SWS: A Complexity-Optimized Solution for Spatial-Temporal Kernel Density Visualization
- 摘要
- 1 引言
- 2 预备知识
- 2.1 STKDV 问题陈述
- 2.2 基于范围查询的解决方案(RQS)
- 3 基于滑动窗口的解决方案(SWS)
- 3.1 时间维度的滑动窗口
- 3.2 SWS:增量算法
- 4 SWS 用于其他时间内核
- 4.1 四次核
- 4.2 三角核
- 5 STKDV 渐进式可视化框架
- 6 实验评价
- 6.1 实验设置
- 6.2 Epanechnikov 内核的效率评估
- 6.3 其他内核的效率
- 6.4 渐进式可视化框架
- 6.5 使用案例:将 STKDV 显示为随时间演变的热点地图
- 7 相关工作
- 8 结论
- 9 附录
- 参考文献

摘要
时空核密度可视化(STKDV)已广泛应用于疾病爆发分析、交通事故热点检测和犯罪热点检测等领域。虽然 STKDV 可以提供准确且全面的数据可视化,但计算 STKDV 非常耗时,并且无法扩展到大规模数据集。为了解决这个问题,我们开发了一种新的基于滑动窗口的解决方案(SWS),理论上降低了生成 STKDV 的时间复杂度,而不增加空间复杂度。此外,我们将SWS与渐进式可视化框架相结合,可以不断向用户输出部分可视化结果(从粗到细),直到用户满意可视化。我们对五个大型数据集的实验研究表明,与最先进的方法相比,SWS 实现了 1.71 倍到 24 倍的加速。
1 引言
数据可视化[22,52,57]是理解数据集的重要工具。在大多数数据可视化工具中,基于核密度估计的可视化(或核密度可视化(KDV))[14, 52]已广泛应用于各种应用,包括疾病爆发分析[4, 17, 24, 30, 51, 65],交通事故热点检测[32, 37, 38, 61],犯罪热点检测[12, 13, 29, 31, 35, 40, 66],健康信息学[33, 60],资源管理 [70, 71]。因此,不同类型的科学/地理软件,包括QGIS [9]、ArcGIS [1]、CrimeStat [2]、KDV-Explorer [17]和Scikit-learn [42],也可以支持此操作。图 1 展示了使用 KDV 可视化 2020 年 2 月至 2021 年 2 月香港 COVID-19 病例密度分布的示例。

为了生成热点图(参见图 1),KDV [14,16,20,21,25,29,61,67]中的现有研究利用以下核密度函数 FP (q)(参见方程 1)确定每个像素 q 的颜色,其中 P、w 和 K(q, p) 表示二维空间数据点的集合(例如,COVID-19 病例的纬度和经度值),正权重值(即归一化)常数)和核函数(例如,Epanechnikov 核)。
F
P
(
q
)
=
∑
p
∈
P
w
⋅
K
(
q
,
p
)
(
1
)
\mathcal{F}_P(\mathbf{q})=\sum_{\mathbf{p}\in P}w\cdot K(\mathbf{q},\mathbf{p}) \qquad (1)
FP(q)=p∈P∑w⋅K(q,p)(1)
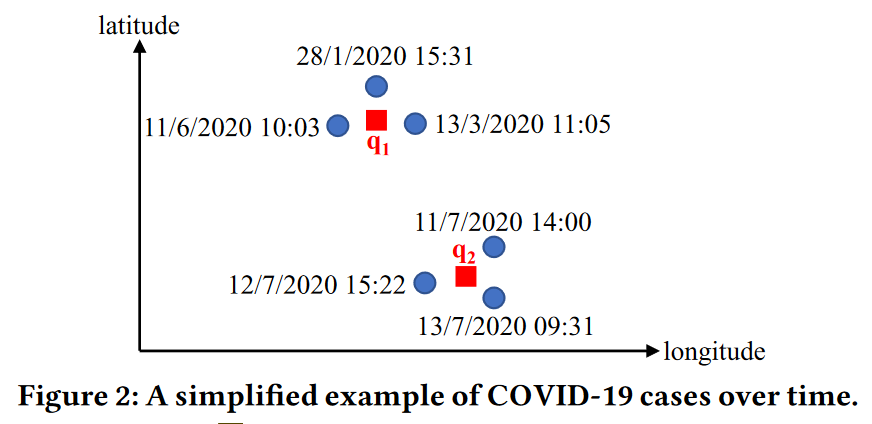
然而,使用 KDV 的一个主要缺点是该方法没有考虑数据点的出现时间,这可能会对领域专家(例如地理用户)产生误导性的可视化效果。使用图2作为COVID19病例随时间变化的简化示例,我们可以观察到q2附近的数据点具有相似的时间,这表明社区爆发,而q1附近的那些数据点的时间差距很大,这仅表明零星的爆发案例。因此,7月份的位置q2应该比q1更需要流行病学家的关注。然而,根据等式1,由于像素q1和q2都被具有相似距离的相同数量(即,三个)数据点包围,所以q1和q2都将具有相似的密度值(或颜色)。
除了上面的例子之外,最近在不同应用中的许多研究(例如犯罪热点检测[31]、疾病暴发分析[24]和交通事故热点检测[37])也指出了同样的缺点,即忽略了每个数据点使用KDV的时间,引用如下。
- “忽视犯罪的时间因素会剥夺研究人员和从业人员针对犯罪风险较高的特定时间段进行研究的机会。” [31]
- “……忽视时间因素(或将其视为次要的地理因素)将破坏我们有能力分析潜在的动态和/或可视化疾病再次发生的可能性……”[24]
- “……STKDE 时空立方体使检测疾病的时空模式变得更加容易。交通违法行为比传统的热点地图要多。” [37]
由于将时间分量纳入 KDV 的重要性,许多现有研究 [24,31,32,37,40,65,71] 提出采用时空核密度可视化(STKDV),其目的是可视化彩色时空立方体(参见图 3c),而不是热点图(如图 1)。在实践中,我们将时空立方体作为时间演化的热点图展示给用户。详细内容请参见6.5节。
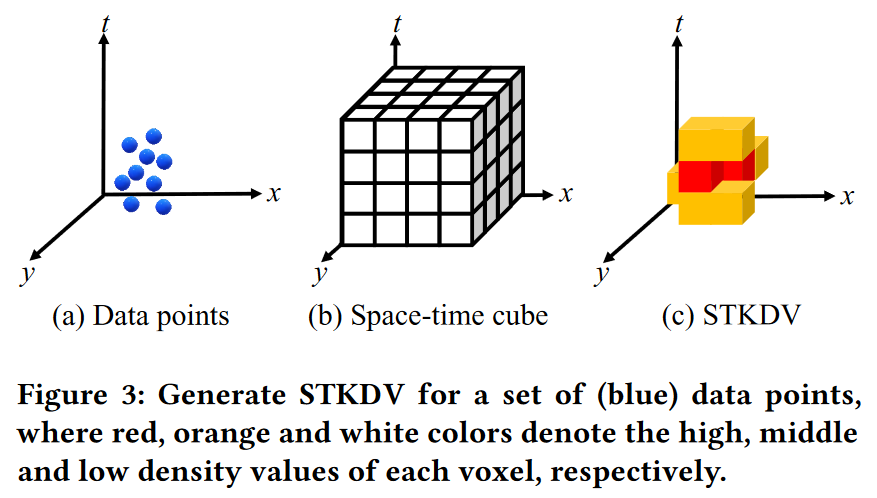
为了生成STKDV,我们首先需要将立方体划分为一组体素(即图3b中的小立方体),表示为(q,tq),其中q和tq表示二维空间位置和时间分别为体素。然后,给定一组 b P 的时空数据点 (p, tp),我们根据时空核密度函数 [30,37,40](参见方程 2)对每个体素进行着色。
F
p
^
(
q
,
t
q
)
=
∑
(
p
,
t
p
)
∈
P
^
w
⋅
K
s
p
a
c
e
(
q
,
p
)
⋅
K
t
i
m
e
(
t
q
,
t
p
)
(
2
)
\mathcal{F}_{\widehat{p}}(\mathbf{q},t_\mathbf{q})=\sum_{(\mathbf{p},t_\mathbf{p})\in\widehat{P}}w\cdot K_{\mathrm{space}}(\mathbf{q},\mathbf{p})\cdot K_{\mathrm{time}}(t_\mathbf{q},t_\mathbf{p})\quad(2)
Fp
(q,tq)=(p,tp)∈P
∑w⋅Kspace(q,p)⋅Ktime(tq,tp)(2)
其中 Kspace(q, p) 和 Ktime(tq, tp) 分别表示空间核和时间核。表1总结了STKDV的不同类型的常用核函数,这些函数在著名的QGIS和ArcGIS软件包中都得到支持。
尽管STKDV已广泛应用于不同领域,但计算STKDV非常耗时。以大小为128×128×128的时空立方体和纽约交通事故数据集[6](近150万个数据点)为例,在最坏情况下,为该数据集生成STKDV需要9.43万亿次运算。因此,该操作无法很好地扩展以处理具有高可视化质量(即大量体素)的大规模数据集,特别是对于探索性分析的使用[24,30,40]。许多现有研究也抱怨计算 STKDV 的效率低下问题。
- “…计算可视化管道的第一步,时空核密度估计(STKDE),这是计算成本最高的。” [51]
- “KDE 的时间延伸被称为时空核密度估计 (STKDE),本质上是沿时空域绘制疾病强度的体积(Nakaya 和 Yano,2010)。然而,上述方法的计算量很大…” [30]
- “扩展 KDE 算法以整合时间维度的计算量很大…” [24]
在本文中,我们开发了一种高效的基于滑动窗口的解决方案(SWS),据我们所知,这是第一个在理论上降低生成 STKDV 的时间复杂度而不增加空间复杂度的解决方案。此外,我们还进一步开发了通用的渐进式可视化框架,可以连续向用户输出部分STKDV(从粗到细)。实验结果表明,与最先进的方法相比,我们的方法 SWS 实现了 1.71x-24x 的加速。
本文的其余部分安排如下。我们首先在第 2 节中讨论背景。然后,我们在第 3 节中介绍我们的方法 SWS。接下来,我们在第 4 节中将 SWS 扩展到其他内核函数。之后,我们在第 5 节中说明 STKDV 的渐进式可视化框架。稍后,我们在第 6 节中展示了我们的实验结果。然后,我们在第 7 节中讨论了相关工作。最后,我们在第 8 节中总结了我们的论文。证明、伪代码和实现细节的附录可以在第 9 节中找到。
2 预备知识
在本节中,我们在 2.1 节中正式定义了 STKDV 的问题。然后,我们在 2.2 节中说明如何采用基于范围查询的解决方案(RQS)作为基线方法。
2.1 STKDV 问题陈述
回想第 1 节,我们需要使用时空核密度函数(参见方程 2),在尺寸为 X × Y ×T 的 3D 立方体(参见图 3b)中确定每个体素的颜色,其中 X 、Y 和 T 分别是 x 轴、y 轴和 t 轴上的体素数。
问题 1. 给定一个立方体,其大小为 X × Y × T ,体素和数据集 b P = {(p1, tp1 ), (p2, tp2 ), …, (pn, tpn )} 具有 n 个空间-对于时间数据点,我们计算每个体素 (q, tq) 的核密度值 F b P (q, tq)(参见方程 2)。
从方程 2 观察,核密度函数 F b P (q, tq) 取决于空间核 Kspace(q, p) 和时间核 Ktime(tq, tp)。由于大多数现有研究(参见表 1)主要利用三角核、Epanechnikov 核或四次核来生成 STKDV(尤其是 Epanechnikov 核),因此我们在本文中特别关注这些核函数。
2.2 基于范围查询的解决方案(RQS)
不同类型的科学和地理软件,例如 Scikitlearn [42]、QGIS [47] 和 ArcGIS [1],都实现了基于范围查询的解决方案(RQS)来提高生成 KDV 的效率。这里,我们说明如何扩展 RQS 来生成 STKDV,即解决问题 1。从表 1 观察,我们发现只有那些 dist(q, p) ≤ 1 γs 且 dist(tq, tp) ≤ 1 γt 可以对给定体素 (q, tq) 产生 F b P (q, tq)(参见方程 2)。因此,我们可以首先获得数据点的约简集Rq(参见公式3),这可以转化为范围查询问题,然后评估核密度函数F b P (q, tq)(参见公式4) ),基于简化集 Rq。
R q = { ( p , t p ) ∈ P ^ ∣ d i s t ( q , p ) ≤ 1 γ s a n d d i s t ( t q , t p ) ≤ 1 γ t } ( 3 ) R_\mathbf{q} = \left\{(\mathbf{p},t_\mathbf{p})\in\widehat{P} \Big| dist(\mathbf{q},\mathbf{p})\leq\frac{1}{\gamma_s} \mathrm{and} dist(t_\mathbf{q},t_\mathbf{p})\leq\frac{1}{\gamma_t}\right\}(3) Rq={(p,tp)∈P dist(q,p)≤γs1anddist(tq,tp)≤γt1}(3)
F P ^ ( q , t q ) = ∑ ( p , t p ) ∈ R q w ⋅ K s p a c e ( q , p ) ⋅ K t i m e ( t q , t p ) ( 4 ) \mathcal{F}_{\widehat{P}}(\mathbf{q},t_\mathbf{q}) = \sum_{(\mathbf{p},t_\mathbf{p})\in R_\mathbf{q}}w\cdot K_\mathrm{space}(\mathbf{q},\mathbf{p})\cdot K_\mathrm{time}(t_\mathbf{q},t_\mathbf{p})\qquad(4) FP (q,tq)=(p,tp)∈Rq∑w⋅Kspace(q,p)⋅Ktime(tq,tp)(4)
在现有的工作[23,28,42]中,可以使用不同类型的索引方法,例如kd树和ball树,来提高获得Rq的效率,表2总结了这些方法。
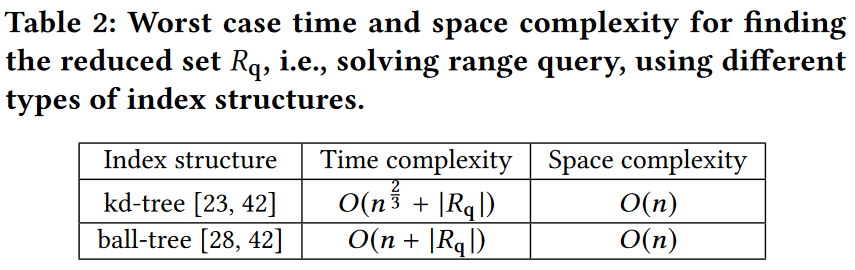
尽管RQS可以提高生成STKDV的效率,但是一旦集合Rq的大小很大,即等式3中的1γs和1γt的值很大,响应时间仍然会很长。理论上,一旦γs→0且 γt → 0,大小 |Rq| → n.在这种情况下,生成 STKDV 的时间复杂度与基本方法(即不进行滤波的扫描)相同,为 O(XYT n)
3 基于滑动窗口的解决方案(SWS)
尽管RQS方法可以提高计算F b P (q,tq)的效率,但RQS无法降低生成STKDV的时间复杂度(参见问题1),仍然需要O(XYTn)时间。在本节中,我们提出了一种基于滑动窗口的解决方案(SWS),仅需要 O(XY (T + n)) 时间来生成 STKDV,使用常用的 Epanechnikov 内核来处理 Ktime(tq, tp)。这里,我们不假设 Kspace(q, p) 的任何内核类型。
3.1 时间维度的滑动窗口
在我们的方法 SWS 中,核心思想是维持体素 (q, tq) 周围时间维度上的滑动窗口(参见图 4)。在这里,我们对 b P 中的数据点进行排序,使得 tp1 ≤ tp2 ≤ … ≤ tpn 。观察到这个滑动窗口 W (tq) 需要覆盖数据点 (p, tp),使得 dist(tq, tp) ≤ 1 γt ,即 Ktime(tq, tp) > 0(参见表 1),其中:
W
(
t
q
)
=
{
(
p
,
t
p
)
∈
P
^
∣
d
i
s
t
(
t
q
,
t
p
)
≤
1
γ
t
}
W(t_\mathbf{q})=\left\{(\mathbf{p},t_\mathbf{p})\in\widehat{P} \Big| dist(t_\mathbf{q},t_\mathbf{p})\leq\frac{1}{\gamma_t}\right\}
W(tq)={(p,tp)∈P
dist(tq,tp)≤γt1}

由于我们可以确保 W (tq) 中的那些数据点应该具有 Ktime(tq, tp) > 0(这里我们使用 Epanechnikov 内核),因此我们可以得出结论:
F
P
^
(
q
,
t
q
)
=
∑
(
p
,
t
p
)
∈
W
(
t
q
)
w
⋅
K
s
p
a
c
e
(
q
,
p
)
⋅
(
1
−
γ
t
2
d
i
s
t
(
t
q
,
t
p
)
2
)
\mathcal{F}_{\widehat{P}}(\mathbf{q},t_\mathbf{q})=\sum_{(\mathbf{p},t_\mathbf{p})\in W(t_\mathbf{q})}w\cdot K_\mathrm{space}(\mathbf{q},\mathbf{p})\cdot(1-{\gamma_t}^2dist(t_\mathbf{q},t_\mathbf{p})^2)
FP
(q,tq)=(p,tp)∈W(tq)∑w⋅Kspace(q,p)⋅(1−γt2dist(tq,tp)2)
采用一些简单的代数运算,我们可以将 F b P (q, tq) 表示为:
F
P
^
(
q
,
t
q
)
=
w
(
1
−
γ
t
2
t
q
2
)
⋅
S
W
(
t
q
)
(
0
)
(
q
)
+
2
w
γ
t
2
t
q
⋅
S
W
(
t
q
)
(
1
)
(
q
)
−
w
γ
t
2
⋅
S
W
(
t
q
)
(
2
)
(
q
)
(
5
)
\mathcal{F}_{\widehat{P}}(\mathbf{q},t_\mathbf{q})=w(1-\gamma_t{}^2t_\mathbf{q}^2)\cdot S_{W(t_\mathbf{q})}^{(0)}(\mathbf{q})+2w\gamma_t{}^2t_\mathbf{q}\cdot S_{W(t_\mathbf{q})}^{(1)}(\mathbf{q})-w\gamma_t{}^2\cdot S_{W(t_\mathbf{q})}^{(2)}(\mathbf{q})\quad(5)
FP
(q,tq)=w(1−γt2tq2)⋅SW(tq)(0)(q)+2wγt2tq⋅SW(tq)(1)(q)−wγt2⋅SW(tq)(2)(q)(5)
当:
S
W
(
t
q
)
(
i
)
(
q
)
=
∑
(
p
,
t
p
)
∈
W
(
t
q
)
t
p
i
⋅
K
s
p
a
c
e
(
q
,
p
)
(
6
)
S_{W(t_\mathrm{q})}^{(i)}(\mathbf{q})=\sum_{(\mathbf{p},t_\mathrm{p})\in W(t_\mathrm{q})}t_\mathrm{p}^i\cdot K_\mathrm{space}(\mathbf{q},\mathbf{p})\quad(6)
SW(tq)(i)(q)=(p,tp)∈W(tq)∑tpi⋅Kspace(q,p)(6)
滑动窗口 (tq) 维护/存储这三个统计项 S(i) W (tq)(q),其中 i = 0, 1, 2。
3.2 SWS:增量算法
在说明了滑动窗口的概念之后,我们提出了一种高效的增量算法,即 SWS,用于提高评估时域中下一个体素 (q, tqn ) 的核密度函数 F b P (q, tqn ) 的效率。维度,即固定空间位置 q 并将时间坐标从 tq 更改为 tqn 。
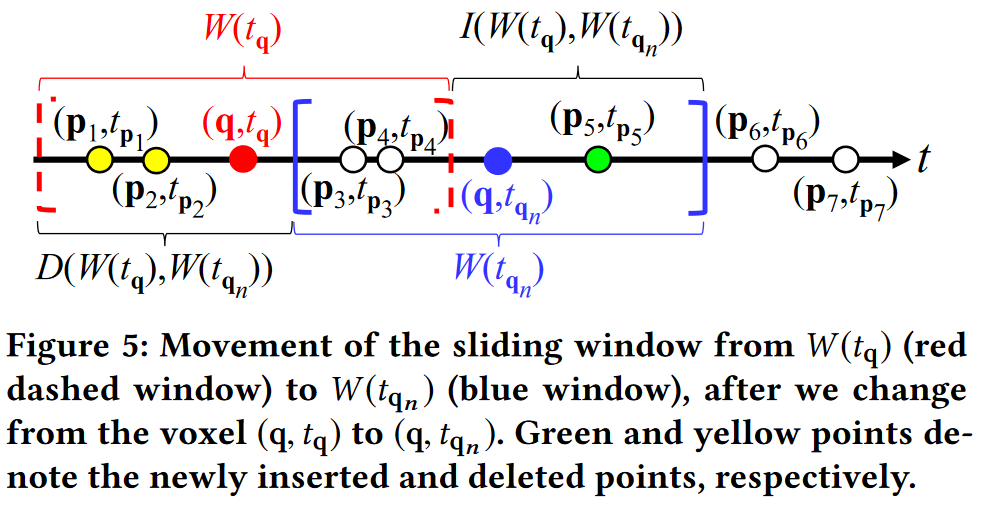
从图5中观察,一旦我们从体素(q,tq)转移到(q,tqn),我们需要插入绿色点(p5,tp5)并删除黄色点(p1,tp1)和(p2,tp2) )以便更新到下一个窗口 W (tqn )(即蓝色窗口)。在这里,我们将这两组点表示为 I (W (tq),W (tqn )) (参见公式 7)和 D(W (tq),W (tqn )) (参见公式 8),其中:
I
(
W
(
t
q
)
,
W
(
t
q
n
)
)
=
W
(
t
q
n
)
∖
W
(
t
q
)
(
7
)
D
(
W
(
t
q
)
,
W
(
t
q
n
)
)
=
W
(
t
q
)
∖
W
(
t
q
n
)
(
8
)
I(W(t_\mathbf{q}),W(t_\mathbf{q_n}))\quad=\quad W(t_\mathbf{q_n})\setminus W(t_\mathbf{q})\quad(7)\\D(W(t_\mathbf{q}),W(t_\mathbf{q_n}))\quad=\quad W(t_\mathbf{q})\setminus W(t_\mathbf{q_n})\quad(8)
I(W(tq),W(tqn))=W(tqn)∖W(tq)(7)D(W(tq),W(tqn))=W(tq)∖W(tqn)(8)
回想一下 3.1 节,每个滑动窗口 W (tq) 需要维护统计项 S(0) W (tq)(q)、S(1) W (tq)(q) 和 S(2) W (tq) (q)(参见公式 6)。因此,一旦我们更新了这些项,我们还需要将这些项更新为 S (0) W (tqn )(q)、S(1) W (tqn )(q) 和 S(2) W (tqn )(q)从 W (tq) 到 W (tqn ) 的窗口。引理 1 显示了在给定统计项 S(i) W (tq)(q) 且 i = 0, 1, 2 的情况下,我们如何逐步获得 S(i) W (tqn )(q)。
引理 1. 分别给定体素 (q, tq) 和 (q, tqn ) 的两个窗口 W (tq) 和 W (tqn ),以及统计项 S(i) W (tq)(q),其中 i = 0, 1, 2,对于窗口W (tq),我们可以用以下等式表示S(i) W (tqn )(q)。
S W ( t q n ) ( i ) ( q ) = S W ( t q ) ( i ) ( q ) − ∑ ( p , t p ) ∈ D ( W ( t q ) , W ( t q n ) ) t p i ⋅ K s p a c e ( q , p ) + ∑ ( p , t p ) ∈ I ( W ( t q ) , W ( t q n ) ) t p i ⋅ K s p a c e ( q , p ) (9) \begin{aligned}S_{W(t_{\mathbf{q}\boldsymbol{n}})}^{(i)}(\mathbf{q})&=S_{W(t_{\mathbf{q}})}^{(i)}(\mathbf{q})-\sum_{(\mathbf{p},t_{\mathbf{p}})\in D(W(t_{\mathbf{q}}),W(t_{\mathbf{q}\boldsymbol{n}}))}t_{\mathbf{p}}^{i}\cdot K_{space}(\mathbf{q},\mathbf{p})\\&+\sum_{(\mathbf{p},t_{\mathbf{p}})\in I(W(t_{\mathbf{q}}),W(t_{\mathbf{q}\boldsymbol{n}}))}t_{\mathbf{p}}^{i}\cdot K_{space}(\mathbf{q},\mathbf{p})&\text{(9)}\end{aligned} SW(tqn)(i)(q)=SW(tq)(i)(q)−(p,tp)∈D(W(tq),W(tqn))∑tpi⋅Kspace(q,p)+(p,tp)∈I(W(tq),W(tqn))∑tpi⋅Kspace(q,p)(9)
从方程9观察,一旦我们更新了窗口W(tqn)的统计项S(i)W(tqn)(q),我们只需要扫描I(W(tq),W(tqn)中的附加数据点)并删除 D(W (tq),W (tqn )) 中的那些点(参见图 5),这些点仅需要 O(|I (W (tq),W (tqn ))| + |D(W ( tq),W (tqn ))|) 时间。因此,我们还可以在 O(|I (W (tq),W (tqn ))| + |D( W (tq),W (tqn ))|) 时间(参见引理 2)。
引理 2. 分别给定体素 (q, tq) 和 (q, tqn ) 的两个窗口 W (tq) 和 W (tqn ),以及统计项 S(i) W (tq)(q),其中 i = 0, 1, 2,对于窗口 W (tq),我们可以计算体素 (q, tqn ) 的核密度函数 F b P (q, tqn ) 并更新统计项 S(i) W (tqn )(q) 对于窗口 W (tqn ),时间为 O(|I (W (tq),W (tqn ))| + |D(W (tq),W (tqn ))|) 时间。
有了上述概念,我们讨论如何有效地计算沿时间轴(或 t 轴)具有相同空间的所有体素的所有核密度值 F b P (q, tq)(参见方程 5)位置 q (参见图 6),其中我们将这些 T 体素表示为 (q, tq1 ), (q, tq2 ),…, (q, tqT )。
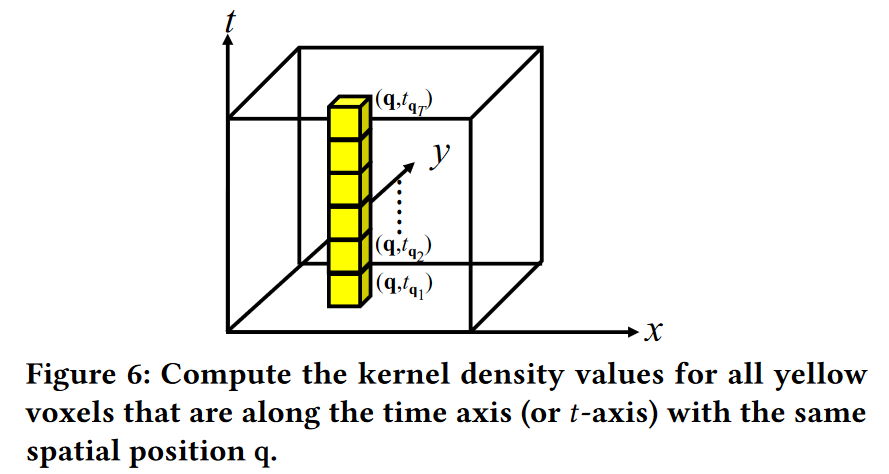
图 7 说明了沿 t 轴对应于不同体素的多个滑动窗口。假设我们已经计算了体素 (q, tq1 ) 的密度值 F b P (q, tq1 ) 并且还维护了红色的统计项 S(i) W (tq1 )(q) (参见方程 6)窗口 Wtq1 ,需要 O(|Wtq1 |) 时间,然后我们可以更新连续窗口 Wtq2 的统计项,即 S (i ) W (tq2 )(q) 并计算 F b P (q, tq2 ) O(|I (W (tq1 ),W (tq2 ))| + |D(W (tq1 ),W (tq2 ))|) 时间,基于引理 2。对其他窗口采用相同的方法(例如,粉红色和黑色窗口),我们可以得出结论,获得沿时间轴具有相同空间位置的所有体素(即图6中的所有黄色体素)的密度值的时间复杂度为1:
O
(
∣
W
t
q
1
∣
+
∑
i
=
1
T
−
1
∣
I
(
W
(
t
q
i
)
,
W
(
t
q
i
+
1
)
)
∣
+
∑
i
=
1
T
−
1
∣
D
(
W
(
t
q
i
)
,
W
(
t
q
i
+
1
)
)
∣
+
T
)
(
10
)
O\Big(|W_{t_{\mathbf{q}_1}}|+\sum_{i=1}^{T-1}|I(W(t_{\mathbf{q}_i}),W(t_{\mathbf{q}_{i+1}}))|+\sum_{i=1}^{T-1}|D(W(t_{\mathbf{q}_i}),W(t_{\mathbf{q}_{i+1}}))|+T\Big)\quad(10)
O(∣Wtq1∣+i=1∑T−1∣I(W(tqi),W(tqi+1))∣+i=1∑T−1∣D(W(tqi),W(tqi+1))∣+T)(10)
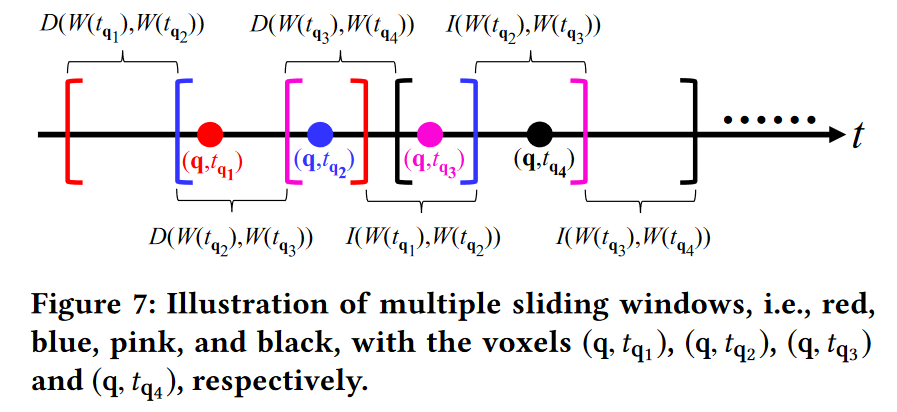
在引理 3 中,我们指出计算所有黄色体素的密度值的时间复杂度(参见方程 10)为 O(T + n)。我们在附录中包含了这个引理的正式证明(参见第 9.1 节)。
引理 3. 计算所有 T 体素 (q, tq1 ), (q, tq2 ),…, (q, tqT ) 的密度值的时间复杂度(即方程 10)为 O(T +n)。
一旦我们可以使用 O(T + n) 时间获得具有相同空间位置的沿 t 轴的所有体素的所有密度值,我们还可以得出结论,SWS 方法只需要 O(XY (T + n)) 时间生成 STKDV,因为可视化中存在 XY 二维空间位置,如定理 1 中所述。
定理 1。基于滑动窗口的解决方案 (SWS) 需要 O(XY (T + n)) 时间来生成 STKDV(参见问题 1),使用 Epanechnikov 内核计算 Ktime(tq, tp)。
需要说明的是,我们的方法 SWS 仅存储一个滑动窗口来处理所有体素 (q, tq1 )、(q, tq2 )、…、(q, tqT )(即图 6 中的黄色体素)。该滑动窗口可以被清除,然后重新用于具有另一个空间位置的下一个 T 体素。因此,SWS 仅需要 O(n) 额外空间来维护该滑动窗口及其统计项,这不会增加生成 STKDV 的最坏情况空间复杂度,即 O(XYT + n) 空间(参见引理 4)。
引理 4. 基于滑动窗口的解决方案 (SWS) 的空间复杂度为 O(XYT + n),用于生成 STKDV(参见问题 1),使用 Epanechnikov 内核计算 Ktime(tq, tp)。
SWS 的伪代码和实现细节可以在附录中找到(参见第 9.4 节)。
4 SWS 用于其他时间内核
在第 3 节中,我们说明了如何利用 SWS 来提高使用 Epanechnikov 核作为 K time(tq, tp) 生成 STKDV 的效率。在这里,我们提出一个问题,我们是否可以将此方法扩展到表1中的其他核函数,并具有类似的时间和空间效率保证(分别参见定理1和引理4)?本节我们对这个问题给出肯定的回答。
4.1 四次核
我们将以下具有四次核的核密度函数视为 Ktime(tq, tp)。
F
p
^
(
q
,
t
q
)
=
∑
(
p
,
t
p
)
∈
W
(
t
q
)
w
⋅
K
s
p
a
c
e
(
q
,
p
)
⋅
(
1
−
γ
t
2
d
i
s
t
(
t
q
,
t
p
)
2
)
2
\mathcal{F}_{\widehat{p}}(\mathbf{q},t_{\mathbf{q}})=\sum_{(\mathbf{p},t_{\mathbf{p}})\in W(t_{\mathbf{q}})}w\cdot K_{\mathrm{space}}(\mathbf{q},\mathbf{p})\cdot(1-{\gamma_{t}}^{2}dist(t_{\mathbf{q}},t_{\mathbf{p}})^{2})^{2}
Fp
(q,tq)=(p,tp)∈W(tq)∑w⋅Kspace(q,p)⋅(1−γt2dist(tq,tp)2)2
观察到我们还可以将该核密度函数分解为:
F
P
^
(
q
,
t
q
)
=
w
(
1
−
2
γ
t
2
t
q
2
+
γ
t
4
t
q
4
)
⋅
S
W
(
t
q
)
(
0
)
(
q
)
+
w
(
4
γ
t
2
t
q
−
4
γ
t
4
t
q
3
)
⋅
S
W
(
t
q
)
(
1
)
(
q
)
+
w
(
6
γ
t
4
t
q
2
−
2
γ
t
2
)
⋅
S
W
(
t
q
)
(
2
)
(
q
)
−
4
w
γ
t
4
t
q
⋅
S
W
(
t
q
)
(
3
)
(
q
)
+
w
γ
t
4
⋅
S
W
(
t
q
)
(
4
)
(
q
)
\begin{aligned} \mathcal{F}_{\widehat{P}}(\mathbf{q},t_{\mathbf{q}})& = w(1-2\gamma_{t}^{2}t_{\mathbf{q}}^{2}+\gamma_{t}^{4}t_{\mathbf{q}}^{4})\cdot S_{W(t_{\mathbf{q}})}^{(0)}(\mathbf{q}) \\ &+ w(4\gamma_t^2t_\mathbf{q}-4\gamma_t^4t_\mathbf{q}^3)\cdot S_{W(t_\mathbf{q})}^{(1)}(\mathbf{q}) \\ &+ w(6\gamma_t^4t_\mathbf{q}^2-2\gamma_t^2)\cdot S_{W(t_\mathbf{q})}^{(2)}(\mathbf{q}) \\ &- 4w\gamma_t^4t_\mathbf{q}\cdot S_{W(t_\mathbf{q})}^{(3)}(\mathbf{q})+w\gamma_t^4\cdot S_{W(t_\mathbf{q})}^{(4)}(\mathbf{q}) \end{aligned}
FP
(q,tq)=w(1−2γt2tq2+γt4tq4)⋅SW(tq)(0)(q)+w(4γt2tq−4γt4tq3)⋅SW(tq)(1)(q)+w(6γt4tq2−2γt2)⋅SW(tq)(2)(q)−4wγt4tq⋅SW(tq)(3)(q)+wγt4⋅SW(tq)(4)(q)
一旦我们在每个体素 (q, tq) 的滑动窗口 W (tq) 中维护统计项 S(i) W (tq)(q)(参见方程 6),其中 0 ≤ i ≤ 4,使用与 3.2 节中的类似想法,我们可以直接扩展引理 1,2,3,4 和四次核的定理 1,即 O(XY (T +n)) 时间和 O(XYT + n) 空间来生成 STKDV。
4.2 三角核
我们继续将三角核的核密度函数视为 Ktime(tq, tp)。
F P ^ ( q , t q ) = ∑ ( p , t p ) ∈ W ( t q ) w ⋅ K s p a c e ( q , p ) ⋅ ( 1 − γ t d i s t ( t q , t p ) ) \mathcal{F}_{\widehat{P}}(\mathbf{q},t_{\mathbf{q}})=\sum_{(\mathbf{p},t_{\mathbf{p}})\in W(t_{\mathbf{q}})}w\cdot K_{\mathrm{space}}(\mathbf{q},\mathbf{p})\cdot(1-\gamma_{t}dist(t_{\mathbf{q}},t_{\mathbf{p}})) FP (q,tq)=(p,tp)∈W(tq)∑w⋅Kspace(q,p)⋅(1−γtdist(tq,tp))
然而,与 Epanechnikov 和四次核不同,我们不能将核密度函数分解为统计项的线性组合(如方程 5),因为我们不能简单地扩展欧几里得距离 dist(tq, tp)。尽管如此,我们注意到:
d
i
s
t
(
t
q
,
t
p
)
=
{
t
q
−
t
p
if
t
q
>
t
p
t
p
−
t
q
otherwise
dist(t_\mathbf{q},t_\mathbf{p})=\begin{cases}t_\mathbf{q}-t_\mathbf{p}&\text{if}t_\mathbf{q}>t_\mathbf{p}\\t_\mathbf{p}-t_\mathbf{q}&\text{otherwise}\end{cases}
dist(tq,tp)={tq−tptp−tqiftq>tpotherwise
因此,一旦我们分别维护了体素 (q, tq) 的左右滑动窗口 WL(tq) 和 WR (tq)(参见图 8),我们就可以获得:
F P ^ ( q , t q ) = w S W ( t q ) ( 0 ) ( q ) − w γ t ( t q S W L ( t q ) ( 0 ) ( q ) − S W L ( t q ) ( 1 ) ( q ) + S W R ( t q ) ( 1 ) ( q ) − t q S W R ( t q ) ( 0 ) ( q ) ) ( 11 ) \begin{aligned}\mathcal{F}_{\widehat{P}}(\mathbf{q},t_{\mathbf{q}})&=wS_{W(t_{\mathbf{q}})}^{(0)}(\mathbf{q})-w\gamma_{t}\Big(t_{\mathbf{q}}S_{W_{L}(t_{\mathbf{q}})}^{(0)}(\mathbf{q})-S_{W_{L}(t_{\mathbf{q}})}^{(1)}(\mathbf{q})\\&+S_{W_{R}(t_{\mathbf{q}})}^{(1)}(\mathbf{q})-t_{\mathbf{q}}S_{W_{R}(t_{\mathbf{q}})}^{(0)}(\mathbf{q})\Big)&(11)\end{aligned} FP (q,tq)=wSW(tq)(0)(q)−wγt(tqSWL(tq)(0)(q)−SWL(tq)(1)(q)+SWR(tq)(1)(q)−tqSWR(tq)(0)(q))(11)
其中 S(0) W (tq)(q)、S(0) WL (tq)(q)、S(1) WL (tq)(q)、S(0) WR (tq)(q) 和 S (1) WR (tq)(q) 是关于 W (tq)、WL(tq) 或 WR (tq) 的统计项(参见公式 6)。

回想一下 3.2 节,我们仍然讨论如何有效地更新下一个体素(q,tqn)的这些统计项。在这里,我们声称需要 O(|I (W (tq),W (tqn ))| + |D(W (tq),W (tqn ))| + |C(tq, tqn )|) 来获得所有这些统计项以及引理 5 中下一个体素 (q, tqn ) 的密度值 F b P (q, tqn ),其中 C(tq, tqn ) 表示 b P 中的点集 (p, tp)时间 tp 在区间 [tq, tqn ] 内(参见公式 12 和图 9),I (W (tq),W (tqn )) 和 D(W (tq),W (tqn )) 定义为分别为等式 7 和 8。我们将引理 5 的证明留在附录中(参见第 9.2 节)。
C
(
t
q
,
t
q
n
)
=
{
(
p
,
t
p
)
∈
P
^
∣
t
q
≤
t
p
≤
t
q
n
}
C(t_\mathbf{q},t_\mathbf{q_n})=\{(\mathbf{p},t_\mathbf{p})\in\widehat{P}|t_\mathbf{q}\leq t_\mathbf{p}\leq t_\mathbf{q_n}\}
C(tq,tqn)={(p,tp)∈P
∣tq≤tp≤tqn}
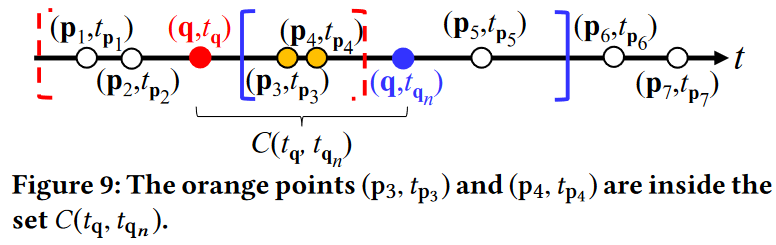
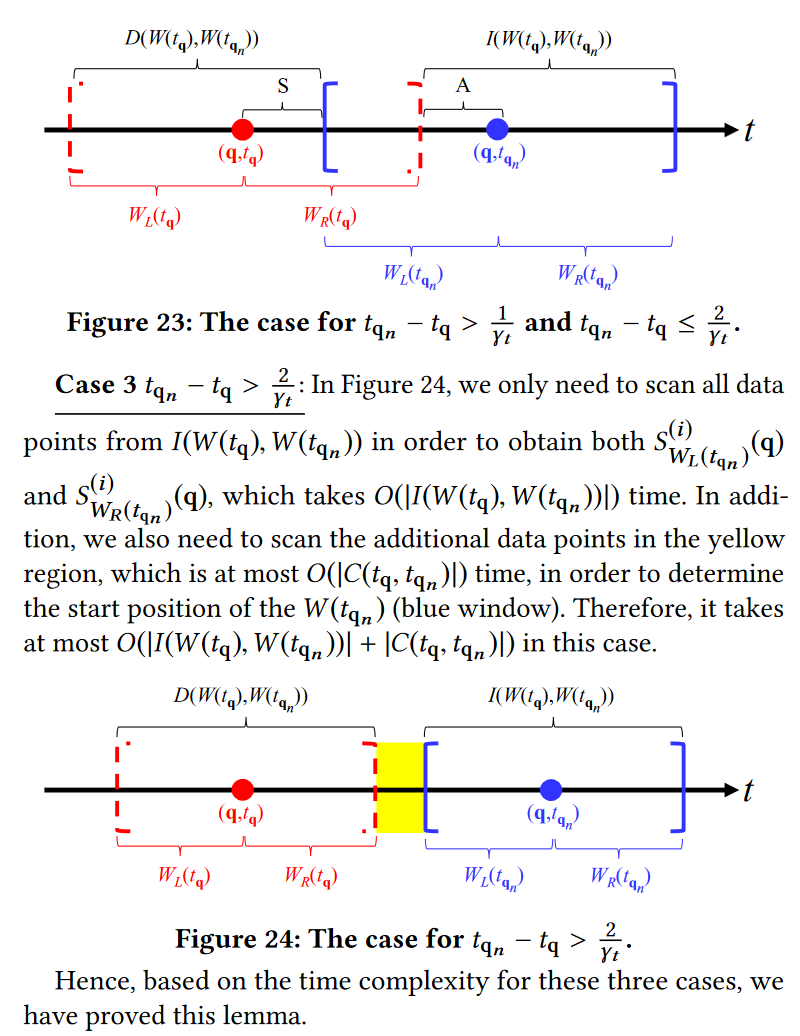
引理 5. 分别给定体素 (q, tq) 和 (q, tqn ) 的两个窗口 W (tq) 和 W (tqn ),以及窗口 W (tq) 的统计项,我们可以计算核密度函数 F b P (q, tqn ),使用三角核,针对体素 (q, tqn ) 并更新 O(|I (W (tq),W (tqn ) 中窗口 W (tqn ) 的统计项)| + |D(W (tq),W (tqn ))| + |C(tq, tqn )|) 时间。
与引理2相比,尽管我们需要花费额外的成本|C(tq, tqn )|为了获得密度值 F b P (q, tqn ),我们声称我们仍然可以使用 O(T + n) 时间来计算所有 T 体素 (q, tq1 )、(q, tq2 ) 的所有密度值, …, (q, tqT ) (参见图 6)在引理 6 中。我们将这个引理的证明留在附录中(参见第 9.3 节)。
引理 6. 使用三角核作为 Ktime(tq, tp),评估所有 T 体素 (q, tq1 ), (q, tq2 ),…, (q, tqT ) 的密度值的时间复杂度为O(T + n)。
基于引理6,我们可以将定理1,即生成STKDV的时间O(XY(T+n))扩展到三角核。另外,由于SWS方法只需要维护WL(tq)、WR(tq)、W(tq)及其统计项,因此该方法的空间复杂度保持在O(XYT + n)(即引理4成立)三角核)。
5 STKDV 渐进式可视化框架
尽管 SWS 可以显着降低生成 STKDV 的时间复杂度(从 O(XYT n) 到 O(XY (T + n))),但 SWS 仍然很耗时,尤其是对于大规模数据集。许多现有研究[34,41,43,45,46,48,67-69]不是用所有数据点生成可视化,而是采用数据采样方法来进一步提高不同可视化任务的效率。特别是,佩罗特等人。 [43]建议首先将数据集划分为不同级别的不同子集(具有不同大小),然后逐步为用户(例如数据科学家)生成可视化。该方法的总体思路是首先向用户提供粗略的可视化,然后进一步细化,直到用户对可视化质量满意为止。在本节中,我们扩展了生成渐进式 STKDV 的想法(参见图 10)。
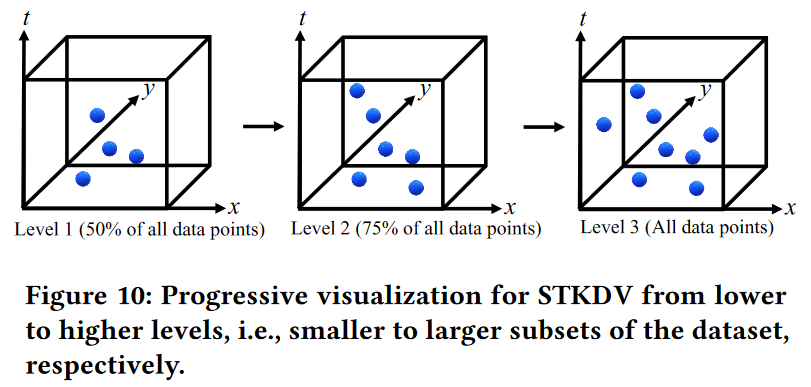
支持渐进式 STKDV 的一种直接方法是从头开始计算每个级别的密度值。然而,我们观察到每对连续级别共享许多数据点,例如图 10 中的级别 2 和级别 3 可以共享六个数据点。因此,这种方法可能会浪费前一级别的密度计算。在这里,我们提出一个问题,我们是否可以重用上一层的信息来生成下一层的STKDV,以进一步提高渐进式可视化的效率?
这里,我们令b Pl 和b Pl+1 分别为第l 层和第(l + 1)层的两组数据点。此外,我们将 Il 表示为位于 b Pl+1 但不在 b Pl 中的新数据点的集合,即 Il = b Pl+1 \ b Pl。根据方程 2,我们有 2:
F P ^ ℓ + 1 ( q , t q ) = F P ^ ℓ ( q , t q ) + F I ℓ ( q , t q ) ( 13 ) \mathcal{F}_{\widehat{P}_{\ell+1}}(\mathbf{q},t_{\mathbf{q}})=\mathcal{F}_{\widehat{P}_{\ell}}(\mathbf{q},t_{\mathbf{q}})+\mathcal{F}_{I_{\ell}}(\mathbf{q},t_{\mathbf{q}})\quad(13) FP ℓ+1(q,tq)=FP ℓ(q,tq)+FIℓ(q,tq)(13)
假设我们已经存储了第 l 层中每个体素 (q, tq) 的精确结果 F b Pl (q, tq),基于计算 FIl (q, tq),我们可以得到 F b Pl+1 (q, tq) , tq),然后添加每个体素 (q, tq) 的预先计算值 F b Pl (q, tq)。因此,我们可以使用 O(XY (T + |Il |)) 时间(基于我们的方法 SWS)来生成 l + 1 级的 STKDV,这比从头开始生成 STKDV 要快得多。由于我们最多只维护两个大小为 X ×Y ×T 的立方体(对于 F b Pl (q, tq) 和 FIl (q, tq))和最多 n 个数据点(对于 b P 1, I2, I3,. …),空间复杂度仍为 O(XYT + n)。需要注意的是,这种渐进式可视化框架可以与不同类型的数据采样方法(例如随机采样[44])相结合。
6 实验评价
在本节中,我们首先介绍6.1节中的实验设置。然后,我们使用 Epanechnikov 内核研究我们的方法相对于第 6.2 节中现有方法的效率改进。之后,我们使用其他核函数进一步比较 6.3 节中所有方法的效率。接下来,我们在 6.4 节中演示使用渐进式可视化框架生成 STKDV 的效率。最后,我们在第 6.5 节中提供了实际用例,通过将 STKDV 显示为时间演化热点图来可视化时间演化热点。
6.1 实验设置
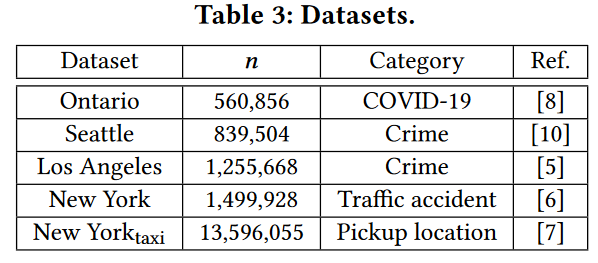
我们使用五个大型数据集进行实验,表3总结了这些数据集。所有这些数据集都是来自不同城市/省份地方政府的开放数据。我们遵循[14, 25]并利用斯科特规则[52]来获得默认参数γs和γt。此外,我们将生成STKDV的默认分辨率设置为128×128×128。
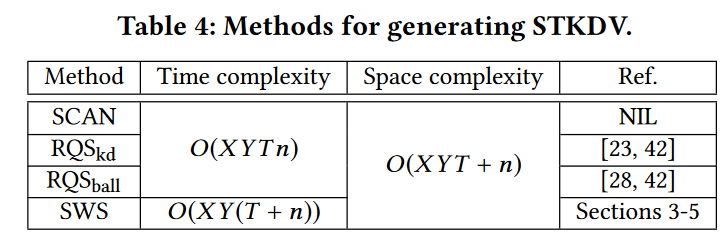
在我们的实验中,我们将我们的方法 SWS 与不同的方法进行了比较(参见表 4)。 SCAN是基于扫描的生成STKDV的方法,它不采用任何类型的过滤。 RQSkd 和 RQSball 是基于范围查询的解决方案(参见第 2.2 节),分别采用 kd 树和 ball 树。与其他方法相比,我们的方法 SWS 具有较低的最坏情况时间复杂度。我们用C++实现了所有方法,并在具有32GB内存的Intel i7 3.19GHz PC上进行了实验。在本文中,我们使用响应时间(秒)来衡量所有方法的效率,并且仅报告小于14400秒(即4小时)的响应时间。
6.2 Epanechnikov 内核的效率评估
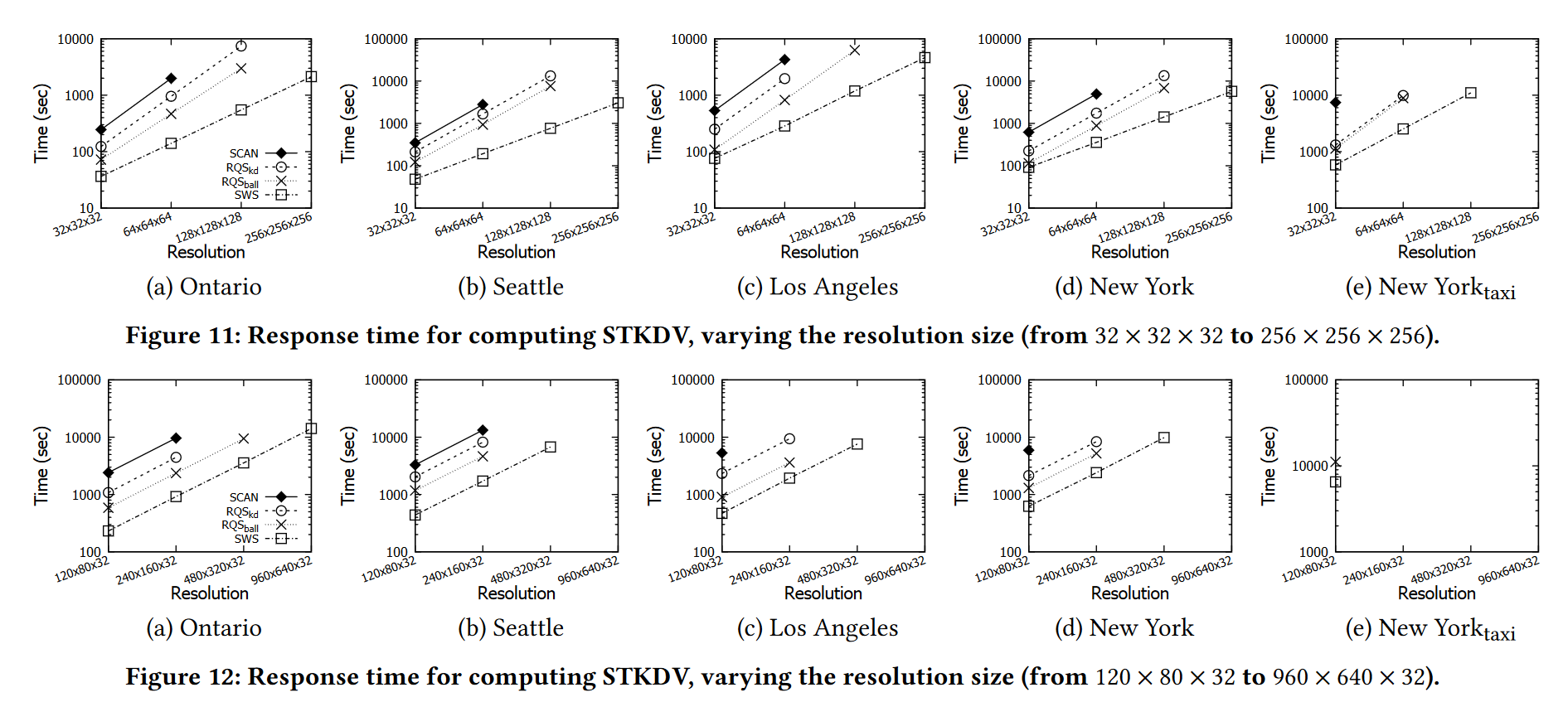
尽管我们的方法 SWS 理论上比现有方法更有效,且没有额外的空间开销(参见表 4),但尚未在实践中将我们的方法与这些方法的时间和空间效率进行比较。在本节中,我们进行以下实验来测试所有方法的时间和空间效率。
改变分辨率大小:在第一个实验中,我们选择四种分辨率大小,分别是32×32×32、64×64×64、128×128×128和256×256×256,并测量不同方法的响应时间。在图 11 中,我们观察到我们的方法 SWS 始终优于具有不同分辨率的现有方法。由于现有方法的(最坏情况)时间复杂度为 O(XYTn)(参见表 4),一旦我们使用下一个更大的分辨率(例如,从 32 × 32 × 32 至 64 × 64 × 64)。然而,由于SWS的时间复杂度为O(XY(T+n)),所以使用下一个更大的分辨率,SWS的响应时间仅增加4倍。因此,分辨率越大,SWS 与现有方法之间的时间差距就越大(参见图 11)。
在第二个实验中,我们进一步选择120×80×32、240×160×32、480×320×32和960×640×32四种分辨率尺寸进行测试。由于我们仅改变空间分辨率 X × Y 并固定时间分辨率 T ,因此我们的方法 SWS 和最佳方法 RQSball 之间的时间差距对于使用下一个更大的分辨率(例如,从 120 × 80 × 32 到 240 × 160 × 32)。尽管如此,与现有方法相比,我们的方法 SWS 仍然实现了至少 1.71 倍到 2.69 倍的加速(参见图 12)。
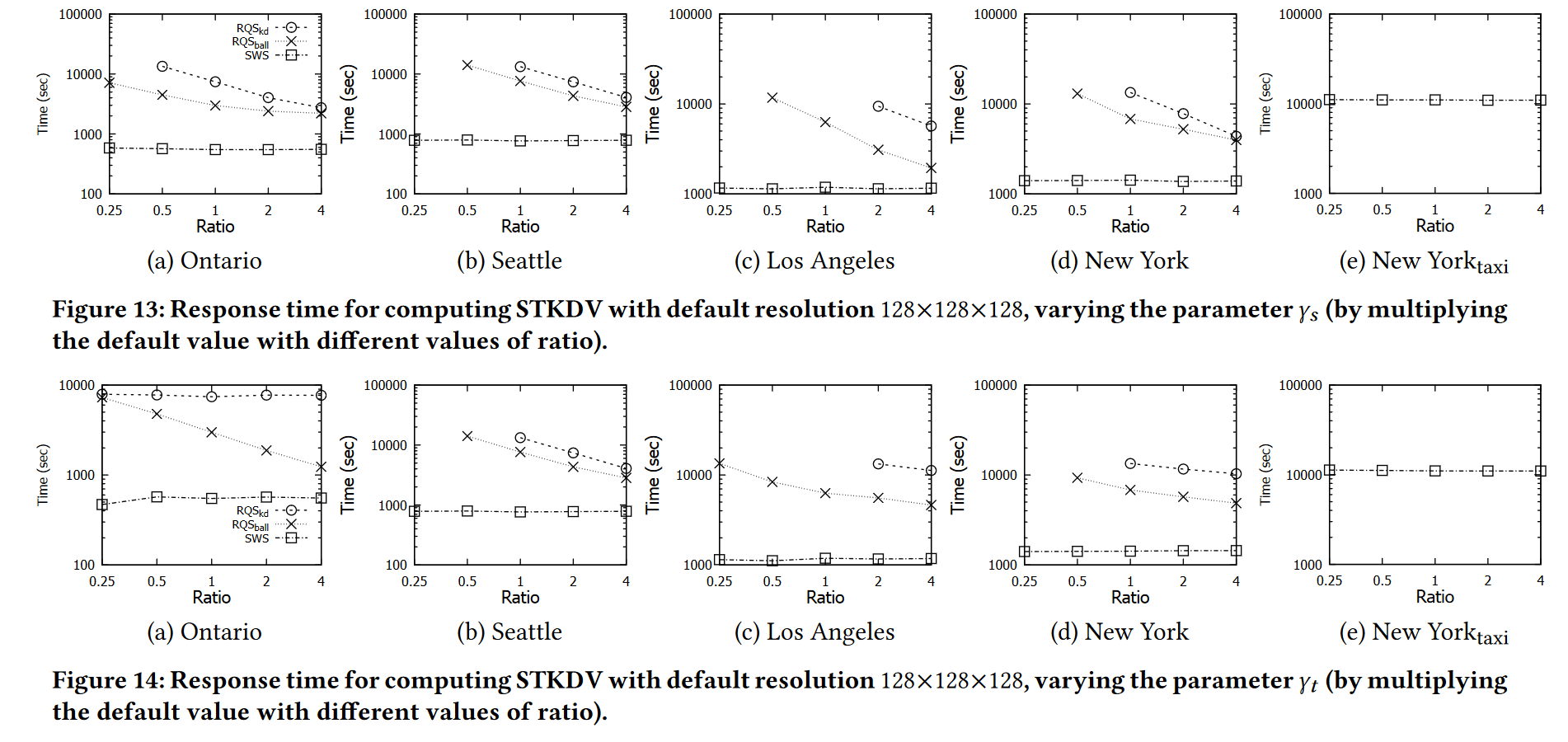
改变参数 γs :我们继续研究参数 γs 如何影响所有方法的响应时间。这里,我们采用默认分辨率128×128×128和默认参数γt(通过斯科特规则获得)。在本实验中,我们将γs的默认值乘以不同的比率值,包括0.25、0.5、1、2和4,并测量生成STKDV的响应时间。回想一下,1 γ 内的数据点可以具有非零的 Kspace(q, p) 值(参见表 1)。因此,一旦γs值较小(即范围1γs较大),所有基于范围查询的方法RQSkd和RQSball都需要扫描更多的数据点和索引节点。因此,当比率值较小时,所有这些基于范围查询的方法都会变慢(参见图 13)。由于我们的方法 SWS 对 γs 不敏感,因此我们的方法比现有方法显着更有效,特别是对于较小的 γs 值。
改变参数γt:我们进一步进行了使用不同的γt值(即默认值乘以不同的比率值)来测量不同方法的响应时间的实验,同时我们采用默认的γs值和默认分辨率大小 128 × 128 × 128。在图 14 中,我们观察到,无论我们采用哪种 γt(或比率),我们的方法 SWS 都明显优于现有方法。此外,与基于范围查询的方法不同,SWS 对参数 γt 不敏感。
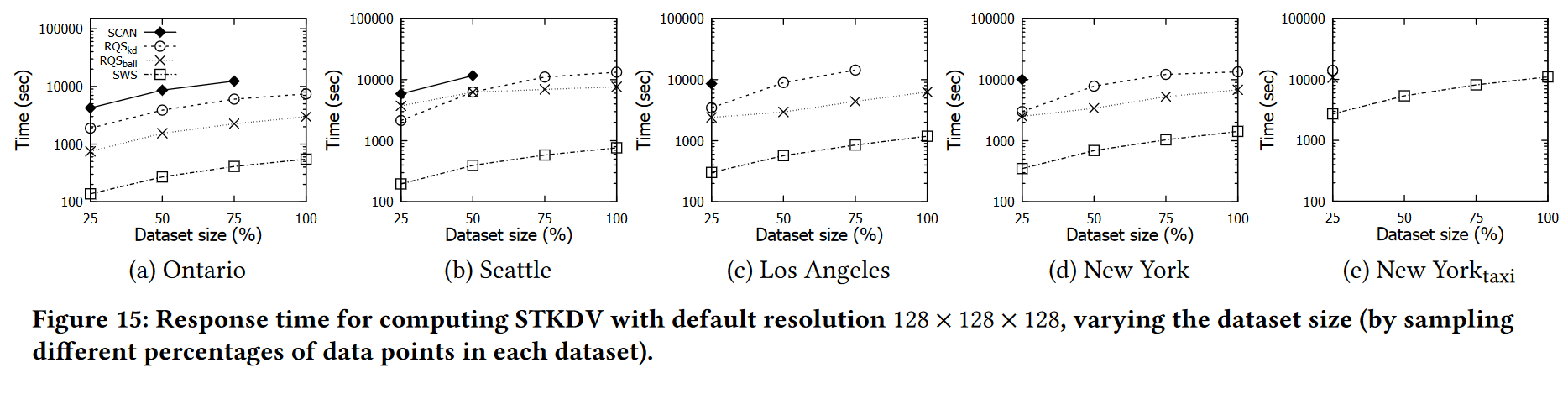
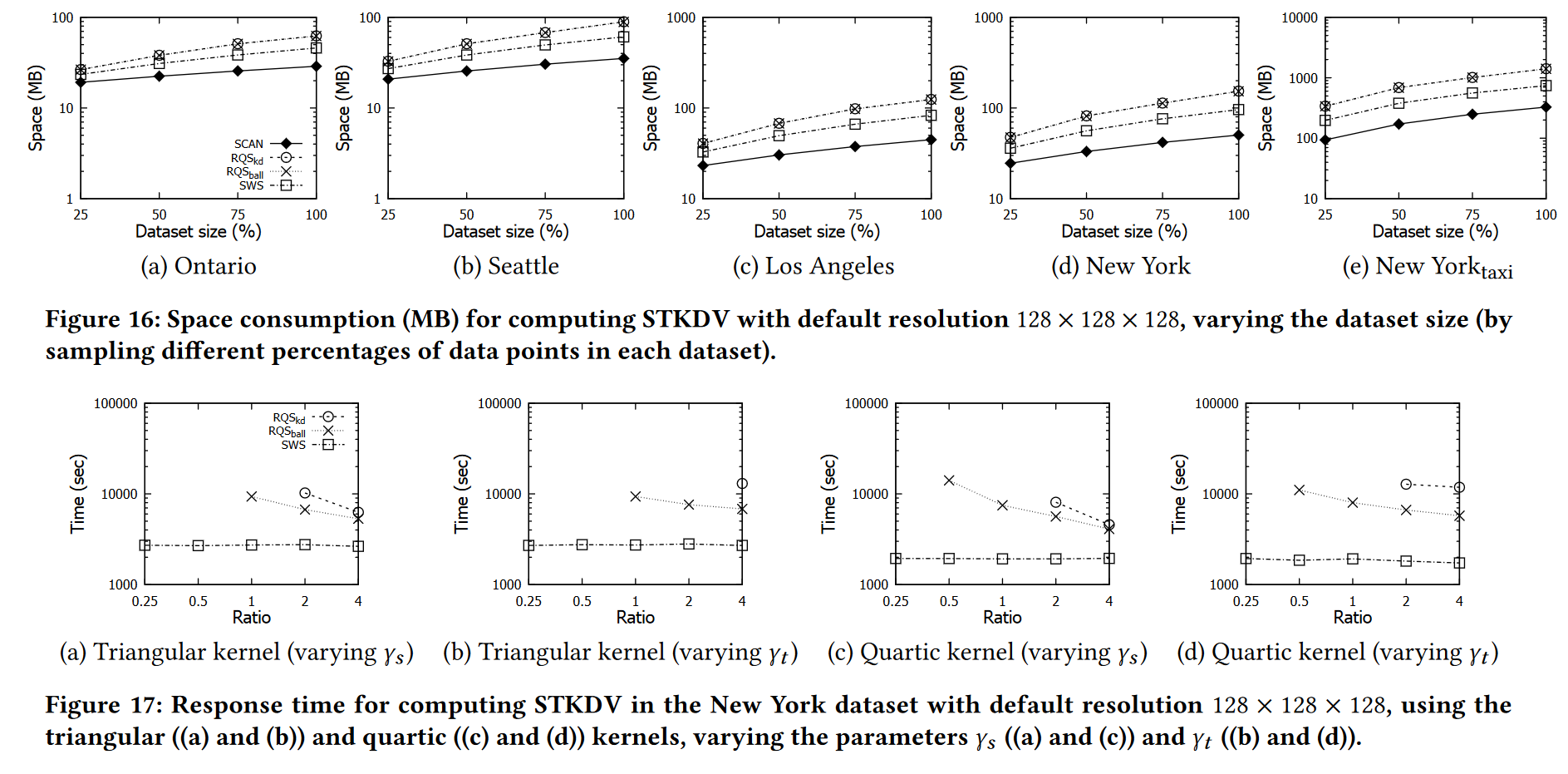
改变数据集大小:在本实验中,我们以不同的百分比对每个数据集(表 3 中)进行随机采样,包括 25%、50%、75% 和 100%(原始数据集),并测量响应时间和内存空间消耗每个采样数据集的每种方法。在图 15 中,我们观察到 SWS 在不同数据集大小下始终优于现有方法 5 到 16 倍的加速。另一方面,由于我们的方法 SWS 与现有方法具有相同的空间复杂度(参见表 4),因此所有方法的空间消耗相似(参见图 16)。
6.3 其他内核的效率
我们研究了使用其他内核生成 STKDV 的响应时间。在本实验中,我们采用纽约数据集进行测试,并遵循第 6.2 节中相同的设置来改变参数 γs 和 γt 。图 17 表明,无论选择何种内核类型,我们的方法 SWS 都可以始终优于最先进的方法。另一方面,由于参数 γs 和 γt 都不会影响我们的方法 SWS 生成具有三角和四次核的 STKDV 的效率,因此我们观察到,无论我们采用哪个 γs 和 γt,SWS 的响应时间都是相似的(参见图 17)。
6.4 渐进式可视化框架
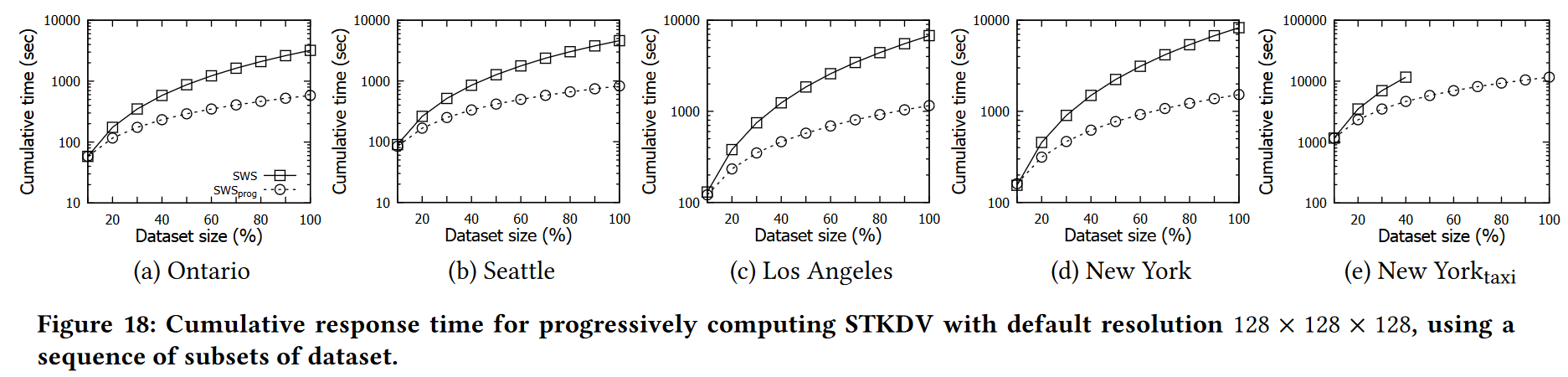
在本节中,我们继续测试使用渐进式可视化框架的效率。为了进行这个实验,我们用不同级别的子集对每个数据集进行随机采样(参见图 10),其中较大级别的子集覆盖较小级别的子集。在这里,我们选择一系列百分比,即 10%、20%、…、100%,来表示每个级别中子集与原始数据集相比的大小。在本实验中,我们按照上述级别顺序测量生成 STKDV 的累积时间。由于我们的方法 SWS 始终比以前的方法更有效,因此我们在本实验中仅比较该方法与该方法 SWSprog 的渐进版本的效率。在图 18 中,我们观察到 SWSprog 实现了更小的累积时间,因为该方法不需要从头开始重新计算所有密度值。
6.5 使用案例:将 STKDV 显示为随时间演变的热点地图
当我们为数据集生成STKDV后,我们可以将这个时空立方体显示为时间演化的热点图,这可以方便用户(例如地球科学家)可视化时间演化的热点(基于STKDV)。在这里,我们在本节中展示两个示例。
交通事故热点检测:图 19 显示了纽约曼哈顿上城区具有四个时间戳的随时间演变的交通事故热点地图,使用纽约交通事故数据集(参见表 3)。观察热点(橙色)可以在不同的时间戳中发生变化。例如,5月交通事故热点地区规模较12月和1月更大。这一现象表明,5月份应向这两个热点地区增派交警,以减少交通事故事件的发生。此外,交通专家还需要调查这一现象的深层原因。
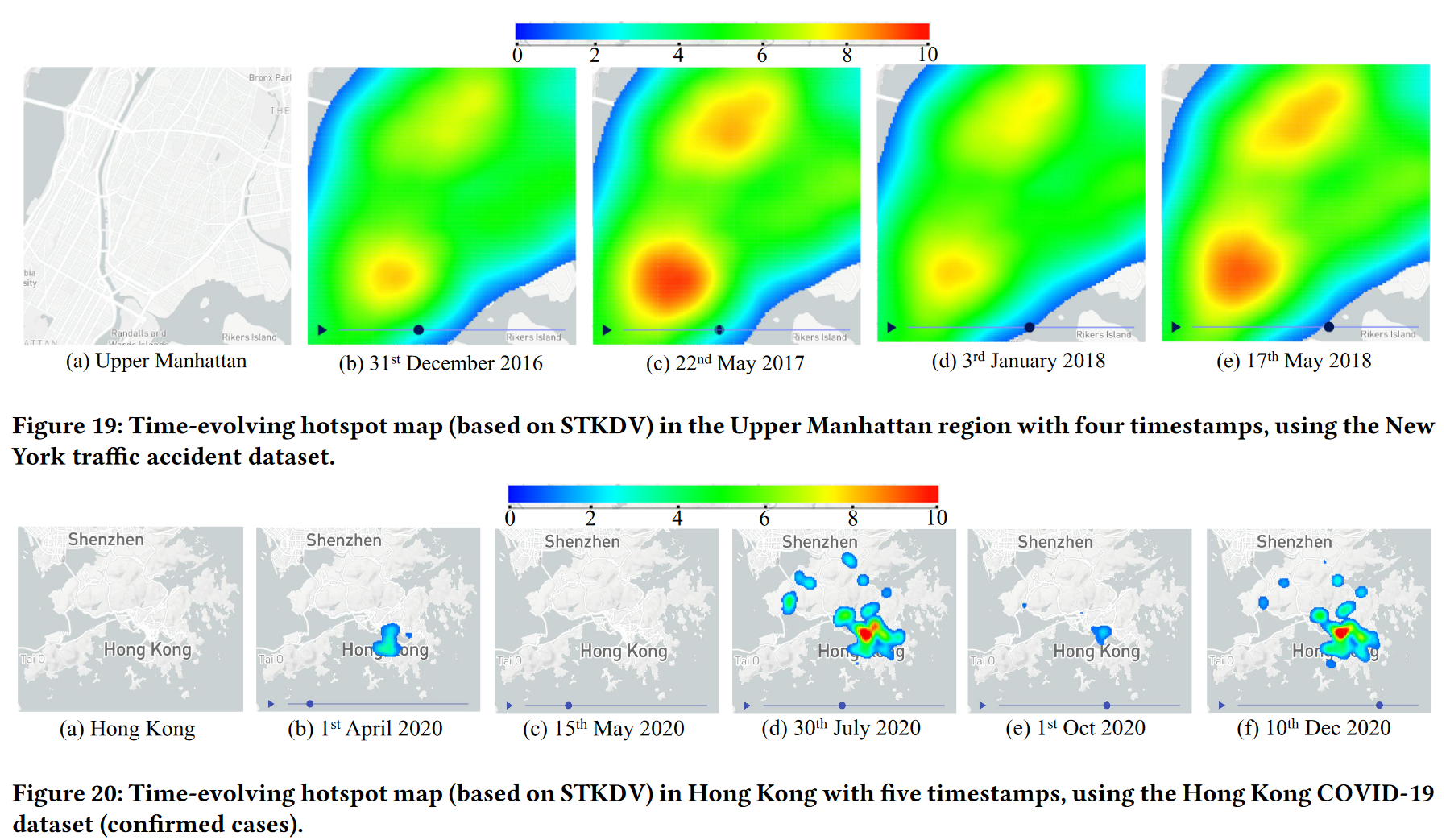
COVID-19 热点检测:在第二个示例中,我们使用香港政府的 COVID-19 开放数据集 [3] 展示了具有五个时间戳的香港随时间演变的 COVID-19 热点地图,该数据集存储了位置和位置信息。香港每例 COVID-19 确诊病例的时间。在图 20 中,观察到热点在不同时间戳中可能会发生显着变化。例如,2020年5月15日可能没有热点,2020年7月30日可能有大热点。此外,该工具可以正确显示香港的不同波浪,这与香港COVID-19确诊病例的趋势相符Kong(参见图 21)。

详细信息请参考Github仓库https://github。 com/STKDV/STKDV,其中我们提供了这两个具有 128 个时间戳的随时间演变的热点图(参见图 19 和图 20)及其实现。此外,我们还讨论了放大操作来探索不同地区和时间范围内的热点。
7 相关工作
核密度可视化(KDV)[14, 52]已广泛应用于不同领域,包括交通事故热点检测[61]、犯罪热点检测[13,29,66]和疾病爆发分析[4, 17]。然而,KDV 仅根据地理事件的空间位置生成可视化(参见公式 1),而忽略了事件时间。因此,最近不同领域的许多研究 [24,31,37,71] 也抱怨使用 KDV 的有效性。为了克服 KDV 的弱点,许多研究 [12,24,30–32,35,37,40,65,71]利用时空核密度可视化(STKDV),它结合了时间核来估计密度(参见. 方程 2),为立方体着色(参见图 3)。这些研究还表明,在不同的案例研究中,与传统的可视化工具(例如 KDV)相比,STKDV 可以取得优异的效果。然而,由于生成 STKDV 的时间复杂度很高,即 O(XYTn),现有方法无法扩展到大规模数据集。据我们所知,这是第一个从理论上降低这种耗时操作的时间复杂度的研究工作(参见表 4)。在本节中,我们总结了五个研究阵营,它们大多与这项工作相关。需要说明的是,技术报告中还回顾了更多相关研究(例如其他可视化方法)[15]。
基于范围查询的方法:回顾 2.2 节,我们可以根据获得约简集 Rq(参见方程 3)来计算 STKDV F b P (q, tq) 的核密度函数(参见方程 4)。因此,计算STKDV也可以转化为解决每个体素(q,tq)的范围查询问题。范围查询 [23,50,63] 在文献中得到了广泛的研究。在大多数现有方法中,kd-tree [11]和ball-tree [39]是最有效和最流行的方法,它们已被广泛用于有效解决低维数据集中的范围查询[42]。尽管基于范围查询的解决方案可以提高生成 STKDV 的效率,但这些方法(参见 RQSkd 和 RQSball)理论上不能降低生成 STKDV 的时间复杂度(参见表 4)。正如我们的实验所示,与我们的方法相比,这些方法无法扩展到大分辨率大小(参见图 11)、小 γs 和 γt(分别参见图 13 和 14)以及大数据集大小(参见图 15) SWS。
基于滑动窗口的方法:在数据库和数据挖掘社区中,已经开发了许多高效的基于滑动窗口的方法来支持不同的查询处理任务,包括聚合(例如,总和、计数、最大值、最小值等)[ 26, 36, 5355, 58],skyline [56],以及 top-k 查询 [59, 72],通过流数据。然而,现有方法都没有关注复杂的时空核密度函数 F b P (q, tq)(参见方程 2)。因此,现有的研究不能轻易扩展以有效计算 F b P (q, tq)。
函数逼近方法:许多研究人员提出逼近核密度函数 FP (q)(参见方程 1),以提高生成 KDV 的效率。雷卡等人。 [49] 和杨等人。 [62]建议使用快速高斯变换来高效且近似地计算 FP (q)。另一方面,陈等人。 [14,19,21],甘等人。 [25] 和格雷等人。 [28] 开发下限和上限函数以精确近似 FP (q)(参见方程 1)。然而,与 KDV 不同,STKDV F b P (q, tq)(参见方程 2)的核密度函数更为复杂,其中涉及空间核 Kspace(q, p) 和时间核 Ktime(tq, tp)。因此,是否可以修改这些方法以支持具有非平凡近似保证的 F b P (q, tq) 的快速计算仍然未知。
数据采样方法:为了有效生成 KDV,Zheng 等人。 [67-69]和菲利普斯等人。 [44-46]开发了先进的算法,首先对原始数据集进行采样,然后根据简化的数据集评估修改后的核密度函数。他们进一步表明,这种方法可以在原始核密度函数值 FP (q) 和每个像素 q 的输出结果之间提供非平凡的近似保证。然而,目前尚不清楚这种方法是否可以扩展以支持具有非平凡近似保证的 STKDV。需要说明的是,我们的渐进式可视化框架(参见第 5 节)可以与不同类型的数据采样方法相结合。
并行/分布式计算和基于硬件的方法:也有许多研究利用并行/分布式计算,例如MapReduce [67]和基于硬件的方法,例如GPU [34,43,64]和FPGA [27],进一步提高KDV的计算效率。最近,Saule 等人。 [51],霍尔等人。 [30] 和德尔梅勒等人。 [24]进一步采用并行计算来提高STKDV的生成效率。由于篇幅限制,我们在本文中重点关注单CPU设置,并将SWS与并行方法[24,30,51]的结合留给技术报告[15]。
8 结论
在本文中,我们研究了时空核密度可视化(STKDV),它已广泛应用于不同类型的应用,包括疾病暴发分析 [30, 65]、交通事故热点检测 [32, 37] 和犯罪热点检测[31]。然而,STKDV 是一种计算成本高昂的操作(时间为 O(XYT n)),无法扩展到大规模数据集。为了提高STKDV的计算效率,我们开发了基于滑动窗口的解决方案(SWS),理论上可以将时间复杂度降低到O(XY(T + n)),而不增加空间复杂度(即O(XYT + n) ))。通过将SWS与渐进式可视化框架相结合,我们可以进一步减少支持不同类型的数据采样方法(例如随机采样[44])的渐进式可视化的响应时间。我们的实验结果表明,我们的方法 SWS 的性能始终优于最先进的方法 2 倍到 24 倍。将来,我们将扩展 SWS 以支持 NKDV [18] 和其他类型的核函数(例如高斯核)。此外,我们还将开发 STKDV 的可视化系统来支持许多数据分析任务。此外,我们还将利用基于硬件的方法与SWS相结合的机会,这可以进一步提高生成STKDV的效率。
9 附录






参考文献