读AI新生:破解人机共存密码笔记07概念和理论
news2026/2/18 17:47:45
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1844859.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
深度学习之计算机视觉
神经网络简介
全连接层和卷积层的根本区别在于权重在中间层中彼此连接的方式。图5.1描述了全连接层或线性层是如何工作的。 在计算机视觉中使用线性层或全连接层的最大挑战之一是它们丢失了所有空间信息,并且就全连接层使用的权重数量而言复杂度太高。例如…
电商爬虫API的定制开发:满足个性化需求的解决方案
一、引言
随着电子商务的蓬勃发展,电商数据成为了企业决策的重要依据。然而,电商数据的获取并非易事,特别是对于拥有个性化需求的企业来说,更是面临诸多挑战。为了满足这些个性化需求,电商爬虫API的定制开发成为了解决…

Spring Boot集成tensorflow实现图片检测服务
1.什么是tensorflow?
TensorFlow名字的由来就是张量(Tensor)在计算图(Computational Graph)里的流动(Flow),如图。它的基础就是前面介绍的基于计算图的自动微分,除了自动帮你求梯度之外,它也提供了各种常见的操作(op,…

使用 jQuery 选择器获取页面元素,然后利用 jQuery 对象的 css() 方法设置其 display 样式属性,从而实现显示和隐藏效果。
在页面中显示电影排行榜 当单击“(收起)”链接时,排行榜中后三项的电影名称隐藏而且链接的文本更改为“(展开) ” 当单击“(展开)”的链接时,后三项的电影名称重新显示且链接的文本…

基于微信共享充电桩小程序毕业设计作品成品(3)开发技术文档_充电桩小程序前端技术栈
后台管理系统文件
所在路径:后台源码ht目录是后台
绿色显示的是系统框架,不要动
位置程序名说明源码根目录login.php后台登录页面源码根目录check_u_login.php后台登录处理程序ht 后台根目录index.php后台首页left.php后台左侧菜单u_logout.php退出登…

2024广东省职业技能大赛云计算赛项实战——OpenStack搭建
OpenStack搭建
前言
搭建采用双节点安装,即controller控制节点和compute计算节点。 CentOS7 系统选择 2009 版本:CentOS-7-x86_64-DVD-2009.iso 可从阿里镜像站下载:https://mirrors.aliyun.com/centos/7/isos/x86_64/
OpenStack使用竞赛培…
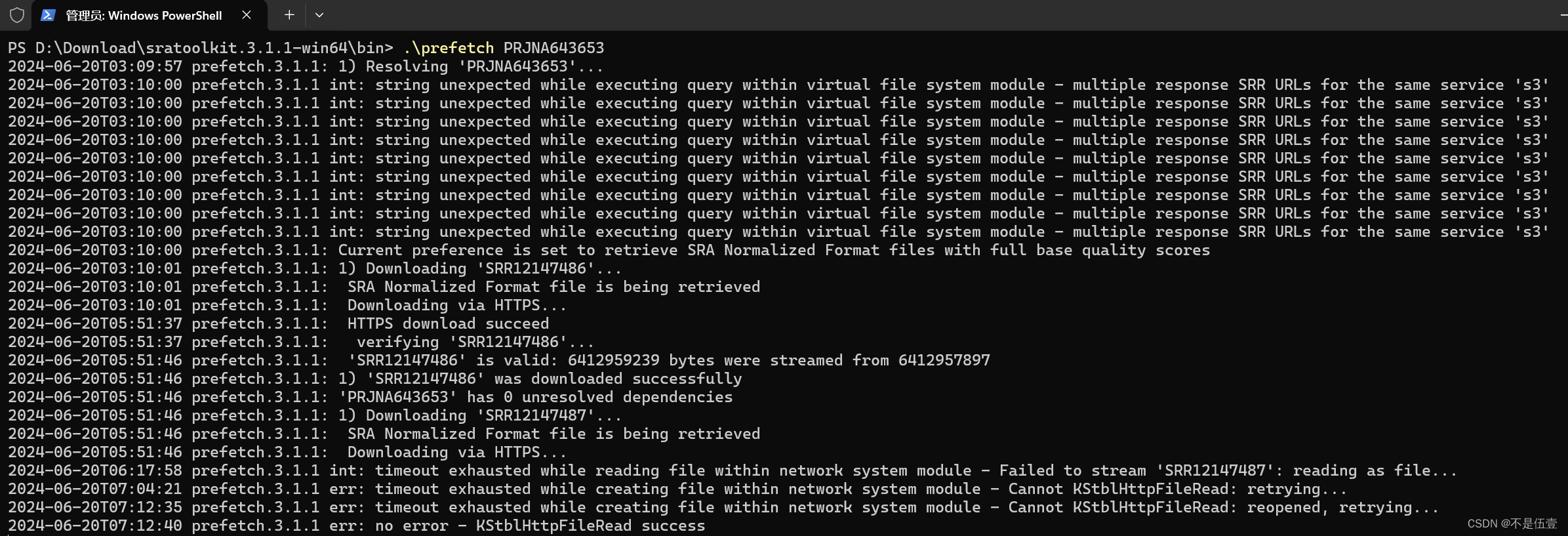
【NCBI】SRA toolkit安装及使用-WindowsLinux版本
文章目录 Windows版本下载安装- 设置环境变量使用下载SRA Linux版本下载安装使用 由于市面上的文章介绍SRA toolkit基本上都是基于Linux,而在windows下运行SRA toolkit基本上可以达到相同的效果且更为方便,故本文将分别阐明在Windows和Linux环境下SRA to…

【DAO】DAOS在后傲腾时代的发展策略
视频:DAOS在后傲腾时代的发展策略_哔哩哔哩_bilibili
代替方案 WAL (write ahead log)
在架构上用DRAM 代替PMEM,如图 变化是:
傲腾方案: PMEM 数据写到内存就完成"落盘",是一个原…

10年265倍!动态展示全球第一股英伟达10年股价走势
英伟达在过去十年的股价走势展示了其在市场上的强劲表现和显著增长。自1999年上市以来,英伟达的股价经历了多次显著的涨幅,并在2024年达到了历史新高。
从2023年6月的数据来看,英伟达的股价为386.54美元/股,市值为9548亿美元。然…

探寻Scala的魅力:大数据开发语言的入门指南
大数据开发语言Scala入门 一、引言1.1 概念介绍1.2 Scala作为大数据开发语言的优势和应用场景1.2.1 强大的函数式编程支持1.2.2 可与Java无缝集成1.2.3 高性能和可扩展性1.2.4 大数据生态系统的支持 二、Scala基础知识2.1. Scala简介:2.1.1 Scala的起源和背景2.1.2 …

django学习入门系列之第三点《CSS基础样式介绍1》
文章目录 高度和宽度块级标签|行内标签的转换字体和颜色往期回顾 高度和宽度 如果在块级标签内,单独定义高度的话,宽度会默认拉满 使用百分比的时候 如果是块级标签,宽度可以用百分比,高度用不了(使用起来没效果&…

前后端分离的后台管理系统源码,快速开发OA、CMS网站后台管理、毕业设计项目
那有没有一款软件解-决这种现状呢?答案是肯定的。引入我们的软件——eladmin。 介绍
ELADMIN,一个简单且易上手的 Spring boot 后台管理框架,已发布 Mybatis-Plus 版本,为开发者提供了一个全-面、高-效的解-决方案。 特点 高-效率:前后端完全分离,项目简单可配,内置代码…

MySQL:表的增删查改
文章目录 1.Create(创建)2.Retrieve(读取、查询)2.1 SELECT 列2.2 WHERE 子句2.3 结果排序(order by)2.4 筛选分页结果(limit、offset)2.5 Update更新2.6 Delete删除2.7 去重 3.聚合函数3.1 聚合函数的基本使用3.2group by子句的使用(分组查询) 增删查改:: Create(创…
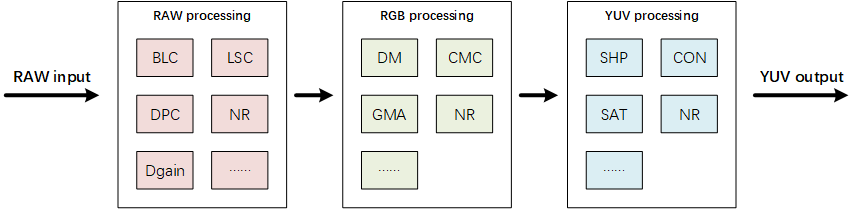
自动驾驶学习-车载摄像头ISP(2)
背景
智能驾驶ISP(Image Signal Processor,图像信号处理器)在自动驾驶和辅助驾驶系统中扮演着至关重要的角色。
典型的ISP通常会对摄像头输出的RAW数据先做黑电平矫正(BLC)、坏点矫正(DPC)、数…
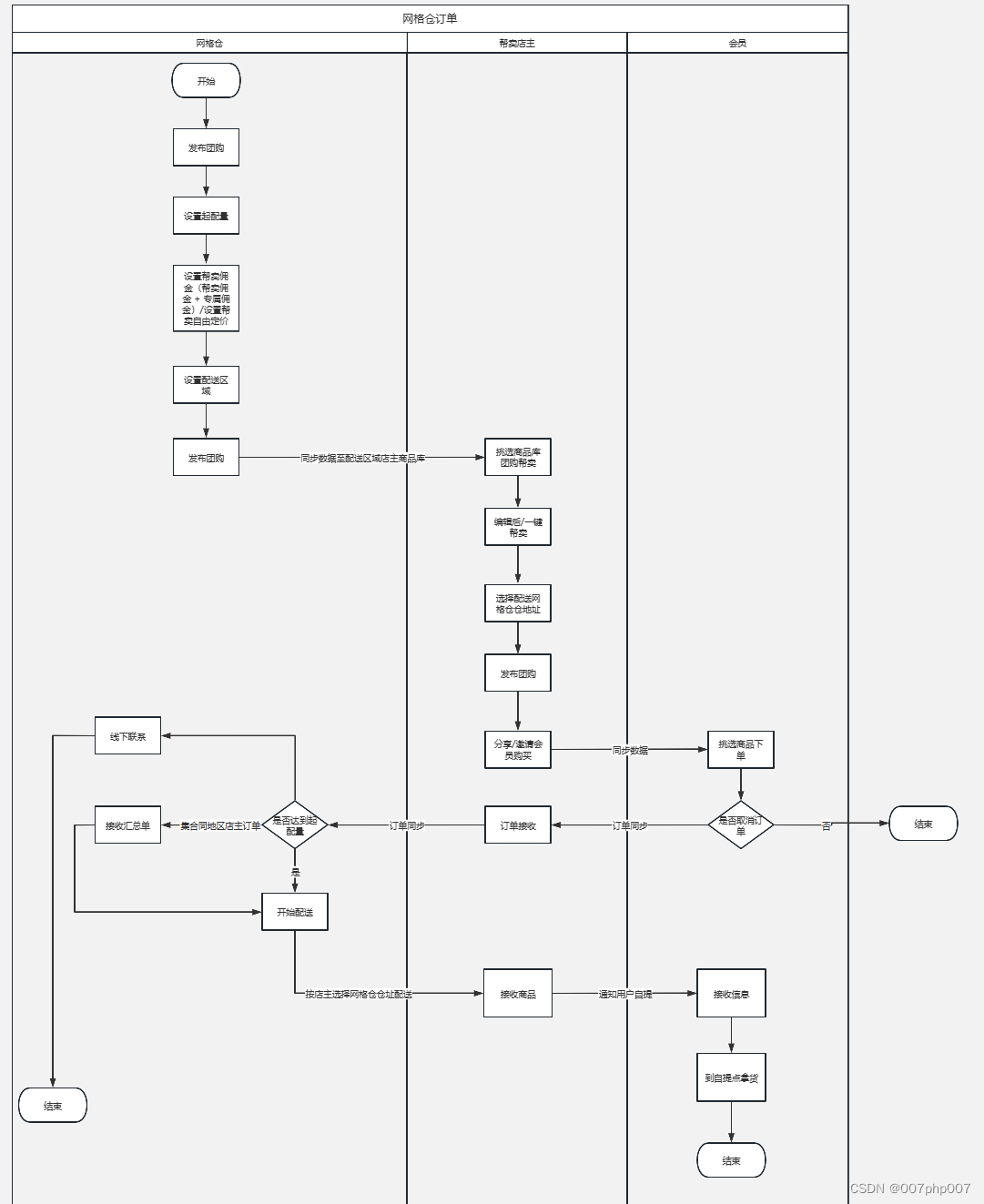
社区团购多级分销流程:从入门到精通实践
随着电商平台和社交媒体的迅速发展,社区团购逐渐成为了一种新兴的购物模式。通过多级分销体系,社区团购有效地扩大了销售网络,提高了商品的流通速度和覆盖范围。本文将详细解析社区团购多级分销的流程,帮助你从入门到精通。 ### 一…
2748. 美丽下标对的数目(Rust暴力枚举)
题目
给你一个下标从 0 开始的整数数组 nums 。如果下标对 i、j 满足 0 ≤ i < j < nums.length ,如果 nums[i] 的 第一个数字 和 nums[j] 的 最后一个数字 互质 ,则认为 nums[i] 和 nums[j] 是一组 美丽下标对 。
返回 nums 中 美丽下标对 的总…

STM32单片机SPI通信详解
文章目录
1. SPI通信概述
2. 硬件电路
3. 移位示意图
4. SPI时序基本单元
5. SPI时序
6. Flash操作注意事项
7. SPI外设简介
8. SPI框图
9. SPI基本结构
10. 主模式全双工连续传输
11. 非连续传输
12. 软件/硬件波形对比
13. 代码示例 1. SPI通信概述
SPI&#x…
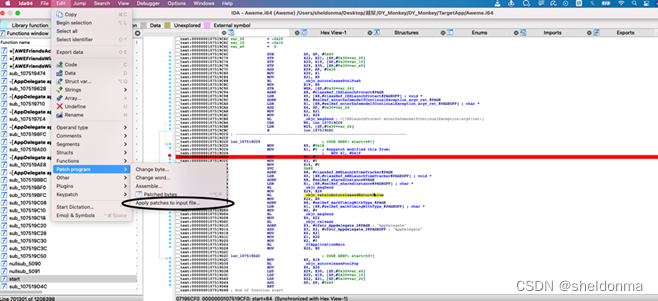
IOS逆向分析—终极详细(三)
IOS逆向分析—终极详细(三) 前言一、逆向分析是什么?二、IDA分析1.下载并安装IDA2.安装插件3.加载二进制4.代码分析5.其它 总结 前言 本文是个人完成对IOS上APP分析的整个过程,当然对于不同的机型还会遇到不同的情况,谨…
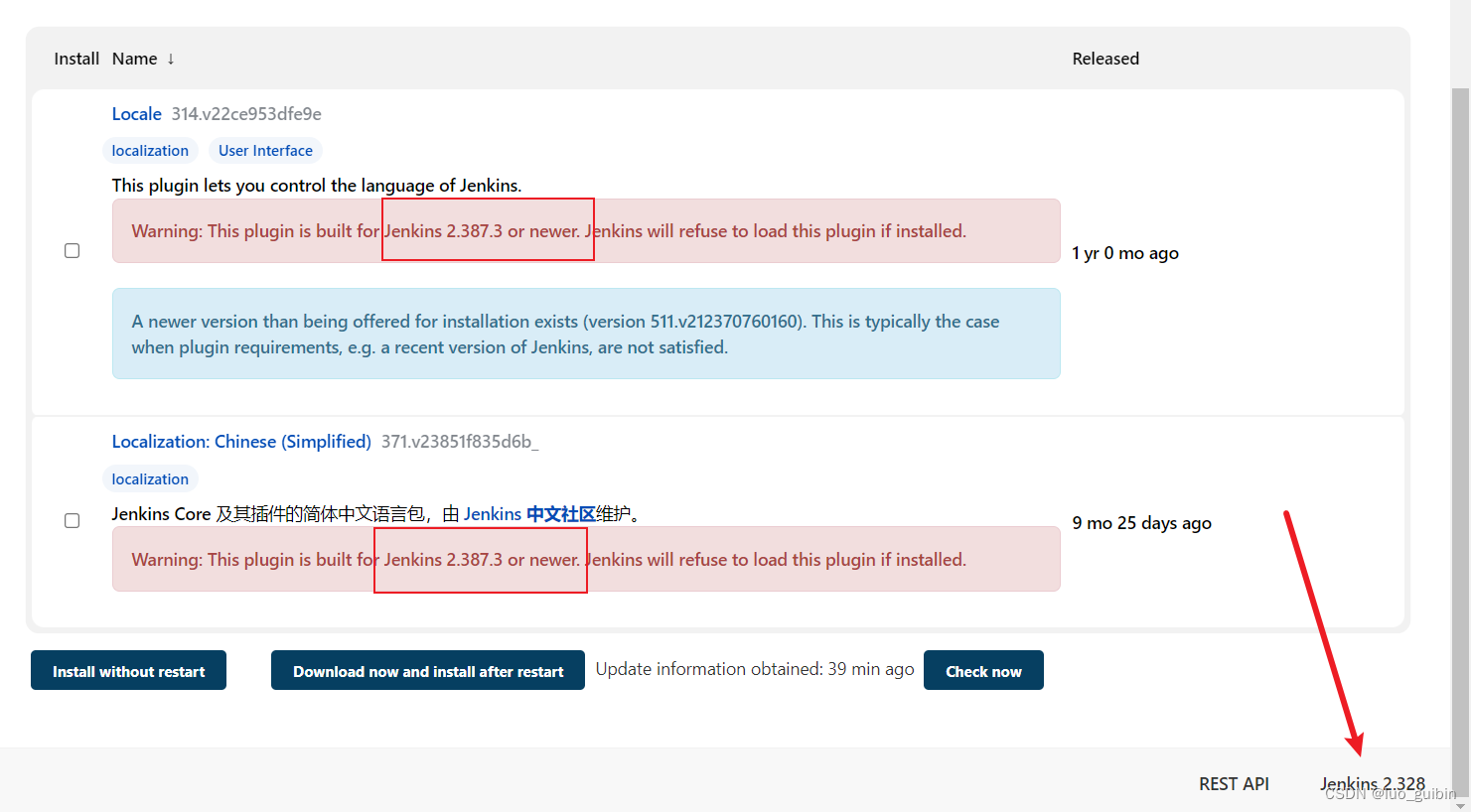
Jenkins+gitee流水线部署springboot项目
目录
前言
一、软件版本/仓库 二、准备工作
2.1 安装jdk 11
2.2 安装maven3.9.7
2.3 安装docker
2.4 docker部署jenkins容器 三、jenkins入门使用
3.1 新手入门
3.2 jenkins设置环境变量JDK、MAVEN、全局变量
3.2.1 jenkins页面
3.2.2 jenkins容器内部终端
3.2.3 全…
从零开始:使用ChatGPT快速创作引人入胜的博客内容
随着科技的飞速发展,人工智能逐渐渗透到我们生活的各个领域。无论是商业、教育还是娱乐,AI技术都在以惊人的速度改变着我们。特别是在内容创作领域,人工智能正发挥着越来越重要的作用。今天,我将和大家分享如何从零开始࿰…