目录结构
注:提前言明 本文借鉴了以下博主、书籍或网站的内容,其列表如下:
1、参考书籍:《PostgreSQL数据库内核分析》
2、参考书籍:《数据库事务处理的艺术:事务管理与并发控制》
3、PostgreSQL数据库仓库链接,点击前往
4、日本著名PostgreSQL数据库专家 铃木启修 网站主页,点击前往
5、参考书籍:《PostgreSQL中文手册》
6、参考书籍:《PostgreSQL指南:内幕探索》,点击前往
1、本文内容全部来源于开源社区 GitHub和以上博主的贡献,本文也免费开源(可能会存在问题,评论区等待大佬们的指正)
2、本文目的:开源共享 抛砖引玉 一起学习
3、本文不提供任何资源 不存在任何交易 与任何组织和机构无关
4、大家可以根据需要自行 复制粘贴以及作为其他个人用途,但是不允许转载 不允许商用 (写作不易,还请见谅 💖)
5、本文内容基于PostgreSQL master源码开发而成
深入理解PostgreSQL数据库之客户端侧auto savepoint的使用和实现
- 文章快速说明索引
- 功能使用背景说明
- 功能实现源码解析
- pgJDBC autosave属性
- psql ON_ERROR_ROLLBACK

文章快速说明索引
学习目标:
做数据库内核开发久了就会有一种 少年得志,年少轻狂 的错觉,然鹅细细一品觉得自己其实不算特别优秀 远远没有达到自己想要的。也许光鲜的表面掩盖了空洞的内在,每每想到于此,皆有夜半临渊如履薄冰之感。为了睡上几个踏实觉,即日起 暂缓其他基于PostgreSQL数据库的兼容功能开发,近段时间 将着重于学习分享Postgres的基础知识和实践内幕。
学习内容:(详见目录)
1、深入理解PostgreSQL数据库之客户端侧auto savepoint的使用和实现
学习时间:
2024年06月20日 22:41:20
学习产出:
1、PostgreSQL数据库基础知识回顾 1个
2、CSDN 技术博客 1篇
3、PostgreSQL数据库内核深入学习
注:下面我们所有的学习环境是Centos8+PostgreSQL master+Oracle19C+MySQL8.0
postgres=# select version();
version
------------------------------------------------------------------------------------------------------------
PostgreSQL 17devel on x86_64-pc-linux-gnu, compiled by gcc (GCC) 8.5.0 20210514 (Red Hat 8.5.0-21), 64-bit
(1 row)
postgres=#
#-----------------------------------------------------------------------------#
SQL> select * from v$version;
BANNER Oracle Database 19c EE Extreme Perf Release 19.0.0.0.0 - Production
BANNER_FULL Oracle Database 19c EE Extreme Perf Release 19.0.0.0.0 - Production Version 19.17.0.0.0
BANNER_LEGACY Oracle Database 19c EE Extreme Perf Release 19.0.0.0.0 - Production
CON_ID 0
#-----------------------------------------------------------------------------#
mysql> select version();
+-----------+
| version() |
+-----------+
| 8.0.27 |
+-----------+
1 row in set (0.06 sec)
mysql>
功能使用背景说明
我们先看一个例子,示例一 如下:
postgres=# select version();
version
------------------------------------------------------------------------------------------------------------
PostgreSQL 17beta1 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 8.5.0 20210514 (Red Hat 8.5.0-21), 64-bit
(1 row)
postgres=#
postgres=# create table t1 (id int primary key);
CREATE TABLE
postgres=# begin;
BEGIN
postgres=*# insert into t1 values(1);
INSERT 0 1
postgres=*# savepoint somename;
SAVEPOINT
postgres=*# insert into t1 values(1);
2024-06-20 07:49:46.746 PDT [180224] ERROR: duplicate key value violates unique constraint "t1_pkey"
2024-06-20 07:49:46.746 PDT [180224] DETAIL: Key (id)=(1) already exists.
2024-06-20 07:49:46.746 PDT [180224] STATEMENT: insert into t1 values(1);
ERROR: duplicate key value violates unique constraint "t1_pkey"
DETAIL: Key (id)=(1) already exists.
postgres=!# rollback to somename;
ROLLBACK
postgres=*# commit;
COMMIT
postgres=# table t1;
id
----
1
(1 row)
postgres=#
如上,非常便于理解,因为savepoint的存在 而不会导致整个事务的回滚!
继续看一个例子,示例二 如下:
postgres=# \d+ t1
Table "public.t1"
Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description
--------+---------+-----------+----------+---------+---------+-------------+--------------+-------------
id | integer | | not null | | plain | | |
Indexes:
"t1_pkey" PRIMARY KEY, btree (id)
Access method: heap
postgres=# table t1;
id
----
1
(1 row)
postgres=# \echo :ON_ERROR_ROLLBACK
off
postgres=# \set ON_ERROR_ROLLBACK on
postgres=#
postgres=# begin ;
BEGIN
postgres=*# insert into t1 values(2);
INSERT 0 1
postgres=*# insert into t1 values(2);
2024-06-20 07:54:10.813 PDT [181022] ERROR: duplicate key value violates unique constraint "t1_pkey"
2024-06-20 07:54:10.813 PDT [181022] DETAIL: Key (id)=(2) already exists.
2024-06-20 07:54:10.813 PDT [181022] STATEMENT: insert into t1 values(2);
ERROR: duplicate key value violates unique constraint "t1_pkey"
DETAIL: Key (id)=(2) already exists.
postgres=*#
postgres=*# commit;
COMMIT
postgres=# table t1;
id
----
1
2
(2 rows)
postgres=#
这是psql变量ON_ERROR_ROLLBACK的使用!PostgreSQL官方文档解释,如下:
ON_ERROR_ROLLBACK:
- 当被设置为on时,如果事务块中的一个语句产生一个错误,该错误会被忽略并且该事务会继续。
- 当被设置为interactive时,只在交互式会话中忽略这类错误,而读取脚本文件时则不会忽略错误。
- 当被重置或者设置为off(默认值)时,事务块中产生错误的一个语句会中止整个事务。
- 错误回滚模式的工作原理是:在事务块的每个命令之前都为你发出一个隐式的SAVEPOINT,然后在该命令失败时回滚到该保存点。
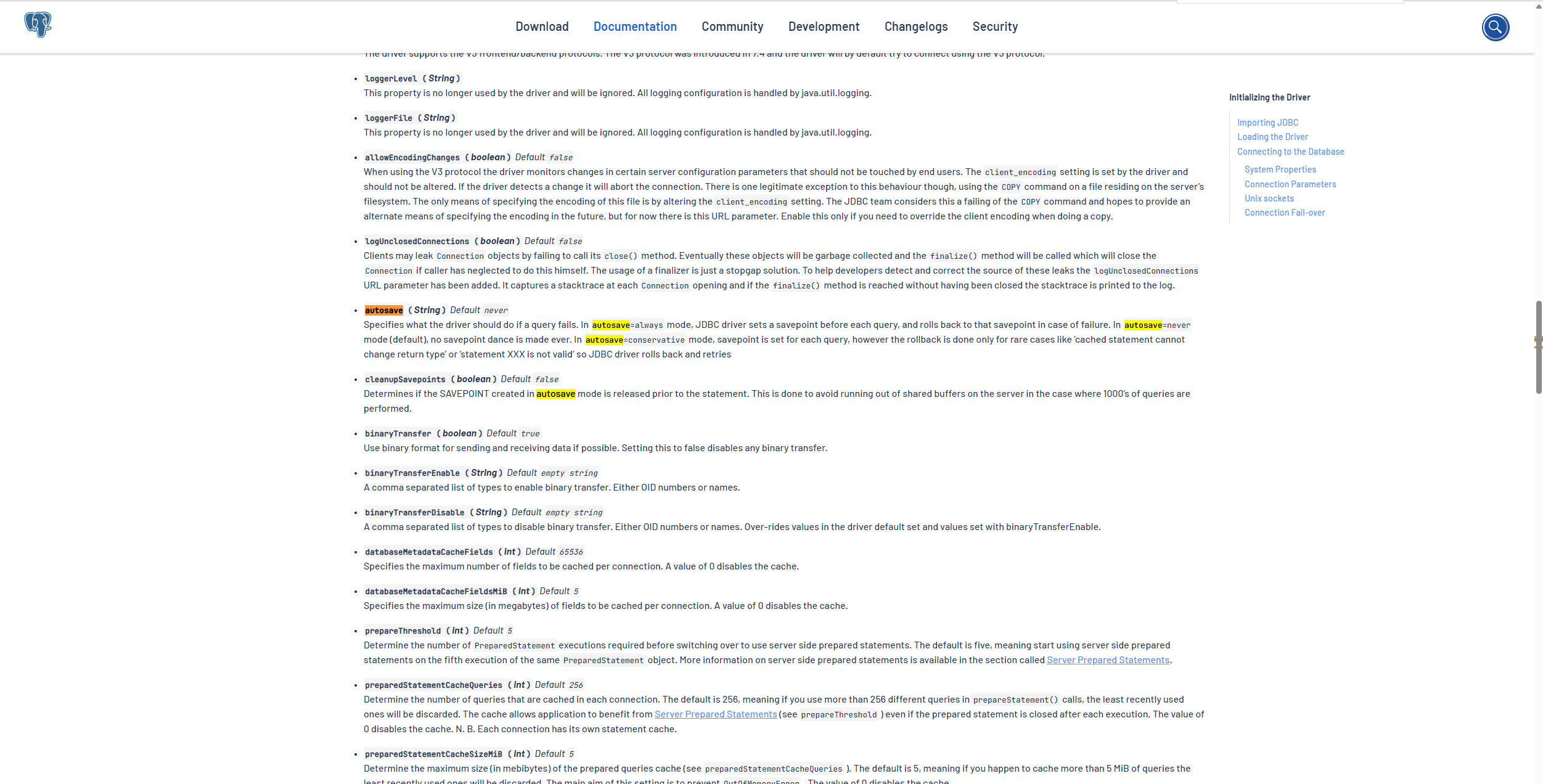
类似的 pgJDBC 中也有一个类似的属性,如下:
- pgJDBC官方文档,点击前往
-
autosave(字符串)默认 never
指定查询失败时驱动程序应执行的操作。在 autosave=always 模式下,JDBC 驱动程序在每次查询前设置一个保存点,并在失败时回滚到该保存点。在 autosave=never 模式(默认)下,永远不会进行保存点切换。在 autosave=conservative 模式下,为每个查询设置保存点,但仅在极少数情况下才会回滚,例如cached statement cannot change return type或statement XXX is not valid,因此 JDBC 驱动程序会回滚并重试 -
cleanupSavepoints(布尔值)默认 false
确定在自动保存模式下创建的 SAVEPOINT 是否在语句之前释放。这样做是为了避免在执行 1000 次查询的情况下耗尽服务器上的共享缓冲区。
功能实现源码解析
pgJDBC autosave属性
// pgjdbc\src\main\java\org\postgresql\core\v3\QueryExecutorImpl.java
@Override
public void execute(Query query, @Nullable ParameterList parameters,
ResultHandler handler,
int maxRows, int fetchSize, int flags, boolean adaptiveFetch) throws SQLException {
try (ResourceLock ignore = lock.obtain()) {
waitOnLock();
if (LOGGER.isLoggable(Level.FINEST)) {
LOGGER.log(Level.FINEST, " simple execute, handler={0}, maxRows={1}, fetchSize={2}, flags={3}",
new Object[]{handler, maxRows, fetchSize, flags});
}
if (parameters == null) {
parameters = SimpleQuery.NO_PARAMETERS;
}
flags = updateQueryMode(flags);
boolean describeOnly = (QUERY_DESCRIBE_ONLY & flags) != 0;
((V3ParameterList) parameters).convertFunctionOutParameters();
// Check parameters are all set..
if (!describeOnly) {
((V3ParameterList) parameters).checkAllParametersSet();
}
boolean autosave = false;
try {
try {
handler = sendQueryPreamble(handler, flags);
autosave = sendAutomaticSavepoint(query, flags);
sendQuery(query, (V3ParameterList) parameters, maxRows, fetchSize, flags,
handler, null, adaptiveFetch);
if ((flags & QueryExecutor.QUERY_EXECUTE_AS_SIMPLE) != 0) {
// Sync message is not required for 'Q' execution as 'Q' ends with ReadyForQuery message
// on its own
} else {
sendSync();
}
processResults(handler, flags, adaptiveFetch);
estimatedReceiveBufferBytes = 0;
} catch (PGBindException se) {
// There are three causes of this error, an
// invalid total Bind message length, a
// BinaryStream that cannot provide the amount
// of data claimed by the length argument, and
// a BinaryStream that throws an Exception
// when reading.
//
// We simply do not send the Execute message
// so we can just continue on as if nothing
// has happened. Perhaps we need to
// introduce an error here to force the
// caller to rollback if there is a
// transaction in progress?
//
sendSync();
processResults(handler, flags, adaptiveFetch);
estimatedReceiveBufferBytes = 0;
handler
.handleError(new PSQLException(GT.tr("Unable to bind parameter values for statement."),
PSQLState.INVALID_PARAMETER_VALUE, se.getIOException()));
}
} catch (IOException e) {
abort();
handler.handleError(
new PSQLException(GT.tr("An I/O error occurred while sending to the backend."),
PSQLState.CONNECTION_FAILURE, e));
}
try {
handler.handleCompletion();
if (cleanupSavePoints) {
releaseSavePoint(autosave, flags);
}
} catch (SQLException e) {
rollbackIfRequired(autosave, e);
}
}
}
@Override
public void execute(Query[] queries, @Nullable ParameterList[] parameterLists,
BatchResultHandler batchHandler, int maxRows, int fetchSize, int flags, boolean adaptiveFetch)
throws SQLException {
try (ResourceLock ignore = lock.obtain()) {
waitOnLock();
if (LOGGER.isLoggable(Level.FINEST)) {
LOGGER.log(Level.FINEST, " batch execute {0} queries, handler={1}, maxRows={2}, fetchSize={3}, flags={4}",
new Object[]{queries.length, batchHandler, maxRows, fetchSize, flags});
}
flags = updateQueryMode(flags);
boolean describeOnly = (QUERY_DESCRIBE_ONLY & flags) != 0;
// Check parameters and resolve OIDs.
if (!describeOnly) {
for (ParameterList parameterList : parameterLists) {
if (parameterList != null) {
((V3ParameterList) parameterList).checkAllParametersSet();
}
}
}
boolean autosave = false;
ResultHandler handler = batchHandler;
try {
handler = sendQueryPreamble(batchHandler, flags);
autosave = sendAutomaticSavepoint(queries[0], flags);
estimatedReceiveBufferBytes = 0;
for (int i = 0; i < queries.length; i++) {
Query query = queries[i];
V3ParameterList parameters = (V3ParameterList) parameterLists[i];
if (parameters == null) {
parameters = SimpleQuery.NO_PARAMETERS;
}
sendQuery(query, parameters, maxRows, fetchSize, flags, handler, batchHandler, adaptiveFetch);
if (handler.getException() != null) {
break;
}
}
if (handler.getException() == null) {
if ((flags & QueryExecutor.QUERY_EXECUTE_AS_SIMPLE) != 0) {
// Sync message is not required for 'Q' execution as 'Q' ends with ReadyForQuery message
// on its own
} else {
sendSync();
}
processResults(handler, flags, adaptiveFetch);
estimatedReceiveBufferBytes = 0;
}
} catch (IOException e) {
abort();
handler.handleError(
new PSQLException(GT.tr("An I/O error occurred while sending to the backend."),
PSQLState.CONNECTION_FAILURE, e));
}
try {
handler.handleCompletion();
if (cleanupSavePoints) {
releaseSavePoint(autosave, flags);
}
} catch (SQLException e) {
rollbackIfRequired(autosave, e);
}
}
}
我们这里对上面两个函数简化一下,如下:
- sendAutomaticSavepoint
- sendQuery(query)
- if(cleanupSavePoints) releaseSavePoint
- 异常 rollbackIfRequired
假设这里启用autosave,第一步,如下:
private boolean sendAutomaticSavepoint(Query query, int flags) throws IOException {
if (((flags & QueryExecutor.QUERY_SUPPRESS_BEGIN) == 0
|| getTransactionState() == TransactionState.OPEN)
&& query != restoreToAutoSave
&& !"COMMIT".equalsIgnoreCase(query.getNativeSql())
&& getAutoSave() != AutoSave.NEVER
// If query has no resulting fields, it cannot fail with 'cached plan must not change result type'
// thus no need to set a savepoint before such query
&& (getAutoSave() == AutoSave.ALWAYS
// If CompositeQuery is observed, just assume it might fail and set the savepoint
|| !(query instanceof SimpleQuery)
|| ((SimpleQuery) query).getFields() != null)) {
/*
create a different SAVEPOINT the first time so that all subsequent SAVEPOINTS can be released
easily. There have been reports of server resources running out if there are too many
SAVEPOINTS.
*/
sendOneQuery(autoSaveQuery, SimpleQuery.NO_PARAMETERS, 1, 0,
QUERY_NO_RESULTS | QUERY_NO_METADATA
// PostgreSQL does not support bind, exec, simple, sync message flow,
// so we force autosavepoint to use simple if the main query is using simple
| QUERY_EXECUTE_AS_SIMPLE);
return true;
}
return false;
}
如上autoSaveQuery是:
private final SimpleQuery autoSaveQuery =
new SimpleQuery(
new NativeQuery("SAVEPOINT PGJDBC_AUTOSAVE", null, false, SqlCommand.BLANK),
null, false);
第二步:就是执行query
第三步:如果这里cleanupSavepoints = true,那么如下:
private void releaseSavePoint(boolean autosave, int flags) throws SQLException {
if ( autosave
&& getAutoSave() == AutoSave.ALWAYS
&& getTransactionState() == TransactionState.OPEN) {
try {
sendOneQuery(releaseAutoSave, SimpleQuery.NO_PARAMETERS, 1, 0,
QUERY_NO_RESULTS | QUERY_NO_METADATA
| QUERY_EXECUTE_AS_SIMPLE);
} catch (IOException ex) {
throw new PSQLException(GT.tr("Error releasing savepoint"), PSQLState.IO_ERROR);
}
}
}
如上releaseAutoSave是:
private final SimpleQuery releaseAutoSave =
new SimpleQuery(
new NativeQuery("RELEASE SAVEPOINT PGJDBC_AUTOSAVE", null, false, SqlCommand.BLANK),
null, false);
第四步:这里通常就是上面query执行失败的情况,如下:
private void rollbackIfRequired(boolean autosave, SQLException e) throws SQLException {
if (autosave
&& getTransactionState() == TransactionState.FAILED
&& (getAutoSave() == AutoSave.ALWAYS || willHealOnRetry(e))) {
try {
// ROLLBACK and AUTOSAVE are executed as simple always to overcome "statement no longer exists S_xx"
execute(restoreToAutoSave, SimpleQuery.NO_PARAMETERS, new ResultHandlerDelegate(null),
1, 0, QUERY_NO_RESULTS | QUERY_NO_METADATA | QUERY_EXECUTE_AS_SIMPLE);
} catch (SQLException e2) {
// That's O(N), sorry
e.setNextException(e2);
}
}
throw e;
}
如上restoreToAutoSave是:
/*
In autosave mode we use this query to roll back errored transactions
*/
private final SimpleQuery restoreToAutoSave =
new SimpleQuery(
new NativeQuery("ROLLBACK TO SAVEPOINT PGJDBC_AUTOSAVE", null, false, SqlCommand.BLANK),
null, false);
}
看到这里,其整个流程上 内部实现和上面的示例一 一模一样!
psql ON_ERROR_ROLLBACK
我们这里直接调试一下 示例二,如下:
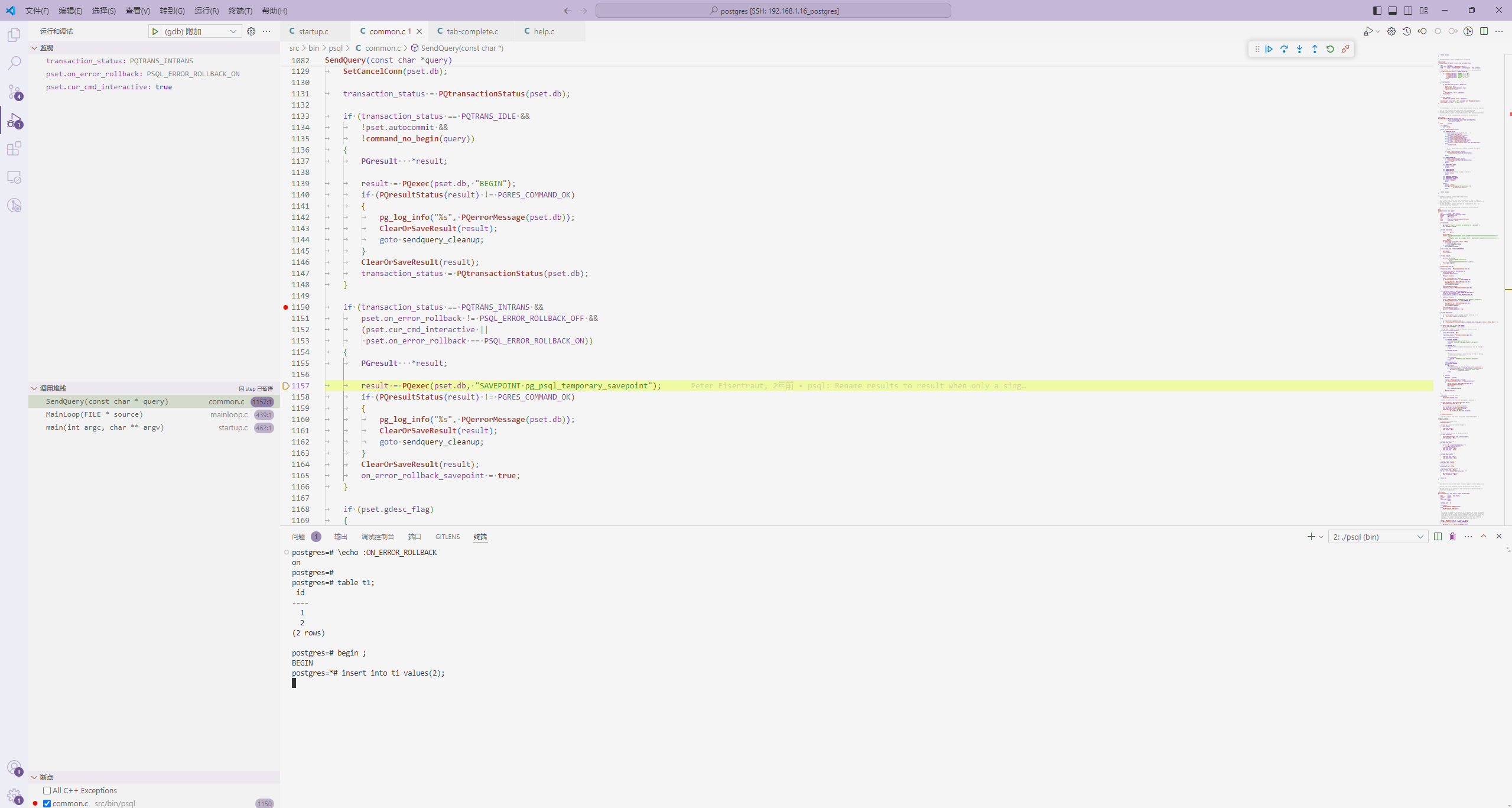
然后开始执行这个query,如下:
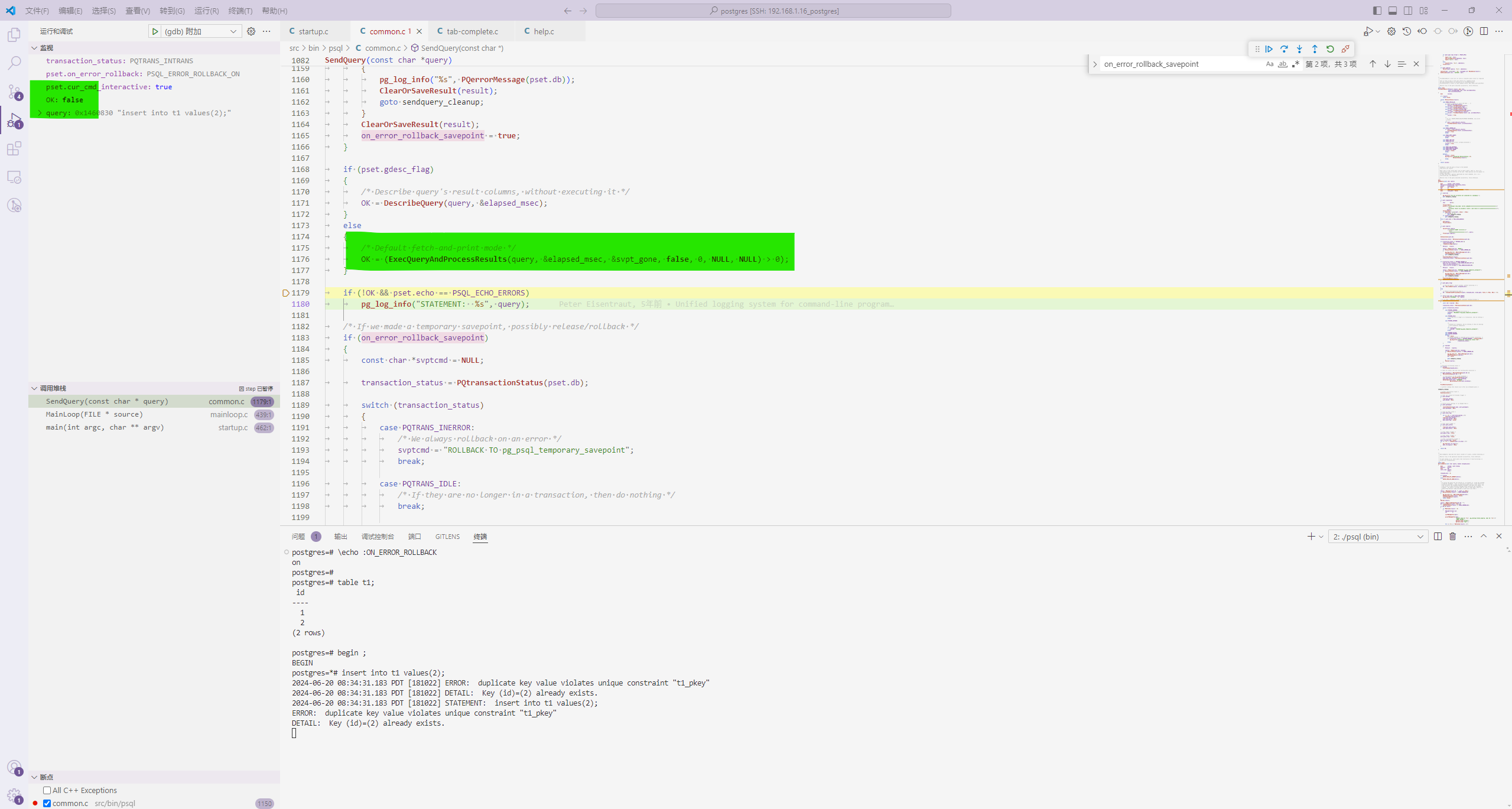
然后看一下接下来的逻辑处理,如下:
// src/bin/psql/common.c
...
/* If we made a temporary savepoint, possibly release/rollback */
if (on_error_rollback_savepoint)
{
const char *svptcmd = NULL;
transaction_status = PQtransactionStatus(pset.db);
switch (transaction_status)
{
case PQTRANS_INERROR:
/* We always rollback on an error */
svptcmd = "ROLLBACK TO pg_psql_temporary_savepoint";
break;
case PQTRANS_IDLE:
/* If they are no longer in a transaction, then do nothing */
break;
case PQTRANS_INTRANS:
/*
* Release our savepoint, but do nothing if they are messing
* with savepoints themselves
*/
if (!svpt_gone)
svptcmd = "RELEASE pg_psql_temporary_savepoint";
break;
case PQTRANS_ACTIVE:
case PQTRANS_UNKNOWN:
default:
OK = false;
/* PQTRANS_UNKNOWN is expected given a broken connection. */
if (transaction_status != PQTRANS_UNKNOWN || ConnectionUp())
pg_log_error("unexpected transaction status (%d)",
transaction_status);
break;
}
if (svptcmd)
{
PGresult *svptres;
svptres = PQexec(pset.db, svptcmd);
if (PQresultStatus(svptres) != PGRES_COMMAND_OK)
{
pg_log_info("%s", PQerrorMessage(pset.db));
ClearOrSaveResult(svptres);
OK = false;
goto sendquery_cleanup;
}
PQclear(svptres);
}
}
...
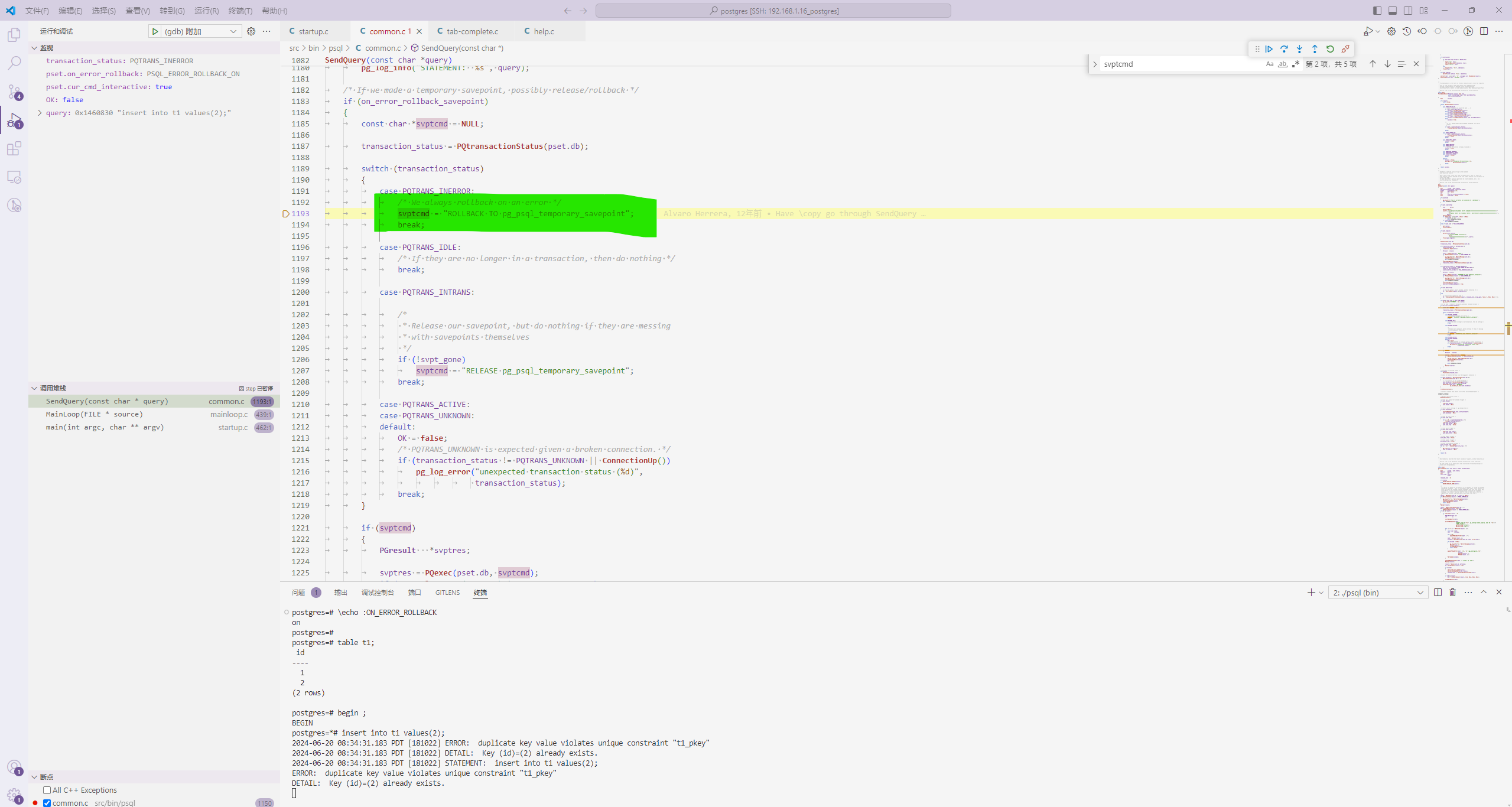
上面是失败的情形,下面来看一个成功的例子!
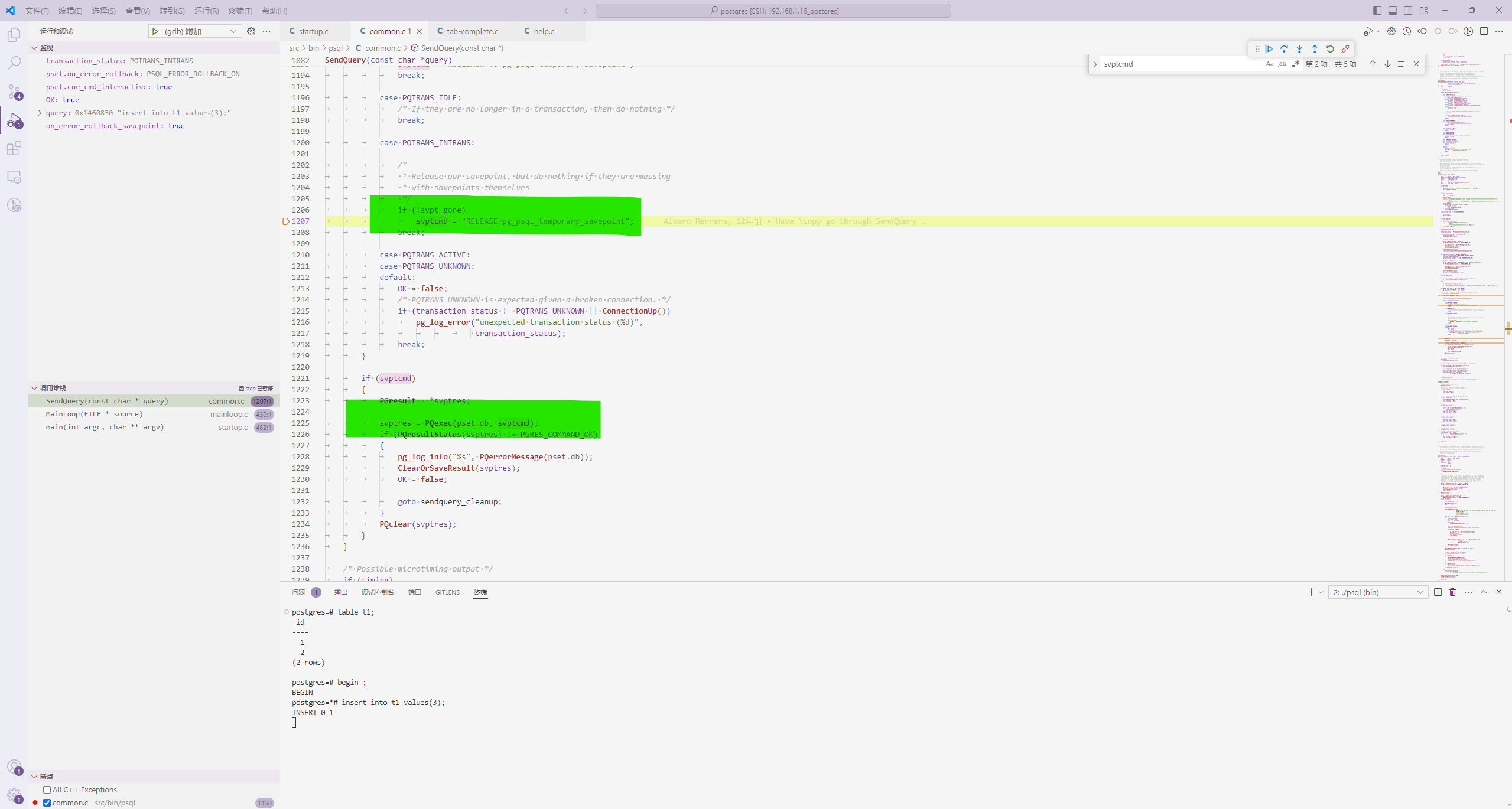
自然这里最终就是成功的,如下:
postgres=# table t1;
id
----
1
2
(2 rows)
postgres=# begin ;
BEGIN
postgres=*# insert into t1 values(3);
INSERT 0 1
postgres=*# commit;
COMMIT
postgres=# table t1;
id
----
1
2
3
(3 rows)
postgres=#
注:无论是驱动pgJDBC还是连接工具psql,如上的 auto savepoint的行为都可以理解为 client 一侧的行为。那么我们是否可以在 server 一端实现类似的功能呢?
这个问题 本人后面另开一篇新的博客进行探讨!