一、监督or非监督
监督学习(Supervised Learning):训练集有标记信息(Y),学习方式有分类和回归
无监督学习(Unsupervised Learning):训练集没有标记信息,学习方式有聚类和降维
强化学习(Reinforcement Learning):有延迟和稀疏的反馈标签的学习方式
二、分类or回归
分类:结果是几个离散类型,比如猫狗二分类,手写数字10分类
回归:结果是连续值,比如房价预测,最后的结果可以是是float数字
三、如何购买苹果
1、监督学中,分类问题,最后是买 or 不买,二分类
2、这是历史数据,我们把尺寸、重量等称为特征(x);买或者不买为标签(y)

四、训练 or 预测
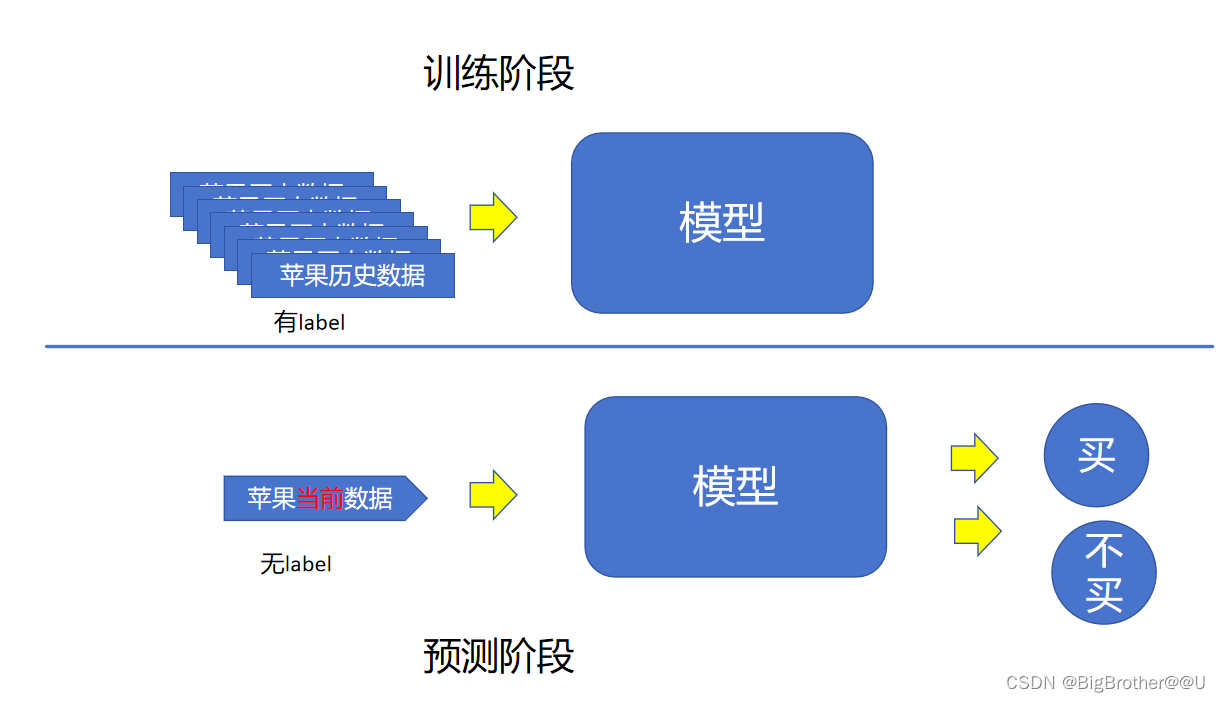 1、训练阶段:通过苹果的历史数据,把苹果的特征(x)和标签(y)“计算”为模型
1、训练阶段:通过苹果的历史数据,把苹果的特征(x)和标签(y)“计算”为模型
2、预测阶段:把当前苹果的特征(x)输入到模型;得到结果(y_hat 不是y,只是个预测值) 买或者不买
五、线性模型如何训练(理解)
大家可能会好奇,模型里面有什么?模型里面有几个东西,比较重要的就是参数
下面从最简单的监督模式–回归问题中–线性回归模型引入如何训练
下图是波士顿房价历史数据(训练数据,包含特征和标签两部分),通过训练可以得到一个模型

1、可能特征和标签的关系是 :price = warea · area + wage · age + b 其中 w是权重 ,b是偏置,这两个都是参数
2、更加简洁一些:y = w1x1 +w2x2 + b
训练就是通过x和y确定w和b,预测就是通过w,x和b计算y
下面开始手写训练:
1、假设b=0
2、w1*50 + w2*20 + 0 = 100 ;方程(1)
w1*60 + w2*10 + 0 = 200 ;方程(2)
方程(2)*2 - 方程(1)可以得到w1约等于4.3,最后可以得出w2
3、这个通过x和y得出w和b的过程叫训练
4、上面是最简单的线性模型,只是让大家理解,实际过程比这个复杂
六、损失函数(基本感受)
如何衡量一个模型中参数好坏?
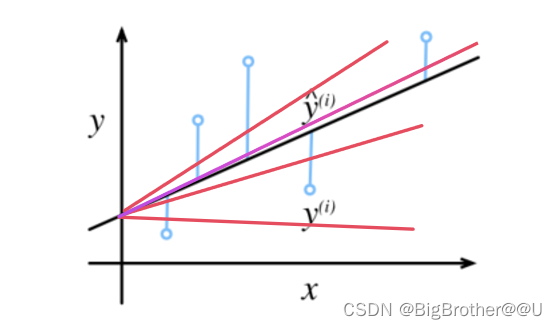
上图中蓝色的点表示5个样本点,4条红线表示4种预测的线性关系,哪个更好呢?
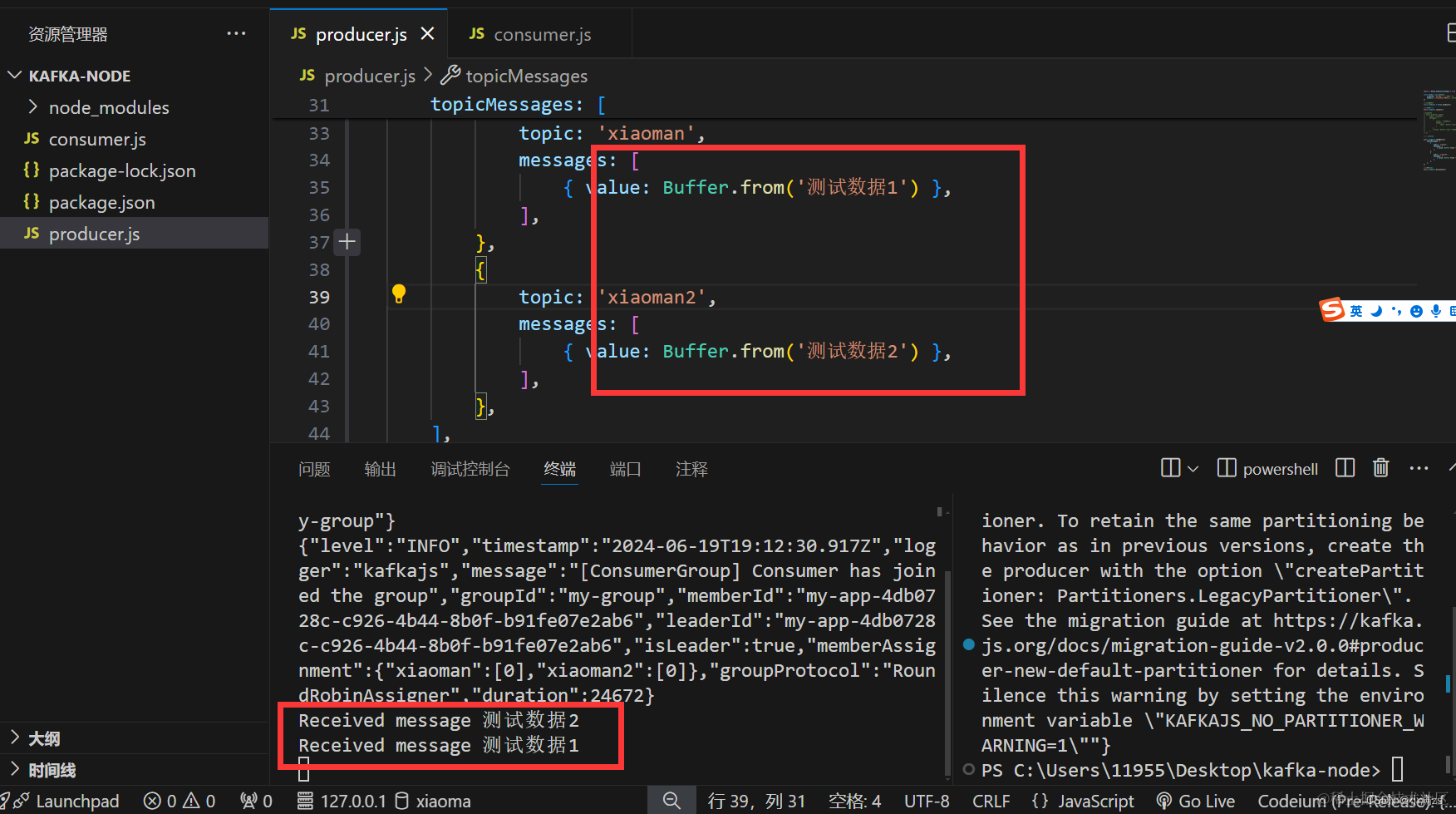
损失函数:计算预测值与实际label的差距
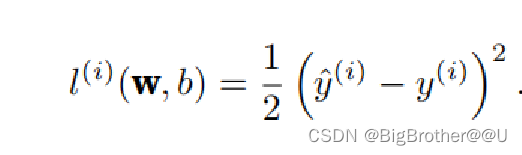
第i个点的损失为预测值y_hat - y的差的平方再除以2
5个点合起来的loss为:n=5 (看不懂公式没有关系只需知道把5个误差进行平均就行)
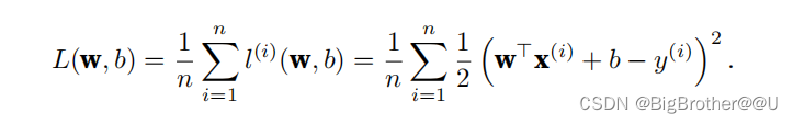 这样可以得出某个红色的线是4条种最优的,但不是最好的,因为仅仅是在这四个可能性种最好
这样可以得出某个红色的线是4条种最优的,但不是最好的,因为仅仅是在这四个可能性种最好
七、损失函数(进阶应用)
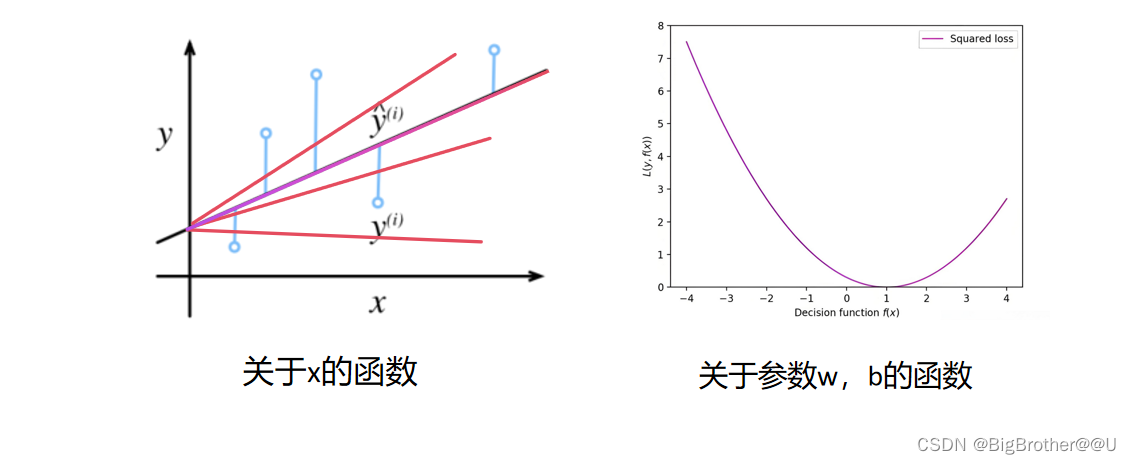
左边图形每一个红线的w和b是固定的,能不能让w和b是变量,得到和y的差距的损失的关系,这样就变为了右图,左边每一条红线在右侧都是一个点。y轴是y_hat和y之间的误差,x轴是w,b。(f(x)=wx+b)。
这样我们求出y轴为0点时,w和b就是当前最好的参数。
找到0点的两种办法,(1)对损失函数求导,导数=0的时候就是最低点(2)梯度下降方法
第一种办法在简单线性模型有效,高阶的时候非常困难。比如下面

梯度下降就像在山上往下走,一步步找到最优点
八、梯度下降
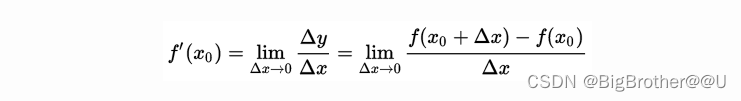 先从导数的定义说起,导数反应的时y的变换和x变换的比,也就是瞬时的变化比
先从导数的定义说起,导数反应的时y的变换和x变换的比,也就是瞬时的变化比
 上图是导数的定义,p0点的导数反应该点的变化情况。Δy为正,Δx为正。该点导数为正。
上图是导数的定义,p0点的导数反应该点的变化情况。Δy为正,Δx为正。该点导数为正。
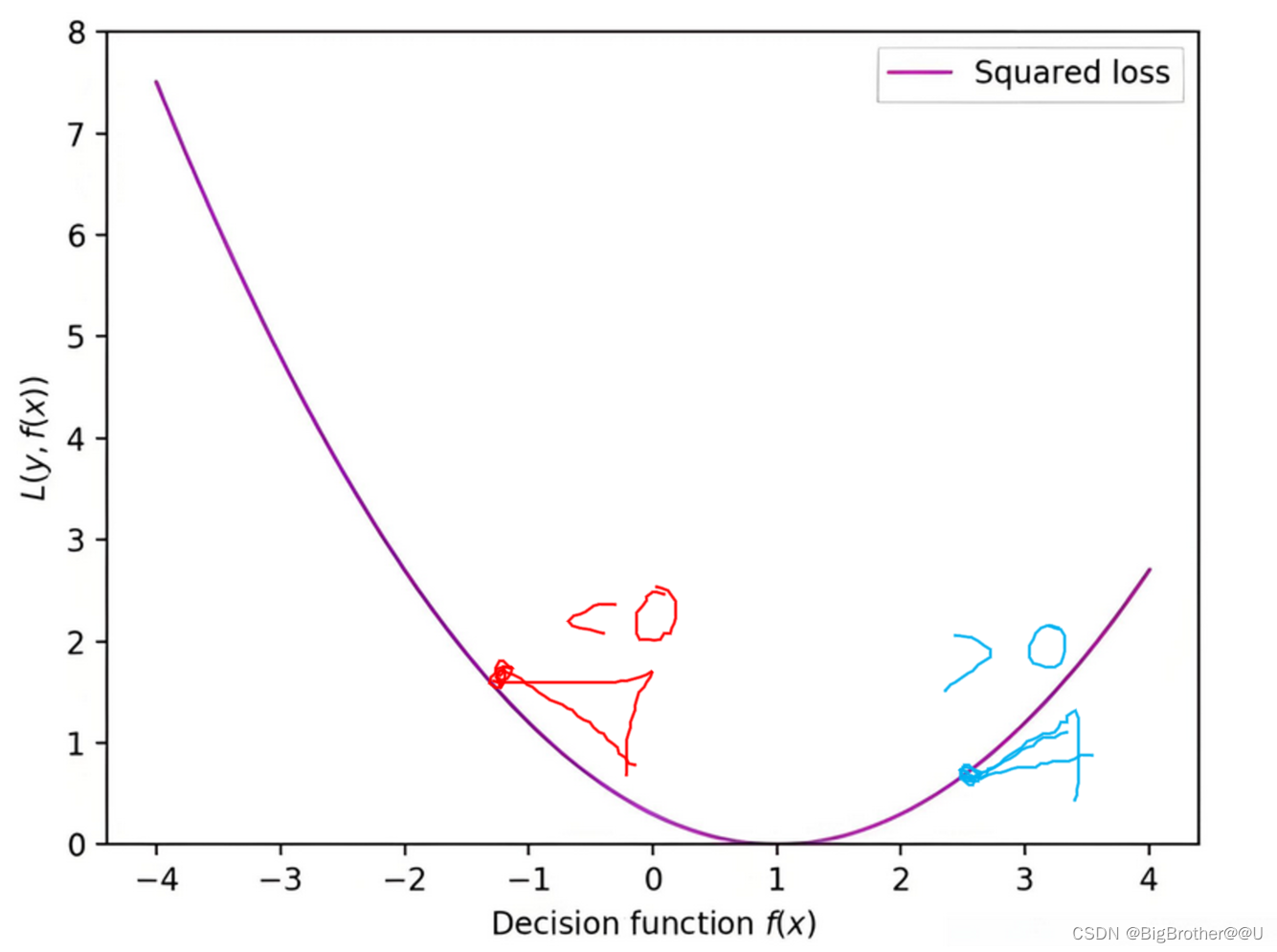
红色三角表示该点导数为负,蓝色三角表示该点导数为负。
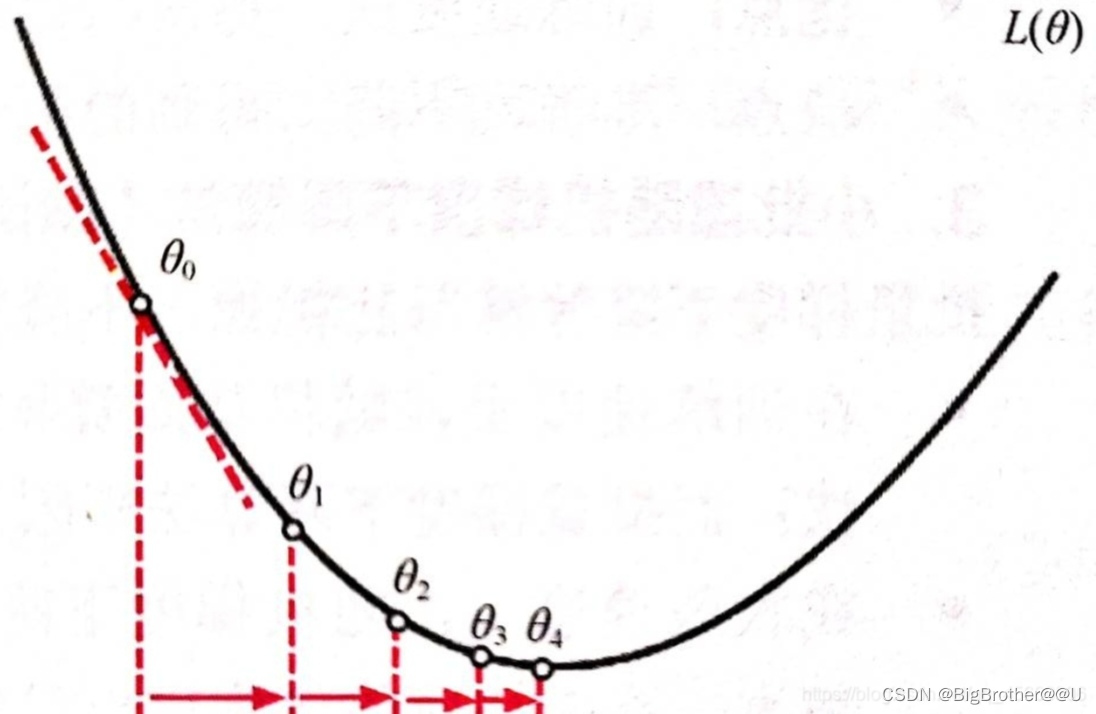
比如当前在θ0处,θ是w和b的函数,此时损失比较大。需要让损失变小,就像从山上往下走一样。从θ0变为θ1,慢慢往下走。最后会边到θ4附近。这样损失就比较小了。找到了比较好的w和b。
我们再看一下θ0如何变为θ1的

θ1=θ0-学习率*θ0处的导数
防止下降太快学习率是个0到1之间的小数