Rich Human Feedback for Text-to-Image Generation斩获CVPR2024最佳论文!受大模型中的RLHF技术启发,团队用人类反馈来改进Stable Diffusion等文生图模型。这项研究来自UCSD、谷歌等。
在本文中,作者通过标记不可信或与文本不对齐的图像区域,以及注释文本提示中的哪些单词在图像上被歪曲或丢失来丰富反馈信号。 在 18K 生成图像 (RichHF18K) 上收集如此丰富的人类反馈,并训练多模态转换器来自动预测丰富的反馈。 实验结果表明,可以利用预测的丰富人类反馈来改进图像生成,例如,通过选择高质量的训练数据来微调和改进生成模型,或者通过使用预测的热图创建mas来修复有问题的区域。 值得注意的是,除了用于生成收集人类反馈数据的图像(稳定扩散变体)之外,这些改进还推广到了模型(Muse)。

MOTIVATION
- many generated images still suffer from issues such as artifacts/implausibility, misalignment with text descriptions, and low aesthetic quality.(伪影和错位问题)
- Inspired by the success of Reinforcement Learning with Human Feedback (RLHF) for large language models, prior works collected human-provided scores as feedback on generated images and trained a reward model to improve the T2I generation.
- There has been much recent work on evaluation of text-to-image models along many dimensions,but the focus of their work is artifact region only.
CONTRIBUTION
- 这是第一个关于生成图像的丰富人类反馈数据集(RichHF-18K),包括对18K张Pick-a-Pic图像的细粒度评分、不真实/错位的图像区域和不一致的关键词。
- 设计了一个多模态Transformer模型(RAHF),用于预测生成图像上的丰富反馈,并展示这些预测与测试集上的人类注释高度相关。
- 进一步展示了通过RAHF预测的丰富人类反馈的有效性,可用于改进图像生成,例如
- (i) 使用预测的热图作为掩模修复问题图像区域,
- (ii) 通过使用预测的评分来帮助微调图像生成模型(例如Muse [6]),例如选择/过滤微调数据或作为奖励指导。我们表明在这两种情况下,我们获得比原始模型更好的图像。
- 在Muse模型上的改进表明,我们的RAHF模型具有良好的泛化能力,与训练集中生成图像的模型不同。
METHODS
Collecting rich human feedback
数据收集过程
-
数据集内容:RichHF-18K数据集包括两种热图(人工/不合理和不一致)、四种细粒度评分(合理性、对齐度、美学和总体评分),以及一个文本序列(不一致的关键词)。(5-point Likert scale)
-
标注者任务:标注者首先检查生成的图像并阅读用于生成图像的文本提示。然后,他们在图像上标记点,以指示与文本提示相关的不合理/人工或不一致的区域。
-
有效半径:每个标记点都有一个“有效半径”(图像高度的1/20),围绕标记点形成一个想象的圆盘区域。这样,即使使用较少的点,也能覆盖图像中有缺陷的区域。

-
数据标注细节(在附录中提供)
- Image artifacts/implausibility definitions
包括对扭曲的人/动物身体/面部、物体、文本以及不真实/无意义的表现形式的定义。
- Image artifacts/implausibility definitions
-
Text-image misalignment definitions and what-to-do
为标注者提供了详尽的操作指导,包括当文本提示中的元素在图像中缺失、属性错误、动作错误、数量错误、位置错误或其他不一致性时的处理方法。
反馈整合
- 多标注者:为了提高收集到的人类反馈的可靠性,每个图像-文本对由三名标注者进行标注。
- 评分整合(score):对于评分,简单地将多个标注者对一个图像的评分平均,以获得最终评分。
- 关键词整合(misaligned keyword annotations):对于不一致关键词的标注,执行多数投票,使用最频繁的标签作为关键词的最终指标序列。
- 点标注整合(point annotations):首先将点标注转换为每个标注的热图,然后将每个点转换为热图上的圆盘区域,并计算所有标注者的平均热图。明显不合理的区域可能会被所有标注者标注,并在最终平均热图中具有较高的值。
数据集RichHF-18K
- 从 Pick-a-Pic 数据集中选择图像文本对的子集进行数据注释,选择大部分数据集为照片级真实感图像
- 类别平衡:为了确保图像类别的平衡,使用了PaLI视觉问题回答(VQA)模型来从Pick-a-Pic数据样本中提取基本特征。对每对图像-文本,提出了两个问题,根据PaLI的答案,从Pick-a-Pic中采样得到17K图像-文本对,形成了多样化的子集。
- 图像是否为照片写实风格(Is the image photorealistic)?
- 最能描述图像的类别是什么?从“人类”、“动物”、“物体”、“室内场景”、“室外场景”中选择。(Which category best describes the image? Choose one in ‘human’, ‘animal’, ‘object’, ‘indoor scene’, ‘outdoor scene’)
数据统计和标注者一致性分析
-
分数标准化:使用公式 s norm = s − s min s max − s min \text{s}_{\text{norm}} = \frac{s - s_{\text{min}}}{s_{\text{max}} - s_{\text{min}}} snorm=smax−smins−smin(其中 s max = 5 s_{\text{max}} = 5 smax=5, s min = 1 s_{\text{min}} = 1 smin=1对分数进行标准化,使分数范围在[0, 1]内。
-
分数分布:分数的分布类似于高斯分布,合理性和文本-图像对齐分数的1.0得分比例略高。

-
样本平衡:收集的分数分布确保了训练良好奖励模型的负面和正面样本数量合理。
-
标注者一致性:为了分析标注者对图像-文本对的评分一致性,计算分数之间的最大差异: maxdiff = max ( scores ) − min ( scores ) \text{maxdiff} = \max(\text{scores}) - \min(\text{scores}) maxdiff=max(scores)−min(scores),其中分数是图像-文本对的三个评分标签。大约25%的样本有完美的标注者一致性,大约85%的样本有良好的标注者一致性(在标准化后maxdiff小于等于0.25或5点Likert量表上的1)。

Predicting rich human feedback
模型架构如图所示,模型基于Vision Transformer(ViT)和T5X模型,灵感来自Spotlight模型架构,但对模型和预训练数据集进行了修改,以更好地适应任务需求。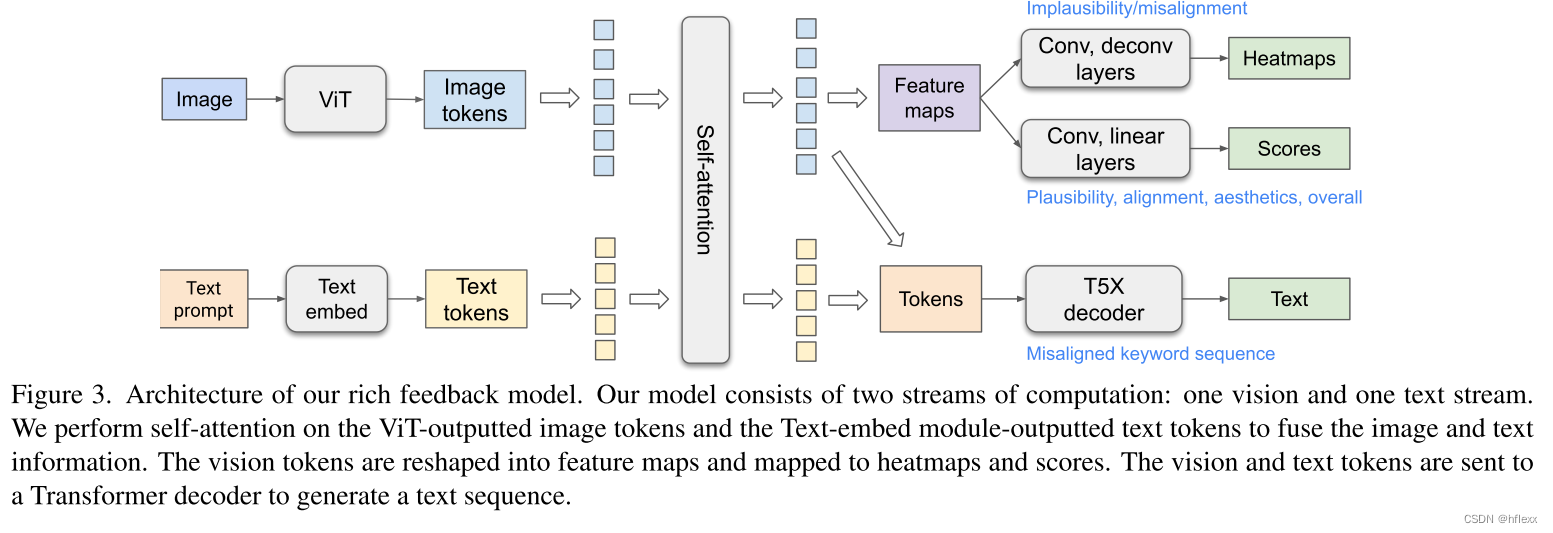
自注意力模块的使用
- 自注意力模块用于处理连接(concatenated)的图像标记(tokens)和文本标记,以实现双向信息传播,这对于任务
- 文本信息传播到图像标记,帮助模型评估文本与图像的不一致性(text misalignment),并预测热图(heatmaps)(点标记)。
- 视觉信息传播到文本标记,增强文本编码对视觉内容的感知,这对于解码文本不一致序列特别重要。
模型结构
-
输入处理
- ViT编码:Vision Transformer(ViT)接收生成的图像作为输入,并将其输出为高级别的图像标记(tokens),这些标记是对图像的高级表示。
- 文本嵌入:文本提示(prompt)被分割成标记(tokens),并嵌入(embedded)到高维向量空间中,形成密集的向量表示。
- 图像标记和嵌入文本标记由 T5X 中的 Transformer 自注意力编码器连接和编码。(在多模态任务中,如文本到图像生成,T5X decoder 可以接收来自图像的编码表示,并生成描述图像的文本)
-
预测器与输出:use three kinds of predictors to predict different outputs
模型包含三种类型的预测头:-
heatmap预测:图像标记被重塑(reshaped)成特征图(feature map)。特征图通过卷积层和反卷积层进行处理,并通过Sigmoid激活函数来输出不合理性(implausibility)和不一致性(misalignment)热图。热图预测器用于生成图像中不合理或不一致区域的热图。
-
score预测:特征图进一步通过卷积层和线性层处理,并通过Sigmoid激活函数生成细粒度的分数(scalars),作为图像的评分。分数预测器用于预测图像的合理性、美学等分数。
-
keyword misalignment sequence预测:使用生成图像的原始文本提示作为模型的文本输入。修改后的提示(特殊后缀“_0”标记不一致的标记)作为T5Xdecoder的预测目标。例如,如果图像中有一只黑色的猫,而文本提示是“a yellow cat”,则修改后的提示可能是“a yellow_0 cat”,这里的“0”表示“yellow”与图像不一致(预测结果).文本预测器用于预测文本中与图像不一致的关键词序列。
-
-
模型变体
- 多头(Multi-head)方法:这是一种直接的方式,用于预测多个热图和分数,通过为每种分数和热图类型使用单独的预测头(prediction head)来实现。这种方法需要总共七个预测头,每种类型一个.
- 增强提示(Augmented prompt)方法:即总共三个预测头,分别用于heatmap、score和keyword misalignment sequence。为了告知模型具体的热图或分数类型,通过在提示中增加输出类型信息来进行增强。具体来说,对于每个样本的特定任务,将任务字符串(例如,“implausibility heatmap”)添加到提示的前面,并使用相应的标签作为训练目标。在推理(inference)阶段,通过在提示中增加相应的任务字符串,单个热图头可以预测不同的热图,单个分数头可以预测不同的分数。实验表明,增强提示方法可以创建特定于任务的视觉特征图和文本编码,这在某些任务中表现得显著更好。
-
用于不同任务的损失函数
- 热图预测的损失:使用像素级均方误差(Mean Squared Error, MSE)损失函数。这种损失函数计算模型预测的热图与真实热图之间的差异,对每个像素的误差进行平方和求平均,从而得到总的误差。
- 分数预测的损失:同样使用MSE损失函数。这里,损失计算的是模型预测的分数与实际分数之间的差异。
- 不一致序列预测的损失:使用教师强制(Teacher-Forcing)交叉熵(Cross-Entropy)损失函数。交叉熵损失衡量的是模型预测的序列与真实序列之间的差异,而教师强制是一种在序列生成任务中常用的技术,它在训练过程中使用真实的输出作为下一个时间步的输入,以提高学习效率。
Experiments
Experimental setup
评估指标
- SCORE预测任务:
- PLCC(皮尔逊线性相关系数):衡量预测分数与人类注释之间的线性相关性。
- SRCC(斯皮尔曼等级相关系数):评估预测分数和实际分数之间的单调关系。
- HEATMAP预测任务:
- MSE(均方误差):用于评估所有样本的预测,包括那些真实热图为空的样本(例如,没有人工/不合理的图像)。
- 标准显著性热图评估指标:对于非空真实热图的样本,报告NSS、KLD、AUC-Judd、SIM、CC等指标。这些指标通常用于评估显著性图(saliency heatmap)的质量,本研究中某些任务可能存在空的真实热图,因此需要适应性修改。
- NSS(Normalized Scanpath Saliency):衡量预测显著性图与实际人类注视路径之间的相关性。评估显著性图的质量,值越高越好。
- KLD(Kullback-Leibler Divergence):衡量预测热图与真实热图之间的差异。 评估预测热图与真实热图的分布差异,值越低越好。
- AUC-Judd(Area Under Curve - Judd): 测量预测热图在二值分类任务中的表现。评估显著性图的检测性能,值越高越好。
- SIM(Similarity):衡量预测热图与真实热图的相似度。评估两个热图之间的相似性,值越高越好。
- CC(Correlation Coefficient):衡量预测热图与真实热图之间的线性相关性。评估热图之间的相关性,值越高越好。
- 不一致关键词序列预测:精确度、召回率和F1分数:计算所有样本中不一致关键词的精确度、召回率和F1分数,这些指标衡量模型在识别不一致关键词方面的准确性。
baseline
-
ResNet-50模型:
使用两个微调的ResNet-50模型作为基线,使用多个全连接层和反卷积头分别预测分数和热图。 -
PickScore模型:
使用现成的模型来计算分数,并针对四种真实分数计算指标。 -
CLIP模型:
- 现成的CLIP模型用以计算图像和文本嵌入之间的余弦相似度,用于文本-图像对齐度量。
- 微调CLIP模型以使用训练数据集预测四种类型的分数。
-
CLIP梯度图:
用作不一致热图预测的基线,提供基于梯度的图像区域指示,这些区域可能与文本提示不一致。(CLIP梯度图表示图像中每个像素对文本描述的匹配度影响程度。梯度值越高的区域表示这些区域对文本描述的影响越大,从而在视觉上更能吸引注意力。)
实验结果
Quantitative analysis
作者展示了他们模型在四个细粒度分数(合理性、对齐度、美学和总体评分)、不可信热图、不一致热图和不一致关键词序列预测方面的预测结果。
- GT = 0:这指的是空的不可信热图(empty implausibility heatmap),即在真实情况(ground truth)中不存在任何人工或不合理的元素。在995个测试样本中,有69个样本的不可信热图为空。
- GT > 0:这指的是存在人工或不合理元素的热图,即在真实情况中确实存在一些问题,需要模型检测并突出显示。




- 在表格1和3中,所提出的模型的两个变体在所有任务上都显著优于ResNet-50模型(或在文本-图像对齐分数上优于CLIP模型)。
- 在表格2中,多头版本的模型在某些任务上表现不如ResNet-50,但增强提示版本的模型表现优于ResNet-50。
- 多头版本的问题:在没有在提示中增强预测任务的情况下,所有七个预测任务使用相同的提示,导致特征图和文本标记相同,可能难以在这些任务之间找到良好的折衷,导致某些任务(如人工/不可信热图)的性能变差。
- 增强提示的优势:通过在提示中增强预测任务,可以为特定任务调整特征图和文本标记,从而获得更好的结果。
- 不一致热图预测通常比不可信热图预测的结果要差,可能是因为不一致区域定义不够明确,注释可能因此更加嘈杂。
Qualitative examples
不合理热图的一些示例预测(图5),其中模型识别了具有伪影/不合理的区域。
以及对于未对准热图(图 6),模型识别了不对应的对象提示。

示例图像的真是分数和预测分数

Learning from rich human feedback
为了确保 RAHF 模型的好处能够泛化到生成模型系列中,主要使用 Muse 作为的目标模型来改进,它基于masked transformer architecture,因此与 RichHF 中的稳定扩散模型变体不一样。
使用预测分数微调生成模型(Finetuning generative models with predicted scores)
使用预训练的Muse模型为12,564个提示生成图像。为每张图像预测RAHF分数,并选择每个提示中分数高于固定阈值的图像作为微调数据集。使用选定的图像数据集对Muse模型进行微调。通过新提示生成图像,并让标注者对原始Muse和微调后的Muse图像进行合理性比较,结果显示微调后的Muse模型生成的图像具有显著更少的人工或不合理元素。

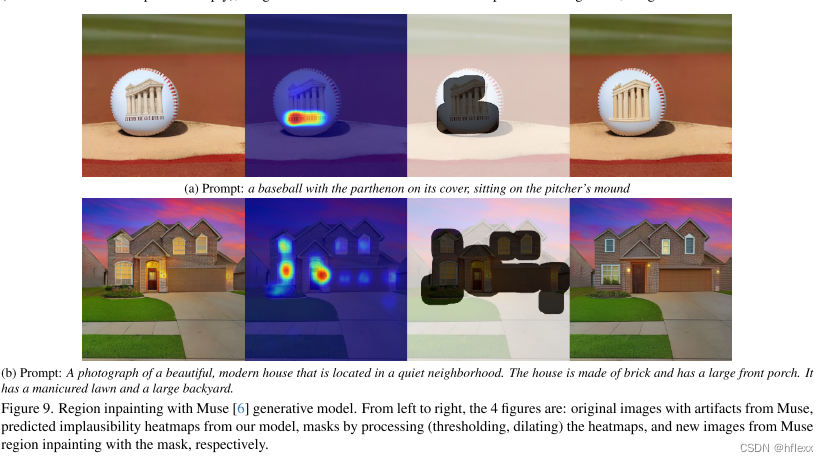
使用预测的热图和分数进行区域修复(Region inpainting with predicted heatmaps and scores)
对于每个图像,我们首先预测不可信热图(implausibility heatmaps),然后通过处理热图(使用阈值thresholding和膨胀dilating)创建mask。 Muse 修复应用在mask区域内,以生成与文本提示匹配的新图像。 生成多个图像,并根据我们的 RAHF 预测的最高合理性分数选择最终图像。