大语言模型系列:Transformer
- 一、前言
- 二、Transformer诞生的背景
- 三、Transformer横空出世
- 四、Transformer的基本结构
- 4.1. 编码器-解码器架构
- 4.2. 自注意力机制
- 4.3. 多头注意力机制
- 4.4. 前馈神经网络
- 4.5. 残差连接和层归一化
- 五、Transformer的工作原理
- 5.1输入嵌入
- 5.2位置编码
- 5.3编码器堆栈
- 5.4解码器堆栈
- 5.5输出生成
- 5.6编码器细节
- 5.6.1输入嵌入与位置编码
- 5.6.2自注意力机制
- 5.6.3多头注意力
- 5.7前馈神经网络
- 5.8 残差连接与层归一化
- 5.9 解码器细节
- 5.9.1 屏蔽机制
- 5.9.2 编码器-解码器注意力
- 6 Transformer的应用
- 6.1.机器翻译
- 6.1.1 Transformer在Google Translate中的应用
- 6.1.2Transformer提升翻译质量的关键因素
- 6.2 文本生成
- 6.2.1 GPT模型的发展历程
- 6.2.2 文本生成中的实际应用
- 6.3 情感分析
- 6.3.1 Transformer在情感分析中的应用
- 6.4 文本摘要
- 6.4.1 Transformer在文本摘要中的应用
- 6.5 对话系统
- 6.5.1Transformer在对话系统中的应用
- 6.6 信息检索
- 6.6.1 Transformer在信息检索中的应用
- 6.7 语言建模
- 6.7.1 Transformer在语言建模中的应用
- 6.8 代码生成
- 6.8.1 Transformer在代码生成中的应用
- 6.9. 生物信息学
- 6.9.1 Transformer在生物信息学中的应用
- 6.10 经济和金融
- 6.10.1 Transformer在经济和金融中的应用
- 6.11 医疗健康
- 6.11.1 Transformer在医疗健康中的应用
- 6.12. 教育与学习
- 6.12.1 Transformer在教育与学习中的应用
- 7 结语
一、前言
嗨,各位亲爱的读者们,欢迎来到我们的大语言模型系列之旅!今天,我们将潜入现代自然语言处理(NLP)领域的核心——Transformer。这不仅是一次技术探讨,更是一场脑洞大开的冒险。准备好你的爆米花,坐稳了,我们要开车了!
二、Transformer诞生的背景
故事得从深度学习的黄金时代开始。那时候,RNN(循环神经网络)和LSTM(长短期记忆网络)如日中天,几乎统治了整个NLP领域。但是,事情总不会一帆风顺,它们也有自己的“致命弱点”:时间依赖和计算复杂度。
想象一下,你正在阅读一本小说的结尾,却要不断翻到前几章确认细节,这就有点像RNN在处理长文本时的痛苦体验。而LSTM虽然有所改进,但计算开销仍然大得让人想“秃头”。
三、Transformer横空出世
2017年,Vaswani等人的一篇论文《Attention is All You Need》如同一道闪电划过夜空,Transformer模型就此登上历史舞台。这篇论文不仅提出了一种新的神经网络架构,更宣告了一种全新的处理序列数据的方式。
Transformer的核心思想是“注意力机制”,它能够让模型在处理序列数据时,专注于重要的信息,而不是无关的细节。这就像是一个超级助理,能在你讲述故事时,自动帮你记住关键情节。
四、Transformer的基本结构
Transformer的结构可以说是简洁明了,主要由以下几部分组成:
4.1. 编码器-解码器架构
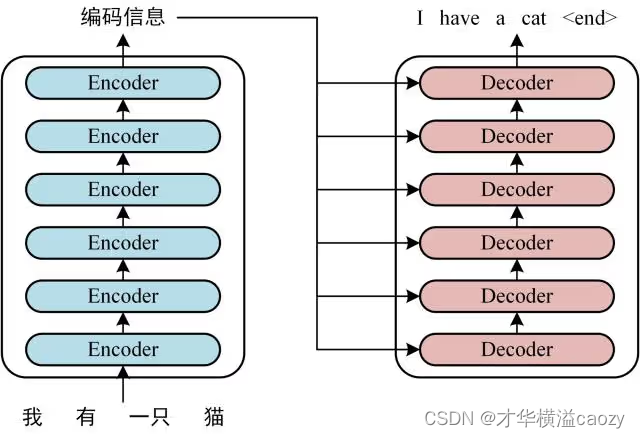
Transformer采用了编码器-解码器架构。编码器负责将输入序列转换成内部表示,解码器则将内部表示转换成输出序列。这种架构类似于你和朋友之间的对话:你说一句话(输入),朋友理解(编码),然后他做出回应(解码)。
4.2. 自注意力机制
自注意力机制是Transformer的秘密武器。它让每个输入元素都能“注意”到其他输入元素,从而捕捉到序列中的全局信息。就像是在阅读一篇文章时,你可以快速找到与当前段落相关的内容。
4.3. 多头注意力机制
多头注意力机制是自注意力机制的升级版。它通过多个注意力头来捕捉不同的特征。想象一下,你有一群侦探,每个人都从不同的角度调查同一个案件,最终汇总线索,得出结论。
4.4. 前馈神经网络
在每个编码器和解码器的内部,还有一个前馈神经网络,它负责进一步处理自注意力机制的输出。可以将其视为一个数据处理管道,确保信息得到充分加工。
4.5. 残差连接和层归一化
为了使训练更加稳定,Transformer采用了残差连接和层归一化。这就像是给模型装上了稳定器,使其在学习过程中不会“翻车”。
五、Transformer的工作原理
为了更好地理解Transformer,我们来模拟一下它的工作流程。
5.1输入嵌入
首先,输入序列通过嵌入层转换成向量表示。这就像是将文字转换成计算机能理解的语言。
5.2位置编码
由于Transformer不具备RNN那样的顺序信息处理能力,我们需要加入位置编码来标记每个输入元素的位置。这就像是在每个词上标记出它在句子中的位置。
5.3编码器堆栈
输入嵌入和位置编码的结合体被送入编码器堆栈。每个编码器层都经过自注意力机制和前馈神经网络的处理。通过层层堆叠,编码器逐渐提取出输入序列的全局特征。
5.4解码器堆栈
解码器的工作流程与编码器类似,但它还有一个额外的步骤:在自注意力机制之后,解码器还要对编码器的输出进行注意力操作。这就像是解码器在理解当前输出的同时,还要参考编码器生成的“线索”。
5.5输出生成
经过解码器层的处理后,最终的输出序列被生成。这个过程类似于你在回答朋友问题时,既要考虑当前话题,又要参考之前的对话内容。
让我们更深入地探索Transformer的工作原理,看看这些细节是如何在实际中运作的。
5.6编码器细节
5.6.1输入嵌入与位置编码
输入嵌入是将离散的词汇转换为连续的向量表示。对于每个输入单词,我们都有一个特定的嵌入向量,这些向量在训练过程中被学习。位置编码则是添加到嵌入向量上的额外信息,以表明单词在序列中的位置。这可以通过正弦和余弦函数来实现,以确保不同位置的编码是唯一的且具有相对位置关系。
公式如下:
对于位置 ( pos ) 和嵌入维度 ( i ):
[ PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{model}}}\right) ]
[ PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{model}}}\right) ]
这种方式保证了不同位置的编码之间有明确的关系,使得模型能够理解序列中的位置信息。
5.6.2自注意力机制
自注意力机制的核心在于计算输入序列中的每个单词与其他所有单词之间的关系。这通过三个矩阵来实现:查询(Q),键(K)和值(V)。每个输入单词都会生成这三个矩阵,这些矩阵可以捕捉不同的特征。
计算过程如下:
- 计算注意力得分:查询与键的点积,然后除以缩放因子(通常是 (\sqrt{d_k})),再通过softmax函数归一化,得到注意力权重。
- 加权求和:使用这些权重对值进行加权求和,得到每个单词的新的表示。
公式为:
[ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) V ]
5.6.3多头注意力
多头注意力机制通过引入多个“头”,每个头都有自己的查询、键和值矩阵,从而能够捕捉到不同的特征和模式。这些头的输出会被拼接起来,然后通过线性变换进行整合,得到最终的注意力输出。
公式为:
[ \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \ldots, \text{head}_h)W^O ]
其中 (\text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V))。
5.7前馈神经网络
每个编码器层除了自注意力机制外,还有一个前馈神经网络。这个网络由两个全连接层组成,中间使用ReLU激活函数。这部分的作用是进一步加工和提取特征,使信息表示更加丰富和抽象。
公式为:
[ \text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2 ]
5.8 残差连接与层归一化
为了使模型训练更加稳定,Transformer在每个子层(如自注意力和前馈神经网络)之后添加了残差连接和层归一化。残差连接将输入直接与子层输出相加,而层归一化则将输出归一化为零均值和单位方差,从而提高训练速度和稳定性。
公式为:
[ \text{LayerNorm}(x + \text{Sublayer}(x)) ]
5.9 解码器细节
解码器的工作原理与编码器类似,但有几个重要的区别:
5.9.1 屏蔽机制
解码器在自注意力机制中引入了屏蔽机制,以确保当前单词只能关注之前的单词,而不能看未来的单词。这对于生成任务尤为重要,确保生成的序列具有因果关系。
5.9.2 编码器-解码器注意力
解码器在处理输入时,会使用编码器生成的表示进行注意力计算,这使得解码器能够参考编码器提供的上下文信息。这部分注意力机制类似于自注意力机制,只不过查询来自解码器,而键和值来自编码器。
6 Transformer的应用
Transformer模型不仅仅是理论上的突破,它在多个实际应用中展现出了非凡的能力。让我们详细探讨一下Transformer在各个领域中的应用及其带来的革命性变化。
6.1.机器翻译
机器翻译是Transformer最早也是最成功的应用之一。在此之前,RNN和LSTM主导了机器翻译领域,但它们在处理长文本时表现不佳,难以捕捉长距离的依赖关系。而Transformer通过自注意力机制和并行处理,极大地改善了翻译质量。
6.1.1 Transformer在Google Translate中的应用
Google Translate在引入Transformer后,翻译质量得到了显著提升。传统的RNN模型在处理长句子时,信息容易丢失,导致翻译结果不准确。Transformer通过自注意力机制,可以有效地捕捉长距离的依赖关系,使得翻译结果更加准确和自然。
6.1.2Transformer提升翻译质量的关键因素
- 全局上下文理解:通过自注意力机制,Transformer可以同时考虑句子中所有词语的关系,从而更好地理解上下文。
- 并行计算:Transformer可以并行处理整个句子,而不是像RNN那样逐字处理,这极大地提升了翻译速度。
- 多头注意力:多头注意力机制使得模型能够从多个角度捕捉句子中的特征,提高了翻译的准确性。
6.2 文本生成
文本生成是另一个Transformer大显身手的领域。GPT(生成预训练变换模型)系列就是基于Transformer的文本生成模型。它们能够生成高质量的自然语言文本,从写诗到编程代码,无所不能。
6.2.1 GPT模型的发展历程
- GPT-1:初代GPT使用了无监督预训练和有监督微调的方式,在多个NLP任务上表现优异。
- GPT-2:GPT-2在模型规模和数据量上进行了大幅度提升,能够生成连贯且富有创意的文本。
- GPT-3:GPT-3进一步扩大了模型规模,达到了1750亿参数,能够完成更复杂和多样化的任务,如写作、编程、翻译等。
6.2.2 文本生成中的实际应用
- 内容创作:GPT模型可以帮助写作,生成文章、小说、诗歌等,极大地提高了内容创作的效率。
- 对话系统:基于Transformer的对话系统能够进行自然流畅的对话,为用户提供智能的聊天体验。
- 编程辅助:GPT-3可以生成代码,帮助程序员编写和调试程序,提高开发效率。
6.3 情感分析
情感分析是NLP中的一个重要应用领域,通过分析文本中的情感信息,模型可以帮助企业了解客户反馈,优化产品和服务。Transformer在情感分析中表现出色,能够准确地捕捉文本中的情感特征。
6.3.1 Transformer在情感分析中的应用
- 客户反馈分析:通过对客户评论、反馈和社交媒体上的评论进行情感分析,企业可以了解用户的情感倾向,及时调整产品和服务。
- 市场调研:情感分析可以帮助企业进行市场调研,了解消费者对不同产品和品牌的态度。
- 舆情监测:通过分析社交媒体和新闻中的情感信息,企业和政府可以及时监测和应对公共舆情。
6.4 文本摘要
在信息爆炸的时代,快速获取关键信息变得尤为重要。Transformer可以自动生成文本摘要,帮助我们在短时间内抓住重点。就像是一个超级速记员,帮你浓缩出文章的精华。
6.4.1 Transformer在文本摘要中的应用
- 新闻摘要:自动生成新闻文章的摘要,帮助读者快速了解新闻的核心内容。
- 文档摘要:对长篇文档进行摘要提取,帮助用户快速浏览和理解文档内容。
- 会议纪要:自动生成会议纪要,记录会议的主要讨论点和决策,提高会议效率。
6.5 对话系统
Transformer在对话系统中的应用也十分广泛。无论是客服机器人还是智能助理,Transformer都能提供自然流畅的对话体验。就像是一个贴心的小助手,随时为你解答疑问。
6.5.1Transformer在对话系统中的应用
- 智能客服:基于Transformer的智能客服系统能够处理客户的咨询,提供准确和及时的回复,提高客户满意度。
- 虚拟助手:智能助理如Siri、Alexa等,利用Transformer技术进行自然语言理解和生成,提供多种服务和信息查询。
- 社交聊天:社交平台上的聊天机器人,利用Transformer技术与用户进行互动,为用户提供娱乐和陪伴。
6.6 信息检索
信息检索是搜索引擎和问答系统的核心技术。Transformer通过其强大的特征提取能力,可以显著提升信息检索的准确性和效率。
6.6.1 Transformer在信息检索中的应用
- 搜索引擎:利用Transformer技术,搜索引擎可以更好地理解用户查询意图,提供更相关的搜索结果。
- 问答系统:基于Transformer的问答系统可以准确回答用户的问题,提供精确的信息和建议。
- 文档检索:在海量文档中,Transformer可以快速检索到相关内容,提高信息查找效率。
6.7 语言建模
语言建模是NLP中的基础任务之一,旨在预测给定序列中的下一个单词。Transformer通过自注意力机制,可以更好地捕捉上下文信息,提高语言建模的性能。
6.7.1 Transformer在语言建模中的应用
- 语音识别:通过语言建模,语音识别系统可以提高识别准确性,理解用户的语音输入。
- 拼写纠错:语言建模可以帮助拼写纠错系统识别和纠正拼写错误,提高文本的准确性。
- 文本预测:在输入法和文本编辑器中,语言建模可以提供智能的文本预测和补全功能,提高输入效率。
6.8 代码生成
Transformer不仅在自然语言处理方面表现出色,在代码生成和编程辅助方面也展现了强大的能力。通过学习大量的代码数据,Transformer可以自动生成代码,帮助程序员提高开发效率。
6.8.1 Transformer在代码生成中的应用
- 自动补全:在代码编辑器中,基于Transformer的自动补全功能可以预测并补全代码,提高编程效率。
- 代码生成:根据自然语言描述,Transformer可以生成相应的代码,实现从需求到代码的自动转换。
- 代码修复:通过分析代码错误,Transformer可以自动生成修复代码,帮助程序员快速解决问题。
6.9. 生物信息学
生物信息学是一个跨学科领域,涉及生物学、计算机科学和统计学。Transformer在生物信息学中的应用,主要体现在基因序列分析和蛋白质结构预测等方面。
6.9.1 Transformer在生物信息学中的应用
- 基因序列分析:通过分析基因序列,Transformer可以识别基因突变和结构变化,为疾病研究和治疗提供支持。
- 蛋白质结构预测:Transformer可以预测蛋白质的三维结构,帮助研究人员理解蛋白质功能和相互作用。
- 药物发现:通过分析生物数据,Transformer可以辅助药物发现和开发,提高新药的研发效率。
6.10 经济和金融
经济和金融领域的数据量巨大且复杂,Transformer可以通过分析大量的金融数据,提供预测和决策支持。
6.10.1 Transformer在经济和金融中的应用
- 股票价格预测:通过分析历史数据和市场动态,Transformer可以预测股票价格走势,提供投资建议。
- 金融文本分析:Transformer可以分析金融报告、新闻和社交媒体上的信息,提供市场情绪分析和投资机会。
- 风险管理:通过对金融数据的深入分析,Transformer可以识别潜在的风险,帮助企业进行风险管理和决策。
6.11 医疗健康
医疗健康领域的数据同样丰富且复杂,Transformer在医疗健康中的应用,主要体现在医疗文本分析、疾病预测和个性化治疗等方面。
6.11.1 Transformer在医疗健康中的应用
- 医疗文本分析:通过分析电子病历、医生笔记和医学文献,Transformer可以提取关键信息,辅助医生进行诊断和治疗。
- 疾病预测:通过分析患者的病史和基因数据,Transformer可以预测疾病的发生和发展,为早期干预提供支持。
- 个性化治疗:根据患者的具体情况,Transformer可以推荐个性化的治疗方案,提高治疗效果。
6.12. 教育与学习
教育与学习领域的应用,Transformer可以通过自然语言处理技术,提供智能辅导、自动评分和知识图谱构建等服务。
6.12.1 Transformer在教育与学习中的应用
- 智能辅导:基于Transformer的智能辅导系统可以回答学生的问题,提供学习建议和辅导,提高学习效果。
- 自动评分:通过分析学生的作业和考试答案,Transformer可以自动进行评分,提供反馈和建议。
- 知识图谱:通过构建知识图谱,Transformer可以将知识点之间的关系可视化,帮助学生更好地理解和掌握知识。
7 结语
Transformer的出现无疑是自然语言处理领域的一次革命。通过自注意力机制和并行计算,Transformer不仅解决了RNN和LSTM的许多问题,还开创了新的研究方向和应用场景。从机器翻译到文本生成,从情感分析到信息检索,Transformer的应用几乎遍布各个领域,为我们的生活带来了诸多便利。
随着技术的不断进步,Transformer将继续在更多领域发挥作用,为我们带来更多惊喜和可能性。希望大家在阅读完这篇博客后,对Transformer有了更深入的了解,也期待在未来的科技发展中,看到更多基于Transformer的创新应用。谢谢大家的阅读,我们下次再见!
如有帮助,还请伸出手指点个关注再走吧,你的支持是我持续创作的动力。不吝赐教,欢迎留言分享你的见解和建议,让我们一起交流进步!