OK,各位未来的高级程序员们,大家好,今天我们来讲解一下二叉树这个部分的第二种存储结构---------链式存储结构,相信大家对这部分内容已经很期待了,但是,这里我们在开讲之前,要先补充一个知识,这个知识本应该是出现在前面一篇博客的内容,之前由于种种原因,就没有写上,那么,现在在这里给大家补上,请谅解。
补充:TOP-K问题:N个数中找最大的前K个。
方法1:建立一个N个数的大堆,空间复杂度:O(N),
然后再PopK次 时间复制度:O(K*logN)。
方法1的这种办法是我们大家最容易想到的一种办法,这个方法我们虽然看不到有什么问题,但是大家不妨想一想,如果N是10亿呢,这种情况下我们再去看方法1,是不是就有点问题了,一下开创10亿个空间,这样的话空间就太大了,空间无法得到一个很好的使用,甚至还会造成一定的空间浪费的情况,因此,我们在这里不推荐使用方法1,用方法2:
方法2:我们可以先将N个数(这里我们将这N个数放在一个文件中,这里我们决定采用文件的方法来实现)中的前K个数拷贝到程序中去,让其形成一个小堆(这里我们采用的是建小堆的方式来完成TOP-K问题的),将这K个数建好一个小堆之后,我们这时候再从文件的第K+1个数开始往后遍历,让它们分别与刚刚建成的小堆的堆顶元素进行比较,若比堆顶元素小,让文件中的下一个元素进行比较,反之,则这个元素替代堆顶元素,成为新的堆顶元素,由于是小堆,必须遵守小堆的规则,采用向下排序建堆的方法来确定这个新的堆顶元素的真正位置,当文件中的所有元素全部比较完之后,这样,小堆中的K个元素就是N个数中最大的前K个数了。
这里再给大家说一下我在第一次接触这个知识的时候,我的一个疑问,就是说如果N个数中的第4大的元素挡在堆顶咋办?那么这样的话,数都进不去了,其实按照我们讲的方法2来解决TOP-K问题的话是不会存在这样的问题的,因为前K个数建立的是一个小堆,小堆的特点是堆顶元素是最小的元素,如果N个数中的第4大的元素挡在堆顶的话,就足以说明N个数中的第1大的元素,第2大的元素,第3大的元素均已经在小堆中了,因此,我们不需要去担心这种情况的发生。
(1).建立数据:
创建1000000个数据并将这1000000个数据全部放在"deta.txt"这个文件中。
void CreateData()
{
int n = 1000000;
srand(time(0));//这里我们使用rand函数来生成1000000个随机数据,由于rand函数生成的数不是真正的随机数,我们这里给其一个种子,大家如果有还不知道rand这个函数的话,可以通过这个链接去了解一下这个函数。
const char* file = "deta.txt";
FILE* fin = fopen(file, "w");//打开文件,并设置成"w"的模式。
if (fin == NULL)
{
perror("fopen error");
return 0;
}
for (size_t i = 0; i < n; ++i)
{
int x = rand() % 1000000;//随机生成1000000个数据。
fprintf(fin, "%d\n", x);//用fprintf函数将这1000000个数据一一写入到"deta.txt"这个文件中。
}
fclose(fin);//关闭文件。
}
rand函数:rand - C++ Reference![]() https://legacy.cplusplus.com/reference/cstdlib/rand/?kw=rand
https://legacy.cplusplus.com/reference/cstdlib/rand/?kw=rand
fprint函数:fprintf - C++ Reference![]() https://legacy.cplusplus.com/reference/cstdio/fprintf/?kw=fprintf
https://legacy.cplusplus.com/reference/cstdio/fprintf/?kw=fprintf
大家可以通过上面的两个链接去了解一下这两个函数。
(2).完成TOP-K:
void TopK()
{
int k = 10;//我们这里选出N个数据中的最大的前10个元素。
int* tmp = (int*)malloc(sizeof(int) * k);//开创10个空间的数组。
if (tmp == NULL)//判断数组是否开创成功。
{
perror("malloc fail");
return;
}
const char* file = "deta.txt";
FILE* fout = fopen(file, "r");//打开文件,并设置成"r"的模式。
for (int i = 0; i < k; i++)//通过上面我们讲的逻辑,这里我们要将上面的那个函数中生成的1000000个数中的前10个元素写入到"deta.txt"文件中。
{
fscanf(fout, "%d", &tmp[i]);//这里我们使用fscanf函数来向数组中写入元素。
}
for (int i = (k - 1 - 1) / 2; i >= 0; i--)//将数组中的10个元素排列成小堆。
{
AdjustDown(tmp, k, i);
}
int x = 0;
while (fscanf(fout, "%d", &x) > 0)//我们将剩下的元素依次与堆顶元素进行比较。
{
if (x > tmp[0])//如果有某个元素比堆顶元素大,这个元素就替代堆顶元素,成为新的堆顶元素,并建成新的小堆。
{
tmp[0] = x;//替代堆顶元素。
AdjustDown(tmp, k, 0);//建成新的小堆。
}
}
}好的,以上就是我们补充前面的内容,接下来,我们现在开始进入我们今天的正题:链式存储结构。
一.链式存储结构:
接下来我们要讲的内容它适用于不完全二叉树结构,也就是普通的二叉树结构。
1.遍历:(1).前序遍历:根 左子树 右子树(要求任意一棵树都按照这样的方式去访问)
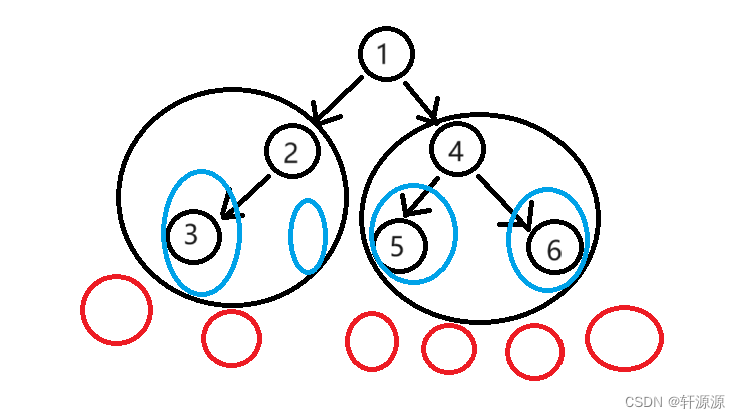
上面的这幅图就是前序遍历的过程图:图有点抽象,我来为大家解释一下:
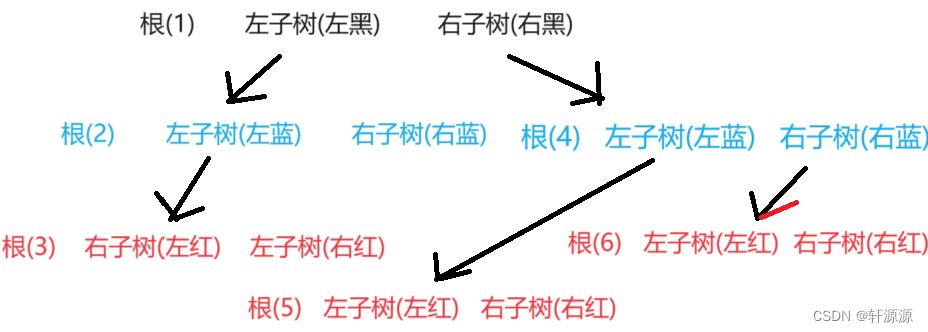
前序遍历的过程其实并不难,就如上图所画的那样,将二叉树分为根,左子树,右子树后,再分别将左右子树均看成一棵树,再分,直到遇到空指针就可以停下了,这个遍历过程其实就和套娃是一个道理,要完成这个过程靠的是递归的思想,当我们完成这一步时(也就是我们遇到空指针的时候),就会返回到上一个递归这个函数的位置,大家一定要了解递归的全过程,递归是我们必须要掌握的一个知识,它的重要程度堪比5颗星。
(下面的操作可能会有一段繁琐,但是只要大家认认真真看,相信就绝对可以理解)
为了方便大家的理解,我在这里给大家细细的过一遍,过一遍之后,那么后面的中序遍历和后序遍历就不细细的写了,过程基本和前序遍历相同,前序遍历在访问的过程中,我们先访问的是根,也就是1,然后再访问左子树,对于左子树,我们也是相同的操作,先访问根,也就是2,然后再访问以2为根的这棵子树的左子树,也是相同的操作,先访问根,也就是3,然后再访问3为根的这棵子树的左子树,由于以3为根的这棵子树的左子树为空,无法再继续进行拆分,因此,递归结束,返回,再访问3为根的这棵子树的右子树,由于访问3为根的这棵子树的右子树也为空,无法再继续进行拆分,因此,递归结束,返回,那么,到这里,就说明我们将以2为根的这棵子树的左子树全部都访问完了,接下来,我们就可以来访问以2为根的这棵子树的右子树了,由于以2为根的这棵子树的有子树为空,无法再继续进行拆分,因此,递归结束,返回,到这里,就说明我们将以1为根的这棵子树的左子树全部都访问完了,接下来,我们就可以来访问以1为根的这棵子树的右子树了,访问右子树,也是相同的操作,先访问根,也就是4,然后再访问4为根的这棵子树的左子树,也就是5,然后再访问以5为根的这棵子树的左子树,也是相同的操作,由于以5为根的这棵子树的左子树为空,无法再继续进行拆分,因此,递归结束,返回,到这里,就说明我们将以4为根的这棵子树的左子树全部都访问完了,接下来,我们就可以来访问以4为根的这棵子树的右子树了,先访问根,也就是6,然后再访问6为根的这棵子树的左子树,由于以6为根的这棵子树的左子树为空,无法再继续进行拆分,因此,递归结束,返回,接下来,我们就可以来访问以6为根的这棵子树的右子树了,访问右子树,由于以6为根的这棵子树的右子树为空,无法再继续进行拆分,因此,递归结束,返回,到这里,就说明我们将以4为根的这棵子树的右子树全部都访问完了,至此,以1为根的这棵子树的右子树全部都访问完了,遍历结束。

(N表示的是NULL)。
(2).中序遍历:左子树 根 右子树

(3).后序遍历:左子树 右子树 根

2.实现二叉树中一些对应的各个操作:
(1).定义一个二叉树的类型(实际上就是定义一个结构体,因为是二叉树,每一个节点都有两个指针,一个指针指向左子树,另一个指针指向右子树,另外还需要一个存放元素的变量。):
typedef int BTDataType;
typedef struct BinaryTreeNode
{
BTDataType _data;//定义一个变量,来存放数据。
struct BinaryTreeNode* _left;//指向左子树的指针。
struct BinaryTreeNode* _right;//指向右子树的指针。
}BTNode; (2).创建二叉树的一个节点:
我们这里之所以写这一步操作,是因为后面我们在进行二叉树的插入操作时,需要建立节点。
BTNode* BuyNode(int x)
{
BTNode* node = (BTNode*)malloc(sizeof(BTNode));//建立一个新的节点。
if (node == NULL)//判断是否建立节点成功。
{
perror("malloc fail");
return NULL;
}
node->_data = x;//我们这个函数传过来的参数就是我们要向开创的新的节点中存放的值。
node->_left = NULL;//指针一般我们都将其初始化为NULL。
node->_right = NULL;
return node;
}(3).二叉树节点的初始化:
void BinaryTreeInit(BTNode* root)
{
assert(root);//首先要看一下root指针是否接收到了传过来的地址。
root->_data = 0;
root->_left = NULL;
root->_right = NULL;
}(4).二叉树前序遍历:
通过上述的讲解过程我们可以知道,前序遍历我们这里是通过递归操作来实现的。
void BinaryTreePrevOrder(BTNode* root)
{
if (root == NULL)//既然知道我们这里进行的是递归操作,那么就必须得有递归的结束条件,由上可知,递归的结束条件就是我们遇到空树的时候,这一趟递归就可以结束了。
{
printf("N ");
return;
}
printf("%d ", root->_data);//因为我们的这一步操作实现的是前序遍历,前序遍历的访问顺序是根然后是左子树再然后是右子树,因此,我们这里先访问根。
BinaryTreePrevOrder(root->_left);//再去遍历左子树。
BinaryTreePrevOrder(root->_right);//最后去遍历右子树。
}(5).二叉树中序遍历:
void BinaryTreeInOrder(BTNode* root)
{
if (root == NULL)//既然知道我们这里进行的是递归操作,那么就必须得有递归的结束条件,由上可知,递归的结束条件就是我们遇到空树的时候,这一趟递归就可以结束了。
{
printf("N ");
return;
}
BinaryTreePrevOrder(root->_left);//因为我们的这一步操作实现的是中序遍历,中序遍历的访问顺序是左子树然后是根再然后是右子树,因此,我们这里先访问左子树。
printf("%d ", root->_data);//然后再访问根。
BinaryTreePrevOrder(root->_right);//最后再访问右子树。
}(6).二叉树后序遍历:
void BinaryTreePostOrder(BTNode* root)
{
if (root == NULL)//既然知道我们这里进行的是递归操作,那么就必须得有递归的结束条件,由上可知,递归的结束条件就是我们遇到空树的时候,这一趟递归就可以结束了。
{
printf("N ");
return;
}
BinaryTreePrevOrder(root->_left);//因为我们的这一步操作实现的是后序遍历,后序遍历的访问顺序是左子树然后是右子树再然后是根,因此,我们这里先访问左子树。
BinaryTreePrevOrder(root->_right);//然后我们再去访问右子树。
printf("%d ", root->_data);//最后我们访问根。
}(7).二叉树节点个数:
int BinaryTreeSize(BTNode* root)
{
if (root == NULL)//既然知道我们这里进行的是递归操作,那么就必须得有递归的结束条件,由上可知,递归的结束条件就是我们遇到空树的时候,这一趟递归就可以结束了。
{
return 0;//我们这里研究的是二叉树的节点个数,递归结束的时候,说明这棵树是空树,也就没有节点,返回0。
}
return BinaryTreeSize(root->_left) + BinaryTreeSize(root->_right) + 1;//如果我们现在访问的这棵树不是空树的话,那么我们就去找这棵树的左子树的节点和这棵树的右子树的节点,并且在最后我们在向上一层返回时还需要加1,这个1代表的是这棵树的根节点。
}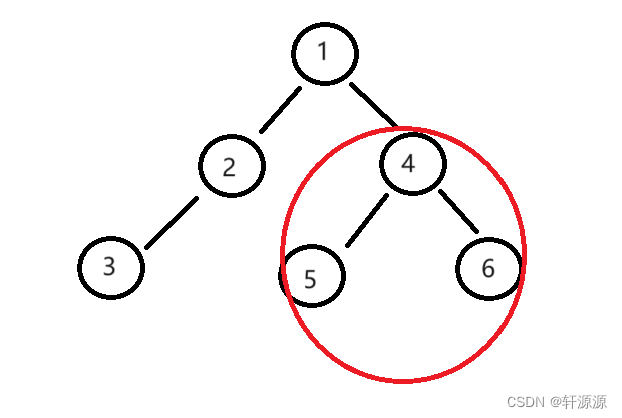
我们就拿红色圈圈里面的这棵子树来说明一下为什么要加1,return BinaryTreeSize(root->_left) + BinaryTreeSize(root->_right) + 1;这一步程序中BinaryTreeSize(root->_left)得到的是以4为根的这棵树的左子树的节点个数,BinaryTreeSize(root->_right)得到的是以4为根的这棵树的右子树的节点个数,当得到之后,我们就要递归回到调用以1为根的这棵树的右子树的函数了,这个函数得到的是以1为根的树的右子树的节点个数,如果我们不加1直接返回的话,就没有加上以4为根的这棵树的那个根节点的个数,因此,这里我们要加1,而这个1表示的就是根节点的个数。
(8).二叉树的层数:
这一个步骤中,我们要实现计算二叉树的层数,在讲解开始之前,我们要先知道二叉树的层数是取决于这棵树的左右两个子树的层数中最大的那一个,就比如说,某一棵树的左子树的层数是4,右子树的层数是2,那么这个二叉树的层数就是4层,或者说,层数就是高度,二叉树的高度这个概念我在上一个博客中有讲到,大家有不了解的,可以到上一个博客去了解一下,链接在下面。树和二叉树系列(一):-CSDN博客文章浏览阅读590次,点赞17次,收藏27次。这里我们还是和上面一样来为大家解释一下过程,我们大家都是学习数据结构的,相比大家肯定都或多或少的通听过堆排序吧,每错,接下来,我就为大家来介绍一下堆排序的过程,说起堆排序,想必大家的脑海中第一个印象就是建立一个第三方数组,来帮助进行排序(我们要想实现堆排序,首先就得建立一个堆),这样也是可以的,但是这样的话,会让空间复杂度上升的,我们这里有更好的方法可以去实现堆排序,就是我们直接在原数组上建堆。也就是这一个篇章,树和二叉树的精彩讲解。https://blog.csdn.net/2301_81390458/article/details/139456368?spm=1001.2014.3001.5501
int BinaryTreeLevelSize(BTNode* root)
{
if (root == NULL)//如果这棵树为空树的话,就说明这棵树是没有节点的,那么这棵树的层数自然就是0了,因此,我们这里直接返回0就可以了。
{
return 0;
}
int a1 = BinaryTreeLevelSize(root->_left);//因为我们这里是要计算某一棵二叉树的层数,我们就要得到这棵二叉树的左右这两棵子树的层数,这里我们先得到左子树的层数,定义一个int类型的变量去接收左子树的层数。
int a2 = BinaryTreeLevelSize(root->_right);//再定义一个int类型的变量去接收右子树的层数。
return a1 > a2 ? a1 + 1 : a2 + 1;//如果这棵树不是空树的话,那么我们完成上面的操作后就要返回这棵树的层数了,根据我们上面的分析,我们这里选择左右子树层数大的那一个层数作为这棵树的层数去返回,由于上面我们得到的是该棵树的左右子树的层数,并不是这棵树的层数,因此,我们这里在找出最大值后还要加上这棵树的根(因为根的层数是1),也就是加1。
}这个步骤到这里其实还还没有结束,这里我们在来给大家说明一个容易出现的问题,就是最后的那三步可不可以压缩成一句代码,如下所示:
return BinaryTreeLevelSize(root->_left) > BinaryTreeLevelSize(root->_right) ? BinaryTreeLevelSize(root->_left) + 1 : BinaryTreeLevelSize(root->_right) + 1;好的,这里给大家说一下,这样写的话,按道理来说的话是正确的,但是这样写的话,会有一个很大的错误,就是这样做的话,会导致时间复杂度将会大幅度上升,效率可能会降低,我们现在来分析一下这一句代码,现调用BinaryTreeLevelSize(root->_left) > BinaryTreeLevelSize(root->_right)这两个函数得到这棵树的左右子树的层数,然后比较,比较完了之后,程序就会接着往后面去走,去让大的那个层数加1,但是,不知道大家有没有注意到,就是最大的那个层数的值没有被我们保存下来,就是丢了,那么我们到后面还要再次去调用这个函数求一下这个最大的层数值,说到这里,大家可能会觉得这没有什么,但是,大家好像忘了一点,就是,我们这个是通过递归来实现的,每次都要去递归一下,这个所消耗的时间是非常恐怖的,你若不信的话,可以自己画图试一试。
(9).二叉树叶子节点个数:
这一个步骤我们要计算的是某一棵二叉树的叶子节点(前一个博客有讲)的个数,也就是这里我们要求的是没有孩子的节点,这里我们要先了解一下叶子节点的特点,就是这棵树的左右子树均为空树,那么这棵树对应的根节点就是叶子节点。
int BinaryTreeLeafSize(BTNode* root)
{
if (root == NULL)//如果这棵树是空树的话,则这棵树没有叶子节点,返回0即可。
{
return 0;
}
if (root->_left == NULL && root->_right == NULL)//判断一下这棵树的左右节点是否均为空,如是的话,则说明这棵树对应的根节点为叶子节点,这棵树有1个叶子节点,返回1即可。
{
return 1;
}
return BinaryTreeLeafSize(root->_left) + BinaryTreeLeafSize(root->_right);//如果这棵树不是空树的话,就返回这棵树的左右子树中所含有的叶子节点的个数之和。
}(10).二叉树第k层节点个数:
我们有时候会想要求一下某一棵二叉树中的某一层上的节点个数,我们大家有好多的人第一次见到这道题的时候是没有思路的,这里我来为大家提供一种思路,以下面这一颗树为例给大家解释一下:
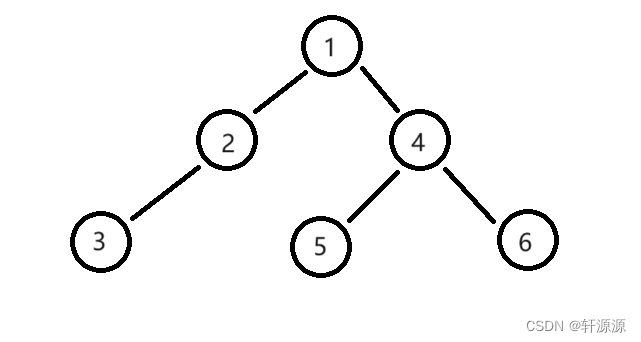
比如说我现在想要得到第3层的节点个数,那么对于以1这个节点为根的这棵树来说的话,就是求第3层的节点个数,但是,对于以2,4这两个节点为根的这两棵树来说的话,求的就是第2层的节点个数,那么对于以3,5,6这三个节点为根的这三棵树来说的话,就是求第1层的节点个数,换句话说,就是求这三棵树的根结点个数。
int BinaryTreeLevelKSize(BTNode* root, int k)
{
if (root == NULL)//如果这颗树为空树,就说明第k层上的节点个数为0。
{
return 0;
}
if (k == 1 && root != NULL)//如果k==1就说明我们要求的是这一层的节点个数,同时我们还要限制这棵树不能为空树,均符合这两个条件的话,那么,就说明有一个节点,返回1即可。
{
return 1;
}
return BinaryTreeLevelKSize(root->_left, k - 1) + BinaryTreeLevelKSize(root->_right, k - 1);//若程序进行到这里时,就说明我们还没有到第k层,就接着去找这棵树的左右子树,这样的话,将这棵树的左右子树再次看成一棵新的树,那么对于这棵新的树来说,要找的就是第k-1层的节点个数。
}(11).二叉树查找值为x的节点:
这一步操作就类似于我们之前学过的查找元素的操作,这个二叉树的查找和前面不同的是,二叉树中的许多个节点中可能存放的都是同一个值,因此,这里我们返回找到的第一个节点的地址即可。
BTNode* BinaryTreeFind(BTNode* root, BTDataType x)
{
if (root == NULL)//如果这颗树为空树,则说明没有找到该节点,返回NULL即可。
{
return NULL;
}
if (root->_data == x)//如果这个节点中存储的值刚好就是我们要查找的值,那么我们返回这个节点的地址即可。
{
return root;
}
BTNode* left = BinaryTreeFind(root->_left, x);//当程序走到这里时,说明这棵树的根节点不是我们要找的节点,那么我们就到这棵树的左右子树上去找,先去左子树找。
BTNode* right = BinaryTreeFind(root->_right, x);//然后再去到右子树去找。
return left == NULL ? right : left;//我们这里返回的是找到的那个节点的地址,如果在左子树上找到了,右子树上没有找到,返回左子树找到的那个节点的地址,如果在右子树上找到了,左子树上没有找到,返回右子树找到的那个节点的地址,如果再左右子树上都找到了,那么,随便返回那个都可以,因为我们这个题的目的是找到符合条件的节点,只要找到就可以了。
}(12).二叉树销毁:
二叉树的销毁这里我们采用的是后序遍历的方法去销毁的,这里其实使用这个方法销毁是最好的方法,如果我们先将根节点销毁掉,那么,就无法找到它的左右子树,还得在销毁之前将它的左右子树先存起来,有点麻烦,因此,我们在这里不采用先销毁根节点的这种方法。
void BinaryTreeDestory(BTNode** root)//这里传不传地址其实都可以,都可以将其销毁掉。
{
if (*root == NULL)//如果这棵树为空树,则不需要将其销毁掉,因为空树就是啥也没有。
{
return;
}
BinaryTreeDestory(&((*root)->_left));//先销毁左子树。
BinaryTreeDestory(&((*root)->_right));//再销毁右子树。
free(*root);//如果程序走到这一步,说明左右子树均被销毁掉了,这一步是销毁掉根节点。
}(13).层序遍历:
这一步我们要进行的层序遍历就是一层一层地去遍历二叉树,我们这里在进行二叉树的层序遍历的时候,还需要借用到队列的相关知识(我们这里在写层序遍历是不需要将空指针也入队列)。
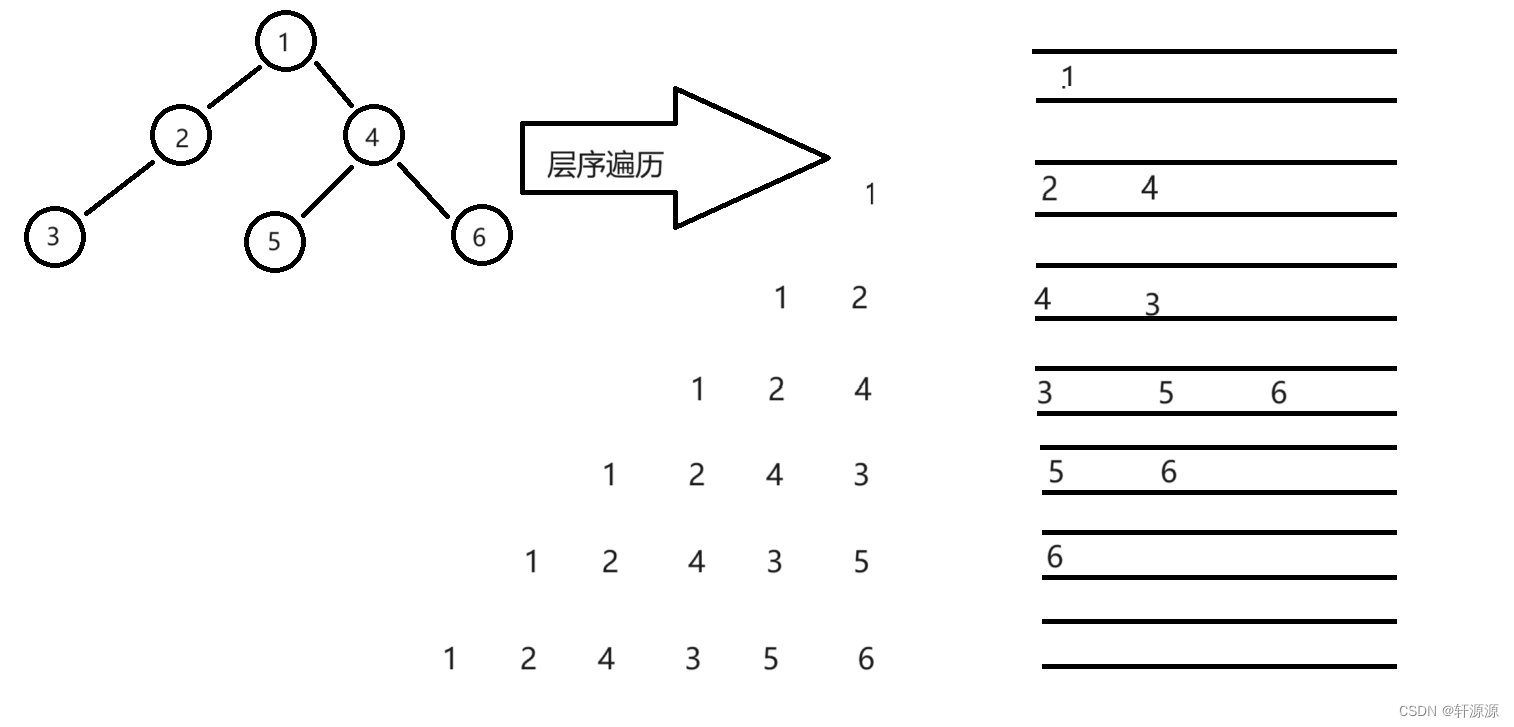
接下来我就上面的二叉树来给大家讲解一下层序遍历的过程,正如上图所示的那样,我们这里先将1这个节点入队,由于是层序遍历,接下来就要入1这个节点的两个子树的根,也就是2这个节点和4这个节点,先将1这个节点出队列,然后将1这个节点的的两个子树的根节点入队列,也就是2这个节点和4这个节点入队列,将2这个节点出队列,然后将2这个节点的的子树的根节点入队列,也就是3这个节点入队列,将4这个节点出队列,然后将4这个节点的的两个子树的根节点入队列,也就是5这个节点和6这个节点,将5这个节点出队列,然后将5这个节点的的子树的根节点入队列,将6这个节点出队列,然后将6这个节点的的子树的根节点入队列,当队列为空时,就说明层序遍历结束了。
这里我们在借助队列来实现层序遍历的时候还有一个要注意的地方,就是队列中的元素类型是啥,我们应该存什么?首先,我们在这里肯定是不能存节点中的值的,否则,找不到根节点的左右子树,其次,我们也不要存节点,这样消耗太大,既然如此,我们就只能存放指向该节点的指针。
void BinaryTreeLevelOrder(BTNode* root)
{
Queue q;//我们在完成层序遍历的时候,需要借助队列的帮助,因此,我们这里要先定义一个队列。
QueueInit(&q);//队列的初始化。
if (root == NULL)//如果二叉树为空,则不需要遍历。
{
return;
}
QueuePush(&q, root);//先将根压到队列中去。
while (!QueueEmpty(&q))//层序遍历的结束条件是队列不为空。
{
BTNode* front = QueueFront(&q);//得到队列中的首元素。
printf("%d ", front->_data);//打印出该节点存储的值。
QueuePop(&q);//将这个首元素出队列。
if (front->_left != NULL)//判断该根节点的左节点是否为空,若不为空,入队列,否则,不如队列。
{
QueuePush(&q,front->_left);
}
if (front->_right != NULL)//判断该根节点的右节点是否为空,若不为空,入队列,否则,不如队列。
{
QueuePush(&q, front->_right);
}
}
QueueDestroy(&q);//销毁队列。
}(14).判断二叉树是否是完全二叉树:
这一步我们判断一个二叉树是否是完全二叉树我们还需要借助队列的帮助,在讲述之前,我们要先了解一下完全二叉树的判断条件,要想判断一棵二叉树是否为完全二叉树,就要看一下两个节点之间是否有空指针(因此,我们在实现这个操作时,必须要将NULL也入队列),那照上着上面的那个思路,换句话说,就是我们可以按照层序遍历的过程,当我们遇到第一个NULL时就停止遍历,接下来就判断队列中剩下的元素中有没有不为NULL的元素,若有,则说明该二叉树不是完全二叉树,反之,则说明该二叉树是完全二叉树。
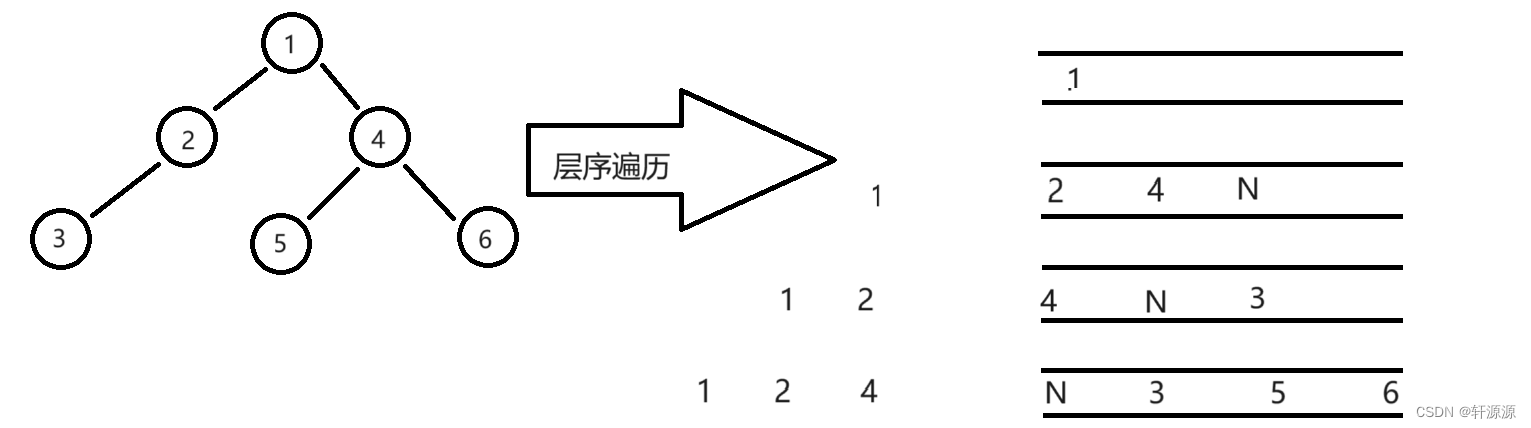
(N代表的是NULL)
int BinaryTreeComplete(BTNode* root)
{
Queue q; 我们在完成层序遍历的时候,需要借助队列的帮助,因此,我们这里要先定义一个队列。
QueueInit(&q); //队列的初始化。
if (root == NULL)//判断一下该二叉树是否为空树,若是空树,则说明此二叉树就是完全二叉树。
{
return 1;
}
QueuePush(&q, root); //先将根压到队列中去。
while (!QueueEmpty(&q)) //我们这里要使用到层序遍历的思想,层序遍历的结束条件是队列不为空。
{
QDataType front = QueueFront(&q);
QueuePop(&q);
if (front == NULL)//如果为NULL,则就停止遍历二叉树,接下来就去判断队列中剩下的元素中有没有不为NULL的元素。
{
break;
}
QueuePush(&q, front->_left);
QueuePush(&q, front->_right);
}
while (!QueueEmpty(&q))//我们要遍历队列中剩余的元素,因此循环结束条件是队列不为空。
{
BTNode* front = QueueFront(&q);//得到队首元素。
QueuePop(&q);//队首元素出队列。
if (front != NULL)//判断队首元素是否为空。
{
return 0;
}
}
QueueDestroy(&q);//销毁队列。
return 1;
}(上述代码中返回0说明该二叉树不是完全二叉树,返回1说明该二叉树是完全二叉树)
(15).通过前序遍历的数组"ABD##E#H##CF##G##"构建二叉树(#代表的是NULL):
这个步骤是想让我们将上面给的这个数组将它转换成为一棵二叉树,换句话说,就是上面给的这个数组是某一棵二叉树的前序遍历的结果,现在需要我们将这个数组给转换回二叉树去。
BTNode* BinaryTreeCreate(BTDataType* a, int n, int* pi)//这里为了方便大家的理解,我先来为大家说明一下这三个参数分别所代表的含义都是什么,a是某一棵二叉树的前序遍历的结果(使用数组表示),n是数组的长度(这里我们没有用上,后面我会向大家解释为什么有这个参数),pi指向的是访问数组的那个下标的地址,就是我们在访问数组时是通过下表来访问数组的,而pi指向的就是这个下标的地址。
{
if (a[*pi] == '#')//如果我们当前访问的数组的位置是NULL,说明此处没有节点,就可以返回了。
{
(*pi)++;//(*pi)++这里之所以要写上这一是因为我们访问完数组中的这个元素后,下一次就要访问数组中的下一个元素了,因此,要++。
return NULL;//返回NULL。
}
BTNode* root = (BTNode*)malloc(sizeof(BTNode));//如果此处不为NULL,则说明这里有一个节点,那么我们就要建立一个节点空间。
if (root == NULL)
{
perror("malloc fail");
return NULL;
}
root->_data = a[*pi++];//将我们要访问的数组元素放到我们刚刚开创的空间中,放完后,我们下一次访问的就是数组中的下一个元素了,因此要++。
root->_left = BinaryTreeCreate(a, n, pi);//因为我们这个数组是二叉树通过前序遍历形成的,所以我们在返回创造二叉树时,也要遵循前序遍历来创建,因此,先接左子树。
root->_right = BinaryTreeCreate(a, n, pi);//然后再接右子树。
return root;//当程序走到这里时,说明我们已经将这棵二叉树给创建好了,那么,直接返回就可以了。
}现在来给大家说一下刚刚上面遗留下来的两个问题:
首先我们来解释一下为什么传的是当前我们要访问的数组元素的地址(也就是下标的地址),而不是下标的值,接下来,通过下图我来为大家解释一下(使用图中所示的数组来为大家解释):
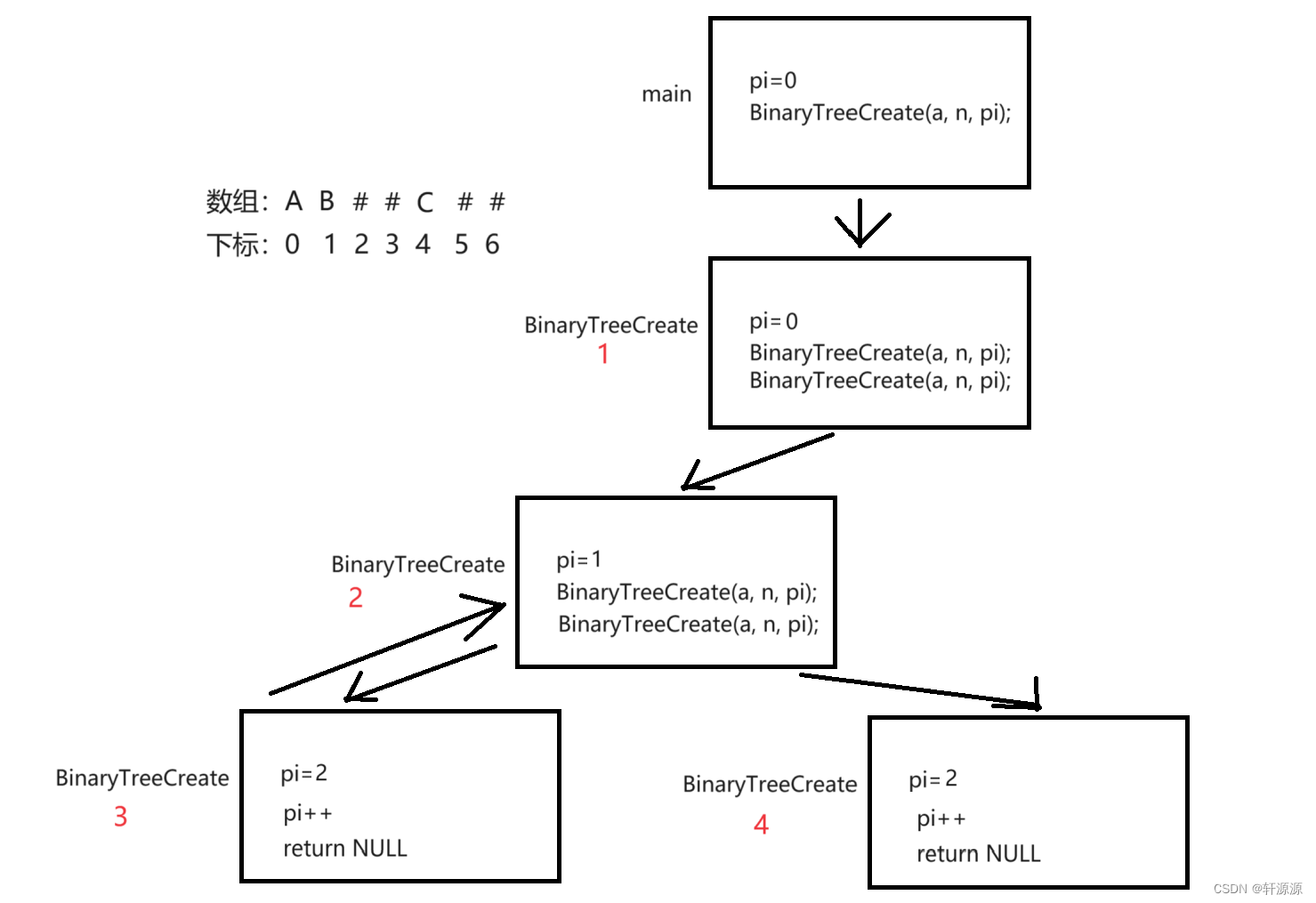
就上图来说,我们在第1次调用BinaryTreeCreate函数时,访问的是数组中下标为0的元素,也就是A,接下来,我们再调用BinaryTreeCreate函数,那么第2次调用该函数访问的元素应该是数组中下标为1的元素,也就是B,紧接着我们往后面走,就是第3次调用BinaryTreeCreate函数,下一个应该访问的是#这个元素,好的,按照我们上面写的程序,就是pi++,returnNULL,返回到第二次调用BinaryTreeCreate函数里面,接下来就是进行第4次调用BinaryTreeCreate函数,按照我们的逻辑来说,这次访问的数组中的元素应该是下标为3的这个元素,但是,实际上,我们发现,我们第4次调用BinaryTreeCreate函数中访问的数组元素居然是下标为2的这个元素,为啥呢?因为在第3次调用BinaryTreeCreate函数之后pi++的时候,他只是在第3次调用BinaryTreeCreate函数中++,形参改变,实参不变,因此导致后面的一些错误,所以,我们这里必须要传参。
其次我们来解决一下下一个问题,就是参数中的n这个参数是干什么作用的,这个n其实就是数组的长度,之所以在参数中传这个数,是因为有时候题目中给你的那个数组不完整,就比如说,可能就会把上面的那个数组改成"ABD##E#H##CF##G#",最后会少一个#,那么这样造成的结果就是会出现越界的情况,加上这个是为了避免这种情况的出现,确定遍历的结束。
这里还有一个情况需要提醒一下大家,就是if (a[*pi] == '#')这一行代码他不可以和下面的(*pi)++这行代码结合进而写成if (a[(*pi)++] == '#'),这种情况会出现问题的,如果我们访问的数组元素刚好是#,那这句代码没有问题,但是如果我们访问的元素不是#,就会出现问题,就拿这个数组来说吧(ab##c##),我们要访问的元素是a,但是程序是有先后顺序的,会先走这个a[(*pi)++]代码,走完后,pi指向的就是b这个元素了,但是我们按照逻辑走的话,这里应该是先访问a这个元素的,实际上,访问的是b这个元素,又出错的风险,因此,这两句代码是不可以结合的。
到这里,我们的所有关于二叉树的部分就全部结束了,希望这篇博客上的内容可以帮助到大家,谢谢大家的支持。