【Python】一文向您详细解析内置装饰器 @lru_cache
下滑即可查看博客内容

🌈 欢迎莅临我的个人主页 👈这里是我静心耕耘深度学习领域、真诚分享知识与智慧的小天地!🎇
🎓 博主简介:985高校的普通本硕,曾有幸发表过人工智能领域的 中科院顶刊一作论文,熟练掌握PyTorch框架。
🔧 技术专长: 在CV、NLP及多模态等领域有丰富的项目实战经验。已累计提供近千次定制化产品服务,助力用户少走弯路、提高效率,近一年好评率100% 。
📝 博客风采: 积极分享关于深度学习、PyTorch、Python相关的实用内容。已发表原创文章600余篇,代码分享次数逾七万次。
💡 服务项目:包括但不限于科研辅导、知识付费咨询以及为用户需求提供定制化解决方案。
🌵文章目录🌵
- 💡一、初识@lru_cache
- 🎯二、深入理解@lru_cache
- 2.1 缓存大小与淘汰策略
- 2.2 类型敏感的缓存
- 2.3 缓存的透明性
- 🚀三、使用场景与示例
- 🚀四、总结与展望
下滑即可查看博客内容
💡一、初识@lru_cache
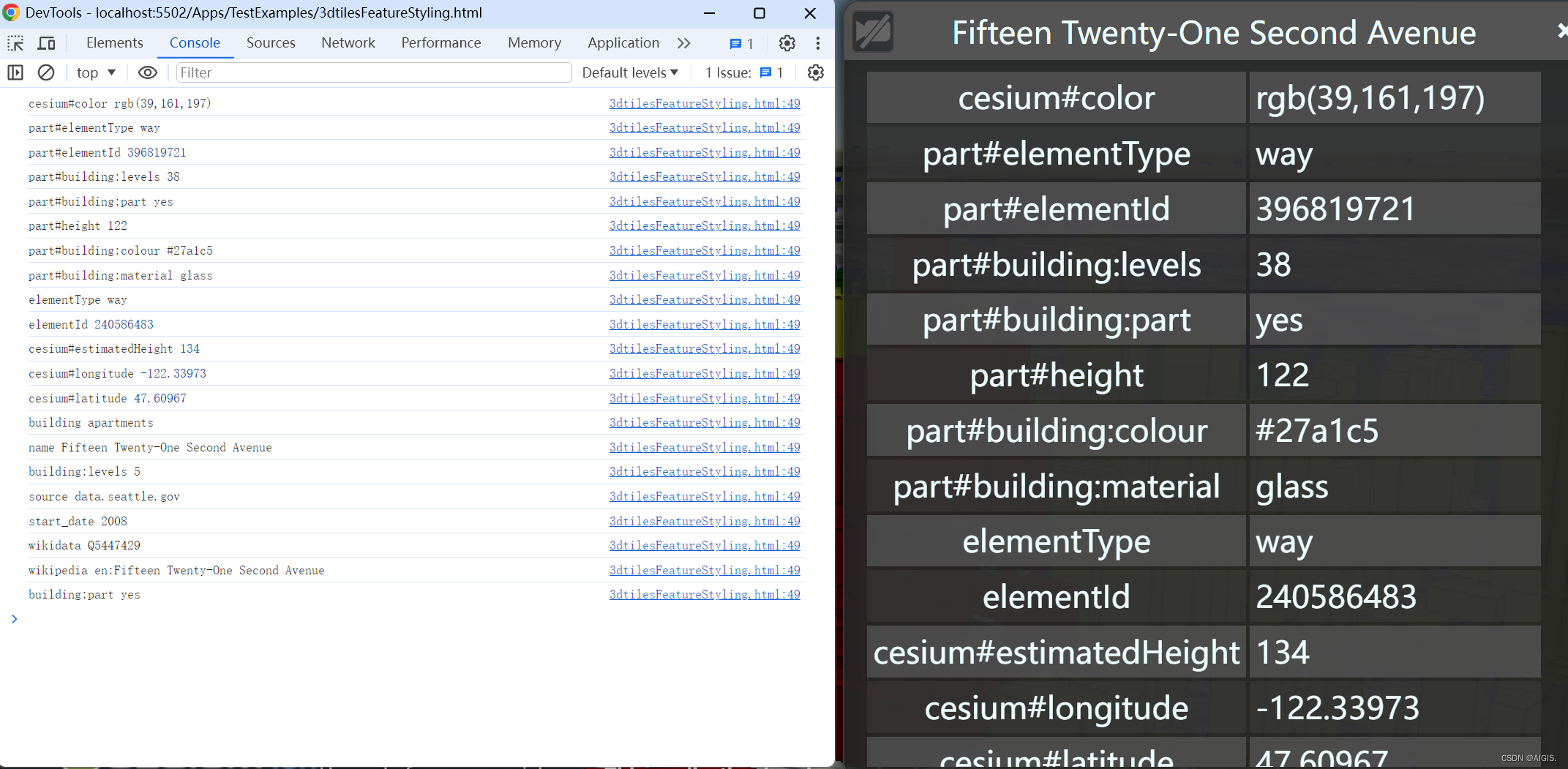
在Python中,当我们需要频繁地调用一个计算成本较高的函数,并且这些调用经常以相同的参数进行时,使用缓存策略可以显著提高性能。Python的functools模块提供了一个名为lru_cache的装饰器,它实现了最近最少使用(Least Recently Used, LRU)缓存策略。
首先,让我们来看看如何使用lru_cache装饰器:
from functools import lru_cache
@lru_cache(maxsize=128)
def fibonacci(n):
if n < 2:
return n
return fibonacci(n-1) + fibonacci(n-2)
# 调用函数
print(fibonacci(10)) # 第一次计算并缓存结果
print(fibonacci(10)) # 直接从缓存中获取结果,不再计算
上面的代码中,fibonacci函数使用了lru_cache装饰器,这意味着该函数的结果会被缓存起来。当以相同的参数再次调用该函数时,它将直接从缓存中返回结果,而不是重新计算。
🎯二、深入理解@lru_cache
2.1 缓存大小与淘汰策略
lru_cache装饰器接受一个可选参数maxsize,它指定了缓存中可以存储的最大项数。当缓存达到其最大大小时,最久未使用的项将被淘汰以腾出空间。如果maxsize设置为None,则缓存大小没有限制(但请注意,这可能会导致内存占用无限增长)。
2.2 类型敏感的缓存
默认情况下,lru_cache装饰器将不同的参数视为不同的缓存键,即使这些参数的值相等但类型不同。如果你希望类型也作为缓存键的一部分,可以将typed参数设置为True。
@lru_cache(maxsize=128, typed=True)
def power(base, exponent):
return base ** exponent
print(power(2, 3)) # 缓存结果
print(power(2.0, 3)) # 由于typed=True,这将被视为一个新的缓存键
2.3 缓存的透明性
使用lru_cache装饰器后,你可以像往常一样调用函数,而不需要知道缓存的存在。缓存是透明的,它会在需要时自动工作。
🚀三、使用场景与示例
lru_cache装饰器在许多场景中都非常有用。例如,在Web开发中,你可能需要频繁地查询数据库或执行复杂的计算,而这些操作的结果可以在短时间内保持不变。通过使用lru_cache,你可以缓存这些结果,从而显著提高性能。
下面是一个简单的示例,展示了如何在Web应用中使用lru_cache来缓存数据库查询结果:
from functools import lru_cache
@lru_cache(maxsize=1024)
def get_user_data(user_id):
# 假设这是一个复杂的数据库查询
# ...
# 返回查询结果
return query_database(user_id)
# 在Web请求中调用get_user_data函数
user_data = get_user_data(123)
在这个示例中,get_user_data函数使用lru_cache装饰器进行了缓存。当Web请求需要获取用户数据时,它将首先尝试从缓存中获取结果。如果缓存中不存在所需的数据,它将执行数据库查询并将结果存储在缓存中。这样,对于相同的用户ID,后续的请求将直接从缓存中获取结果,而不需要再次执行数据库查询。
🚀四、总结与展望
lru_cache是Python中一个非常有用的装饰器,它可以帮助我们提高计算密集型函数的性能。通过缓存函数的结果,我们可以避免重复计算相同的操作,并减少不必要的计算开销。在本文中,我们详细解析了lru_cache的工作原理、使用场景与示例。希望这些信息能够帮助你更好地理解和使用lru_cache装饰器,并在实际项目中发挥它的最大作用。
随着Python生态系统的不断发展壮大,相信未来会有更多优秀的缓存库和工具出现,为我们提供更强大、更灵活的缓存解决方案。让我们期待未来Python在缓存技术方面的更多创新和进步!





![[Vulnhub] Sleepy JDWP+Tomcat+Reverse+Reverse-enginnering](https://img-blog.csdnimg.cn/img_convert/b490c94cf3e2dffdd472ea0e61537e30.jpeg)