照片由 兹比内克·布里瓦尔 on Unsplash
一、介绍
欢迎来到我关于 NumPy 的教程的第二部分!之前,我们已经介绍了以下列表中的前 7 章。现在在这篇文章中,我们将从第 8 章一直到第 14 章。
- Numpy 安装
- 数组初始化
- Numpy 数组限制
- 计算速度和内存使用率
- 数据类型
- 索引和切片
- 数组生成函数
- 随机数
- 查看和复制
- 数学函数
- 逻辑运算符和按位运算符
- 搜索和排序
- 塑造和重塑
- 串联和拆分
注意:本文中使用的所有资源都可以在我的 GitHub 存储库中找到。 这是它的链接。
八. 随机数
Numpy 允许我们生成随机数。就我而言,当我尝试从头开始实现机器学习和深度学习模型时,我曾经使用过此功能来初始化它们。我相信这种 Numpy 功能必须有其他应用程序。
8.1 均匀分布
现在让我们从 开始。此函数从 [0.0, 1.0] 范围内的均匀分布生成随机数。这意味着这个数字可能正好是 0.0,但它只能接近 1.0。要使用这个函数,我们只需要传递我们想要的数组的形状。 实际上相当于 。但是,请记住,此函数的输入需要采用元组形式。这两个函数中的任何一个实际上都可以互换使用,因为这只是一个偏好问题。np.random.rand()、np.random.random()、np.random.rand()
# Codeblock 1
np.random.rand(10,3)
### Alternative
# np.random.random((10,3))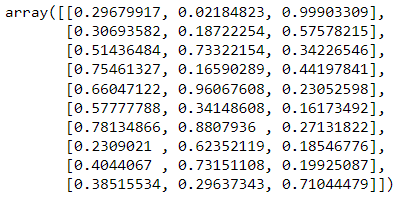
图 1.从形状为 10×3 的均匀分布创建随机数数组。
仍然与随机均匀分布有关,如果您需要更多的灵活性,则可以使用 .这个函数允许我们指定分布的范围,而不仅仅是固定在 [0.0, 1.0]。在下面的代码块中,我演示了如何设置函数,使数字范围在 90 到 100 之间。np.random.uniform()
# Codeblock 2
np.random.uniform(low=90, high=100, size=(5,5))
图2.数字分布现在在 90 到 100 之间。
如果我们把均匀分布的数字放到 ,我们可以看到所有的 bin(第一个索引中的数组)都有相似的出现频率。在下面的示例中,我生成了 50,000 个号码,然后将其分配到 10 个箱中。这导致每个 bin 大约有 5,000 次出现。随机均匀函数 (和 ) 的三个变体都以这种方式运行。np.histogram()np.random.rand()np.random.random()np.random.uniform()
# Codeblock 3
np.histogram(np.random.uniform(size=(50000)))
### Yields similar results
# np.histogram(np.random.rand(50000))
# np.histogram(np.random.random(50000))
图3.np.histogram() 的输出有两个:第一,每个 bin 的出现次数,第二,每个 bin 的边界。
8.2 正态分布
不仅均匀分布,我们还可以使用 创建正态分布的数据。我们在这里唯一可以传递的参数是要创建的数组的形状。np.random.randn()
# Codeblock 4
np.random.randn(6,4)
图4.此数组中的值呈正态分布。
不幸的是,它不允许我们改变分布的均值和标准差。在此函数中,两个参数分别固定为 0 和 1。如果要自定义这些值,则应改用。在 中,可以使用参数调整均值,而可以使用参数修改标准差。np.random.randn()np.random.normal()np.random.normal()locscale
# Codeblock 5
np.random.normal(loc=8, scale=3, size=(5,5))
图5.此数组的值分布现在以 8 为中心,标准差为 3。
我之前使用的函数可用于验证数组是否由正态分布生成并确实遵循正态分布。下面的图 6 说明了这一点,因为第一个数组显示中间的 bin 包含出现频率最高的内容。np.histogram()、np.random.randn()、np.random.normal()
# Codeblock 6
np.histogram(np.random.normal(loc=0, scale=1, size=50000))
### Yields similar result
# np.histogram(np.random.randn(50000))
图6.在正态分布中,中间的条柱通常包含最高频率的数据。
到目前为止,我确实承认在生成随机数时有很多类似的函数,尤其是那些与均匀分布和正态分布相关的函数。在这种特殊情况下,我建议您只使用,因为两者是最灵活的。np.random.uniform()np.random.normal()
8.3 随机整数
我们之前讨论的函数主要集中在生成随机浮点数上。事实上,Numpy 为我们提供了一个生成随机整数的函数,即 。此函数的参数和行为与 相同。指定范围内的所有数字将具有完全相同的被选中概率。换句话说,使用均匀离散分布作为数字选择的基础。在下面的示例中,生成的数字将在 [5,10] 的范围内(这意味着不包括 10)。np.random.randint()np.random.uniform()np.random.randint()
# Codeblock 7
np.random.randint(low=5, high=10, size=(20,3))
图7.由 np.random.randint() 生成的整数数组。
8.4 数组洗牌
接下来要讲的函数是。但在我们进一步讨论之前,我想先初始化数组。np.random.shuffle()K
# Codeblock 8
K = np.random.randint(1, 30, size=10)
K![]()
图8.数组 K 的样子。
正如您可能已经猜到的那样,是一个函数,可让我们打乱数组中元素的顺序。请记住,此函数将数组洗牌到位,这基本上意味着它直接洗牌原始数组,而不是创建一个新数组。np.random.shuffle()
# Codeblock 9
print('K before shuffle\t: ', K)
np.random.shuffle(K)
print('K after shuffle\t\t: ', K)![]()
图 9.数组 K 在洗牌前后的样子。
8.5 随机选择
仍在使用数组,现在如何从中随机选择一个数字?我们可以使用 .在下面的代码块中,我演示了如何使用该函数的几个示例。Knp.random.choice()
# Codeblock 10
print(np.random.choice(K), end='\n\n') #(1)
print(np.random.choice(K, size=(2,3)), end='\n\n') #(2)
print(np.random.choice(K, size=(2,4), replace=False)) #(3)
图 10.上述示例的输出。
在 标记的行处,如果我们只将一个数组传递给函数,它将返回从该数组中获取的单个数字。我们还可以使用参数指定输出的维度,如 行 所示。您可以注意到相应的输出,数字 16 出现了两次。这主要是因为默认情况下,该函数选择带有替换的随机数,即可以多次取原始数组中的单个数字。如果你不希望发生这样的替换,那么你可以像我在行上所做的那样写。请注意,如果这样做,则生成数组中的元素数不能大于源数组的元素数。如果您想知道,在第三个输出中出现两次的数字 12 基本上是因为数组中确实出现了两次 12 。#(1)size#(2)replace=False#(3)K
8.6 种子
在许多情况下,您希望生成的随机数是可重现的。这可以使用 来实现。使用它的方法很简单,您只需将一个数字作为参数,并在您希望输出完全相同的笔记本单元格中使用相同的数字。让我们考虑以下示例。在这里,我希望生成的数组在两个连续的代码块中完全相同。在这里,我决定将种子设置为 99(不过您基本上可以选择任何整数)。为了使返回完全相同的数字,我们需要使用相同的种子再次调用。np.random.seed()np.random.randint()np.random.randint()np.random.seed()
# Codeblock 11
np.random.seed(99)
np.random.randint(low=0, high=10, size=(2,5))
图 11.从代码块 11 返回的数组。
# Codeblock 12
np.random.seed(99)
np.random.randint(low=0, high=10, size=(2,5))
图 12.如果我们对 np.random.seed() 和 np.random.randint() 使用完全相同的参数,则可以获得相同的结果。如果我们使用不同的种子,那么即使 np.random.randint() 的参数相同,输出也会有所不同。
九、查看和复制
9.2 视图
由于 Numpy 的性质,在将数组从一个变量分配给另一个变量时,我们需要小心。让我们看一下下面的例子。
# Codeblock 13
L = np.array([55, 66, 77, 88, 99])
M = L
print(M)![]()
图 13.数组 M.
假设这里我们得到了数组并将其赋值,以便两个变量包含相同的数组。接下来,我们要更改下面使用 Codeblock 14 的第 0 个索引。但是,即使我们只打算更改 的第一个元素,数组中的元素也会被更改。LMMML
# Codeblock 14
M[0] = 15
print('L:', L)
print('M:', M)![]()
图 14.数组 L 也会被更改,即使我们只打算更改 M 的第一个元素。
我们之所以得到这个结果,本质上是因为只是 的“视图”。换句话说,我上面演示的方法实际上并没有复制数组,因为这两个变量仍然是“连接”的。ML
9.3 复制
如果您不希望发生上述情况,您可以做的是在将方法分配给 时将其放在 上。通过这样做,存储在中的数组将是一个完全不同的数组,确保对一个数组的修改不会影响另一个数组。copy()LMM
# Codeblock 15
L = np.array([55, 66, 77, 88, 99])
M = L.copy()
M[0] = 15
print('L:', L)
print('M:', M)![]()
图 15.使用 copy() 方法允许独立修改两个数组。
十、数学函数
10.1 基本数学运算
在本章中,我想讨论如何使用 Nampy 的数学功能。在我们开始之前,让我们提前初始化数组。NO
# Codeblock 16
N = np.array([1,2,3], dtype='int32')
O = np.array([4,5,6], dtype='int32')我们将首先从最基本的开始:加法、减法、乘法和除法。在 Numpy 中,如果我们在数组上应用这些运算符,这些操作将以元素的方式执行。因此,您需要确保数组操作数具有完全相同的维度。
# Codeblock 17
print(N + O)
print(N - O)
print(N * O)
print(N / O)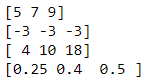
图 16.Codeblock 17 生成的数组。
上面代码块 17 中演示的方法只能用于 Numpy 数组。如果您尝试在列表上执行相同的操作,则所有这些示例都会导致错误,除非求和将两个列表连接起来。
或者,您还可以使用 Numpy 提供的函数,即 、 和 。运算符符号和函数产生完全相同的结果。因此,在这种情况下,这只是偏好问题。下面的代码块演示了我如何使用这些函数。结果输出与图 16 中所示的输出完全相同。
np.add()np.subtract()np.multiply()np.divide()
# Codeblock 18
print(np.add(N, O))
print(np.subtract(N, O))
print(np.multiply(N, O))
print(np.divide(N, O))在 Numpy 中,有一个称为“广播”的概念,它本质上意味着我们可以在不同大小的数组之间或数组和标量之间执行操作。在下面的例子中,我们可以说数字 5 被广播到数组中的所有元素。N
# Codeblock 19
print(N + 5)
print(N - 5)
print(N * 5)
print(N / 5)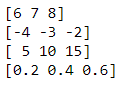
图 17.数组 N 中的所有元素都经过 5 的运算。
接下来我要讨论的是矩阵乘法。正如我之前提到的,四个基本的数学运算函数以元素的方式工作。这基本上意味着它不适用于矩阵乘法。相反,我们需要使用它来这样做。在这种情况下,我们需要确保两个输入矩阵是可操作的。在下面的示例中,我在数组 和 之间执行乘法,其中它们的大小分别为 (4,3) 和 (3,2)。
np.multiply()np.matmul()OP
# Codeblock 20
O = np.array([[2, 1, 0],
[5, 4, 3],
[8, 7, 6],
[1, 0, 9]])
P = np.array([[4, 3],
[6, 5],
[8, 7]])
np.matmul(O, P)
图 18.大小为 4×3 和 3×2 的矩阵之间的乘法得到另一个大小为 4×2 的矩阵。
其他仍然与基本数学运算相关的函数是 和 。我将演示这些函数在数组上的用法。np.sign()np.negative()np.abs()Q
# Codeblock 21
Q = np.array([-56, 92, -24, -66, 72, -75, 90, 0, 32, 51])
print(np.sign(Q))
print(np.negative(Q))
print(np.abs(Q)) # Alternative: np.absolute()
图 19.np.sign()、np.negative() 和 np.abs() 的输出。
正如函数名称所暗示的那样,用于获取数组中每个元素的符号。只有 3 个可能的输出:-1、0 和 1。接下来,我们可以用来翻转一个数字的符号。在上面的示例中,-56 变为 56,92 变为 -92,依此类推。最后,我们可以使用 or 来取一个数字的绝对值。np.sign()np.negative()np.abs()np.absolute()
10.2 GCD 和 LCM
最大公约数 (GCD) 和最小公倍数 (LCM) 分别在 Numpy 中实现。为了使这些函数工作,我们可以简单地将要计算的两个数字或数组作为输入参数。np.gcd()np.lcm()
# Codeblock 22
print(np.gcd(81, 72)) #(1)
print(np.lcm([3, 6, 9], 24)) #(2)
print(np.lcm([3, 12, 9], [24, 16, 3])) #(3)
图 20.代码块 22 中 np.gcd() 和 np.lcm() 的输出。
让我们看一下上面 Codeblock 22 中的示例。标记的行返回一个数字,即 81 和 72 的 GCD。同时,在第 24 行将数字广播到第一个参数,其中 LCM 在 24 和列表中的每个数字之间计算。最后,如果我们传递两个参数的列表,那么 LCM 或 GCD 计算将以元素方式 () 完成。#(1)#(2)#(3)
10.3 指数函数
可以使用 执行指数运算。此函数接受两个输入:基数和指数。该函数非常灵活,因为我们还可以传递指数的小数,以便我们也计算根。np.power()
# Codeblock 23
print(np.power(8, 3))
print(np.power([1,2,3,4], 2))
print(np.power(144, 1/2))
图 21.代码块 23 中 np.power() 的输出。
尽管有这种灵活性,但在计算速度方面实际上并不是最好的。实际上,还有其他几种用于特定目的的替代方案可以提供更快的计算速度,即 、 和 。随后的代码块说明了这些函数与 的等效用法。np.power()np.square()np.sqrt()np.cbrt()np.exp()np.power()
# Codeblock 24
print(np.square(6)) # Equivalent with: np.power(6,2)
print(np.sqrt([144,16,9,4])) # Equivalent with: np.power([144,16,9,4], 1/2)
print(np.cbrt([343,27])) # Equivalent with: np.power([343,27], 1/3)
print(np.exp([2,3,4])) # Equivalent with: np.power(np.e, [2,3,4])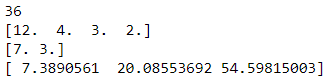
图 22.代码块 24 中 np.square()、np.sqrt()、np.cbrt() 和 np.exp() 的输出。
10.4 角度转换和三角函数
三角函数在 Numpy 中可用。在使用 时需要记住的一件事是,这些函数接受弧度的角度。所以,如果你有一个角度,你需要先把它传递给。下面的代码块 25 显示了如何将度数转换为弧度,反之亦然。np.sin()np.cos()np.tan()np.deg2rad()
# Codeblock 25
R = np.array([0, 90, 180, 270]) # Angles in degree
S = np.array([0, np.pi/2, np.pi, np.pi*3/2]) # Angles in radian
print(np.deg2rad(R))
print(np.rad2deg(S))![]()
图 23.角度转换结果。
由于我们已经了解了如何进行角度转换,现在我将演示三角函数的使用。在下面的代码中,我假设数字 0、45 和 60 表示以度为单位的角度。这些数字被转换为弧度,然后存储在数组中,然后用作 和 的输入。Tnp.sin()np.cos()np.tan()
# Codeblock 26
T = np.deg2rad([0, 45, 60])
print(np.sin(T))
print(np.cos(T))
print(np.tan(T))
图 24.代码块 26 中三角函数的输出。
10.5 对数函数
说到对数函数,我想至少有三个可以被认为是最基本的函数。下面的代码块 27 显示了我如何使用 和 on 数组。np.log()np.log2()np.log10()U
# Codeblock 27
U = [1, 2, 10, np.e]
print(np.log(U))
print(np.log2(U))
print(np.log10(U))
图 25.数组 U 上 np.log()、np.log2() 和 np.log10() 的输出。
在 Numpy 中,相当于数学中的 ln() 函数(以 e 为基数的对数)。同时,和 分别是以 2 和 10 为基数的对数。np.log()np.log2()np.log10()
10.6 统计函数
如果具有数值数据分布,则可以通过计算其统计特征对其进行进一步分析。幸运的是,Numpy 提供了许多功能,我们可以用来轻松完成任务。与此相关的所有函数(我猜它们都是不言自明的)都显示在代码块 28 中。
# Codeblock 28
V = np.array([1, 5, 4, 6, 8, 5, 4, 3, 2, 4, 7, 9, 5, 4, 3, 2, 0, 7, 9])
print('sum\t:', np.sum(V))
print('mean\t:', np.mean(V))
print('median\t:', np.median(V))
print('var\t:', np.var(V))
print('stddev\t:', np.std(V))
print('q1\t:', np.quantile(V, 0.25))
print('q2\t:', np.quantile(V, 0.5))
print('q3\t:', np.quantile(V, 0.75))
print('min\t:', np.min(V))
print('max\t:', np.max(V))
图 26.数组 V 的统计特征。
除了这个主题之外,实际上还有另外两个函数与统计测量没有直接关系,但它们可能仍然有用。我所指的两个函数是 和 ,它们返回包含数组中最小和最大数字的索引。如果存在多个最低值或最高值,则这两个函数都将返回索引最低的值。np.argmin()np.argmax()
# Codeblock 29
print('argmin\t:', np.argmin(V))
print('argmax\t:', np.argmax(V))![]()
图 27.包含数组 V 中最小和最大数字的索引。
10.7 线性代数
Numpy 提供了一套丰富的工具来执行线性代数计算。在这里,我想向你们展示我们可以做的几件事。假设我们有两个数组,如代码块 30 所示。
# Codeblock 30
W = np.array([10, 20, 30, 40])
X = np.array([3, 4, 5, 6])在 Numpy 中,我们可以将一维数组视为向量。因此,可以使用 来计算 和 的点积。WXnp.dot()
# Codeblock 31
np.dot(W, X)![]()
图 28.数组 W 和 X 之间的点积。
此外,Numpy 还允许我们通过 和 计算内积和外积。np.inner()np.outer()
# Codeblock 32
print(np.inner(W, X))
print(np.outer(W, X))
图 29.数组 W 和 X 的内积和外积。
现在让我们更深入地了解一下,如果我们处理 2D 数组,我们可以做什么。在演示之前,我想提前初始化数组。Y
# Codeblock 33
Y = np.array([[2, 1, 0],
[0, 4, 5],
[2, 6, 3]])为了获得矩阵的转置,我们可以使用或简单地获取该矩阵的属性。请参阅下面的代码块。np.transpose()T
# Codeblock 34
np.transpose(Y)
### Alternative
# Y.T
图 30.矩阵 Y 的转置。
Numpy 还提供了一个用于计算矩阵逆函数的函数。这可以使用 来实现。下面是矩阵的逆矩阵的样子。np.linalg.inv()Y
# Codeblock 35
np.linalg.inv(Y)
图 31.矩阵 Y 的逆矩阵。
但是,重要的是要记住,每当矩阵为奇异时,即行列式为 0,就会返回误差。因此,我认为在计算矩阵的逆函数之前检查矩阵行列式值可能是一个好主意。np.linalg.inv()np.linalg.det()
# Codeblock 36
np.linalg.det(Y)![]()
图 32.矩阵 Y 被认为是非奇异的,因为它的行列式不为零。因此,这个矩阵是可逆的。
此外,Numpy 允许我们使用 .由于此函数同时返回这两个变量,因此您需要确保为输出分配两个变量。np.linalg.eig()
# Codeblock 37
eigenvalues, eigenvectors = np.linalg.eig(Y)
print(eigenvalues, end='\n\n')
print(eigenvectors)
图 33.矩阵 Y 的特征值和特征向量。
到目前为止,我们已经讨论了 Numpy 中的许多数学函数。事实上,实际上还有很多我没有解释的。如果您有兴趣探索更多,可以访问此网站 [1]。
11. 逻辑运算符和按位运算符
11.1 逻辑运算符
在本文的开头,我提到 Numpy 允许我们创建布尔数据类型的数组,但我还没有深入研究这个话题。现在,我想在本章中谈谈它。让我们从初始化两个数组开始,我将其命名为 和 。ZAA
# Codeblock 38
Z = np.array([True, True, True])
AA = np.array([False, True, True])执行布尔运算的最简单方法是使用 、 和 。如果我们放置两个与参数相同维度的数组,那么这些函数将执行元素操作。请参阅以下示例。np.logical_and()np.logical_or()np.logical_xor()
# Codeblock 39
print(np.logical_and(Z, AA))
print(np.logical_or(Z, AA))
print(np.logical_xor(Z, AA))
图 34.数组 Z 和 AA 之间的 AND、OR 和 XOR 运算的结果。
实际上有两个特殊函数有点类似于 OR 和 AND 运算符,即 和 。如果数组中至少有一个,则前者返回。同时,只有当数组中的所有元素都是 时,后者才会返回。在下面的 Codeblock 40 中,我演示了如何在数组和 .np.any()np.all()TrueTrueTrueTrueZ AA
# Codeblock 40
print('np.any(Z): ', np.any(Z))
print('np.all(Z): ', np.all(Z), end='\n\n')
print('np.any(AA):', np.any(AA))
print('np.all(AA):', np.all(AA))
图 35.np.any() 和 np.all() 在数组 Z 上都返回 True,因为它的所有元素都是 True。同时,np.all() 在数组 AA 上返回 False,因为它的一个元素是 False。
我们实际上可以在使用 和 方面更先进一些。在以下代码块中标记的行处,如果数组中至少有一个数字大于 4,则将返回。接下来,只有当 的所有元素都大于 4 时,line 才会返回。np.any()np.all()#(1)np.any()TrueAB#(2)TrueAB
# Codeblock 41
AB = np.array([2, 0, 3, -5, 5, -1, 2, -4])
print(np.any(AB > 4)) #(1)
print(np.all(AB > 4)) #(2)![]()
Figure 36. There is only one number in array AB which is greater than 4, hence np.any(AB > 4) returns True while np.all(AB > 4) returns False.
图 36. 数组 AB 中只有一个数字大于 4,因此 np.any(AB > 4) 返回 True,而 np.all(AB > 4) 返回 False。
11.2 位操作 Operators
位运算符可能看起来不像逻辑运算符那么简单。不过,两者的基本思想是完全相同的,只不过按位运算符以整数作为输入。在运算过程中,这些整数先转换为二进制,然后再按位方式进行运算。在下面的示例中,我将 12 和 13 作为 , 和 .np.bitwise_and()np.bitwise_or()np.bitwise_xor() 的输入参数
# Codeblock 42
print(np.bitwise_and(12, 13))
print(np.bitwise_or(12, 13))
print(np.bitwise_xor(12, 13))![]()
图 37.代码块 42 的输出。
上述所有函数最初都是通过将 12 和 13 转换为二进制来工作的:1100 和 1101。对这些值执行 AND 运算符将得到 1100。同时,OR 运算符返回 1101,XOR 返回 0001。将这些二进制序列转换为十进制会导致我们在最终输出中有 12、13 和 1。
除了这个主题之外,我们还可以使用 检查十进制数的二进制表示。np.binary_repr()
# Codeblock 43
print(np.binary_repr(12))
print(np.binary_repr(13))![]()
图 38.12 和 13 的二进制表示形式。
12. 搜索和排序
12.1 搜索
在查找特定数字时,我们可以使用一种称为布尔索引的技术。我们实际上可以把这种方法想象成一种掩蔽。在这里,我想在数组上演示这个想法,我在以下代码块中初始化了该数组。AC
# Codeblock 44
AC = np.array([9, 4, 5, 3, 2, 6, 8, 6, 5, 4, 5, 5, 3, 2])
mask = AC > 5 #(1)
mask![]()
图 39.掩码数组。
称为“mask”的数组基本上是另一个长度与 完全相同的数组,其中它仅包含布尔值。要创建这样的数组,我们可以简单地应用一个条件,就像我在 line .在那行代码中,检查数组中的每个元素是否满足指定的条件。如果是这样,则相应的索引将分配 .AC#(1)ACTrue
然后使用下面的代码块 45 执行实际的屏蔽。通过这样做,打印的数字只是那些符合我们标准的数字。
# Codeblock 45
AC[mask]![]()
图 40.布尔索引结果。
事实上,您不一定需要将掩码存储在单独的变量中。相反,我们可以简单地这样写下来:
# Codeblock 46
AC[AC > 5]![]()
图 41.执行布尔索引的更简单方法。
也可以使用逻辑运算符。以下示例打印出除 9 之外的所有大于 5 的元素。
# Codeblock 47
AC[(AC > 5) & (AC != 9)]![]()
图 42.使用逻辑运算符执行布尔索引。
我们实际上可以使用 来实现同样的事情。以下是如何操作。我不显示结果输出,因为它与前一个完全相同。np.where()
# Codeblock 48
AC[np.where((AC > 5) & (AC != 9))]该函数本身基本上是通过返回满足指定条件的数组的索引来工作的。在这种特殊情况下,所选索引是 5、6 和 7,它们实际上对应于阵列 AC 上的 6、8 和 6。np.where()
# Codeblock 49
np.where((AC > 5) & (AC != 9))
# Recall the elements of AC: [9, 4, 5, 3, 2, 6, 8, 6, 5, 4, 5, 5, 3, 2].![]()
图 43.np.where() 的输出是什么样的。
np.where()如果我们将 3 个参数传递给它,即 ,并且按照确切的顺序,也会更有用。我们可以这样想这些论点:“如果返回,则执行。为了更好地说明这一点,以下代码会在数组中的所有元素的值大于 5 时将其转换为 0。否则,该数字将加 2。conditionxyxconditionTrueyAC
# Codeblock 50
print(AC)
print(np.where(AC > 5, 0, AC+2))![]()
图 44.原始数组 AC(上图)与使用 np.where() 修改后的数组 AC(下图)相比。
如果要求我们找出数组中唯一值的数量,我们可以这样做。使用这个函数的方法很简单,我们可以把数组作为唯一的一个参数。或者,如果需要,也可以使用 获取这些值的出现次数。np.unique()return_counts=True
# Codeblock 51
np.unique(AC, return_counts=True)![]()
图 45.np.unique() 如果我们将 return_counts 设置为 True,则返回两个数组。第二个数组包含相应值的出现次数。
12.2 排序
正如函数的名称所暗示的那样,是我们对数组进行排序所需的函数。例如,这里我得到了数组,我们将在其中对它们进行排序。np.sort()ADAE
# Codeblock 52
AD = np.array([77,33,44,99,22,88,55,11,66])
AE = np.array(["Elon Musk", "Bill Gates", "Joe Biden", "Barack Obama"])
print(np.sort(AD))
print(np.sort(AE))![]()
图 46.排序后的阵列 AD 和 AE。
在上面的输出中,您可以看到两个数组都是按升序排序的。实际上,它没有一个参数,我们可以设置该参数来使结果数组按降序排序。因此,如果我们想这样做,我们可以使用 .np.sort()np.flip()
# Codeblock 53
print(np.flip(np.sort(AD)))
print(np.flip(np.sort(AE)))
### Alternative
# print(np.sort(AD)[::-1])
# print(np.sort(AE)[::-1])![]()
图 47.使用 np.flip() 翻转数组。使用[::-1]索引方法也可以实现同样的事情。
如果你想对数组进行排序,但你只需要索引(而不是值),我们可以使用 .np.argsrot()
# Codeblock 54
np.argsort(AD)
# Recall the elements of AD: [77, 33, 44, 99, 22, 88, 55, 11, 66].![]()
图 48.已排序的数组 AD 的索引。
图 48 所示的输出基本上告诉我们,第 7 个索引包含数组中的最小数字,然后是 、 等。为了确保排序是否正常工作,我们可以使用整个输出来执行索引,如下所示:AD AD[4]AD[1]np.argsort()
# Codeblock 55
AD[np.argsort(AD)]![]()
图 49.使用 np.argsort(AD) 的输出对数组 AD 本身进行索引。这会产生与 np.sort(AD) 完全相同的结果。
在 2D 数组的情况下,我们可以使用参数确定排序方向。这可以同时应用于 和 。让我们考虑下面的数组。axisnp.sort()np.argsort()AF
# Codeblock 56
AF = np.array([[3, 1, 5, 7],
[8, 9, 3, 2],
[4, 8, 2, 6]])如果我们希望上述矩阵沿列排序,我们应该使用 。同时,让我们沿着行对它进行排序。下面的代码块 57 显示了如何做到这一点。axis=0axis=1
# Codeblock 57
print(np.sort(AF, axis=0), end='\n\n')
print(np.sort(AF, axis=1))
图 50.用于沿列(上图)执行排序。如果我们将轴设置为 1,它将沿行(如下)执行排序。axis=0
本章我想谈的最后一件事实际上与排序不太相关,但它仍然与数组序列有些相关。我说的功能是你可以用它来对元素执行圆周移。为了说明这个想法,我将首先创建一个序列。np.roll()
# Codeblock 58
AG = np.arange(13)
AG![]()
图 51.我们将执行 np.roll() 的序列。
现在使用下面的代码块,我们可以根据我们传递给参数的值来旋转序列。在这种情况下,我尝试向右旋转 3 次 () 和向左旋转 3 次 ()。shiftAG#(1)#(2)
# Codeblock 59
print(np.roll(AG, shift=3)) #(1)
print(np.roll(AG, shift=-3)) #(2)![]()
图 52.数组旋转结果。
13. 塑造和重塑
在 Python 列表中,我们可以使用该函数来找出它拥有的元素数量。这种方法实际上对多维数组不是很有效,因为它只能计算最外层的维度。正如下面的代码块所示,该函数仅返回 5,它不代表整个数组维度。len()len()
# Codeblock 60
AH = np.array([[0, 1, 2, 3, 4, 5],
[6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23],
[24, 25, 26, 27, 28, 29]])
len(AH)![]()
图 53.len() 函数只返回 5,即外部数组的元素数。
与函数不同的是,我们可以通过获取 Numpy 数组的属性来获得更精确的结果。下面的代码块 61 的输出表明数组由 5 个内部数组组成,其中每个内部数组由 6 个元素组成。我们可以把它想象成一个大小为 5×6 的矩阵,正如我在上一章中解释的那样。或者,如果您对图像处理感兴趣,这对应于高度为 5 像素、宽度为 6 像素的图像。len()shapeAH
# Codeblock 61
AH.shape![]()
图 54.AH 阵列的形状。
Numpy 允许我们通过该方法重塑数组。在下面的示例中,我将重塑尺寸为 (3,10).reshape()AH
# Codeblock 62
AH.reshape(3,10)
图 55. 阵列重塑结果。 重塑数组时要记住的一件重要事情是,在重塑操作之前和之后元素总数必须保持不变。换句话说,数组维度应该是元素总数的一个因素。如果我们不满足这个要求,它将返回错误。 数组重塑不仅仅限于二维数组。在下面的代码块中,我将数组转换为 3D。
# Codeblock 63
AH.reshape(2,3,5)
图 56. 将 2D 数组转换为 3D。 如果您不确定为轴选择的数字,您可以简单地写入 -1,Numpy 会自动为其设置一个值。但是,请记住,Numpy 不允许我们一次传递多个 -1。
# Codeblock 64
AH.reshape(-1,5)
图 57. 在本例中,-1 自动将第一个轴设置为 6。 下面是另一个例子。在本例中,我将数组设置为 30 行 1 列。
# Codeblock 65
AH.reshape(-1,1)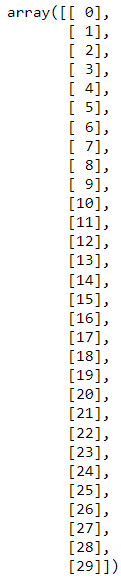
图 58.-1 将第一个轴设置为 30。
如果您有一个多维数组,并且想要将其重塑为一维,则可以使用 或 方法。flatten()reshape(-1)
# Codeblock 66
AH.flatten()
### Alternative
# AH.reshape(-1)![]()
图 59.使用 np.flatten() 将数组转换为 1D(展平)。
除了这个主题之外,如果我们有一个数组,我们想添加一个空轴,我们可以使用它来这样做。老实说,对我来说,这种技术并不简单。因此,我通常用于实现与我在 Codeblock 65 中所做的相同的事情。np.newaxisnp.reshape()
# Codeblock 67
AH.flatten()[:, np.newaxis]
### Alternative
# AH.flatten().reshape(-1,1)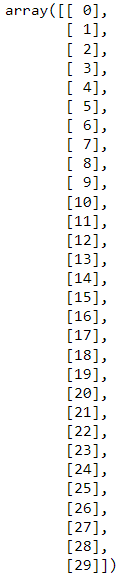
图 60.使用 np.newaxis 添加列轴。数组形状现在是 (30, 1)。
下面是 的另一个示例。在这里,我用它来为行添加一个新轴。np.newaxis
# Codeblock 68
AH.flatten()[np.newaxis, :]
### Alternative
# AH.flatten().reshape(1,-1)![]()
图 61.添加行轴。数组形状现在是 (1, 30)。
14. 串联和拆分
14.1 串联
可以使用该方法将新元素添加到 Python 列表。在 Nupy 中,有几种替代方法,即 、 、 和 。尽管这些函数的主要思想基本相同,即组合多个数组,但所有这些函数都有不同的用途。append()np.vstack()np.hstack()np.append()np.concatenate()
在我们开始讨论这个话题之前,我想先初始化两个新数组:和 。AIAJ
# Codeblock 69
AI = np.array(np.random.randint(0, 5, (2,4)))
AJ = np.array(np.random.randint(5, 10, (2,4)))
print(AI, end='\n\n')
print(AJ)
图 62.我们将使用上面的两个数组来演示上述函数。
要通过垂直连接两个数组来组合它们,我们可以使用 .np.vstack()
# Codeblock 70
np.vstack((AI,AJ))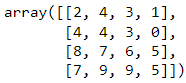
图 63.垂直堆叠结果。
正如您可能已经猜到的那样,用于水平堆叠两个数组。np.hstack()
# Codeblock 71
np.hstack((AI,AJ))![]()
图 64.水平堆叠结果。
两者都能够同时堆叠多个阵列。需要注意的是,当数组的列数相同时,可以进行垂直堆栈。在水平堆栈的情况下,它只有在数组具有相同的行数时才有效。np.vstack()np.hstack()
# Codeblock 72
print(np.vstack((AI,AJ,AJ,AJ,AI)), end='\n\n')
print(np.hstack((AI,AJ,AJ,AJ,AI)))
图 65.一次堆叠多个阵列。
接下来,在实际连接数组之前,先将数组展平。因此,生成的输出将是一个一维数组。尽管有这种默认行为,我们可以通过使用参数使行为与相同。np.append()np.append()np.vstack()np.hstack()axis
# Codeblock 73
print(np.append(AI, AJ), end='\n\n')
print(np.append(AI, AJ, axis=0), end='\n\n')
print(np.append(AI, AJ, axis=1))
图 66.axis=0 和 axis=1 导致 np.append() 的行为分别类似于 np.vstack() 和 np.hstack()。
事实上,它不允许我们一次组合两个以上的数组。如果要这样做,可以改用。该参数的工作方式也与 相同。如果未指定 的值,则将执行垂直堆栈。np.append()np.concatenate()axisnp.append()axisnp.concatenate()
# Codeblock 74
print(np.concatenate([AI, AI, AI], axis=None), end='\n\n')
print(np.concatenate([AI, AI, AI]), end='\n\n')
print(np.concatenate([AI, AI, AI], axis=1))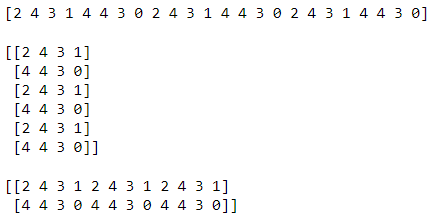
图 67.使用 np.concatenate() 组合多个数组。
14.2 分裂
不仅用于堆叠,Numpy 还为我们提供了一些拆分功能。让我们考虑下面的数组。AK
# Codeblock 75
AK = np.random.randint(0, 10, (20))
AK![]()
图 68.阵列 AK 的样子。
我想先演示一下。此函数接受两个主要参数:(要拆分的数组)和(拆分点)。在下面的代码中,我尝试在索引 3 和 5 处拆分数组,从而生成三个新数组。这些数组中的每一个都取自原始数组,从索引 0 到 2、3 到 4 和 5 到 19。np.split()aryindices_or_sectionsAL
# Codeblock 76
np.split(AK, indices_or_sections=[3,5])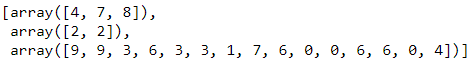
图 69.拆分结果。所有这些数组都存储在一个列表中。
要拆分 2D 数组,我们可以使用 或 。实际上,您也可以通过传递参数来实现相同的目的。主要思想基本相同,只是 和 的分割点分别指行号和列号。我将在数组上演示这两个函数。np.hsplit()np.vsplit()axisnp.split()np.vsplit()np.hsplit()AL
# Codeblock 77
AL = np.random.randint(0, 10, (5,6))
AL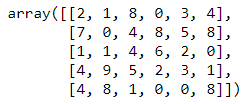
图 70.数组 AL 的样子。
以下是如何使用。np.vsplit()
# Codeblock 78
np.vsplit(AL, [2,4])
### Alternative
# np.split(AL, [2,4], axis=0)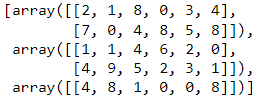
图 71.使用 np.vsplit() 执行垂直拆分。
最后,这是如何使用.np.hsplit()
# Codeblock 79
np.hsplit(AL, [3,4])
### Alternative
# np.split(AL, [3,4], axis=1) #equivalent
图 72.np.hsplit() 生成的水平拆分结果。
15 结束
终于完成了!到目前为止,我们已经涵盖了我经常使用的许多 Numpy 函数。实际上还有很多我没有解释的。但是不要担心,因为您将能够轻松学习使用它们,因为现在您已经掌握了所有基础知识。
感谢您的阅读,希望本文对您有所帮助。下期见。再见!
引用
[1] 通用函数 (ufunc)。NumPy的。Universal functions (ufunc) — NumPy v2.0 Manual [2024年1月8日访问]。
Mastering NumPy: A Comprehensive Guide to Efficient Array Processing (Part 2/2) | by Muhammad Ardi | Jun, 2024 | Python in Plain English