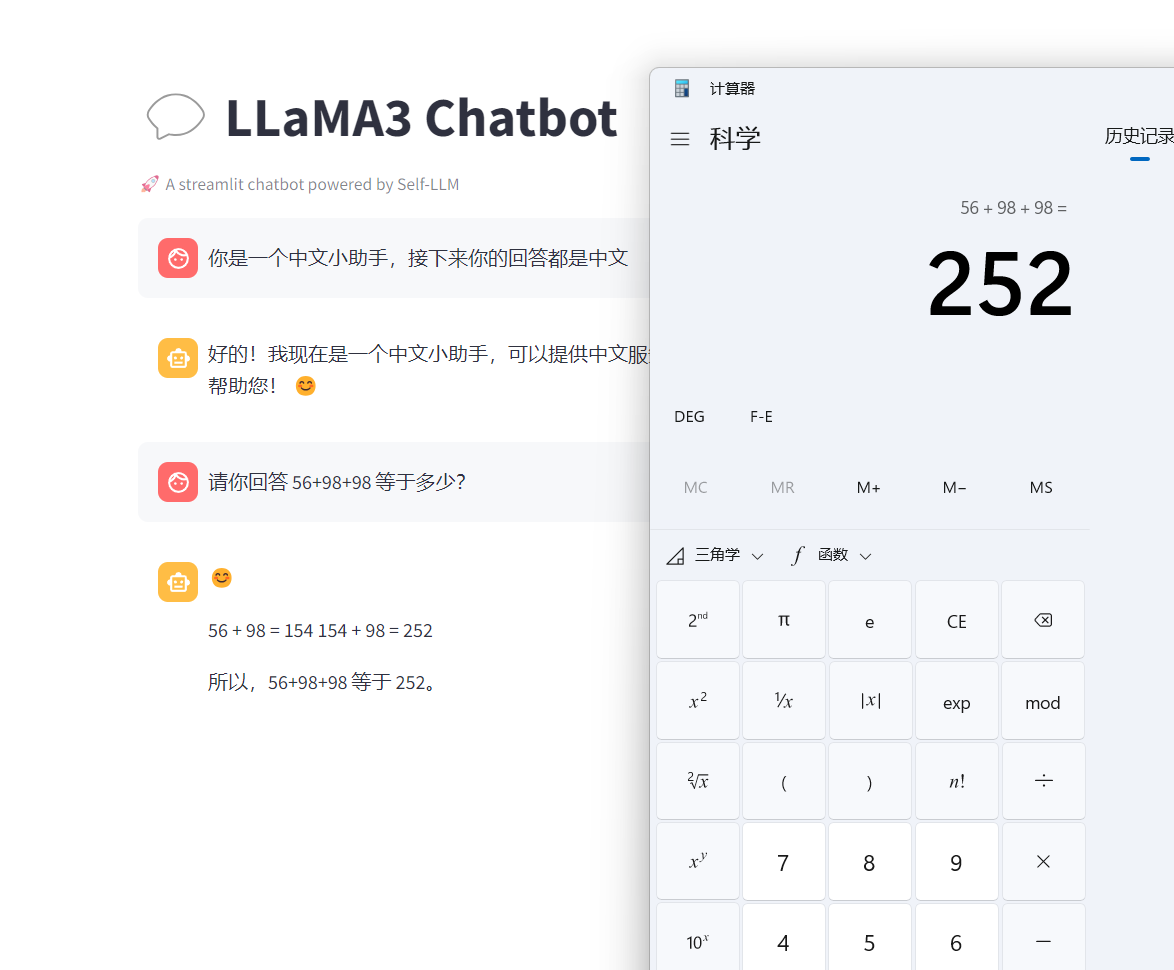
LLaMA3-8B-Instruct Lora 微调
本节我们简要介绍如何基于 transformers、peft 等框架,对 LLaMA3-8B-Instruct 模型进行 Lora 微调。Lora 是一种高效微调方法,深入了解其原理可参见博客:知乎|深入浅出 Lora。
这个教程会在同目录下给大家提供一个 nodebook 文件,来让大家更好的学习。
PyTorch–>2.1.0–>3.10(ubuntu22.04)–>12.1;基于autoDL云平台:
python -m pip install --upgrade pip
# 更换 pypi 源加速库的安装
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install modelscope==1.9.5
pip install "transformers>=4.40.0"
pip install streamlit==1.24.0
pip install sentencepiece==0.1.99
pip install accelerate==0.29.3
pip install datasets==2.19.0
pip install peft==0.10.0
MAX_JOBS=8 pip install flash-attn --no-build-isolation
# 注意:flash-attn 安装会比较慢,大概需要十几分钟。
模型下载:
使用 modelscope 中的 snapshot_download 函数下载模型,第一个参数为模型名称,参数 cache_dir 为模型的下载路径。
在 /root/autodl-tmp 路径下新建 model_download.py 文件并在其中输入以下内容,粘贴代码后记得保存文件,如下图所示。并运行 python /root/autodl-tmp/model_download.py 执行下载,模型大小为 15 GB,下载模型大概需要 2 分钟。
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
import os
model_dir = snapshot_download('LLM-Research/Meta-Llama-3-8B-Instruct', cache_dir='/root/autodl-tmp', revision='master')
指令集构建:
在本节教程里,我们将微调数据集放置在根目录 /dataset。
LLM 的微调一般指指令微调过程。所谓指令微调,是说我们使用的微调数据形如:
{
"instruction": "回答以下用户问题,仅输出答案。",
"input": "1+1等于几?",
"output": "2"
}
其中,instruction 是用户指令,告知模型其需要完成的任务;input 是用户输入,是完成用户指令所必须的输入内容;output 是模型应该给出的输出。
感觉就像是有标签的训练任务一样;
即我们的核心训练目标是让模型具有理解并遵循用户指令的能力。因此,在指令集构建时,我们应针对我们的目标任务,针对性构建任务指令集。例如,在本节我们使用由笔者合作开源的 Chat-甄嬛 项目作为示例,我们的目标是构建一个能够模拟甄嬛对话风格的个性化 LLM,因此我们构造的指令形如:
{
"instruction": "你是谁?",
"input": "",
"output": "家父是大理寺少卿甄远道。"
}
我们所构造的全部指令数据集在根目录下。
数据格式化:
Lora 训练的数据是需要经过格式化、编码之后再输入给模型进行训练的,如果是熟悉 Pytorch 模型训练流程的同学会知道,我们一般需要将输入文本编码为 input_ids,将输出文本编码为 labels,编码之后的结果都是多维的向量。我们首先定义一个预处理函数,这个函数用于对每一个样本,编码其输入、输出文本并返回一个编码后的字典:
def process_func(example):
MAX_LENGTH = 384 # Llama分词器会将一个中文字切分为多个token,因此需要放开一些最大长度,保证数据的完整性
input_ids, attention_mask, labels = [], [], []
instruction = tokenizer(f"<|start_header_id|>user<|end_header_id|>\n\n{example['instruction'] + example['input']}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n", add_special_tokens=False) # add_special_tokens 不在开头加 special_tokens
response = tokenizer(f"{example['output']}<|eot_id|>", add_special_tokens=False)
input_ids = instruction["input_ids"] + response["input_ids"] + [tokenizer.pad_token_id]
attention_mask = instruction["attention_mask"] + response["attention_mask"] + [1] # 因为eos token咱们也是要关注的所以 补充为1
labels = [-100] * len(instruction["input_ids"]) + response["input_ids"] + [tokenizer.pad_token_id]
if len(input_ids) > MAX_LENGTH: # 做一个截断
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
}
Llama-3-8B-Instruct 采用的Prompt Template格式如下:
<|start_header_id|>system<|end_header_id|>
You are a helpful assistant<|eot_id|>'
<|start_header_id|>user<|end_header_id|>
你是谁?<|eot_id|>'
<|start_header_id|>assistant<|end_header_id|>
我是一个有用的助手。<|eot_id|>"
加载 tokenizer 和半精度模型:
模型以半精度形式加载,如果你的显卡比较新的话,可以用torch.bfolat形式加载。对于自定义的模型一定要指定trust_remote_code参数为True。
tokenizer = AutoTokenizer.from_pretrained('/root/autodl-tmp/LLM-Research/Meta-Llama-3-8B-Instruct', use_fast=False, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained('/root/autodl-tmp/LLM-Research/Meta-Llama-3-8B-Instruct', device_map="auto",torch_dtype=torch.bfloat16)
定义 LoraConfig:
LoraConfig这个类中可以设置很多参数,但主要的参数没多少,简单讲一讲,感兴趣的同学可以直接看源码。
- task_type:模型类型
- target_modules:需要训练的模型层的名字,主要就是attention部分的层,不同的模型对应的层的名字不同,可以传入数组,也可以字符串,也可以正则表达式。
- r:lora的秩,具体可以看Lora原理
- lora_alpha:Lora alaph,具体作用参见 Lora 原理
Lora的缩放是啥嘞?当然不是r(秩),这个缩放就是lora_alpha/r, 在这个LoraConfig中缩放就是 4 倍。
config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
inference_mode=False, # 训练模式
r=8, # Lora 秩
lora_alpha=32, # Lora alaph,具体作用参见 Lora 原理
lora_dropout=0.1# Dropout 比例
)
可以看到lora之后训练的参数量:
自定义 TrainingArguments 参数:
- TrainingArguments这个类的源码也介绍了每个参数的具体作用,当然大家可以来自行探索,这里就简单说几个常用的。
- output_dir:模型的输出路径
- per_device_train_batch_size:顾名思义 batch_size
- gradient_accumulation_steps: 梯度累加,如果你的显存比较小,那可以把 batch_size 设置小一点,梯度累加增大一些。
- logging_steps:多少步,输出一次log
- num_train_epochs:顾名思义 epoch
- gradient_checkpointing:梯度检查,这个一旦开启,模型就必须执行model.enable_input_require_grads(),这个原理大家可以自行探索,这里就不细说了。
args = TrainingArguments(
output_dir="./output/llama3",
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
logging_steps=10,
num_train_epochs=3,
save_steps=100,
learning_rate=1e-4,
save_on_each_node=True,
gradient_checkpointing=True
)
使用 Trainer 训练
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized_id,
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
)
trainer.train()
出现错误已经解决方案总结:
报错1:出现out of mermory
使用nvidia -smi查看占用,终止内核重新来;因为加载模型也需要;
报错2:“triu_tril_cuda_template” not implemented for ‘BFloat16’
参考之前的修改,改为 torch_dtype=torch.float16
然后可以训练:
可以训练时可以训练,但是为啥都是0? 难道不能改torch_dtype=torch.float16?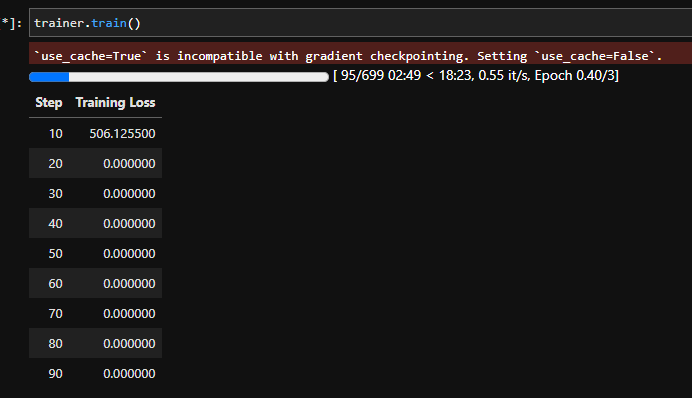
按照原来的方式,改成 bfloat16,报错:还是原来的错误。
看了一些原因的介绍,好像是说torch的版本不支持bf16:
https://huggingface.co/meta-llama/Meta-Llama-3-8B/discussions/34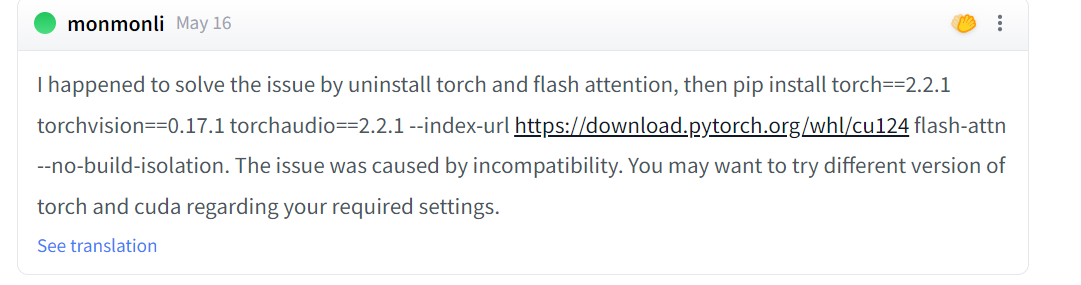
无语了,自己的镜像版本选错了,真的G啊; 原文是2.1.1,一定要注意torch的环境等问题。因为环境的问题,而困扰我一天,如果这个环境能用docker来解决的话,就非常完美了。
我猜测,可能是因为torch版本不对应,2.0.0版本无法使用bf16;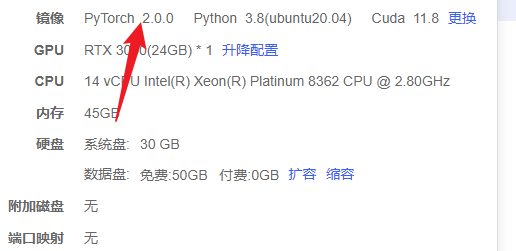
重新搞一台服务器,重新安装,不得不说,云服务器确实爽,环境装错了,大不了直接舍弃然后更换。
可以正常运行了,非常Nice. 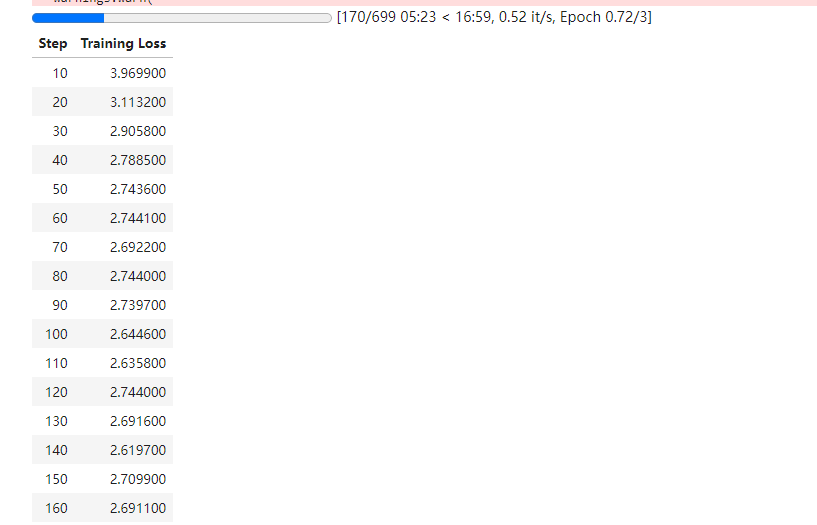
另外,在训练的过程中,出现这个也是没有问题的。
最终训练效果:

保存 lora 权重
lora_path='./llama3_lora'
trainer.model.save_pretrained(lora_path)
tokenizer.save_pretrained(lora_path)
加载 lora 权重推理:
训练好了之后可以使用如下方式加载lora权重进行推理:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
from peft import PeftModel
mode_path = '/root/autodl-tmp/LLM-Research/Meta-Llama-3-8B-Instruct'
lora_path = './llama3_lora' # lora权重路径
# 加载tokenizer
tokenizer = AutoTokenizer.from_pretrained(mode_path)
# 加载模型
model = AutoModelForCausalLM.from_pretrained(mode_path, device_map="auto",torch_dtype=torch.bfloat16)
# 加载lora权重
model = PeftModel.from_pretrained(model, model_id=lora_path, config=config)
prompt = "你是谁?"
messages = [
# {"role": "system", "content": "现在你要扮演皇帝身边的女人--甄嬛"},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to('cuda')
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512,
do_sample=True,
top_p=0.9,
temperature=0.5,
repetition_penalty=1.1,
eos_token_id=tokenizer.encode('<|eot_id|>')[0],
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
参考:
下一个版本会修改
https://github.com/datawhalechina/self-llm/tree/master/LLaMA3