.RocketMQ的安装
一.RocketMQ安装
1.1.下载RocketMQ
下载地址:http://rocketmq.apache.org/release_notes/release-notes-4.2.0/
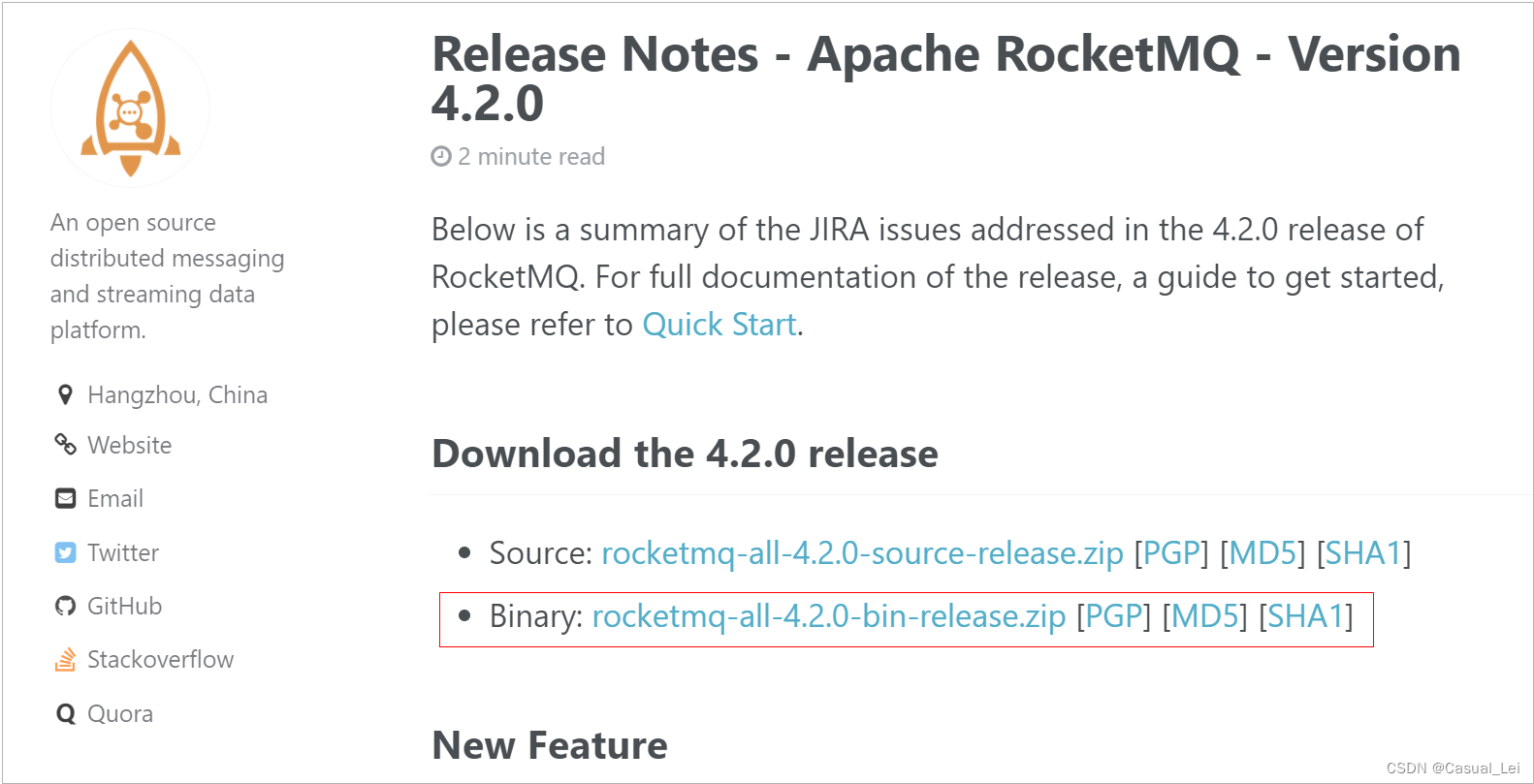
下载后解压
-
Bin : 可执行文件目录
-
config:配置文件目录
-
Lib : 依赖库,一堆Jar包
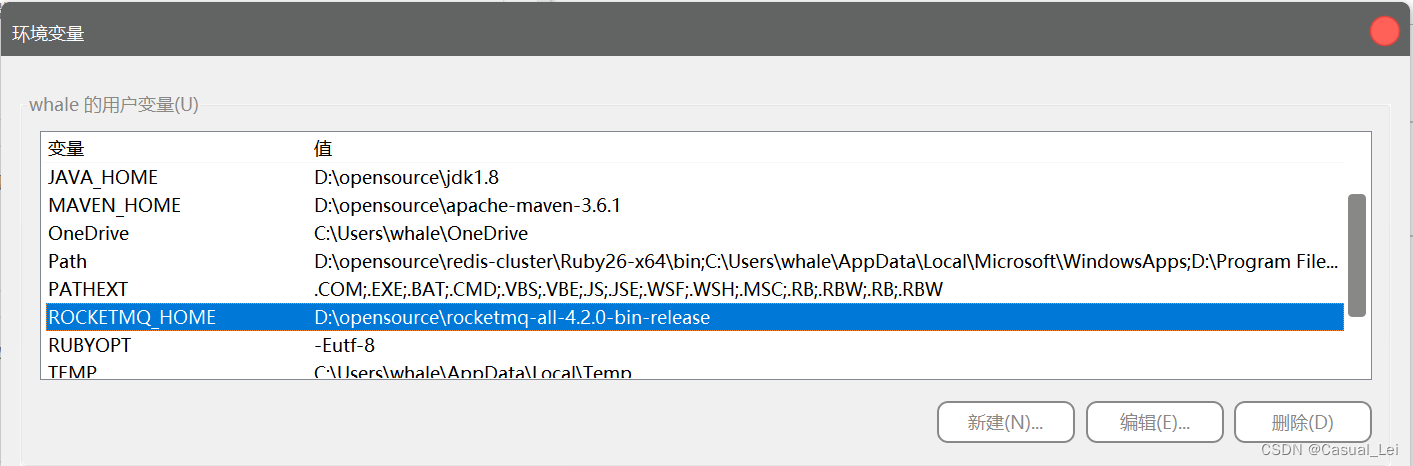
1.2.配置ROCKETMQ_HOME
解压压缩包,配置 ROCKETMQ_HOME
1.3.启动MQ
- 启动NameServer
Cmd命令框执行进入至‘MQ文件夹\bin’下,然后执行 start mqnamesrv.cmd,启动NameServer。
成功后会弹出提示框,此框勿关闭。
- 启动Broker
进入至‘MQ文件夹\bin’下,修改Bean目录下的 runbroker.cmd 中JVM占用内存大小
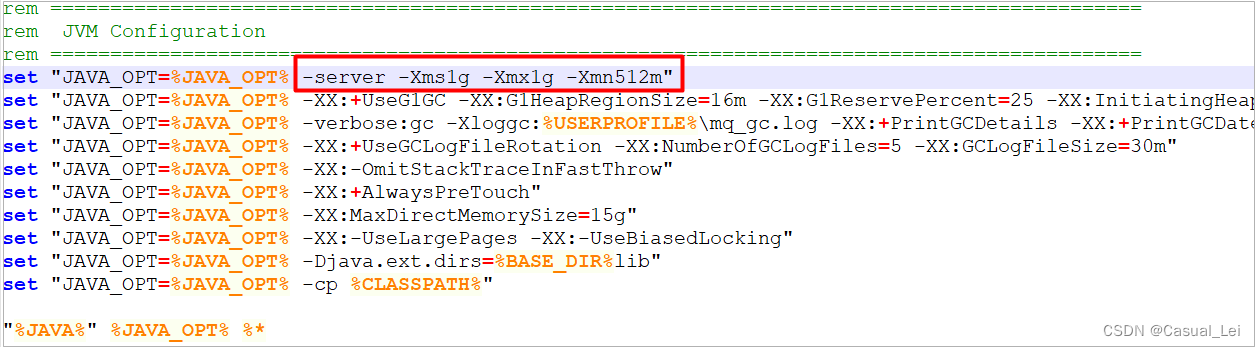
CMD执行start mqbroker.cmd -n 127.0.0.1:9876 autoCreateTopicEnable=true ,启动Broker。
成功后会弹出提示框,此框勿关闭
1.4.RocketMQ存储结构
RocketMQ安装好之后会在用户目录下产生一个store目录用来存储相关数据:
- Commitlog : 消息是存储写在commitlog目录中,一mapperdFile文件顺序存储消息。
- Config : 存放运行期间的配置文件
- Consumerqueue : 该目录中存放的是队列,consume queue存放着commitlog中的消息的索引位置
- Index :存放着消息索引文件 indexFile,用来实现根据key进行消息的快速查询
- Abort : 该文件在broker启动后自动创建,正常关闭abort会消失
- Checkpoint :记录 Commitlog ,Consumerqueue 和index 文件的最后刷盘时间戳
[问]RocketMQ数据存储在磁盘会影响性能吗?
不会,RocketMQ的性能在所有的MQ中是比较高的,主要是因为RocketMQ使用了mmap零拷贝技术,consumequeue中的数据是顺序存放的,还引入了PageCache的预读取机制,使得对 consumequeue文件的读取几乎接近于内存读取,即使在有消息堆积情况下也不会影响性能。
2.RocketMQ插件-控制台
为了方便管理,我们需要安装一个可视化插件
2.1.下载插件
RocketMQ可视化管理插件下载地址:https://github.com/apache/rocketmq-externals/releases

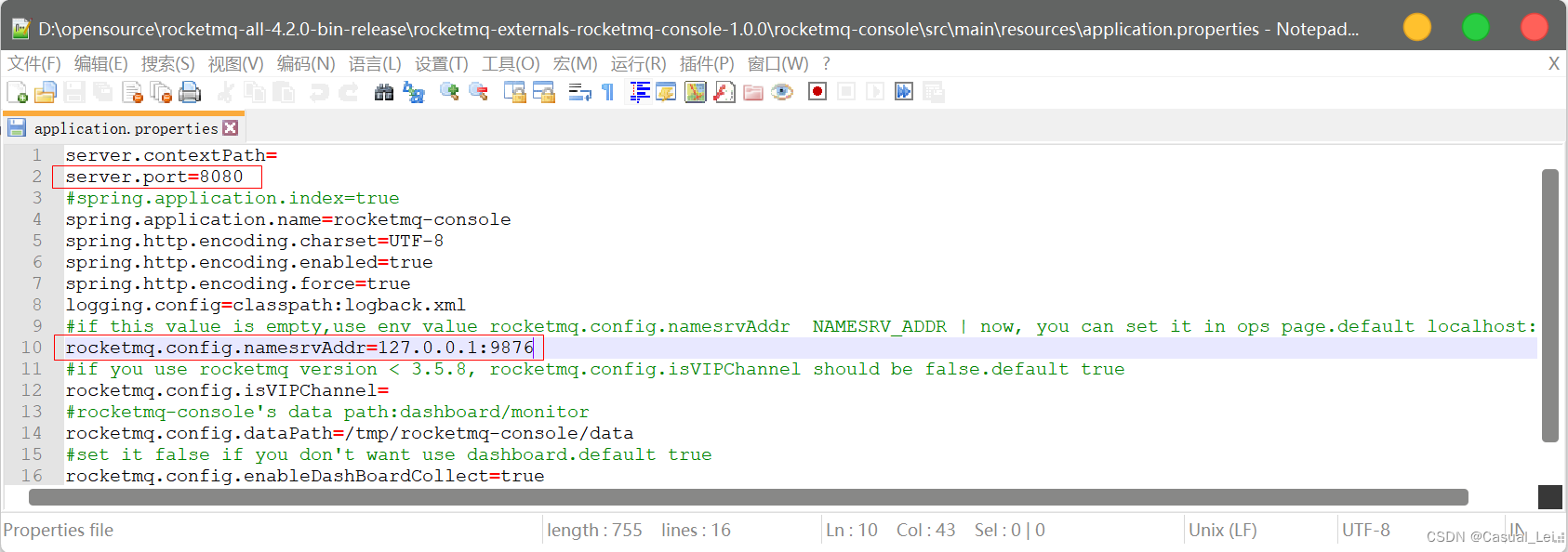
2.2.修改配置
解压后,修改配置:src/main/resource/application.properties ,这里需要指向Name Server 的地址和端口 如下:
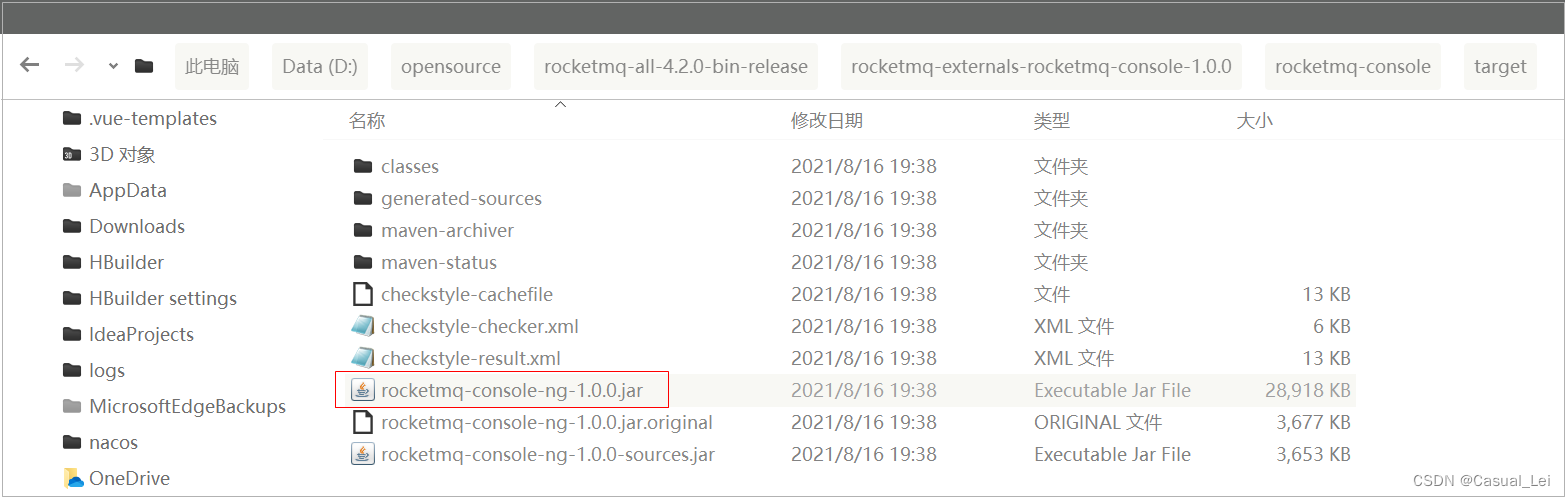
2.3.打包插件
回到安装目录,执行: mvn clean package -Dmaven.test.skip=true ,然后会在target目录生成打包后的jar文件
2.4.启动插件
进入 target 目录,执行 java -jar rocketmq-console-ng-1.0.0.jar , 访问 http://localhost:8080
二.RocketMQ的原理
1.RokcetMQ架构
RocketMQ开发官方文档:
https://github.com/apache/rocketmq/blob/master/docs/cn/RocketMQ_Example.md
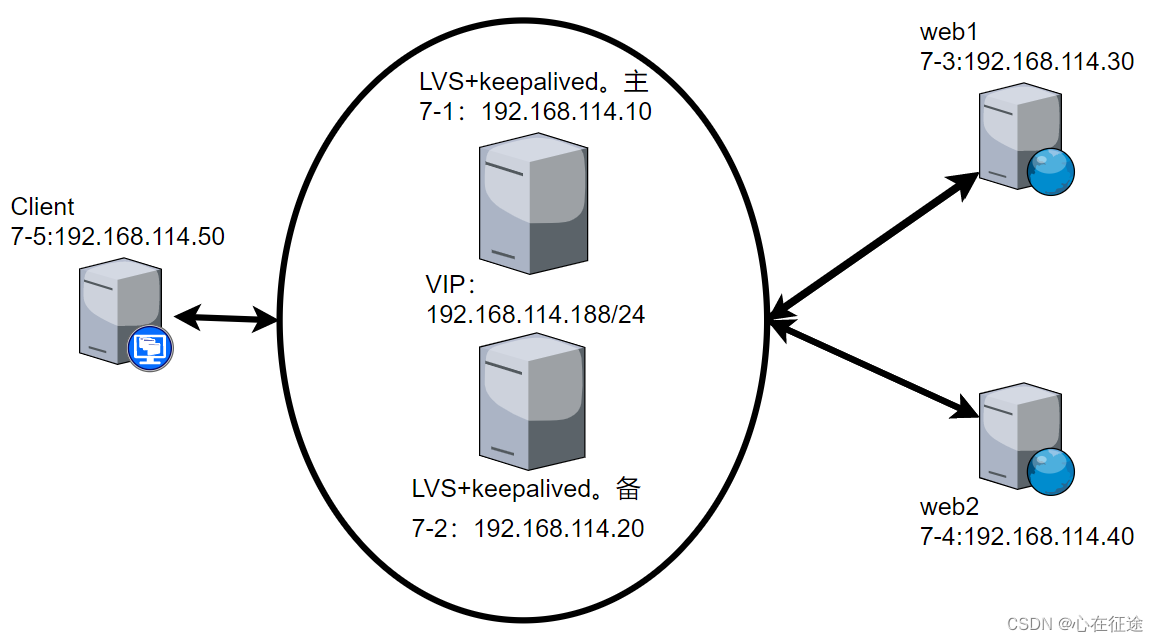
RocketMQ的集群架构如下
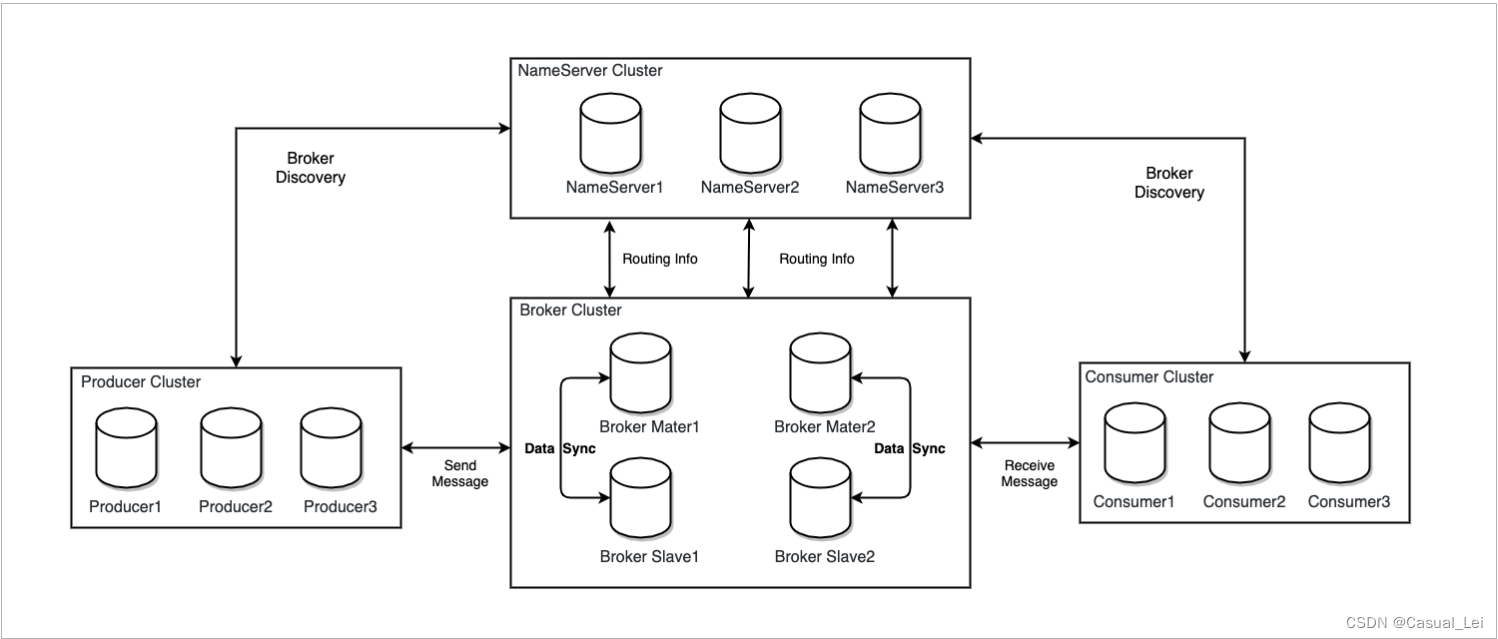
RocketMQ架构上主要分为四部分,如上图所示
1.1.Producer
消息发布的角色,支持分布式集群方式部署。Producer通过nameserver的负载均衡模块选择相应的Broker集群队列进行消息投递,投递的过程支持快速失败并且低延迟。
1.2.Consumer
消息消费的角色,支持分布式集群方式部署。支持以push推,pull拉两种模式对消息进行消费。同时 也支持集群方式和广播方式的消费,它提供实时消息订阅机制,可以满足大多数用户的需求。
1.3.Broker
Broker主要负责消息的存储、投递和查询以及服务高可用保证。
1.4.NameServer
NameServer是一个Broker与Topic路由的注册中心支持Broker的动态注册与发现主要包括两个功能
-
Broker管理NameServer接受Broker集群的注册信息并且保存下来作为路由信息的基本数据。然后提供心跳检测机制,检查Broker是否还存活。
-
路由信息管理每个NameServer将保存关于Broker集群的整个路由信息和用于客户端查询的队列信息。然后Producer和Conumser通过NameServer就可以知道整个Broker集群的路由信息,从而进行消息的投递和消费
2.RocketMQ入门
官方案例:https://github.com/apache/rocketmq/blob/master/docs/cn/RocketMQ_Example.md
2.1.导入依赖
注意和安装的MQ版本一致
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-client</artifactId>
<version>4.8.0</version>
</dependency>
2.2.生产者
步骤分析
-
创建producer组
-
设置NameServer地址
-
startr生产者
-
发送消息获取结果
-
结束producer
//消息发送者
public class ProducerTest {public static void main(String[] args) { try { // 实例化消息生产者Producer DefaultMQProducer producer = new DefaultMQProducer("producergroup"); // 设置NameServer的地址 producer.setNamesrvAddr("localhost:9876"); // 启动Producer实例 producer.start(); for (int i = 0; i < 100; i++) { //构建消息 Message message = new Message("topic_log","tags_error",("我是消息"+i).getBytes()); SendResult sendResult = producer.send(message); System.out.printf("%s%n", sendResult); } // 如果不再发送消息,关闭Producer实例。 producer.shutdown(); }catch (Exception e){ e.printStackTrace(); } }}
代码解释:
-
DefaultMQProducer : MQ生产者 , 可以指定组名 producerGroupName
-
producer.setNamesrvAddr : 指定Name Server地址,用作Brocker发现。注意IP和启动name server服务时指定的IP保持一致。
-
producer.start() : 启动 生产者
-
new Message(“topic_log”,“tags_error”,(“我是消息”+i).getBytes()) :消息,参数为:topic,tags,内容
-
producer.send(message) : 发送消息
-
SendResult :发送结果,其中包含
- sendStatus=SEND_OK :发送状态
- msgId :producer 创建的消息ID
- offsetMsgId :Brocker创建的消息ID
- messageQueue :消息存储的队列
- producer.shutdown():关闭生产者
2.3.消费者
-
创建consumer组
-
设置Name Server地址
-
设置消费位置,从最开始销毁
-
设置消息回调处理监听 -> 处理消息
-
Start consumer
//消息发送者
public class ConsumerTest {public static void main(String[] args) { try { // 实例化消息生产者Producer DefaultMQPushConsumer consumer = new DefaultMQPushConsumer ("consumergroup"); // 设置NameServer的地址 consumer.setNamesrvAddr("127.0.0.1:9876"); //从最开始的位置开始消费 consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET); // 订阅一个或者多个Topic,以及Tag来过滤需要消费的消息 //和发送者保持一致才能搜到消息 consumer.subscribe("topic_log", "tags_error"); // 注册回调实现类来处理从broker拉取回来的消息 consumer.registerMessageListener(new MessageListenerConcurrently() { @Override public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) { System.out.printf("%s 成功搜到消息: %s %n", Thread.currentThread().getName(), msgs); // 标记该消息已经被成功消费 return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; } }); // 启动Producer实例 consumer.start(); }catch (Exception e){ e.printStackTrace(); } }}
- DefaultMQPushConsumer :消费者 , 可以指定 consumerGroupName
- consumer.setNamesrvAddr : 设置name server 地址
- consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET) :从什么位置开始消费
- consumer.subscribe(“topic_log”, “tags_error”) :订阅某个topic下的某个tags的消息
- consumer.registerMessageListener :注册消息监听器,拿到消息后,进行消息处理。
- ConsumeConcurrentlyStatus :消费者消费结果状态,ConsumeConcurrentlyStatus.CONSUME_SUCCESS代表成功
3.RocketMQ 核心概念
3.1.RocketMQ工作原理
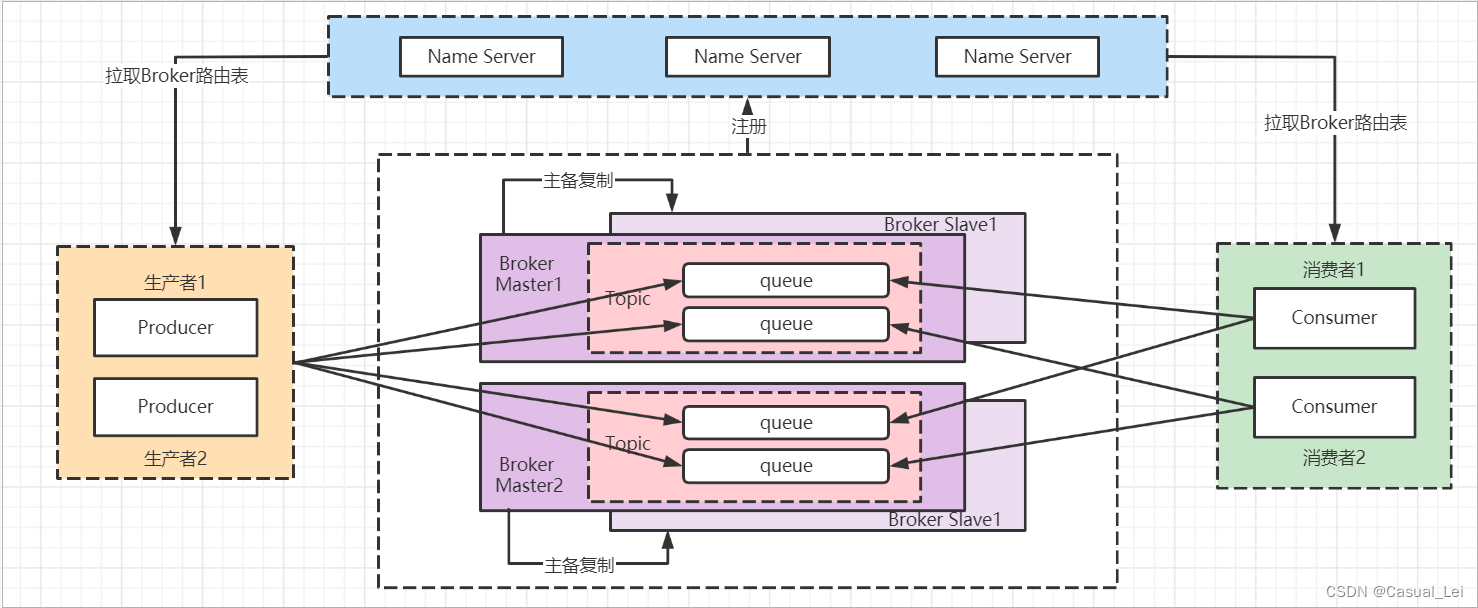
1.RocketMQ 网络部署特点
为了增强Broker性能与吞吐量,Broker一般都是以集群形式出现的。各集群节点中可能存放着相同Topic的不同Queue。
不过,这里有个问题,如果某Broker节点宕机,如何保证数据不丢失呢?其解决方案是,将每个Broker集群节点进行横向扩展,即将Broker节点再建为一个HA集群,解决单点问题。
Broker节点集群是一个主从集群,即集群中具有Master与Slave两种角色。Master负责处理读写操作请求,Slave负责对Master中的数据进行备份。当Master挂掉了,Slave则会自动切换为Master去工作。所以这个Broker集群是主备集群。Consumer既可以从Master订阅消息,也可以从Slave订阅消息
一个Master可以包含多个Slave,但一个Slave只能隶属于一个Master。 Maste与Slave 的对应关系是通过指定相同的BrokerName、不同的BrokerId 来确定的。BrokerId为0表示Master非0表示Slave。每个Broker与NameServer集群中的所有节点建立长连接,定时注册Topic信息到所有NameServer。
2.RocketMQ工作流程
-
启动NameServer,NameServer起来后监听端口,等待Broker、Producer、Consumer连上来,相当于一个路由控制中心。
-
Broker启动,跟所有的NameServer保持长连接,定时发送心跳包。心跳包中包含当前Broker信息(IP+端口等)以及存储所有Topic信息。注册成功后,NameServer集群中就有Topic跟Broker的映射关系。
-
收发消息前,先创建Topic,创建Topic时需要指定该Topic要存储在哪些Broker上,也可以在发送消息时自动创建Topic。
-
Producer发送消息,启动时先跟NameServer集群中的其中一台建立长连接,并从NameServer中获取当前发送的Topic存在哪些Broker上,轮询从队列列表中选择一个队列,然后与队列所在的Broker建立长连接从而向Broker发消息。
| topicid | broker | 队列 |
|---|---|---|
| topic_log | 1 | 队列1,队列2 |
| topic_log | 2 | 队列3,队列4 |
- Consumer跟Producer类似,跟其中一台NameServer建立长连接,获取当前订阅Topic存在哪些Broker上,然后直接跟Broker建立连接通道,开始消费消息
3.2.Producer 生产者
RocketMQ提供多种发送方式,同步发送、异步发送、顺序发送、单向发送。同步和异步方式均需要Broker返回确认信息,单向发送不需要。
RocketMQ中的消息生产者都是以生产者组(Producer Group)的形式出现的。生产者组是同一类生产者的集合,这类Producer发送相同Topic类型的消息。一个生产者组可以同时发送多个主题的消息。
Producer会使用一定的算法(随机轮询+规避故障)选择把消息发送到哪个master的某个queue中。
3.3.Consumer 消费者
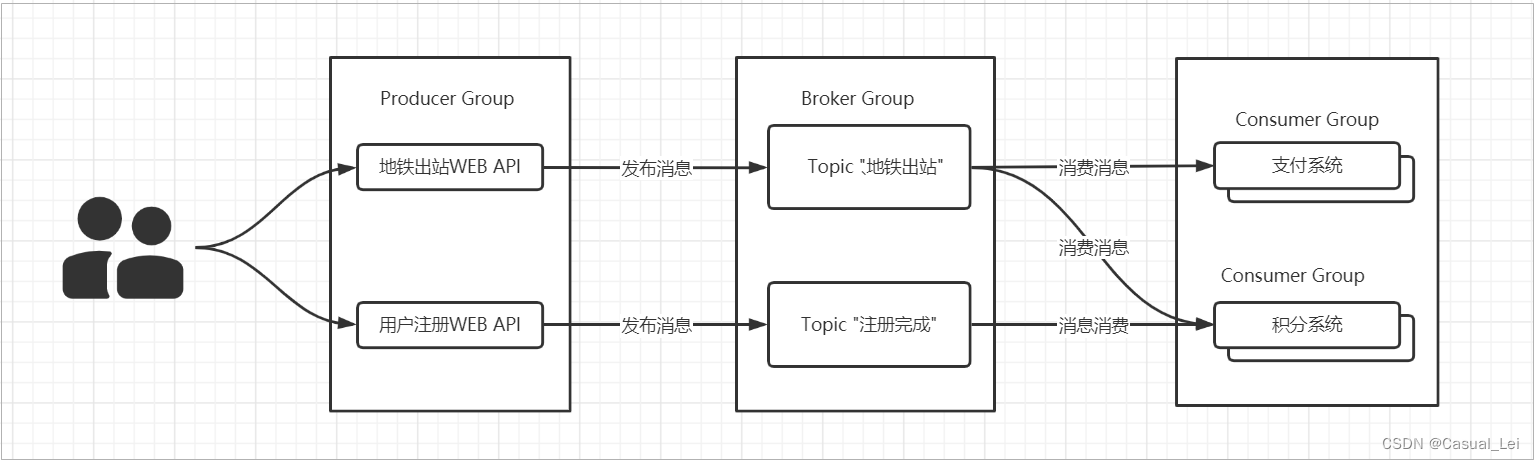
Consumer 支持两种消费形式:拉取式消费、推动式消费。(主动,被动),RocketMQ中的消息消费者都是以消费者组(Consumer Group)的形式出现的。消费者组是同一类消费者的集合,这类Consumer消费的是同一个Topic类型的消息,不同的 Consumer Group可以消费同一个Topic。
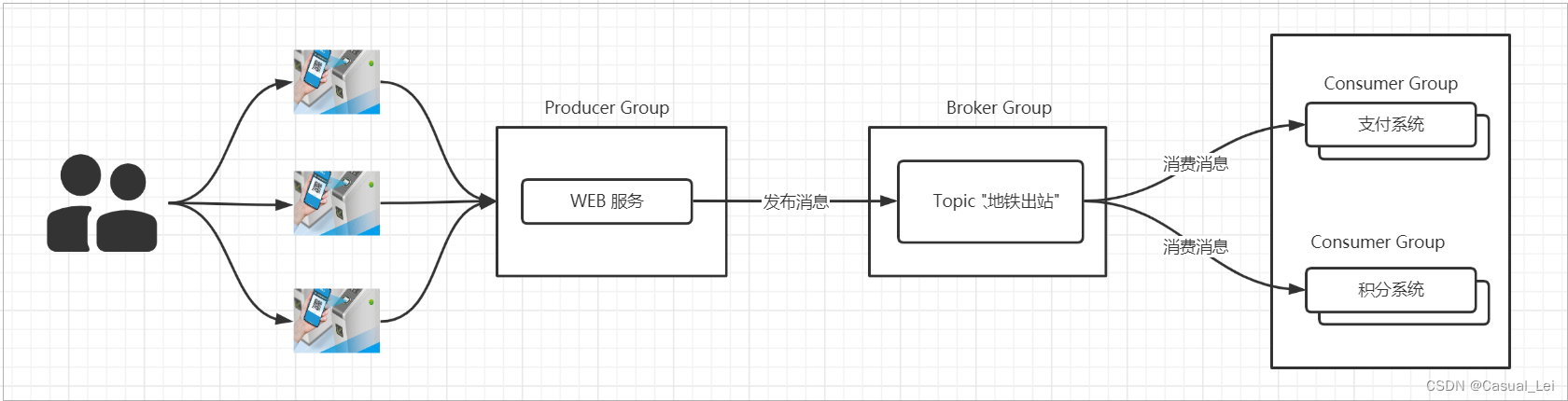
一个Consumer Group内的Consumer可以消费多个Topic的消息。
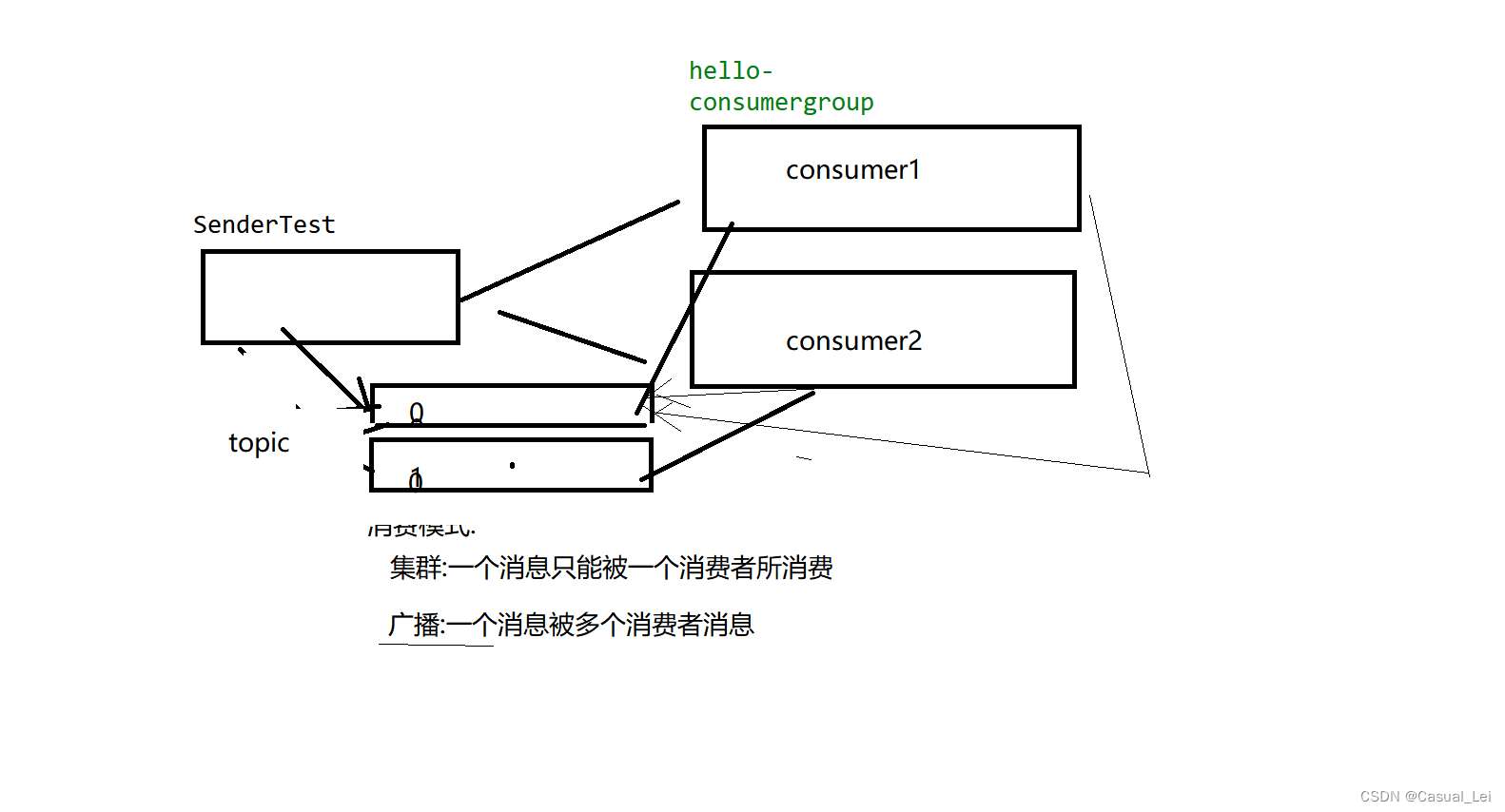
[注意] 集群模式:一个Queue是不能被同一个ConsumerGroup中的多个Consumer消费的,目的是减少资源竞争提升整体性能。
3.4.Topic 消息主题
Topic表示一类消息的集合,每个topic主题包含若干条message消息,每条message消息只能属于一个topic主题,Topic是RocketMQ进行消息订阅的基本单位。
3.5.Message
消息是指消息系统所传输信息的物理载体,生产和消费数据的最小单位,每条消息必须属于一个主题(topic)。
3.6.Tag 标签
为消息设置的标志,用于同一主题下区分不同类型的消息。来自同一业务单元的消息,可以根据不同业务目的在同一主题下设置不同标签。标签能够有效地保持代码的清晰度和连贯性,并优化RocketMQ提供的查询系统。消费者可以根据Tag实现对不同子主题的不同消费逻辑,实现更好的扩展性。Topic是消息的一级分类,Tag是消息的二级分类
3.7.MessageQueue
一个Topic中可以包含多个Queue,一 个Topic的Queue也被称为一个Topic中消息的分区(Partition)。
在集群模式下, 在一个Consumer Group内,一个Queue最多只能分配给一个Consumer,一个Cosumer可以分配得到多个Queue。这样的分配规则,每个Queue只有一个消费者,可以避免消费过程中的多线程处理和资源锁定,有效提高各Consumer消费的并行度和处理效率。
消费者组中Consumer的数量应该小于等于订阅Topic的Queue数量。如果超出Queue数量,则多出的 Consumer将不能消费消息。如果一个Consmer挂了,该Consumer Group中的其它Consumer可以接着消费原Consumer消费的Queue。
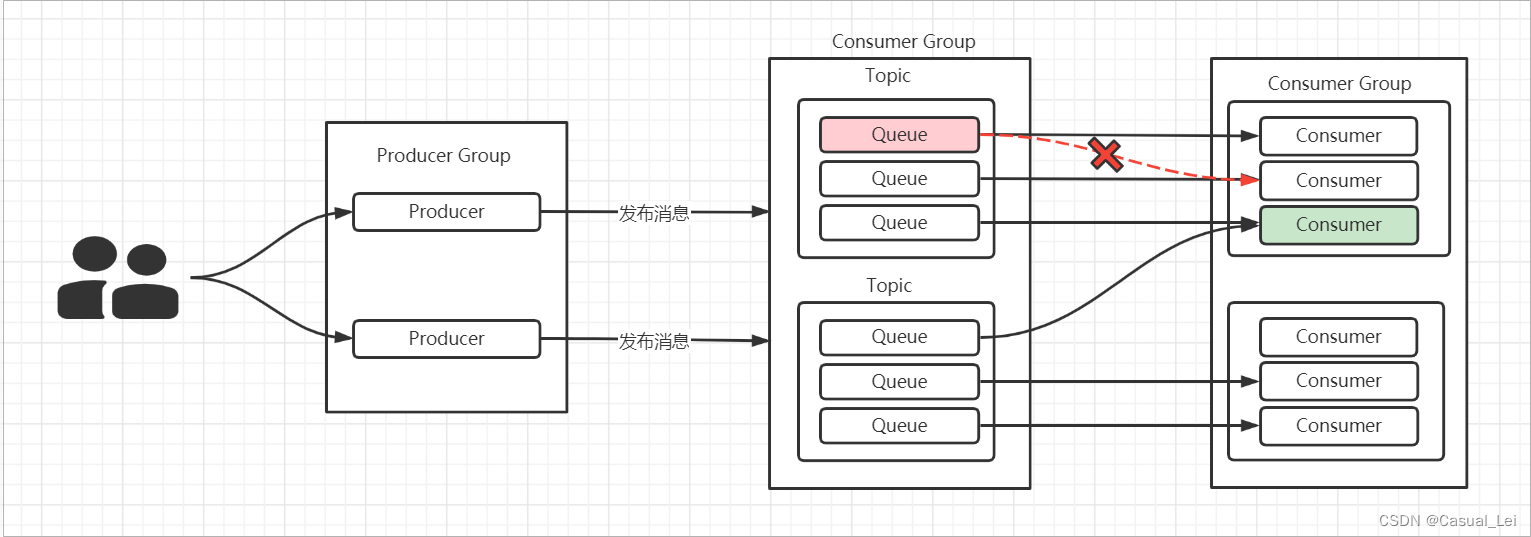
【注意】 一个Topic可以对应多个消费者 ,一个Queue只能对应一个组中的一个消费者。
【注意】为了防止消息紊乱,一个Consumer Group 中的Consumer都是订阅相同Topic下的Queue。
在广播模式下一个队列要可以被多个消费者对应.在广播模式下,同一个 ConsumerGroup 中的每个 Consumer 监听全部的队列。需要注意的是,广播模式下因为每个 Consumer 实例都需要处理全部的消息,因此这种模式仅推荐在**通知推送、配置同步类小流量场景使用。
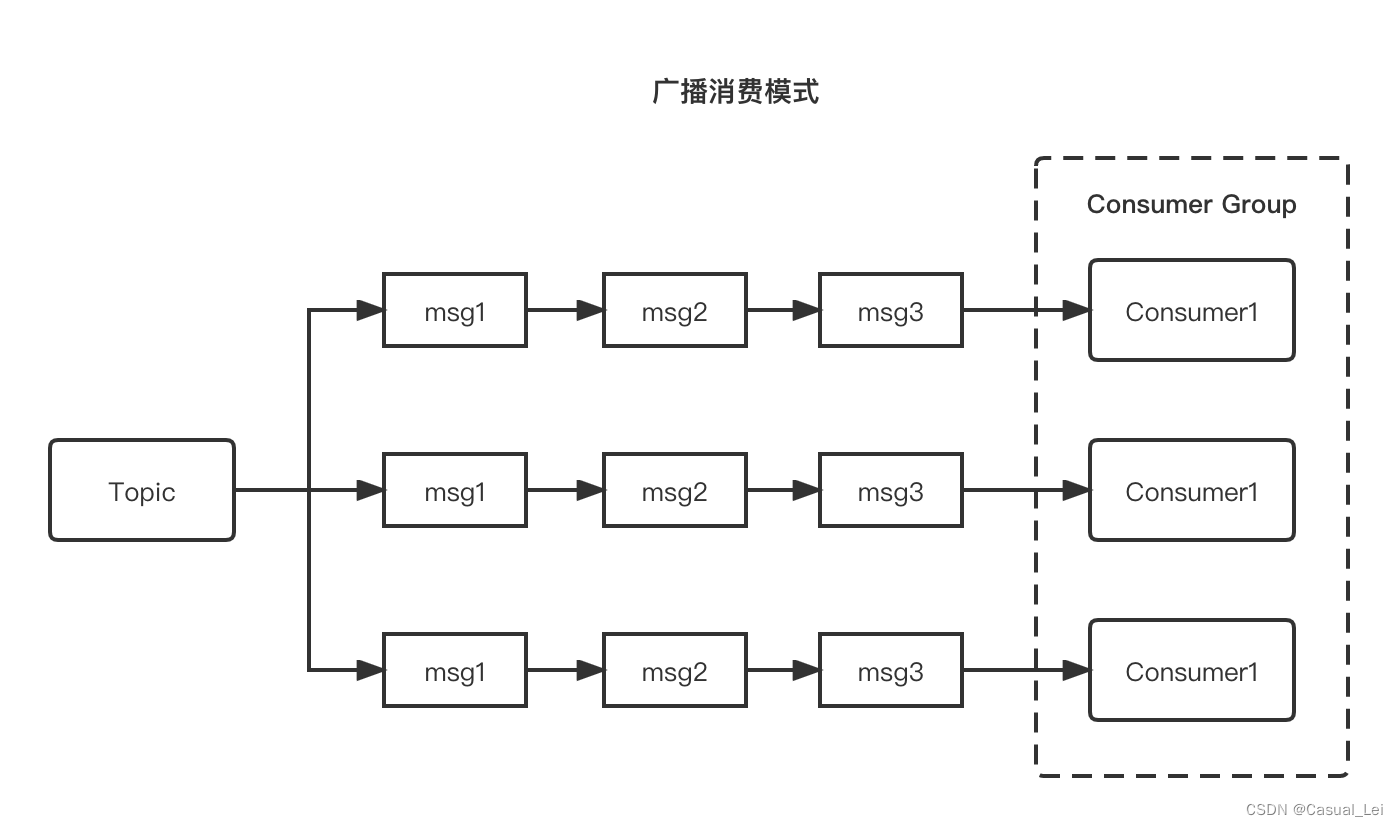
读写队列
Queue分为 写队列 和 读队列 ,默认创建数量是都是4 ,这个读写队列是从逻辑上进行划分在物理上读/写是一个队列,Producer发送的消息进入写队列 ,Consumer从读队列获取数据,一半情况下读写队列数量是一样的。
可以通过可视化界面修改Topic中的队列数量
perm用于设置对当前创建Topic的操作权限:2表示只写,4表示只读,6表示读写。
3.8.MessageId/Key
RocketMQ中每个消息拥有唯一的MessageId,且可以携带具有业务标识的Key,以方便对消息的查询。 不过需要注意的是,MessageId有两个:在生产者send()消息时会自动生成一个MessageId(msgId),
当消息到达Broker后,Broker也会自动生成一个MessageId(offsetMsgId)。msgId、offsetMsgId与key都称为消息标识。
3.9.Rebalance重新负载
当消费者数量或者Queue的数量修改,Rebalance是把⼀个Topic下的多个Queue重新分配给Consumer Group下的Consumer。目的是增加消费能力。
由于一个队列值分配给一个Consumer,那么当Consumer Group中的消费者数量大于队列数量,那么多出来的Consumer分配不到队列。
3.10.消息拉取模式
消息的消费分为:拉取式 pull ,和推送式 push
-
Pull:拉取式,需要消费者间隔一定时间就去遍历关联的Queue,实时性差但是便于应用控制消息的拉取
-
Push:推送式,封装了Queue的遍历,实时性强,但是对系统资源占用比较多。
3.11.消息消费模式
-
广播模式(一对多):同一个Consumer Group 下的所有Consumer都会收到同一个Topic的所有消息。同一个消息可能会被消费多次。
-
集群模式(一对一):同一个Gonsumer Group 下的Consumer平分同一个Topic下的消息。同一个消息只是被消费一次。
3.12.Queue的分配算法
Queue是如何分配给Consumer的,这对应了四种算法:平均分配策略,环形平均策略,一致性Hash策略,同机房策略。
-
平均分配【默认】:根据 qeueuCount (4)/ consumerCount (3)作为每个消费者平均分配数量,如果多出来的queue就再依次逐个分配给Consumer。
-
环形平均策略:根据消费者的顺序,一个一个的分配Queue即可类似于发扑克牌。
-
一致性Hash策略 : 该算法将Consumer的Hash值作为节点放到Hash环上,然后将Queue的hash值也放入Hash环上,通过顺时针进行就近分配。
-
同机房策略:该算法会根据queue的部署机房位置和consumer的位置,过滤出当前consumer相同机房的queue。然后按照平均分配策略或环形平均策略对同机房queue进行分配。如果没有同机房queue,则按照平均分配策略或环形平均策略对所有queue进行分配。
平均分配性能比较高,一致性Hash性能不高,但是能减少Rebalance,如果Consumer数量变动频繁可以使用一致性Hash。
3.13.Offset管理
RockertMQ通过Offset来维护Consumer的消费进度,比如:消费者从哪个位置开始持续消费消息的?这里有三个枚举来指定从什么位置消费
CONSUME_FROM_LAST_OFFSET:从queue的最后一条消息开始消费CONSUME_FROM_FIRST_OFFSET:从queue的第一条消息开始消费CONSUME_FROM_TIMESTAMP:从某个时间戳位置的消息开始消费。
消费者消费结束之后,会向Consumer会提交其消费进度offset给Broker。Offset信息的存储分为本地 Offset管理 和远程Offset管理
- 远程Offset管理:Brocker通过 store/config/consumerOffset.json 文件以JSON方式来存储offset相关数据以json的形式:适用于集群模式
- 本地Offset管理:offset相关数据以json的形式持久化到Consumer本地磁盘文件中,路径为当前用户主目录下的.rocketmq_offsets/ c l i e n t I d / {clientId}/ clientId/{group}/Offsets.json :适用于广播模式
Offset的同步提交与异步提交: 集群消费模式下,Consumer消费完消息后会向Broker提交消费进度offset,其提交方式分为两种:
- 同步提交:消费者在消费完一批消息后会向broker提交这些消息的offset,等待broker的成功响应。若在等待超时之前收到了成功响应,则继续读取下一批消息进行消费(从ACK中获取 nextBeginOffset)。若没有收到响应,则会重新提交,直到获取到响应。而在这个等待过程中,消费 者是阻塞的。其严重影响了消费者的吞吐量。
- 异步提交:消费者在消费完一批消息后向broker提交offset,但无需等待Broker的成功响应,可以继续读取并消费下一批消息。这种方式增加了消费者的吞吐量。但需要注意,broker在收到提交的offset 后,还是会向消费者进行响应的。可能还没有收到ACK,此时Consumer会从Broker中直接获取 nextBeginOffset。
3.14.消息的清理
消息不会被单独清理,消息是顺序存储到commitlog的,消息是以commitlog为单位进行清理,RocketMQ有自己的清理规则,默认是72小时候后进行清理
-
到达时间清理点,自动清理过期的文件(凌晨4点)
-
磁盘空间使用率达到了过期清理阈值(75%),自动清理过期的文件。
-
磁盘占用率达到清理阈值(85%),开始按照设定的规则清理文件,从老的文件开始。
-
磁盘占用率达到系统危险阈值(90%),拒绝写入数据。