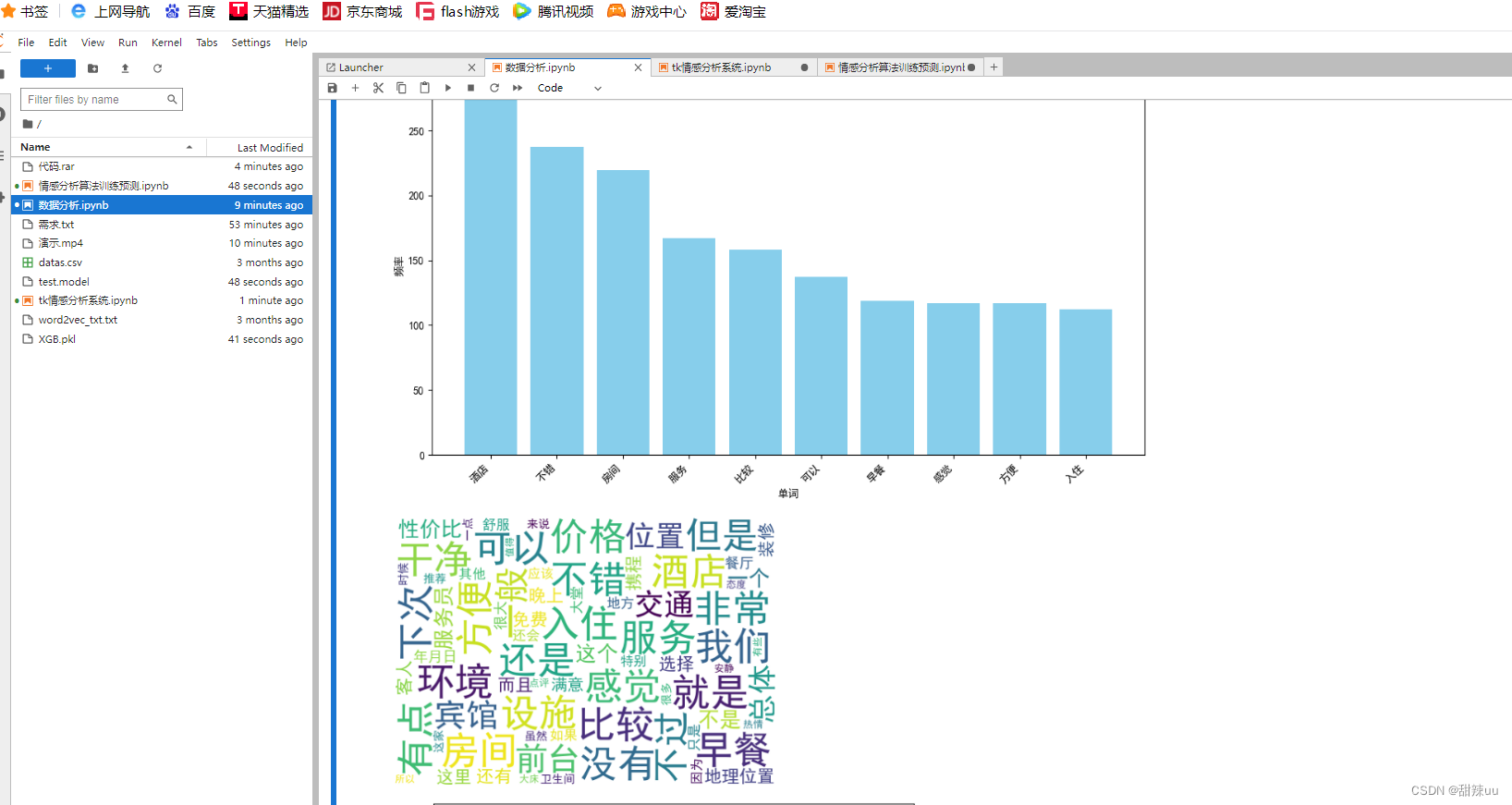
文章目录
- GPT-1
- GPT-2
- GPT-3
- 从 GPT-3 到 InstructGPT
- GPT-3.5、Codex 和 ChatGPT
- GPT-4
GPT-1
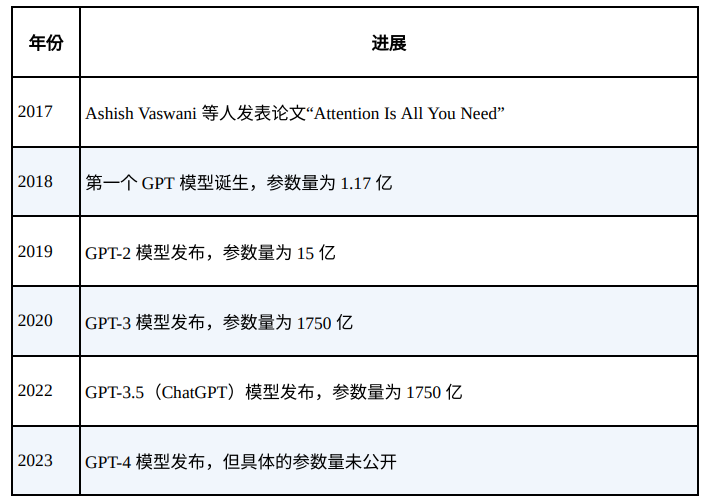
2018 年年中,就在 Transformer 架构诞生⼀年后,OpenAI 发表了⼀篇题 为“Improving Language Understanding by Generative Pre-Training”的论文,作者是 Alec Radford 等⼈。这篇论文介绍了 GPT,也被称为 GPT-1。在 GPT-1 出现之前,构建高性能 NLP 神经网络的常用方法是利用监督学习。这种学习技术使用大量的手动标记数据。以情感分析任务为例,目标是对给定的文本进行分类,判断其情感是积极的还是消极的。⼀种常见的策略是收集数千个手动标记的文本示例来构建有效的分类模型。然而,这需要有大量标记良好的监督数据。这⼀需求限制了监督学习的性能,因为要生成这样的数据集,难度很大且成本高昂。接下来回顾 OpenAI 的 GPT 模型从 GPT-1 到 GPT-4 的演变历程。
在论文中,GPT-1 的作者提出了⼀种新的学习过程,其中引入了无监督的预训练步骤。这个预训练步骤不需要标记数据。相反,他们训练模型来预测下⼀个标记。由于采用了可以并行化的 Transformer 架构,预训练步骤是在大量数据上进行的。对于预训练,GPT-1 模型使用了 BookCorpus 数据集。该数据集包含约 11 000 本未出版图书的文本。BookCorpus 最初由 YukunZhu 等⼈在 2015 年的论文“Aligning Books and Movies: Towards Story-likeVisual Explanations by Watching Movies and Reading Books”中给出,并通过多伦多大学的网页提供。然而,原始数据集的正式版本如今已不能公开访问。
GPT-4 和 ChatGPT 基于⼀种特定的神经网络架构,即 Transformer。Transformer 就像阅读机⼀样,它关注句子或段落的不同部分,以理解其上下文并产生连贯的回答。此外,它还可以理解句子中的单词顺序和上下文意思。这使 Transformer 在语言翻译、问题回答和文本生成等任务中非常有效。
⼈们发现,GPT-1 在各种基本的文本补全任务中是有效的。在无监督学习阶段,该模型学习 BookCorpus 数据集并预测文本中的下⼀个词。然而,GPT-1 是小模型,它无法在不经过微调的情况下执行复杂任务。因此,人们将微调作为第⼆个监督学习步骤,让模型在⼀小部分手动标记的数据上进行微调,从而适应特定的目标任务。比如,在情感分析等分类任务中,可能需要在一小部分手动标记的⽂本示例上重新训练模型,以使其达到不错的准确度。这个过程使模型在初始的预训练阶段习得的参数得到修改,从而更好地适应具体的任务。
尽管规模相对较小,但 GPT-1 在仅用少量手动标记的数据进行微调后,能够出色地完成多个 NLP 任务。GPT-1 的架构包括⼀个解码器(与原始 Transformer 架构中的解码器类似),具有 1.17 亿个参数。作为首个 GPT 模型,它为更强大的模型铺平了道路。后续的 GPT 模型使用更大的数据集和更多的参数,更好地利用了 Transformer 架构的潜力。
GPT-2
2019 年初,OpenAI 提出了 GPT-2。这是 GPT-1 的⼀个扩展版本,其参数量和训练数据集的规模大约是 GPT-1 的 10 倍。这个新版本的参数量为 15亿,训练文本为 40 GB。2019 年 11 月,OpenAI 发布了完整版的 GPT-2 模型。GPT-2 是公开可用的,可以从 Hugging Face 或 GitHub 下载。GPT-2 表明,使用更大的数据集训练更大的语言模型可以提高语言模型的任务处理能力,并使其在许多任务中超越已有模型。它还表明,更大的语言模型能够更好地处理自然语⾔。
GPT-3
2020 年 6 月,OpenAI 发布了 GPT-3。GPT-2 和 GPT-3 之间的主要区别在于模型的大小和用于训练的数据量。GPT-3 比 GPT-2 大得多,它有 1750 亿个参数,这使其能够捕捉更复杂的模式。此外,GPT-3 是在更广泛的数据集上进行训练的。这包括 Common Crawl(它就像互联网档案馆,其中包含来自数十亿个网页的文本)和维基百科。这个训练数据集包括来自网站、书籍和文章的内容,使得 GPT-3 能够更深入地理解语言和上下文。因此,GPT-3在各种语言相关任务中都展示出更强的性能。此外,它在文本生成方面还展示出更强的连贯性和创造力。它甚至能够编写代码片段,如 SQL 查询,并执行其他智能任务。此外,GPT-3 取消了微调步骤,而这在之前的 GPT模型中是必需的。
然而,GPT-3 存在⼀个问题,即最终用户提供的任务与模型在训练过程中所见到的任务不⼀致。我们已经知道,语言模型根据输入文本的上下文来预测下⼀个标记。这个训练过程不⼀定与最终用户希望模型执行的任务⼀致。此外,增大语言模型的规模并不能从根本上使其更好地遵循用户的意图或指令。像 GPT-3 这样的模型是在互联网数据上进行训练的。尽管数据源经过⼀定的筛选,但用于训练模型的数据仍然可能包含虚假信息或有问题的文本,比如涉及种族歧视、性别歧视等。因此,模型有时可能说错话,甚至说出有害的话。2021 年,OpenAI 发布了 GPT-3 模型的新版本,并取名为 InstructGPT。与原始的 GPT-3 基础模型不同,InstructGPT 模型通过强化学习和⼈类反馈进行优化。这意味着 InstructGPT 模型利用反馈来学习和不断改进。这使得模型能够从人类指令中学习,同时使其真实性更大、伤害性更小。
为了说明区别,我们输⼊以下提示词:“解释什么是时间复杂度。”两个模型给出的回答如下所述。
- 标准的 GPT-3 模型给出的回答是:“解释什么是空间复杂度。解释什么是大 O 记法。”
- InstructGPT 模型给出的回答是:“时间复杂度用于衡量算法运行和完成任务所需的时间,通常采用大 O 记法表示。它以操作次数来衡量算法的复杂度。算法的时间复杂度至关重要,因为它决定了算法的效率和对更大输入的扩展能力。”
我们可以看到,对于相同的输入,第⼀个模型无法回答问题(它给出的回答甚至很奇怪),而第⼆个模型可以回答问题。当然,使用标准的 GPT-3模型也能够得到所需的回答,但需要应用特定的提示词设计和优化技术。这种技术被称为提示工程(prompt engineering)。
从 GPT-3 到 InstructGPT
在题为“Training Language Models to Follow Instructions with Human Feedback”的论文中,OpenAI 的欧阳龙等人解释了 InstructGPT 是如何构建的。从 GPT-3 模型到 InstructGPT 模型的训练过程主要有两个阶段:监督微调(supervised fine-tuning,SFT)和通过人类反馈进行强化学习(reinforcement learning from human feedback,RLHF)。每个阶段都会针对前⼀阶段的结果进行微调。也就是说,SFT 阶段接收 GPT-3 模型并返回⼀个新模型。RLHF 阶段接收该模型并返回 InstructGPT 版本。根据 OpenAI 的论文,我们重新绘制了⼀张流程图,如下图所示。

在 SFT 阶段中,原始的 GPT-3 模型通过监督学习进行微调(上图中的步骤 1)。OpenAI 拥有⼀系列由最终用户创建的提示词。首先,从可用的提示词数据集中随机抽样。然后,要求⼀个⼈(称为标注员)编写⼀个示例来演示理想的回答。重复这个过程数千次,以获得⼀个由提示词和相应的理想回答组成的监督训练数据集。最后,使用该数据集微调 GPT-3 模型,以针对用户的提问提供更⼀致的回答。此时得到的模型称为 SFT 模型。
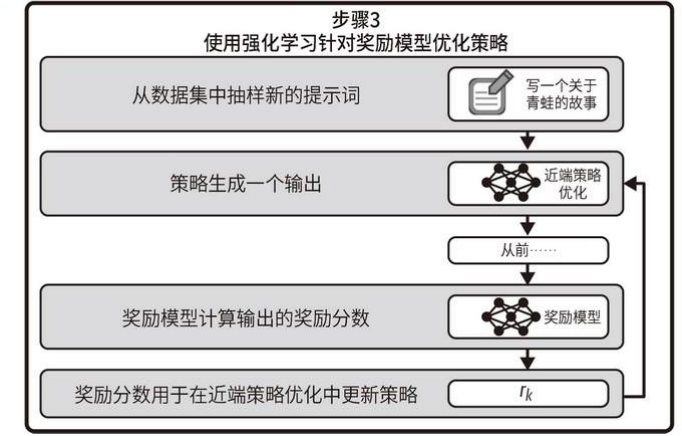
RLHF 阶段分为两个子步骤:首先训练奖励模型(上图中的步骤 2),然后使用奖励模型进行强化学习(上图中的步骤 3)。奖励模型的目标是自动为回答给出分数。当回答与提示词中的内容匹配时,奖励分数应该很高;当回答与提示词中的内容不匹配时,奖励分数应该很低。为了训练奖励模型,OpenAI 首先随机选择⼀个问题,并使用 SFT模型生成几个可能的答案。我们稍后将看到,通过⼀个叫作温度(temperature)的参数,可以针对同⼀输入生成许多回答。然后,要求标注员根据与提示词的匹配程度和有害程度等标准给这些回答排序。在多次重复此过程后,使用数据集微调 SFT 模型以进行评分。这个奖励模型将用于构建最终的 InstructGPT 模型。
训练 InstructGPT 模型的最后⼀步是强化学习,这是⼀个迭代的过程。它从⼀个初始的生成式模型开始,比如 SFT 模型。然后随机选择⼀个提示词,让模型给出预测结果,由奖励模型来评估结果。根据得到的奖励分数,相应地更新生成式模型。这个过程可以在无须人工干预的情况下重复无数次,从而自动、高效地提高模型的性能。与基础的 GPT-3 模型相比,InstructGPT 模型能够针对用户的提问生成更准确的内容。OpenAI 建议使用 InstructGPT 模型,而非原始版本。

GPT-3.5、Codex 和 ChatGPT
2022 年 3 月,OpenAI 发布了 GPT-3 的新版本。新模型可以编辑文本或向文本中插入内容。它们所用的训练数据截至 2021 年 6 月,OpenAI 称它们比先前的版本更强大。2022 年 11 月底,OpenAI 正式称这些模型为 GPT-3.5模型。OpenAI 还提出了 Codex 模型,这是⼀个在数十亿行代码上进行了微调的GPT-3 模型。正是它给 GitHub Copilot 这款自动化编程工具赋予了强大的能力,为使用 Visual Studio Code、JetBrains 甚至 Neovim 等许多文本编辑器的开发人员提供了帮助。然而,Codex 模型在 2023 年 3 月被 OpenAI 弃⽤。相反,OpenAI 建议用户从 Codex 切换到 GPT-3.5 Turbo 或 GPT-4。与此同时,GitHub 发布了基于 GPT-4 的 Copilot X 版本,其功能比之前的版本多得多。
OpenAI 对 Codex 模型的弃用提醒我们,使用应用程序接口存在固有风险:随着更高效的模型的开发和发布,它们可能会发生变化,甚至被停用。2022 年 11 月,OpenAI 推出了 ChatGPT,并将其作为⼀种实验性的对话式模型。该模型经过了微调,采用上图所示的类似技术,在交互式对话中表现出色。ChatGPT 源自 GPT-3.5 系列,该系列为其开发奠定了基础。可以说,ChatGPT 是由 LLM 驱动的应用程序,而不是真正的LLM。ChatGPT 背后的 LLM 是 GPT-3.5 Turbo。然而,OpenAI 在发布说明中将 ChatGPT 称为“模型”。在本书中,除非操作代码,否则我们将 ChatGPT 用作通用术语,既指应用程序又指模型。在特指模型时,我们使用 gpt-3.5-turbo。
GPT-4
2023 年 3 月,OpenAI 发布了 GPT-4。关于这个新模型的原理以及关键技术我们都知之甚少,因为 OpenAI 提供的信息很少。这是 OpenAI 迄今为止最先进的系统,应该能够针对用户的提问生成更安全、更有用的回答。OpenAI 声称,GPT-4 在高级推理能力方面超越了 ChatGPT。与 OpenAI GPT 家族中的其他模型不同,GPT-4 是第⼀个能够同时接收文本和图像的多模态模型。这意味着 GPT-4 在生成输出句子时会考虑图像和文本的上下文。这样⼀来,用户就可以将图像添加到提示词中并对其提问。GPT-4 经过了各种测试,它在测试中的表现优于 ChatGPT。比如,在美国统⼀律师资格考试中,ChatGPT 的得分位于第 10 百分位,而 GPT-4 的得分位于第 90 百分位。国际生物学奥林匹克竞赛的结果也类似,ChatGPT 的得分位于第 31 百分位,GPT-4 的得分则位于第 99 百分位。这个进展令⼈印象深刻,尤其考虑到它是在不到⼀年的时间内取得的。
你可能听说过基础模型这个术语。虽然像 GPT 这样的 LLM 被训练用于处理人类语言,但基础模型其实是⼀个更宽泛的概念。这类模型在训练时采用多种类型的数据(不仅限于文本),并且可以针对各种任务进行微调,包括但不限于 NLP 任务。所有的 LLM 都是基础模型,但并非所有的基础模型都是 LLM。