转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn]
如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~
目录
背景介绍
原因解释
问题修复
背景介绍
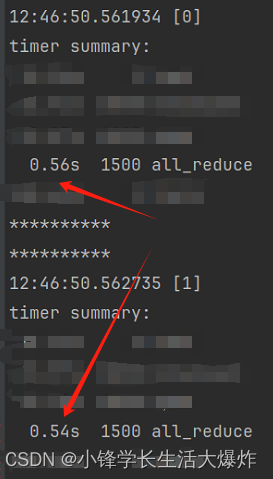
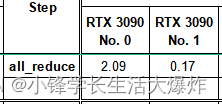
按照网上的说法,计时使用了torch.cuda.Event(enable_timing=True)和torch.cuda.synchronize(),但跑出来的时间相差还是很大。
原因解释
其实出现这个问题,是因为我们忽略了一个事实,而这个在网上相关的文章里都没有提:
-
torch.cuda.synchronize()- 作用:这个函数会使当前设备(GPU)上的所有先前CUDA操作完成。也就是说,它会等待设备上所有的CUDA内核、内存复制、CUDA流操作等完成。
- 使用场景:通常在计时或调试时使用,确保所有的GPU操作在继续执行代码之前都已完成。
- 作用范围:仅在当前设备上起作用,并不涉及跨设备或跨进程的同步。
-
dist.barrier()- 作用:这个函数会在所有参与分布式计算的进程上进行同步。只有当所有进程都到达这个屏障时,所有进程才会继续执行后续代码。这确保了所有进程在某个点上同步。
- 使用场景:在多进程分布式计算中使用,用于确保所有进程在某个同步点上处于一致状态。
- 作用范围:在所有参与同一分布式组的进程之间同步。
那么就很明显了,对于GPU之间的通信而言,只使用synchronize实际上是不够的,因为他只能保证当前GPU完成了CUDA操作。所以要保证GPU间同步,我们还得加barrier。
问题修复
把计时代码改成类似这种的即可。注意,由于网上对此的相关资料较少,如果是为了计时是可以这样搞,正常执行应该不需要加。我也不是很确定这样是否合理,请大家自行选择哈。
dist.barrier()
start_event.record()
# xxxxxxxx
dist.barrier()
end_event.record()
torch.cuda.synchronize()这样的计时,两者就很接近了: